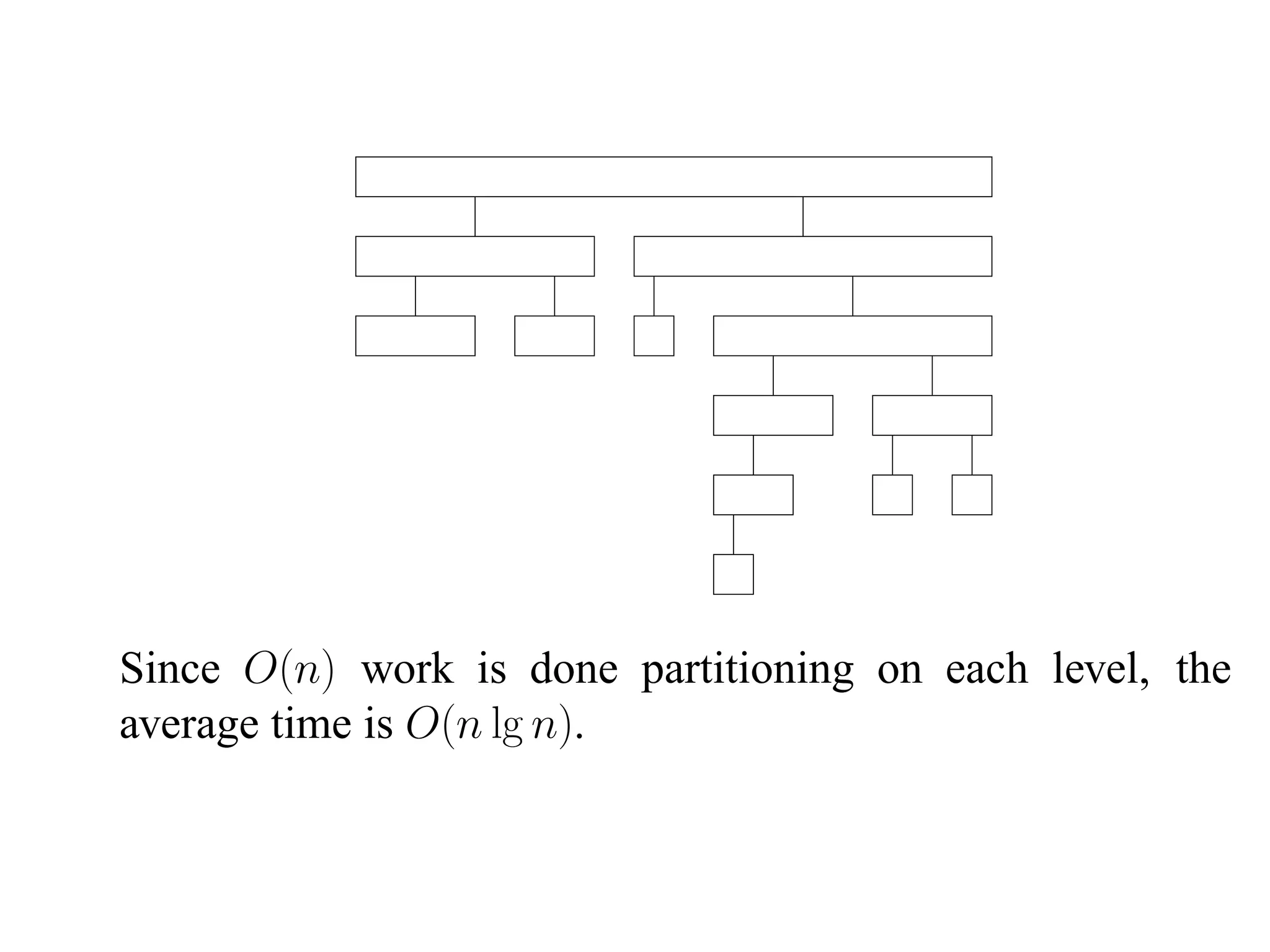
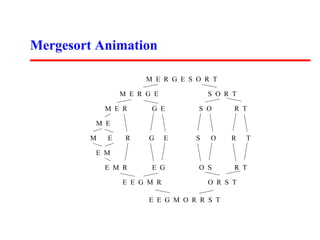
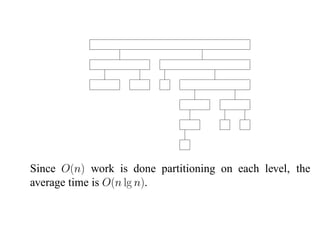
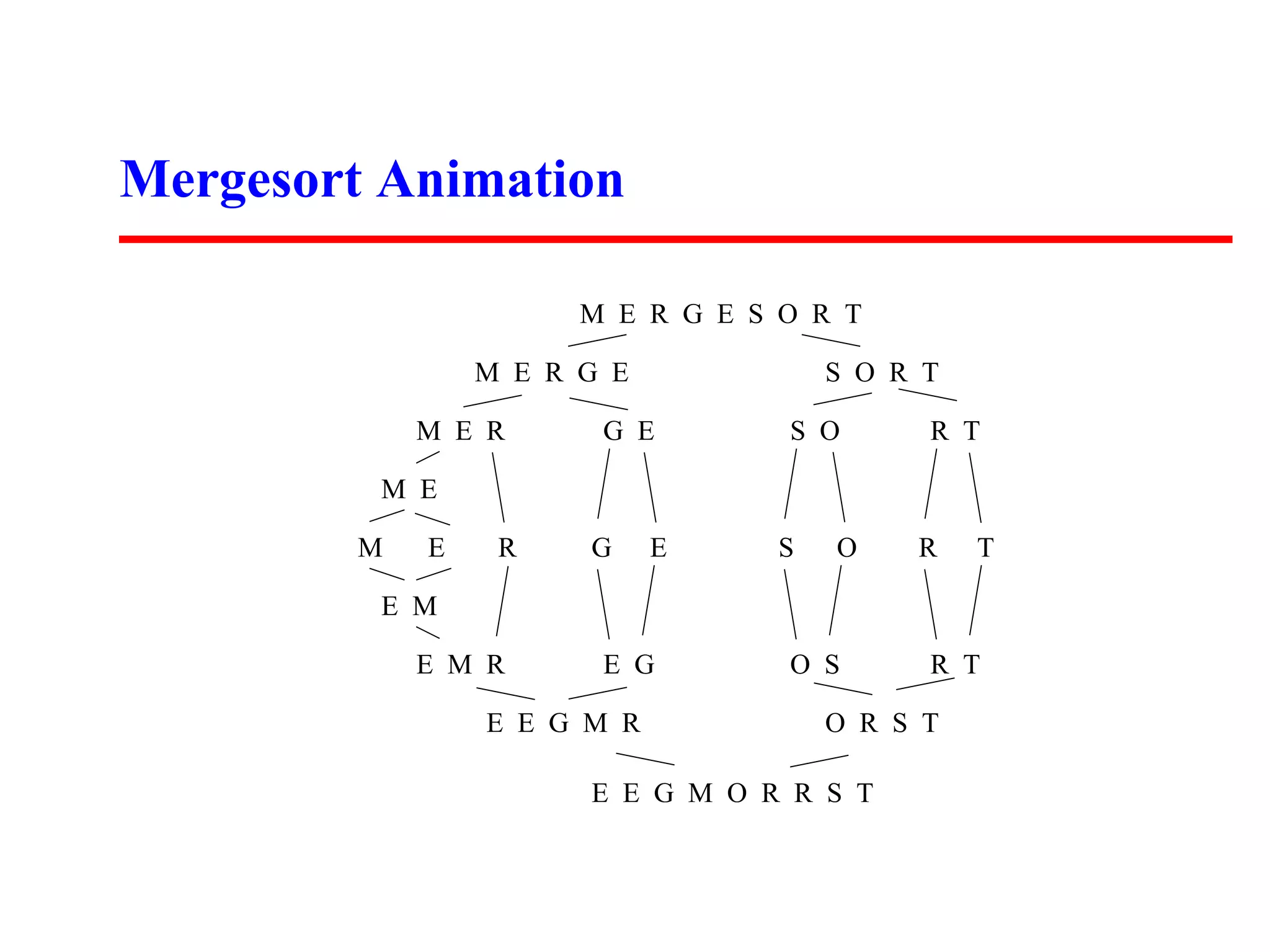
The document summarizes two sorting algorithms: Mergesort and Quicksort. Mergesort uses a divide and conquer approach, recursively splitting the list into halves and then merging the sorted halves. Quicksort uses a partitioning approach, choosing a pivot element and partitioning the list into elements less than and greater than the pivot. The average time complexity of Quicksort is O(n log n) while the worst case is O(n^2).




