4
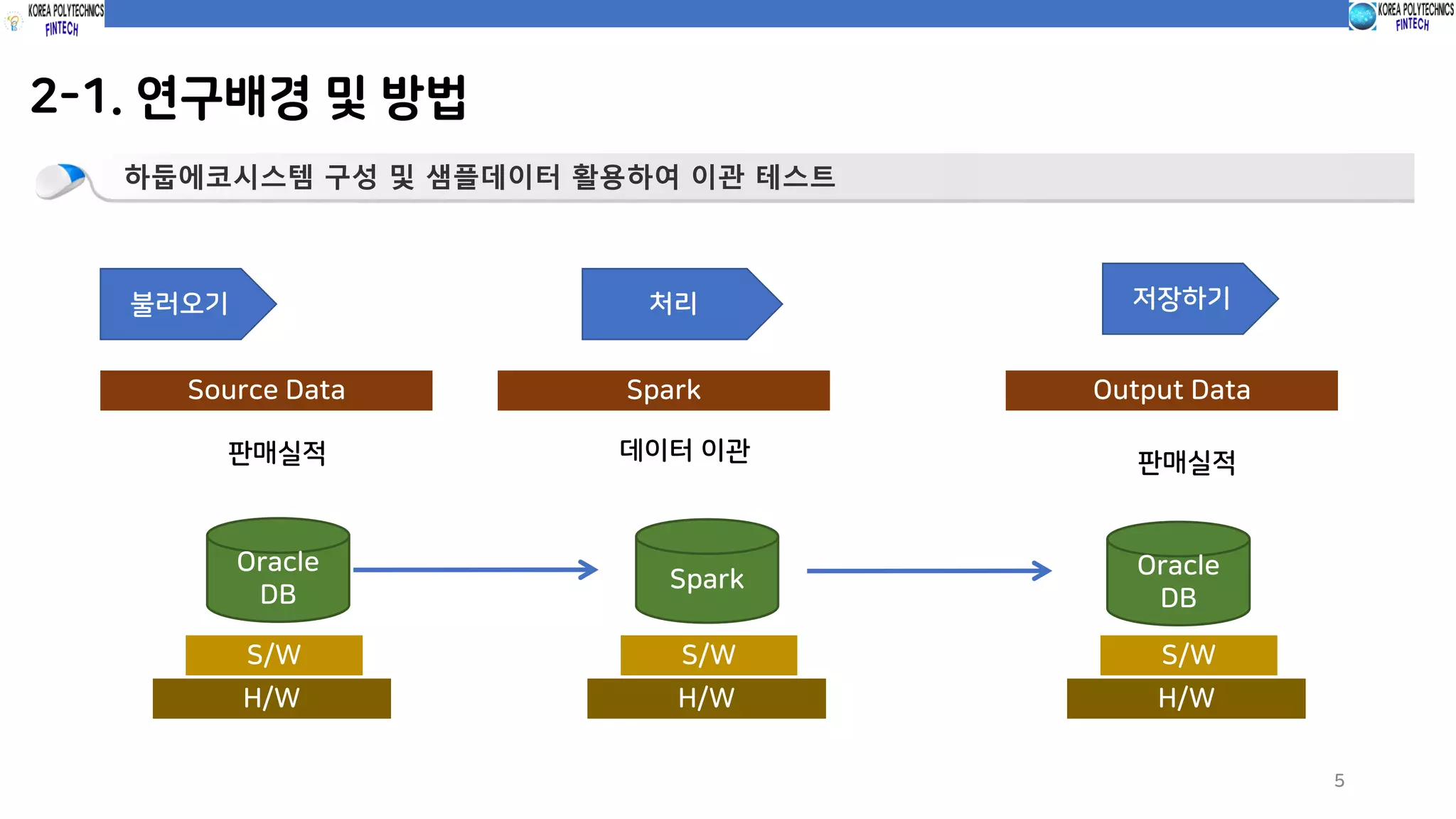
2-1. 연구배경 및방법
하둡에코시스템 구성 및 샘플데이터 활용하여 이관 테스트
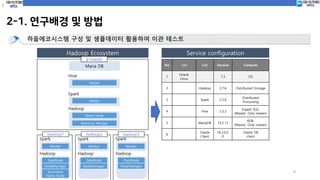
Hadoop
Name Node
Spark
Master
Hive
Master
Resource Manger
No Lv1 Lv2 Version Contents
1
Oracle
Linux
7.3 OS
2 Hadoop 2.7.6 Distributed Storage
3 Spark 2.2.0
Distributed
Processing
4 Hive 2.3.3
Supprt SQL
(Master, Only master)
5 MariaDB 10.2.11
RDB
(Master, Only master)
6
Oracle
Client
18.3.0.0.
0
Oracle DB
client
Maria DB
Hadoop
DataNode
Spark
Worker
NodeManager
Hadoop
DataNode
Spark
Worker
NodeManager
Hadoop
DataNode
Spark
Worker
NodeManager
Service configurationHadoop Ecosystem
Secondary
Name Node
p-master
hadoop1 hadoop2 hadoop3
5.
5
2-1. 연구배경 및방법
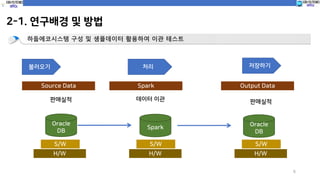
하둡에코시스템 구성 및 샘플데이터 활용하여 이관 테스트
불러오기 처리 저장하기
Source Data Spark Output Data
판매실적 데이터 이관 판매실적
Oracle
DB
Spark
Oracle
DB
S/W
H/W
S/W
H/W
S/W
H/W
6.
