Downloaded 20 times












































The document discusses association rule mining. It defines frequent itemsets as itemsets whose support is greater than or equal to a minimum support threshold. Association rules are implications of the form X → Y, where X and Y are disjoint itemsets. Support and confidence are used to evaluate rules. The Apriori algorithm is introduced as a two-step approach to generate frequent itemsets and rules by pruning the search space using an anti-monotonic property of support.
An introductory lecture on Data Mining, highlighting the purpose and course structure.
Definition of Association Rule Mining, its application in predicting item occurrences in market-basket transactions, and frequent itemset definition.
Explanation of support and confidence metrics, crucial for evaluating the significance of association rules.
Examples showcasing the discovery of association rules with support and confidence values, detailing the comprehensive process.
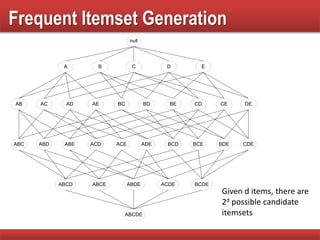
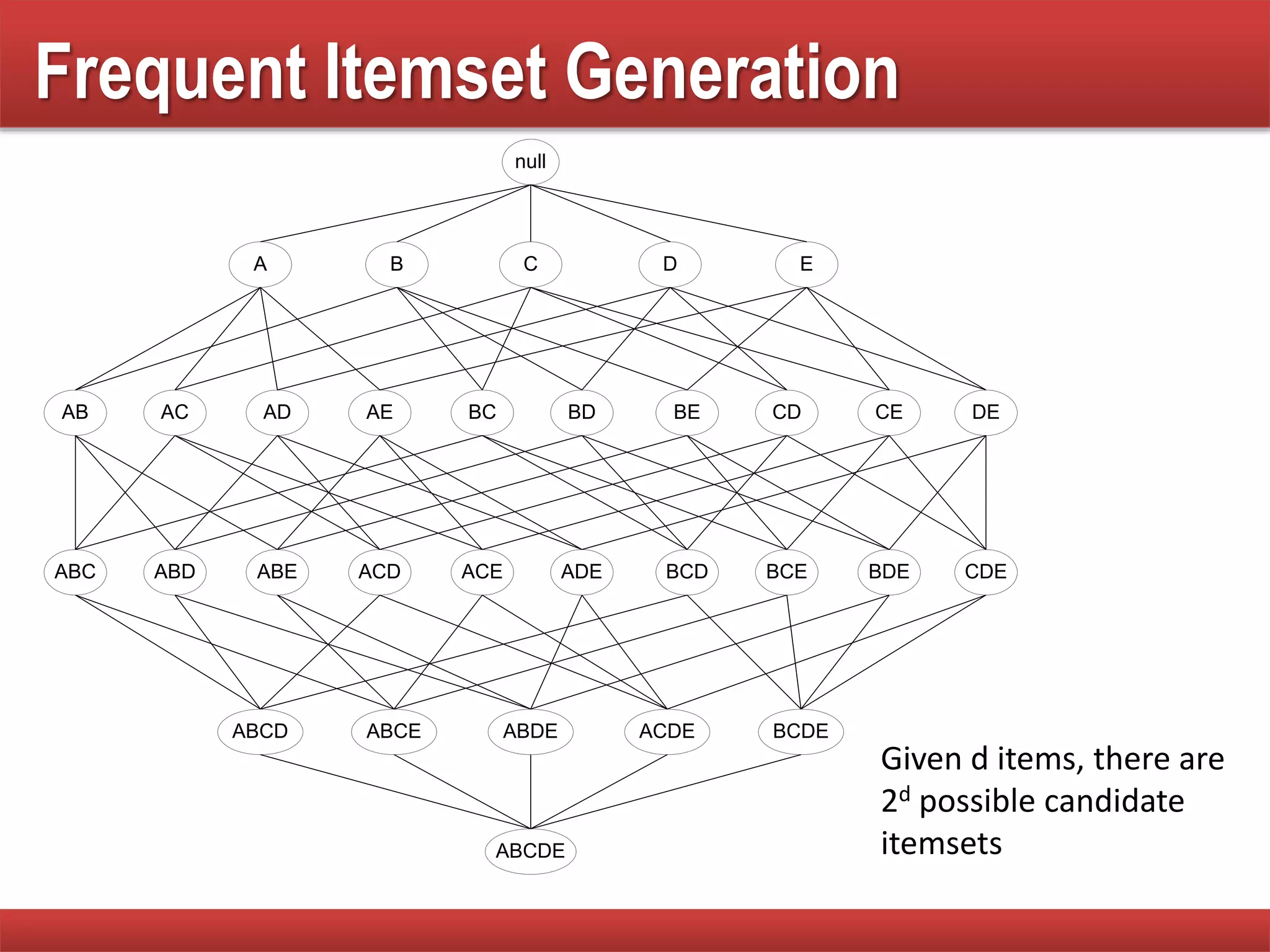
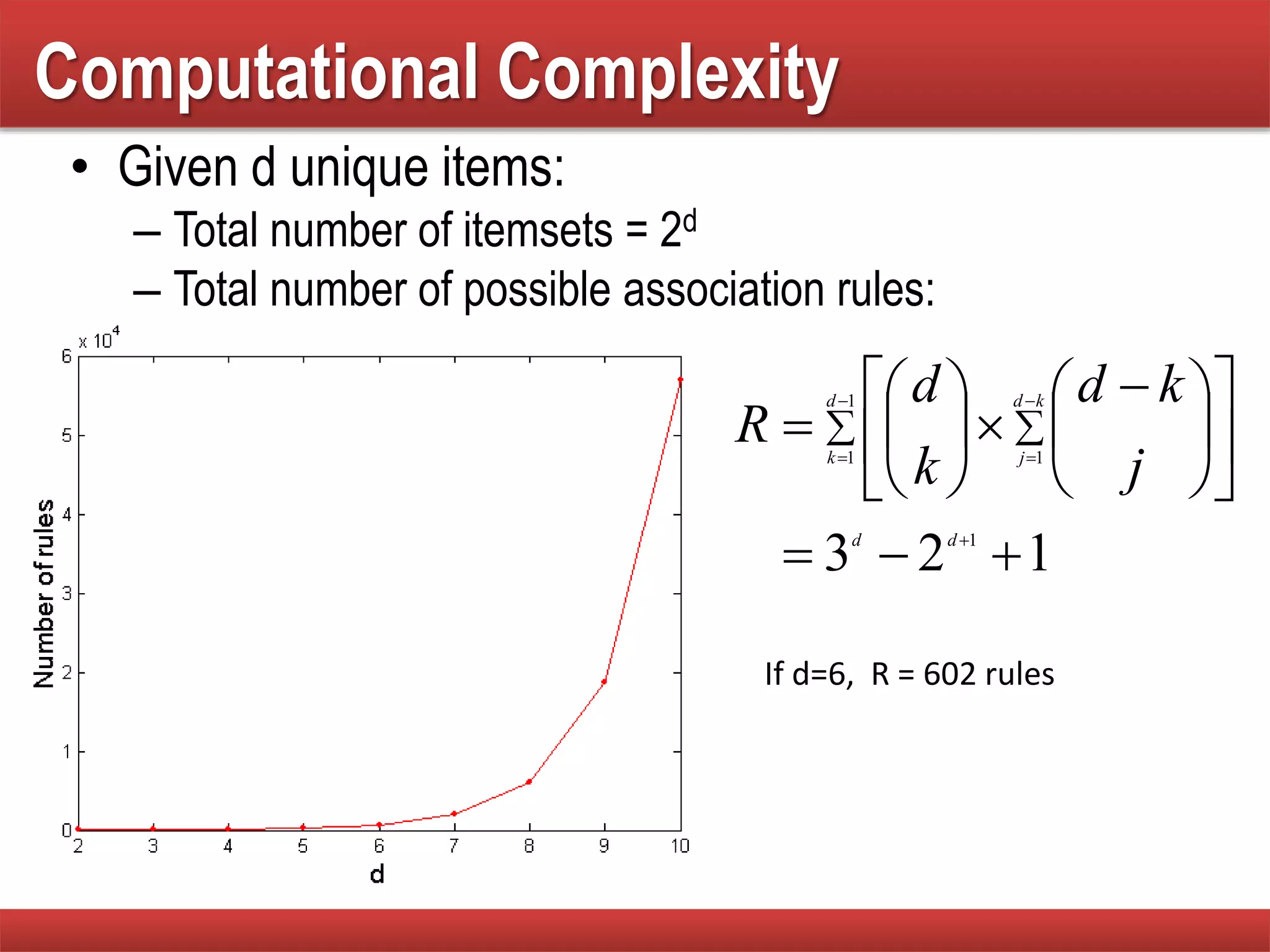
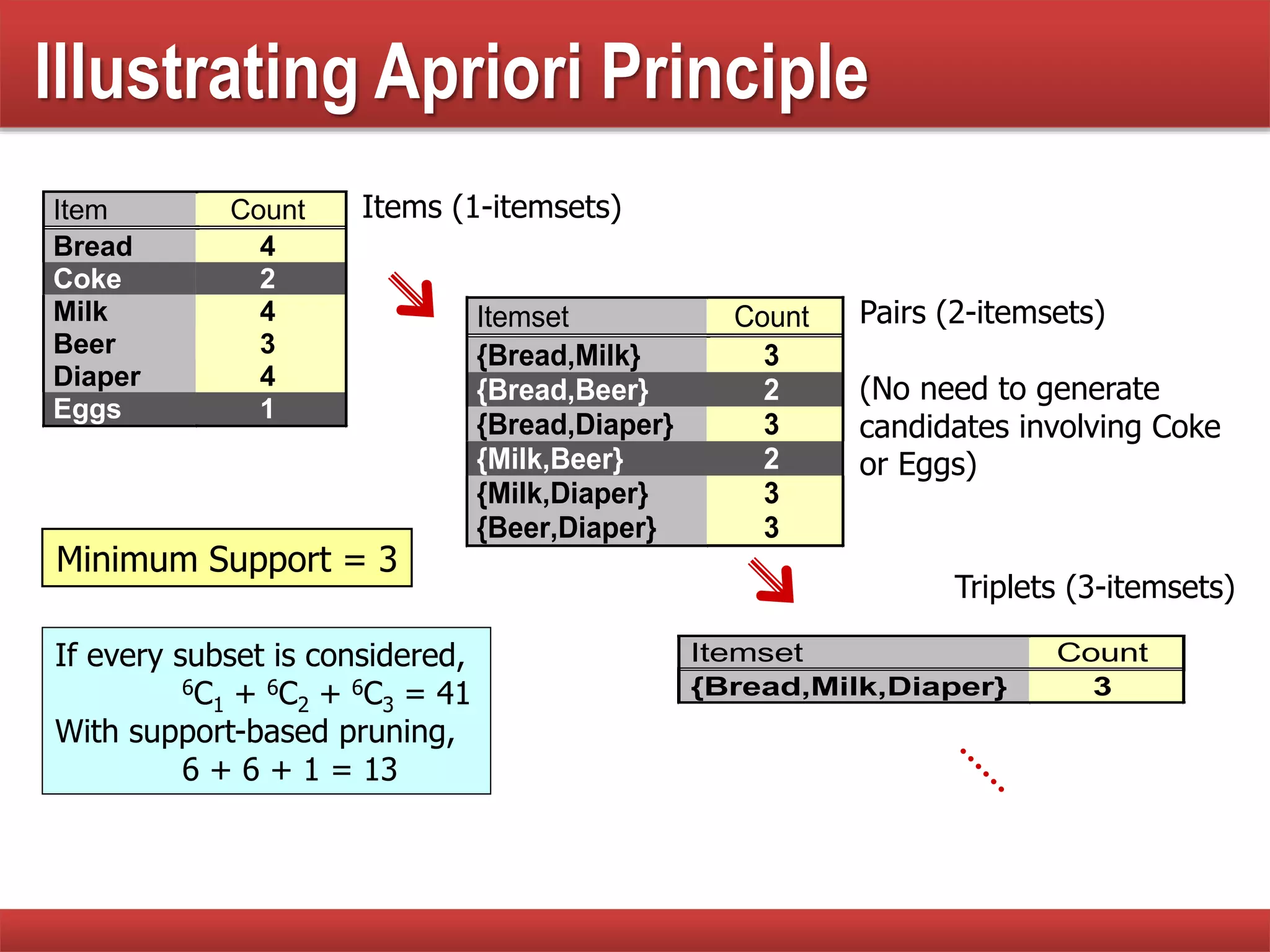
Discusses the process and challenges in generating frequent itemsets and computational costs involved.
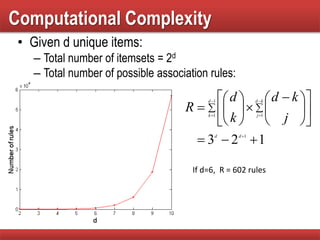
Analysis of the complexity of generating itemsets and strategies to reduce the number of candidates in frequent itemset generation.