![Mergesort Implementation
mergesort(item type s[], int low, int high)
{
int i; (* counter *)
int middle; (* index of middle element *)
if (low < high) {
middle = (low+high)/2;
mergesort(s,low,middle);
mergesort(s,middle+1,high);
merge(s, low, middle, high);
}
}](https://image.slidesharecdn.com/skienaalgorithm2007lecture08quicksort-111212074919-phpapp01/85/Skiena-algorithm-2007-lecture08-quicksort-5-320.jpg)








![Partition Implementation
Partition(A,low,high)
pivot = A[low]
leftwall = low
for i = low+1 to high
if (A[i] < pivot) then
leftwall = leftwall+1
swap(A[i],A[leftwall])
swap(A[low],A[leftwall])](https://image.slidesharecdn.com/skienaalgorithm2007lecture08quicksort-111212074919-phpapp01/85/Skiena-algorithm-2007-lecture08-quicksort-15-320.jpg)




















![Mergesort Implementation
mergesort(item type s[], int low, int high)
{
int i; (* counter *)
int middle; (* index of middle element *)
if (low < high) {
middle = (low+high)/2;
mergesort(s,low,middle);
mergesort(s,middle+1,high);
merge(s, low, middle, high);
}
}](https://image.slidesharecdn.com/skienaalgorithm2007lecture08quicksort-111212074919-phpapp01/75/Skiena-algorithm-2007-lecture08-quicksort-5-2048.jpg)








![Partition Implementation
Partition(A,low,high)
pivot = A[low]
leftwall = low
for i = low+1 to high
if (A[i] < pivot) then
leftwall = leftwall+1
swap(A[i],A[leftwall])
swap(A[low],A[leftwall])](https://image.slidesharecdn.com/skienaalgorithm2007lecture08quicksort-111212074919-phpapp01/75/Skiena-algorithm-2007-lecture08-quicksort-15-2048.jpg)