6
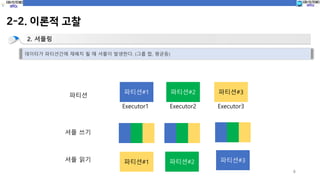
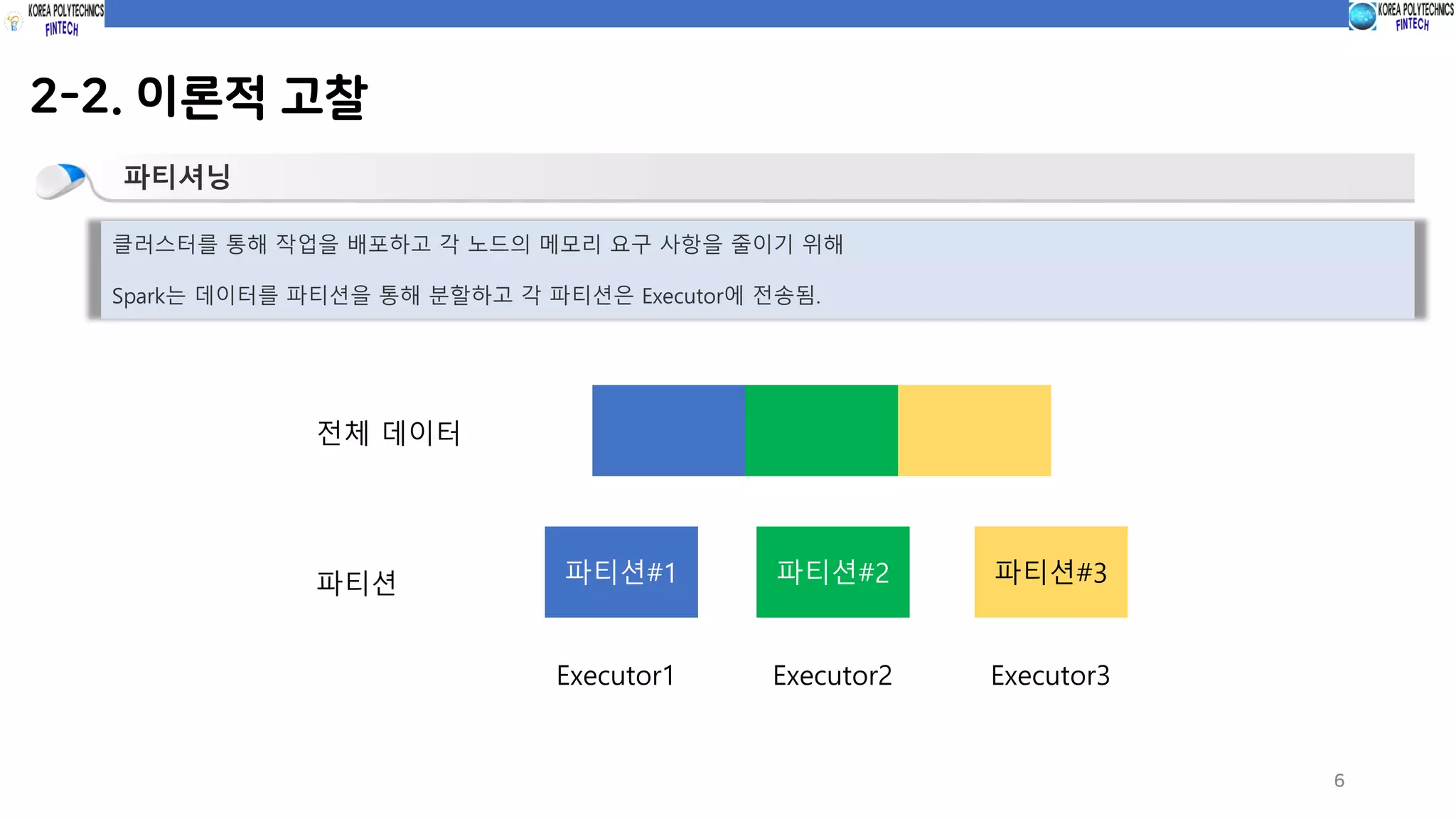
2-2. 이론적 고찰
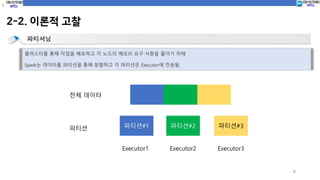
파티셔닝
클러스터를통해 작업을 배포하고 각 노드의 메모리 요구 사항을 줄이기 위해
Spark는 데이터를 파티션을 통해 분할하고 각 파티션은 Executor에 전송됨.
전체 데이터
파티션 파티션#1 파티션#2 파티션#3
Executor1 Executor2 Executor3
7.