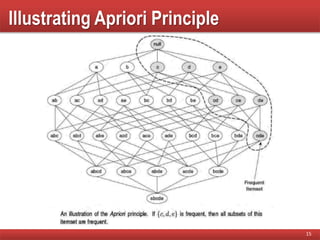
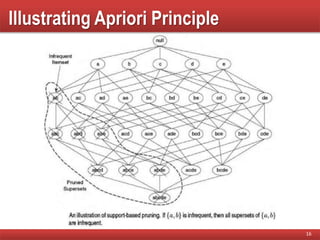
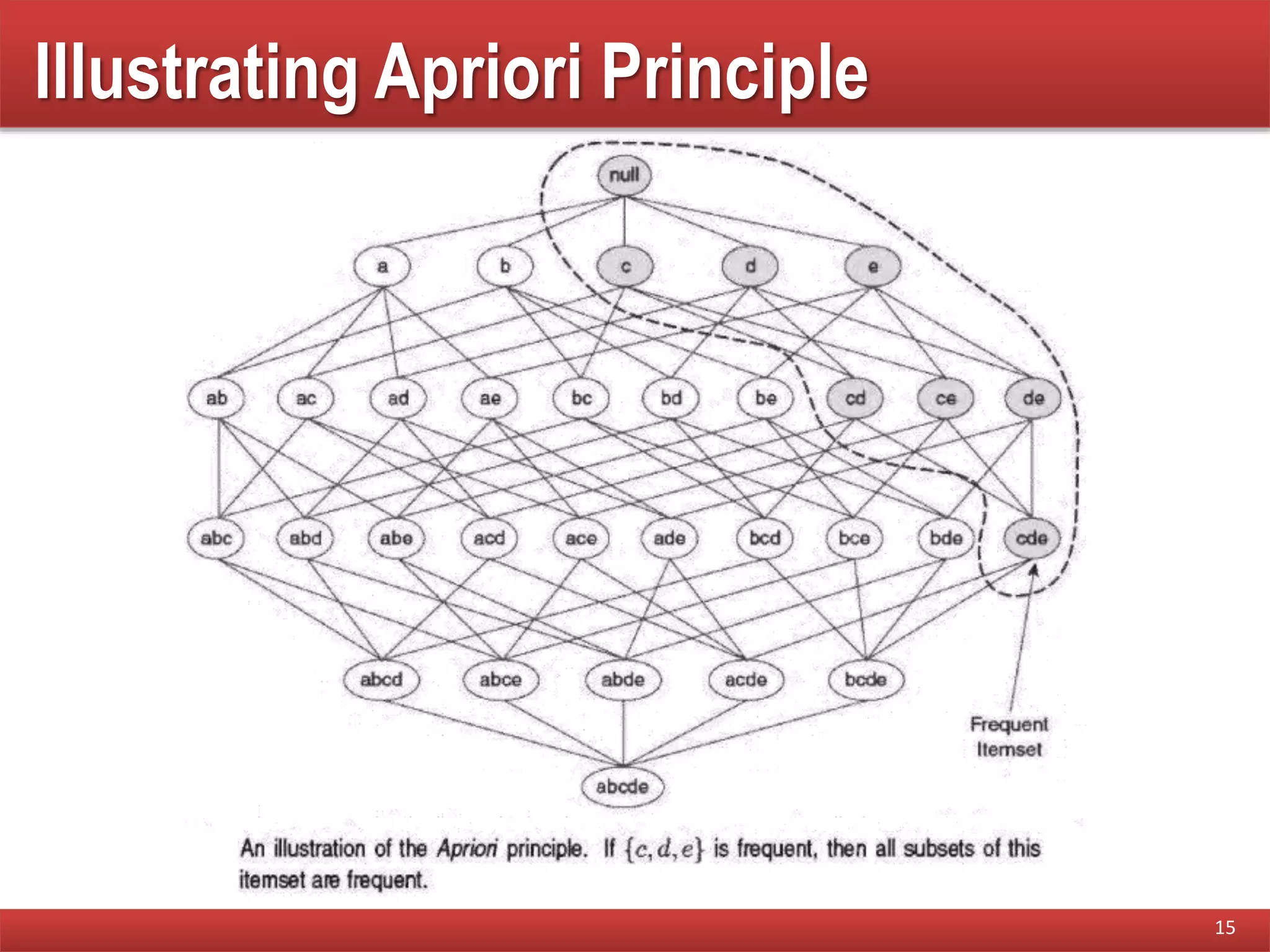
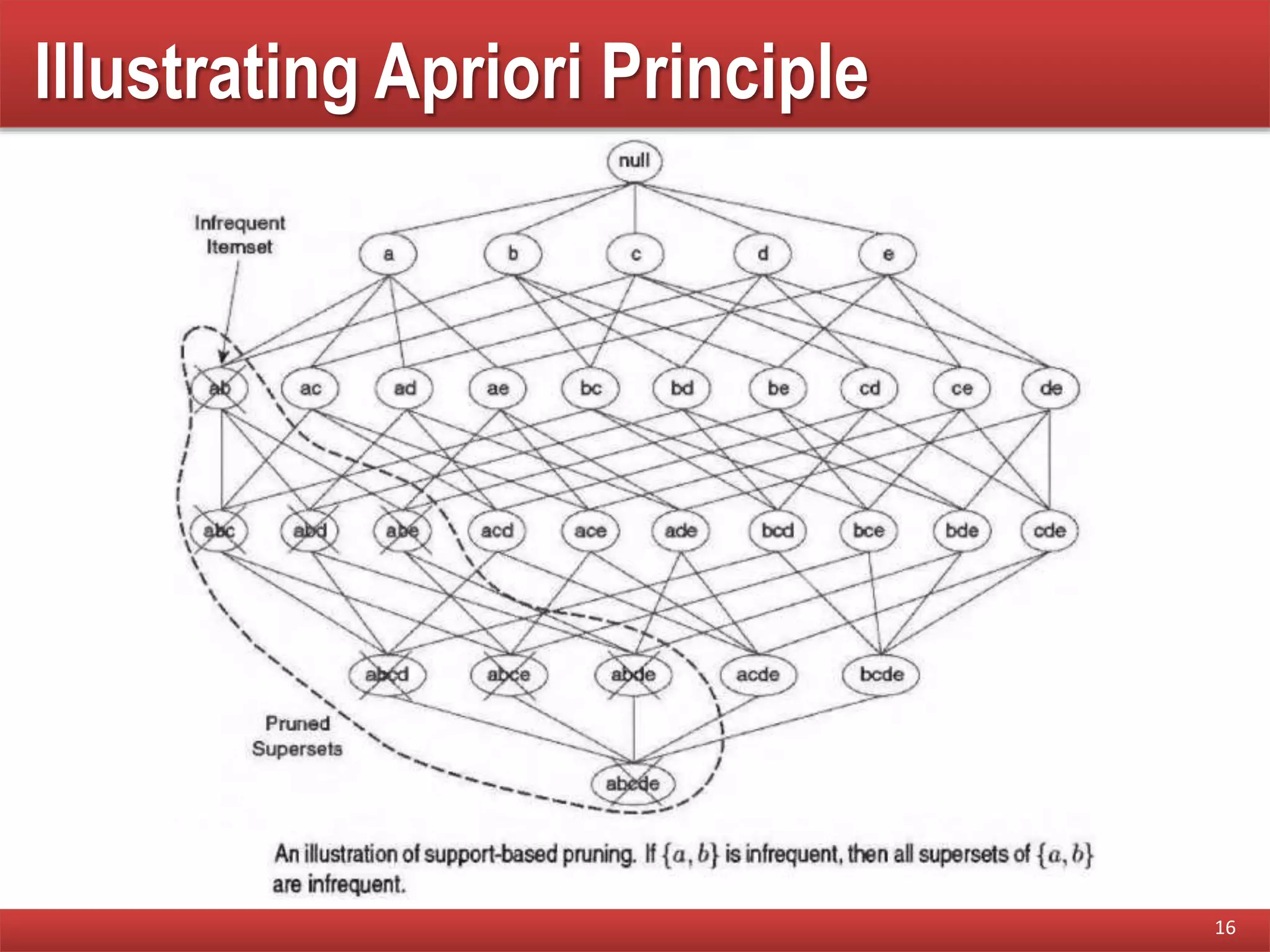
Explanation of the monotonicity property, describing how support can guide pruning of candidate itemsets during mining.