7
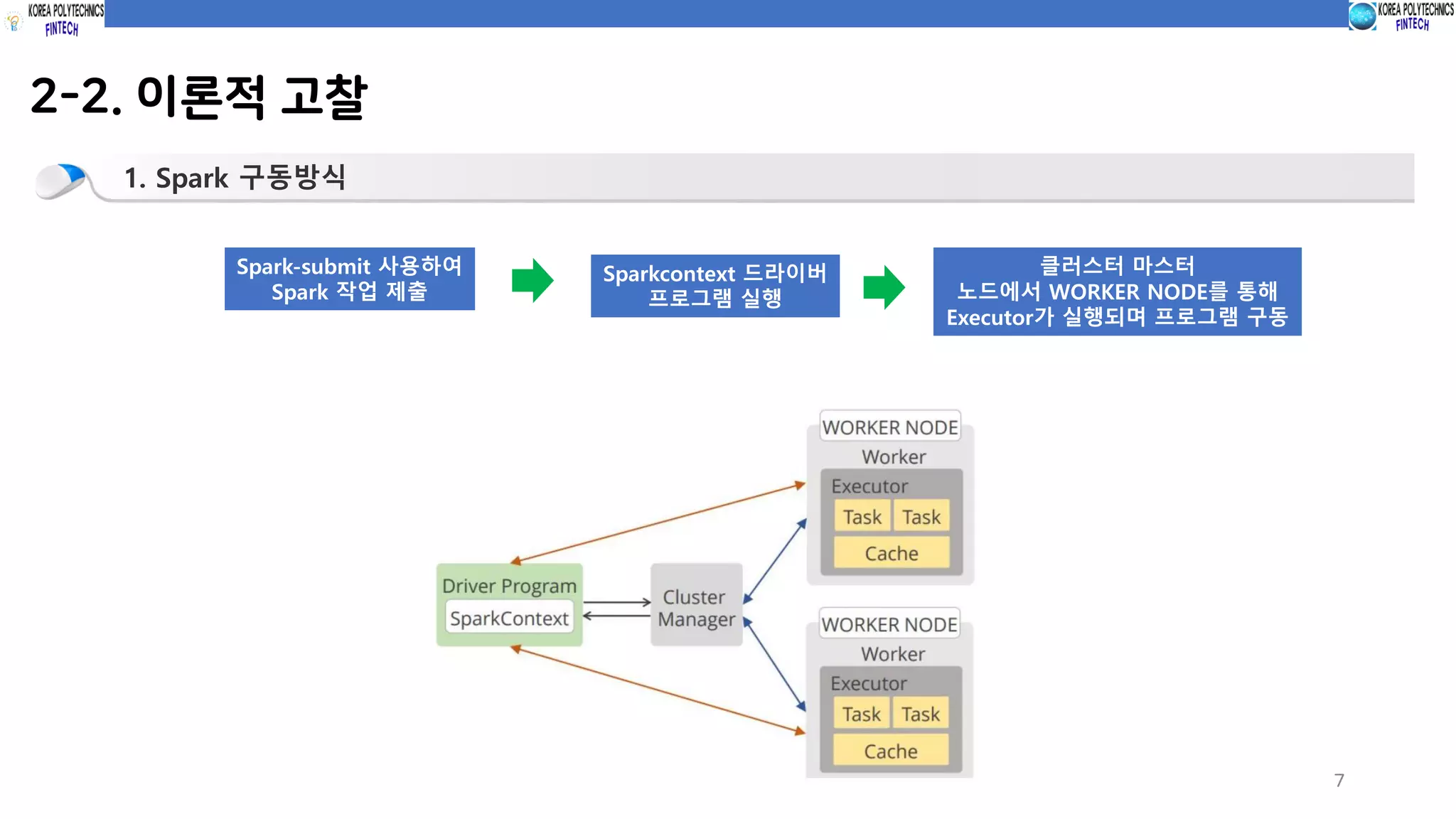
2-2. 이론적 고찰
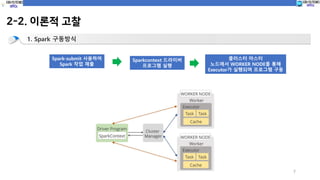
1.Spark 구동방식
Spark-submit 사용하여
Spark 작업 제출
Sparkcontext 드라이버
프로그램 실행
클러스터 마스터
노드에서 WORKER NODE를 통해
Executor가 실행되며 프로그램 구동
8.
8
2-2. 이론적 고찰
2.셔플링
데이터가 파티션간에 재배치 될 때 셔플이 발생한다. (그룹 합, 평균등)
파티션
셔플 쓰기
파티션#1 파티션#2 파티션#3
Executor1 Executor2 Executor3
파티션#1 파티션#2 파티션#3셔플 읽기
9.
9
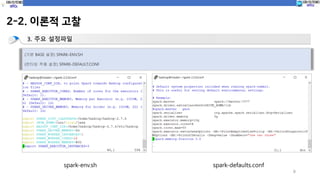
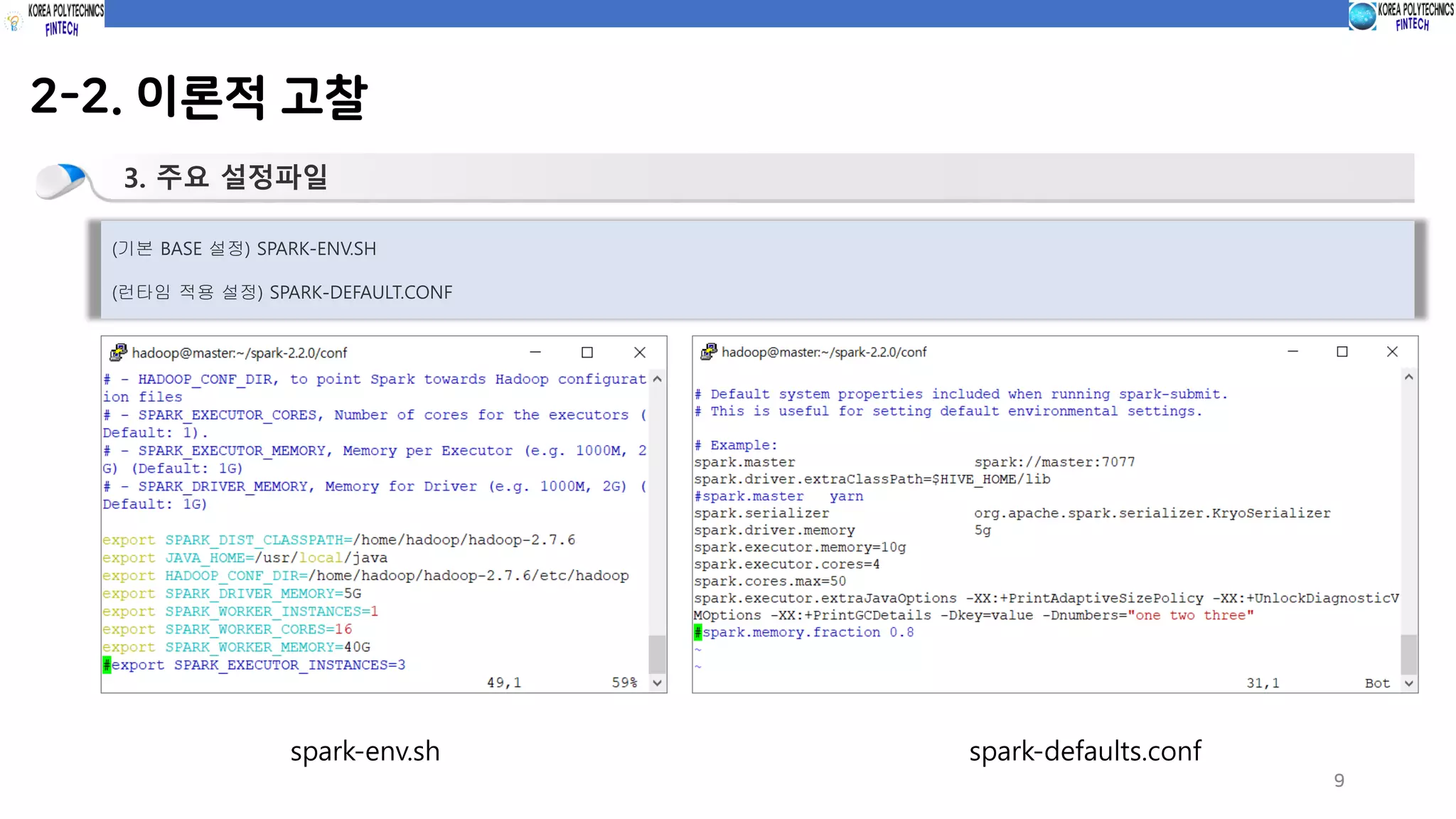
2-2. 이론적 고찰
3.주요 설정파일
(기본 BASE 설정) SPARK-ENV.SH
(런타임 적용 설정) SPARK-DEFAULT.CONF
spark-env.sh spark-defaults.conf
10.
10
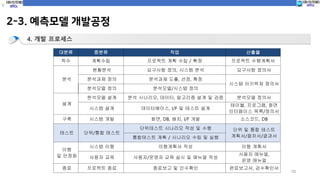
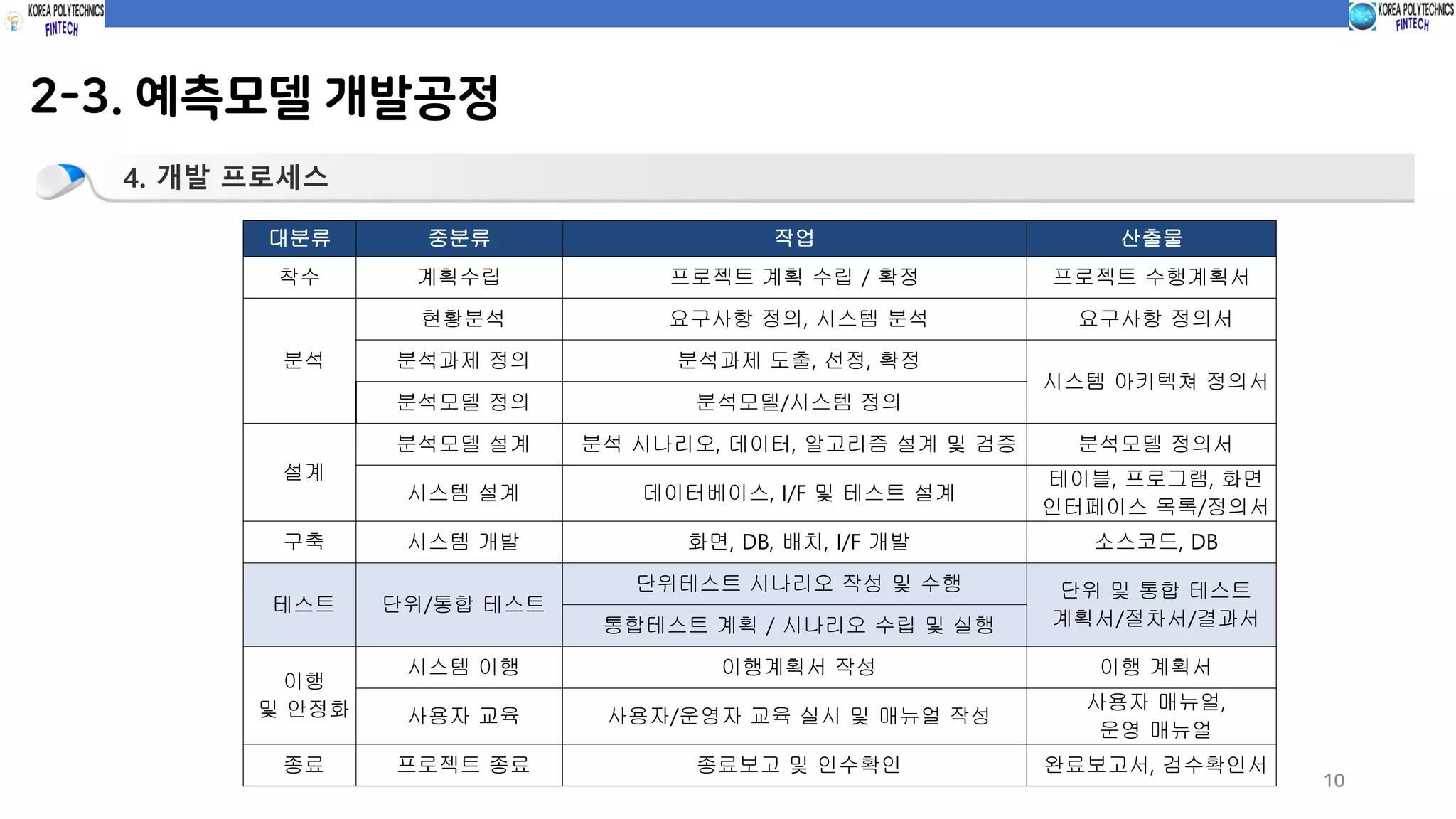
2-3. 예측모델 개발공정
4.개발 프로세스
대분류 중분류 작업 산출물
착수 계획수립 프로젝트 계획 수립 / 확정 프로젝트 수행계획서
분석
현황분석 요구사항 정의, 시스템 분석 요구사항 정의서
분석과제 정의 분석과제 도출, 선정, 확정
시스템 아키텍쳐 정의서
분석모델 정의 분석모델/시스템 정의
설계
분석모델 설계 분석 시나리오, 데이터, 알고리즘 설계 및 검증 분석모델 정의서
시스템 설계 데이터베이스, I/F 및 테스트 설계
테이블, 프로그램, 화면
인터페이스 목록/정의서
구축 시스템 개발 화면, DB, 배치, I/F 개발 소스코드, DB
테스트 단위/통합 테스트
단위테스트 시나리오 작성 및 수행 단위 및 통합 테스트
계획서/절차서/결과서통합테스트 계획 / 시나리오 수립 및 실행
이행
및 안정화
시스템 이행 이행계획서 작성 이행 계획서
사용자 교육 사용자/운영자 교육 실시 및 매뉴얼 작성
사용자 매뉴얼,
운영 매뉴얼