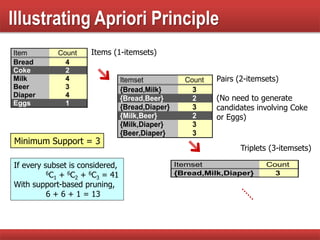
Illustrates the Apriori principle and outlines the steps of the Apriori algorithm in mining frequent itemsets.
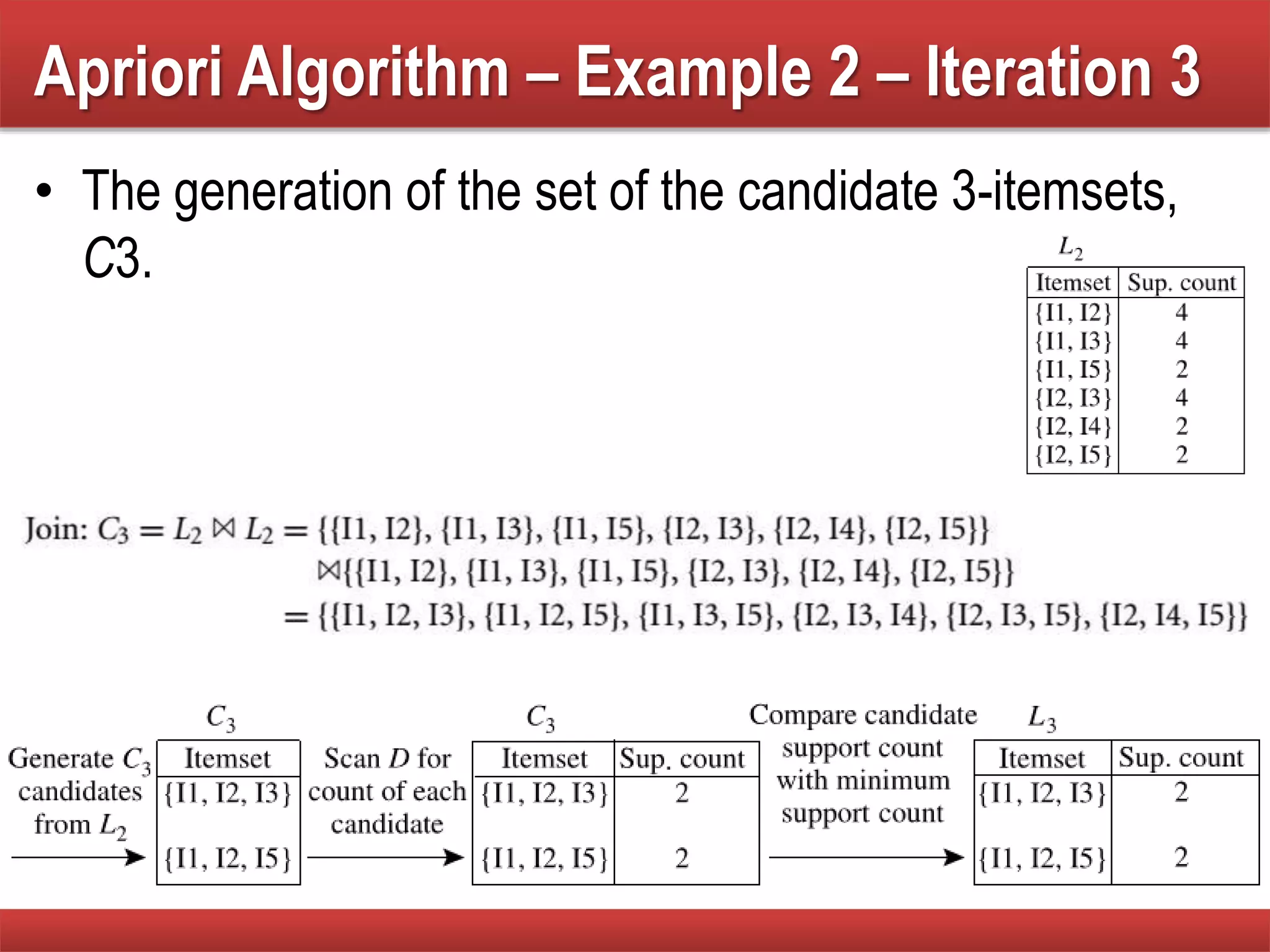
Detailed iteration steps of the Apriori algorithm, demonstrating the identification and refinement of frequent itemsets.