종료 프로젝트 종료 종료보고 및 인수확인 완료보고서, 검수확인서
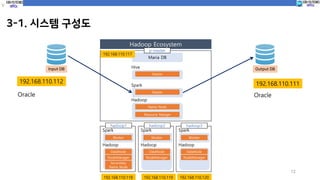
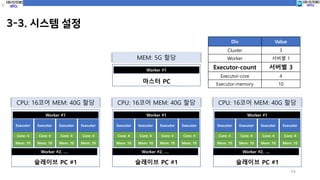
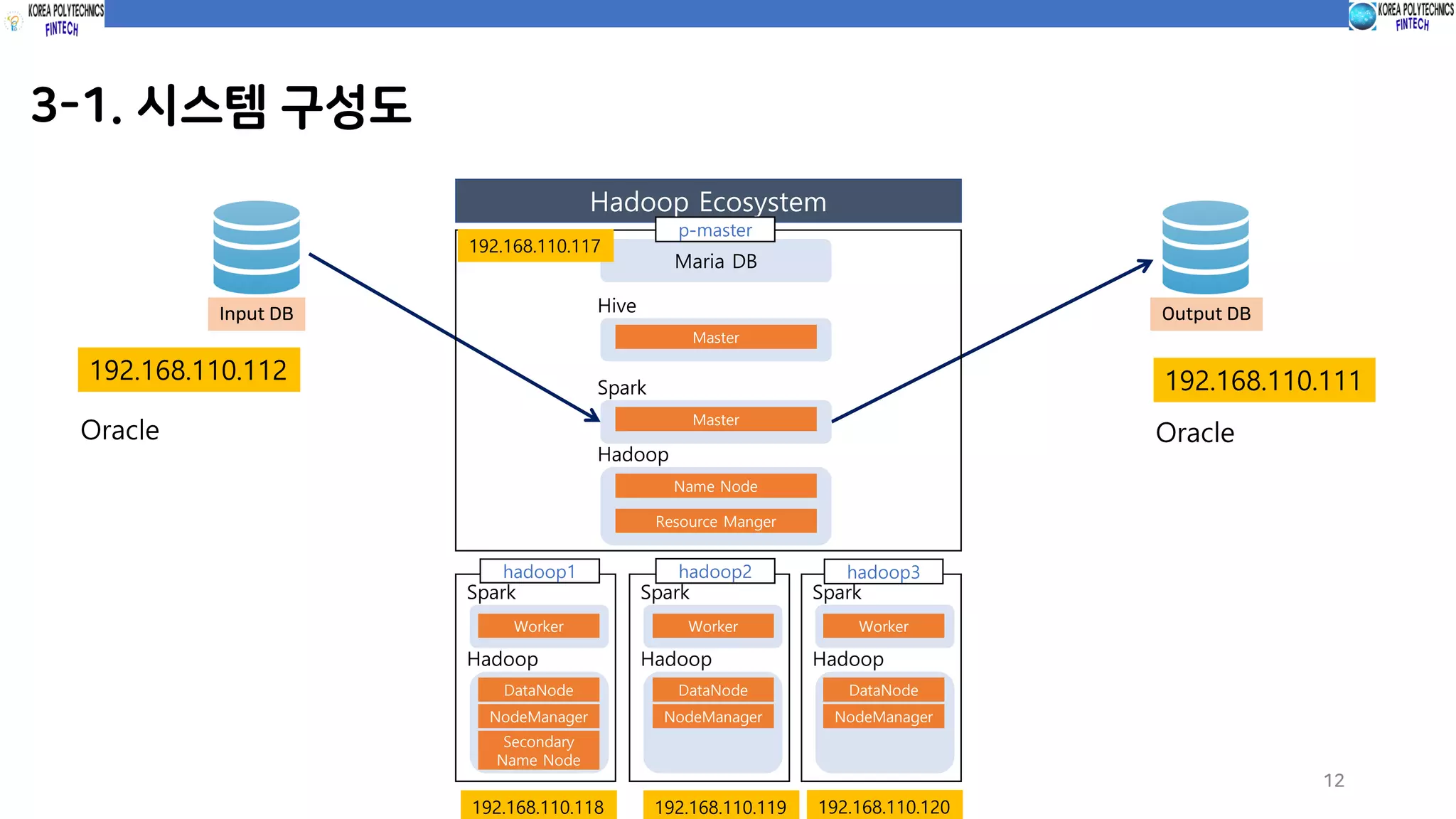
3-1. 시스템 구성도
12
InputDB Output DB
192.168.110.112 192.168.110.111
Hadoop
Name Node
Spark
Master
Hive
Master
Resource Manger
Maria DB
Hadoop
DataNode
Spark
Worker
NodeManager
Hadoop
DataNode
Spark
Worker
NodeManager
Hadoop
DataNode
Spark
Worker
NodeManager
Hadoop Ecosystem
Secondary
Name Node
p-master
hadoop1 hadoop2 hadoop3
192.168.110.117
192.168.110.118 192.168.110.119 192.168.110.120
Oracle Oracle
13.