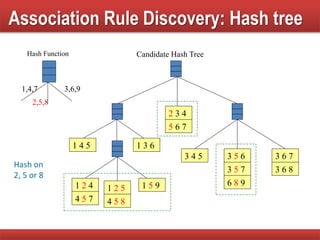
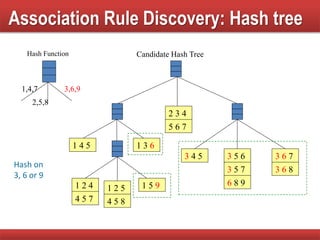
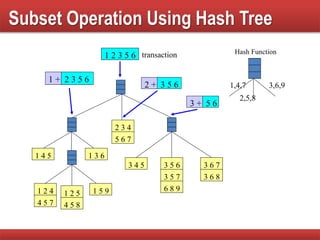
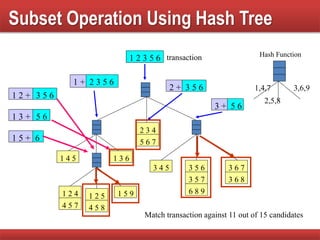
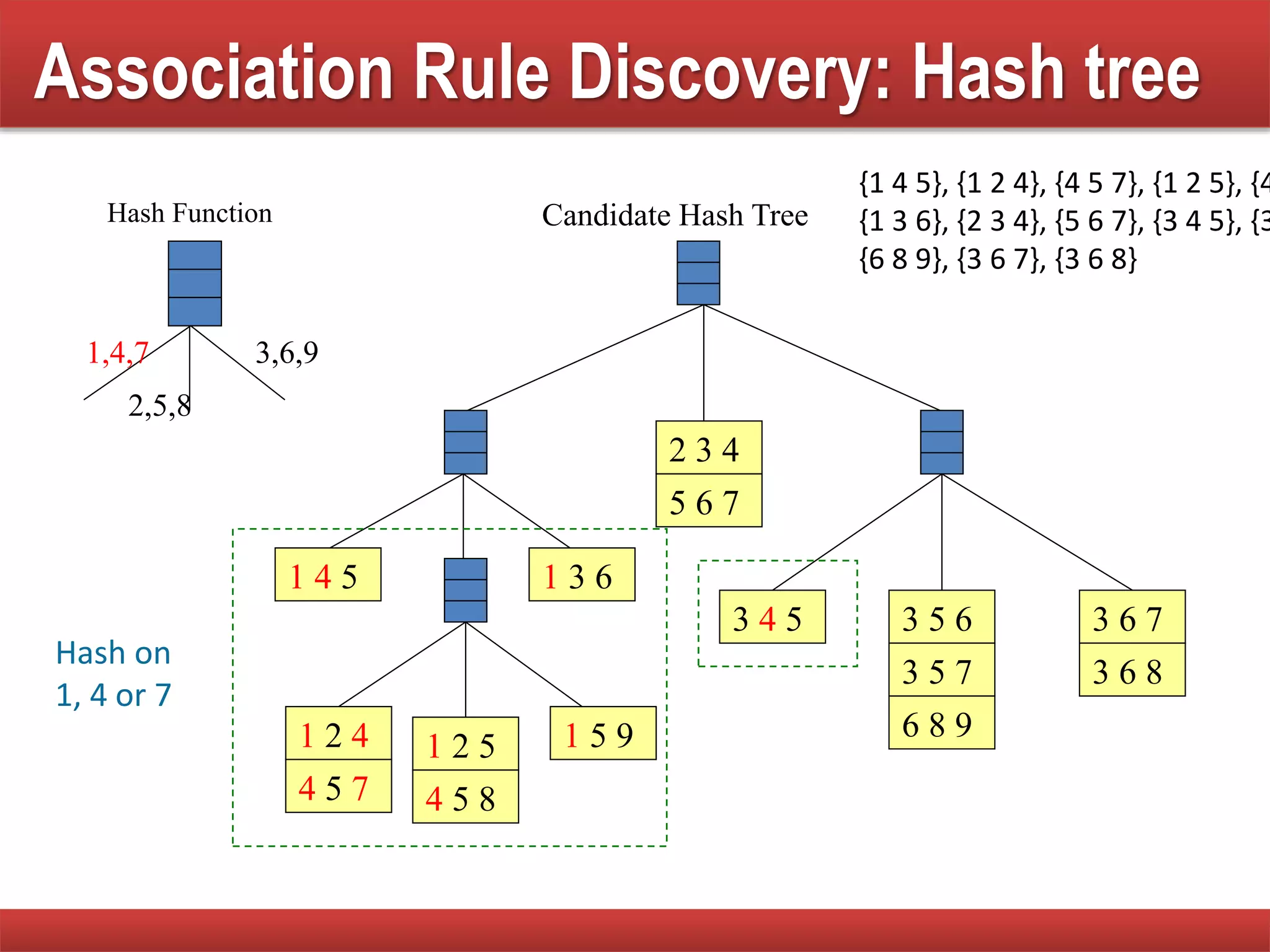