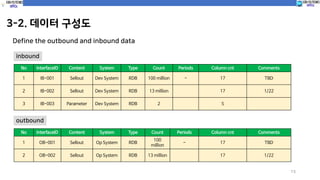
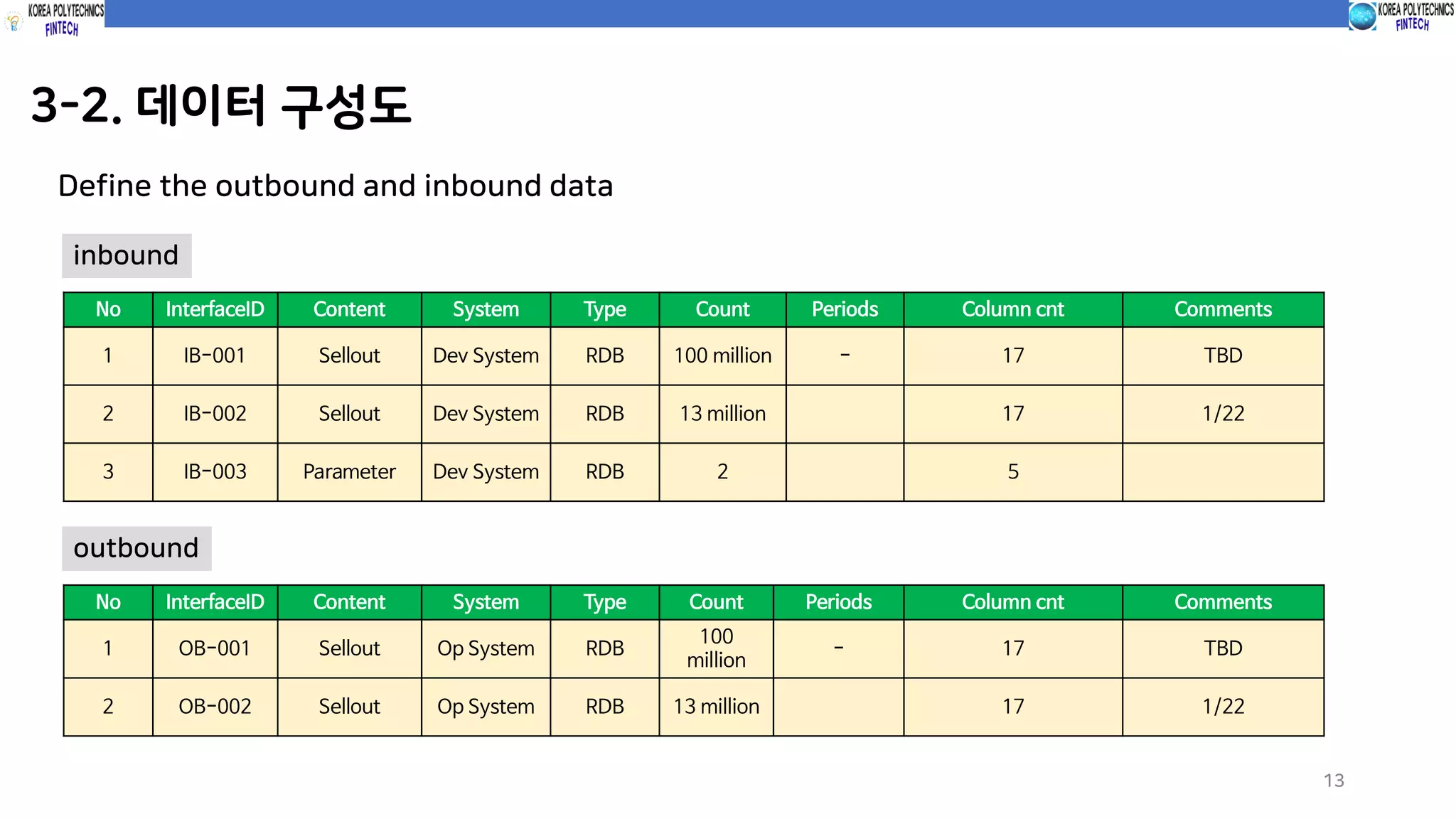
3-2. 데이터 구성도
13
Definethe outbound and inbound data
No InterfaceID Content System Type Count Periods Column cnt Comments
1 IB-001 Sellout Dev System RDB 100 million - 17 TBD
2 IB-002 Sellout Dev System RDB 13 million 17 1/22