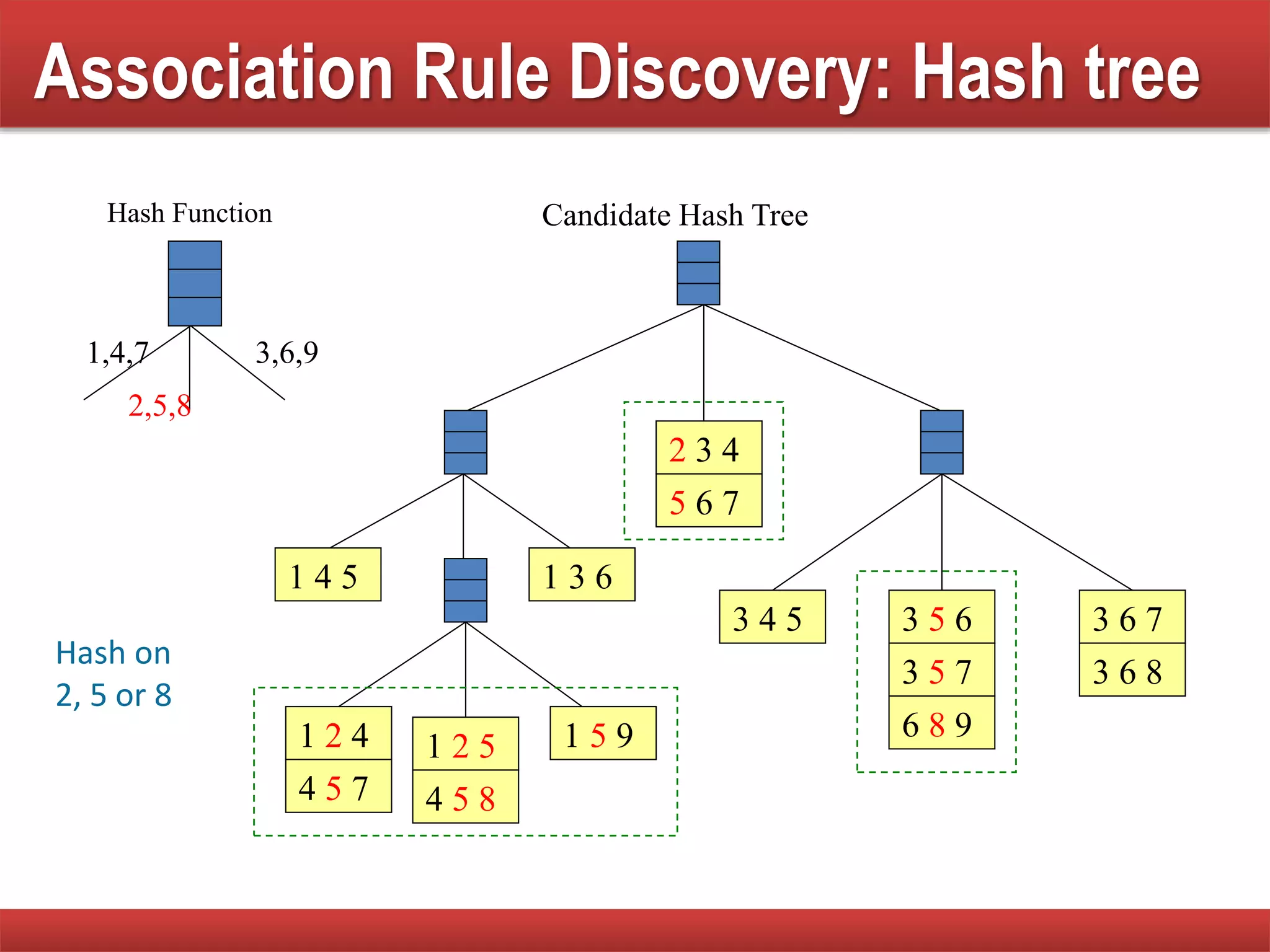
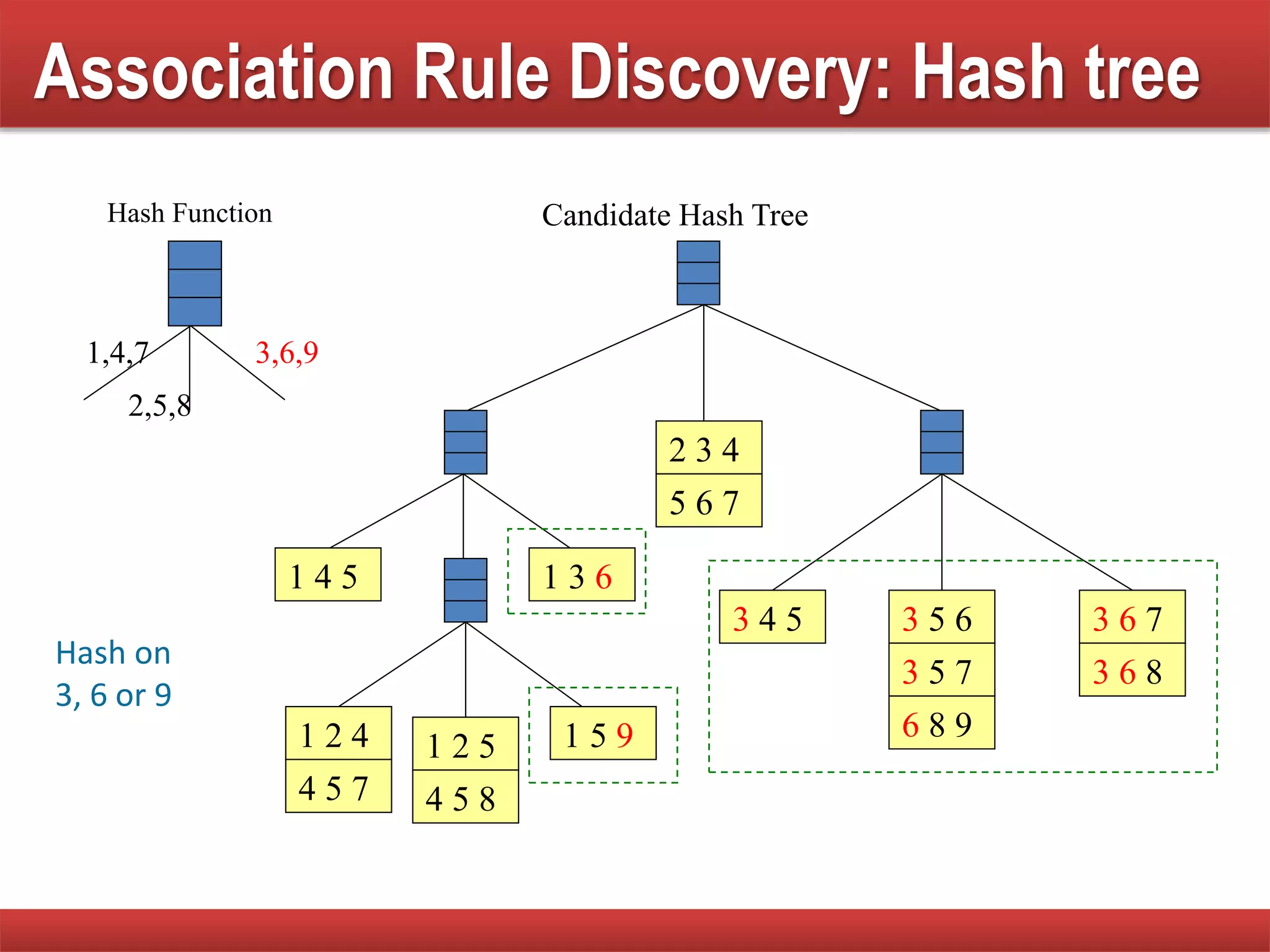
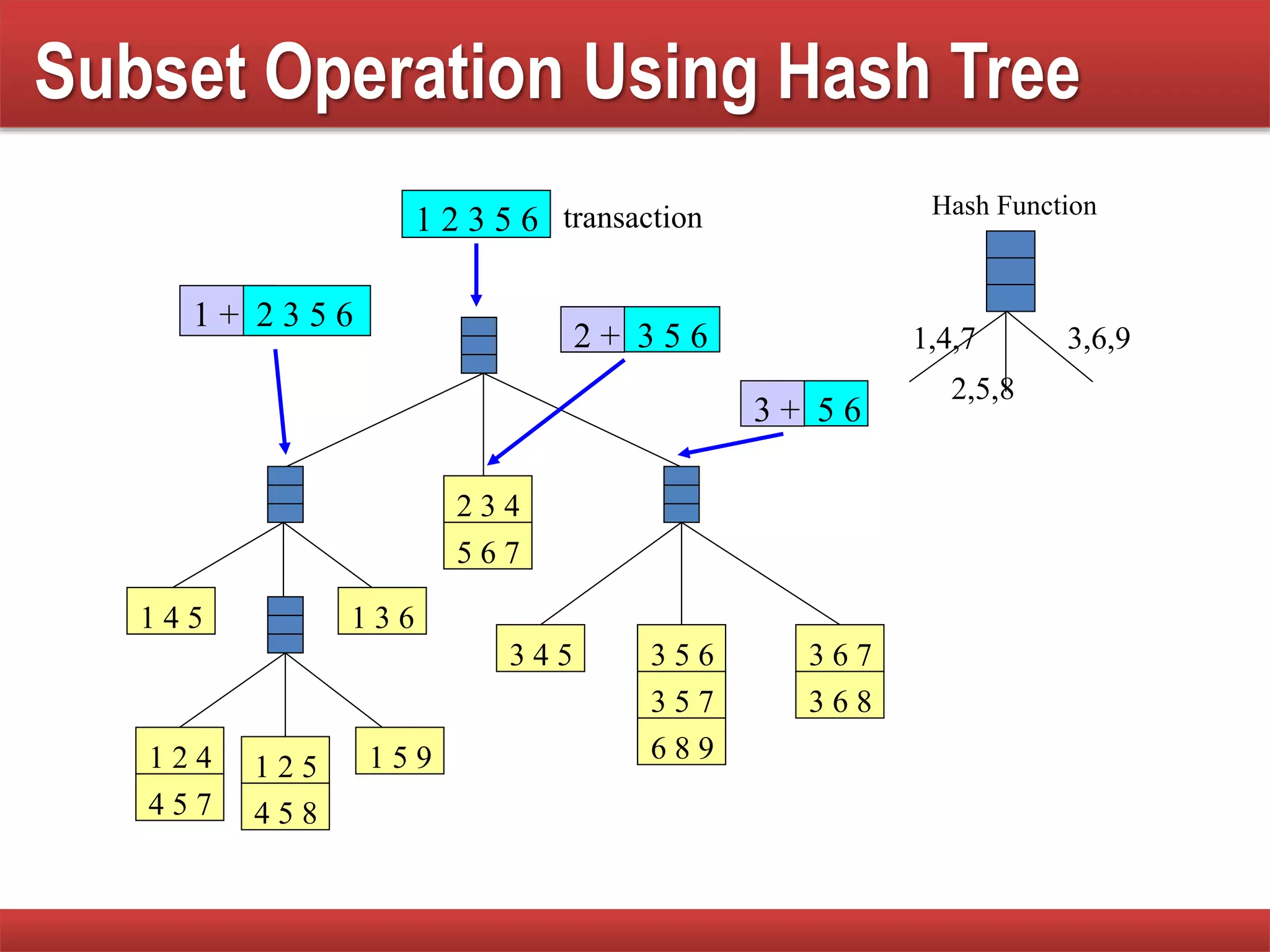
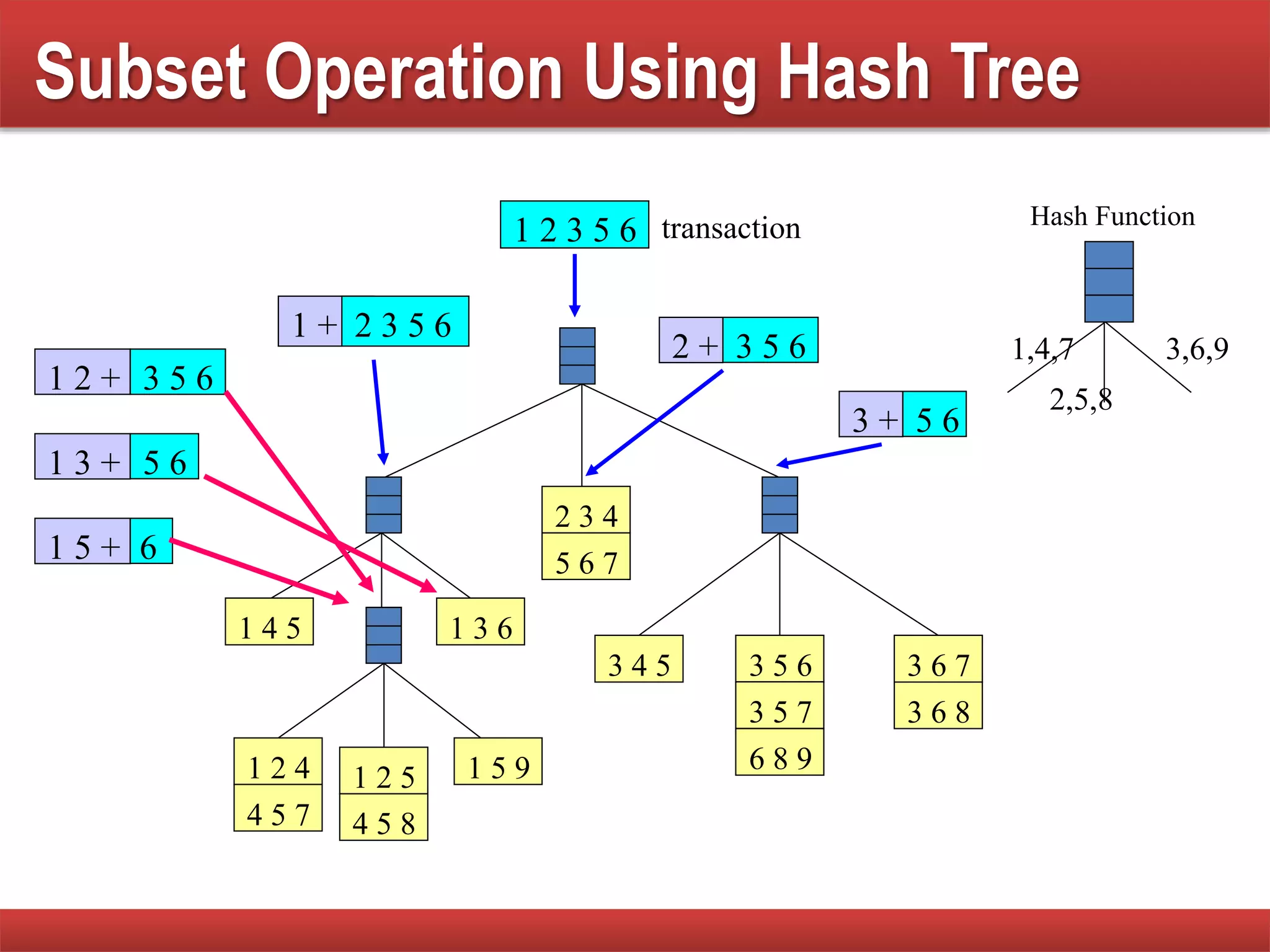
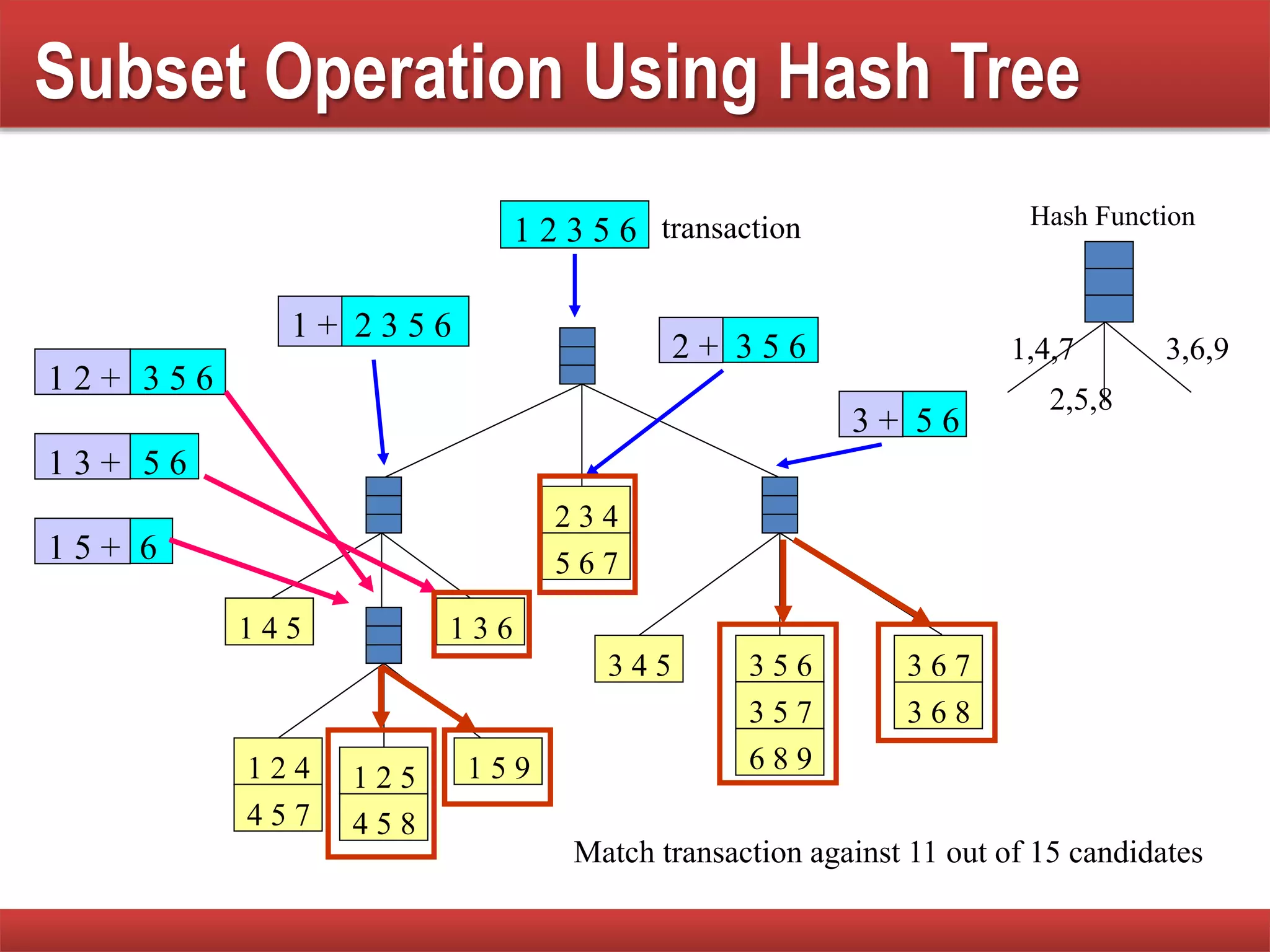
Techniques to reduce comparison costs by utilizing candidate counting and hash tree structures for efficiency.
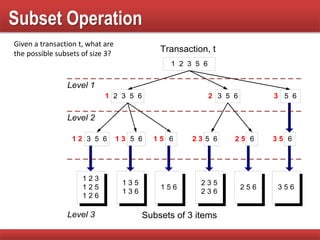
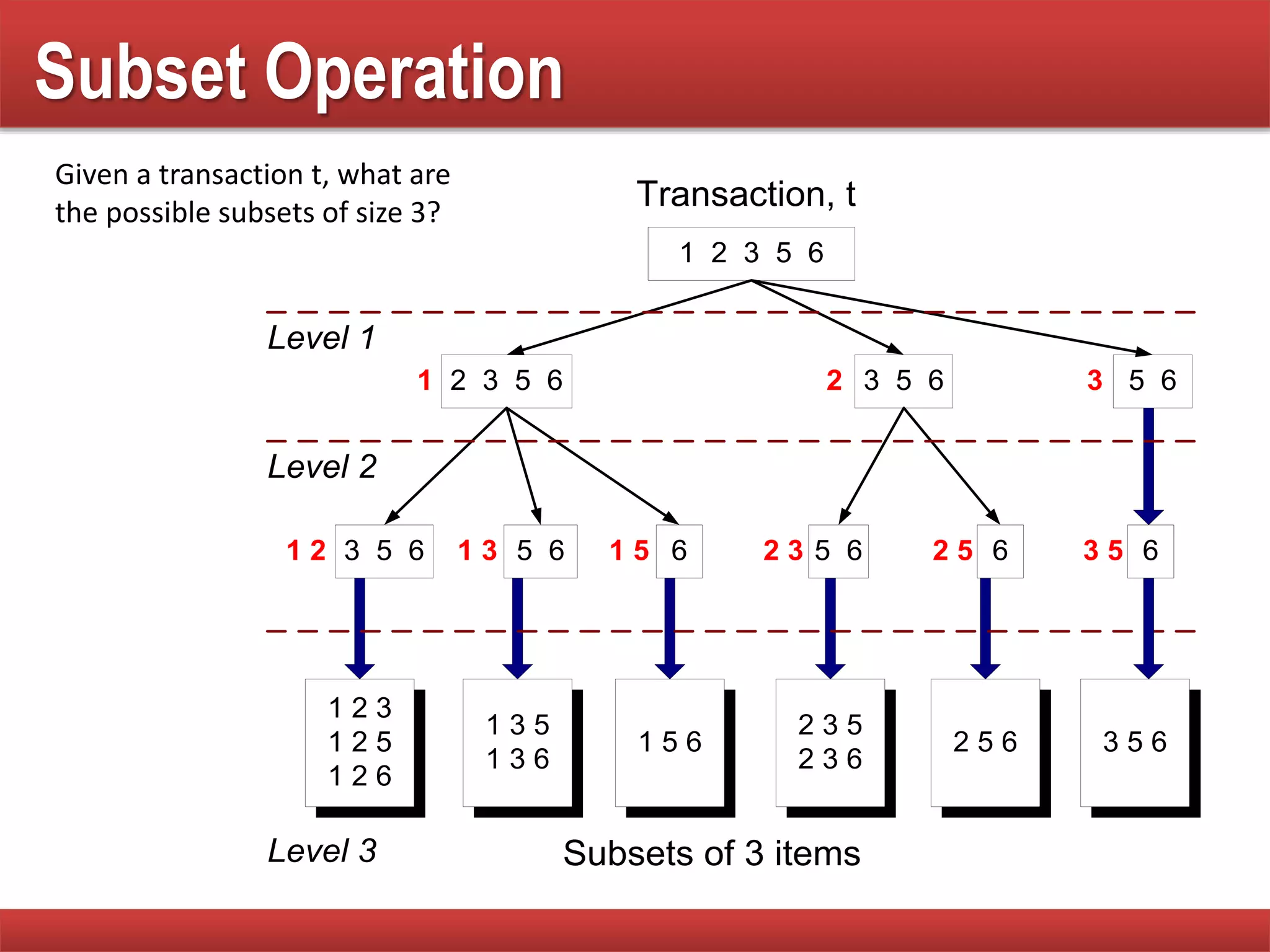
Explains subset operations using hash trees to optimize matching processes and improve mining efficiency.























































