3 IB-003 Parameter Dev System RDB 2 5
inbound
No InterfaceID Content System Type Count Periods Column cnt Comments
1 OB-001 Sellout Op System RDB
100
million
- 17 TBD
2 OB-002 Sellout Op System RDB 13 million 17 1/22
outbound
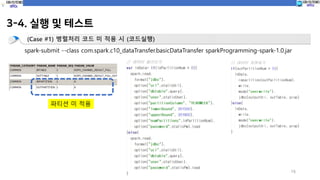
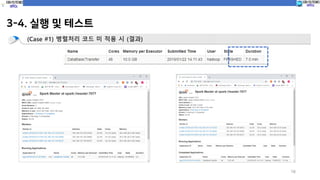
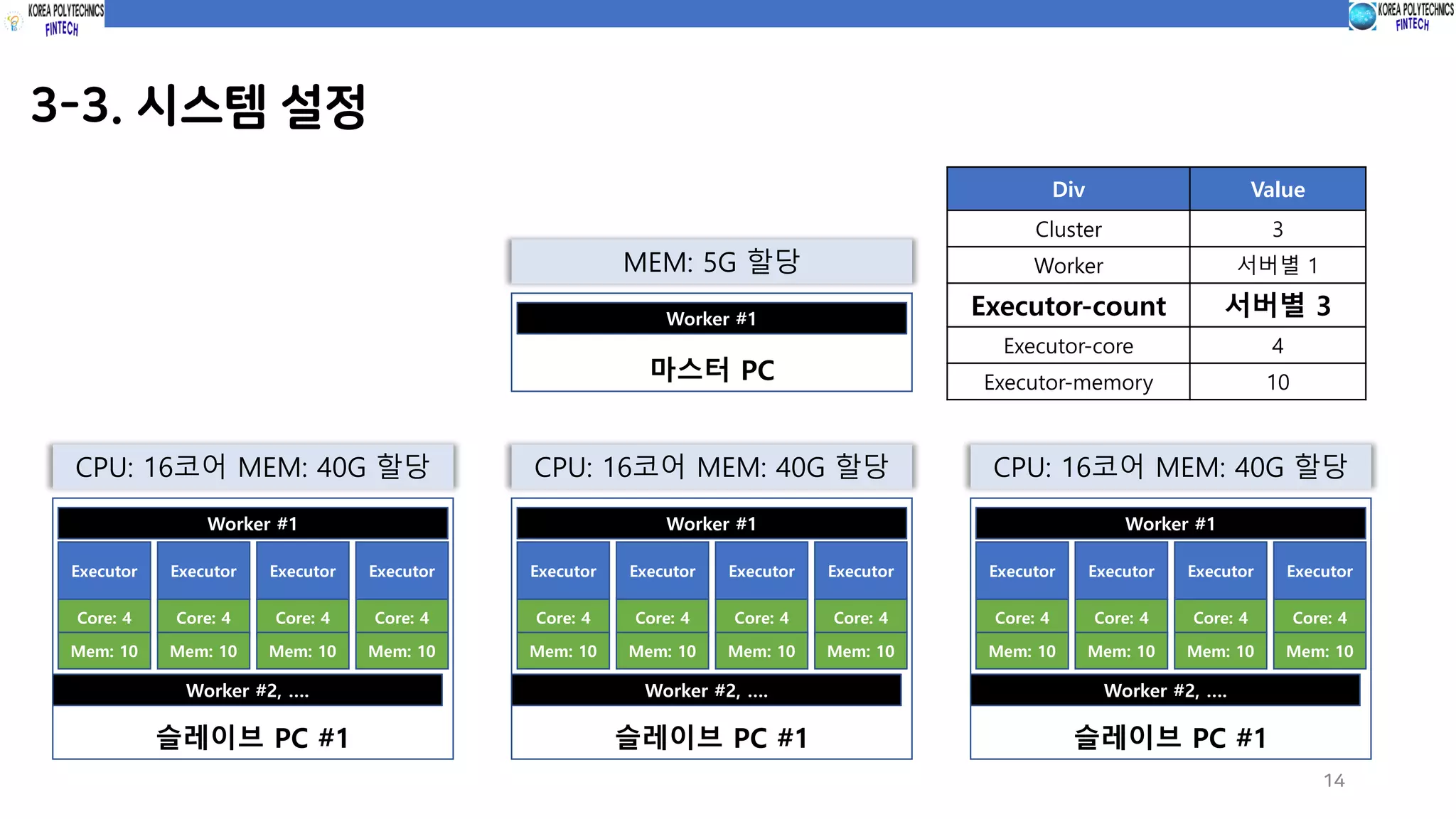
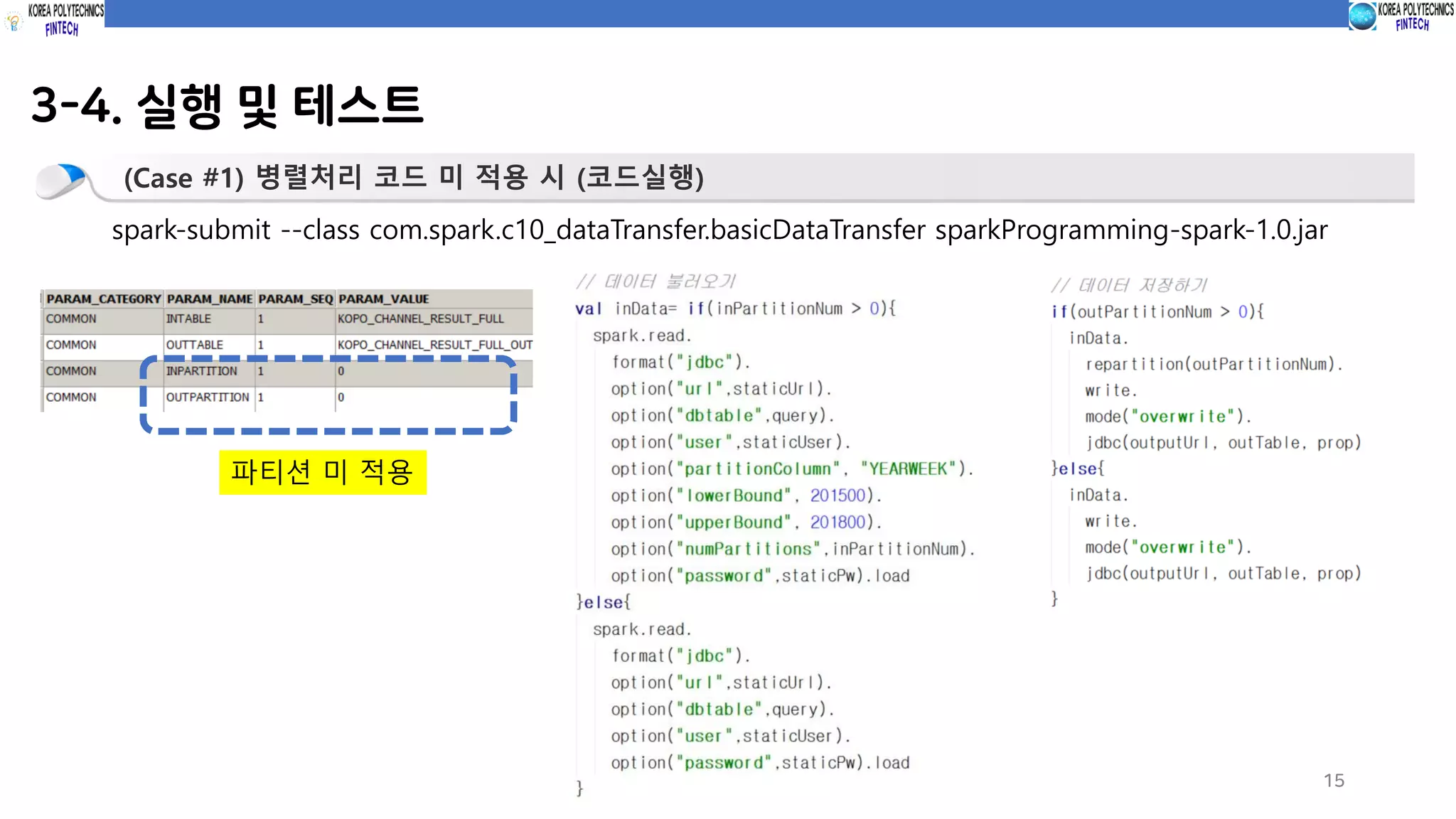
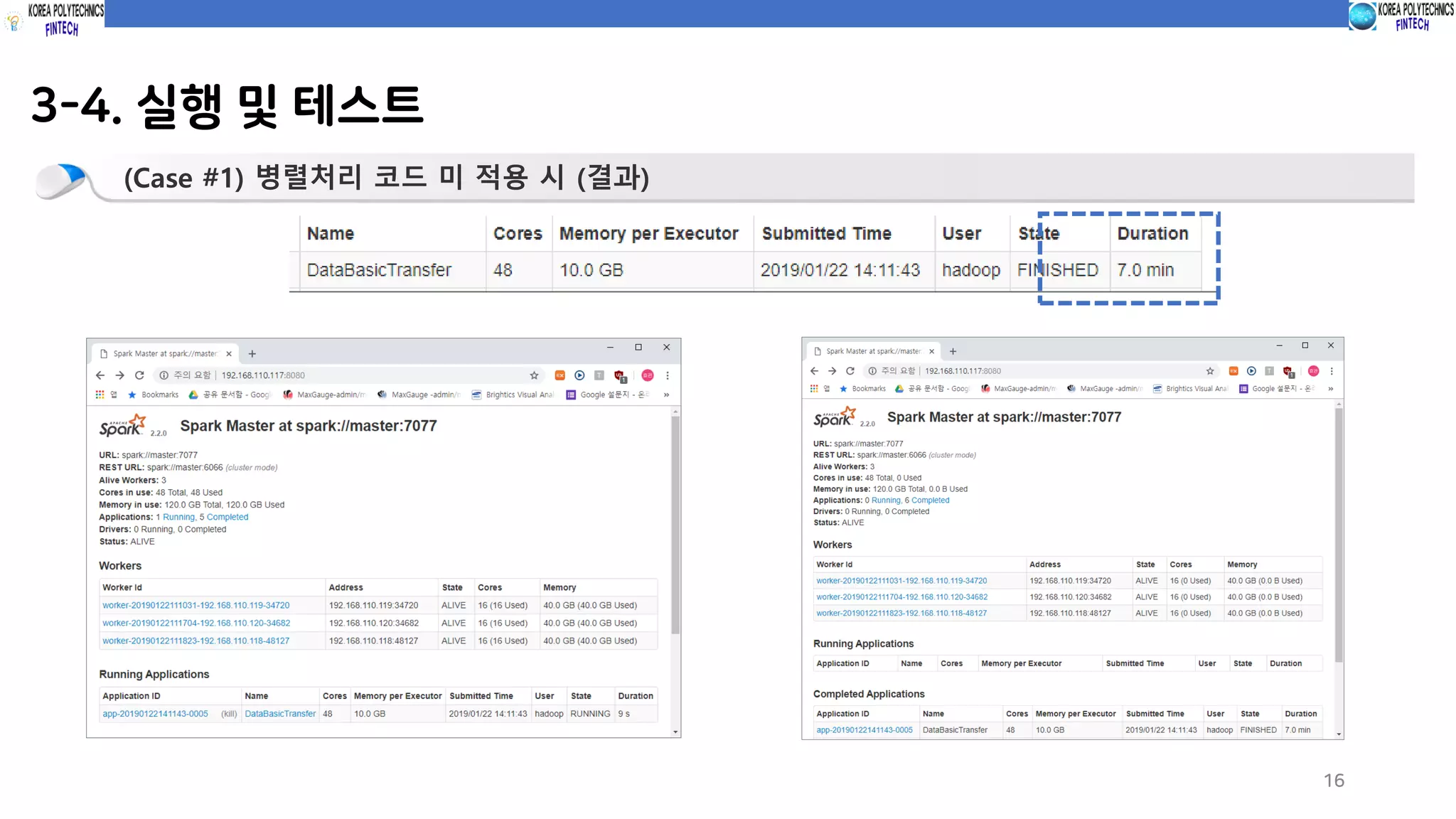
3-4. 실행 및테스트
15
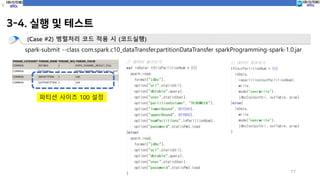
(Case #1) 병렬처리 코드 미 적용 시 (코드실행)
spark-submit --class com.spark.c10_dataTransfer.basicDataTransfer sparkProgramming-spark-1.0.jar
파티션 미 적용
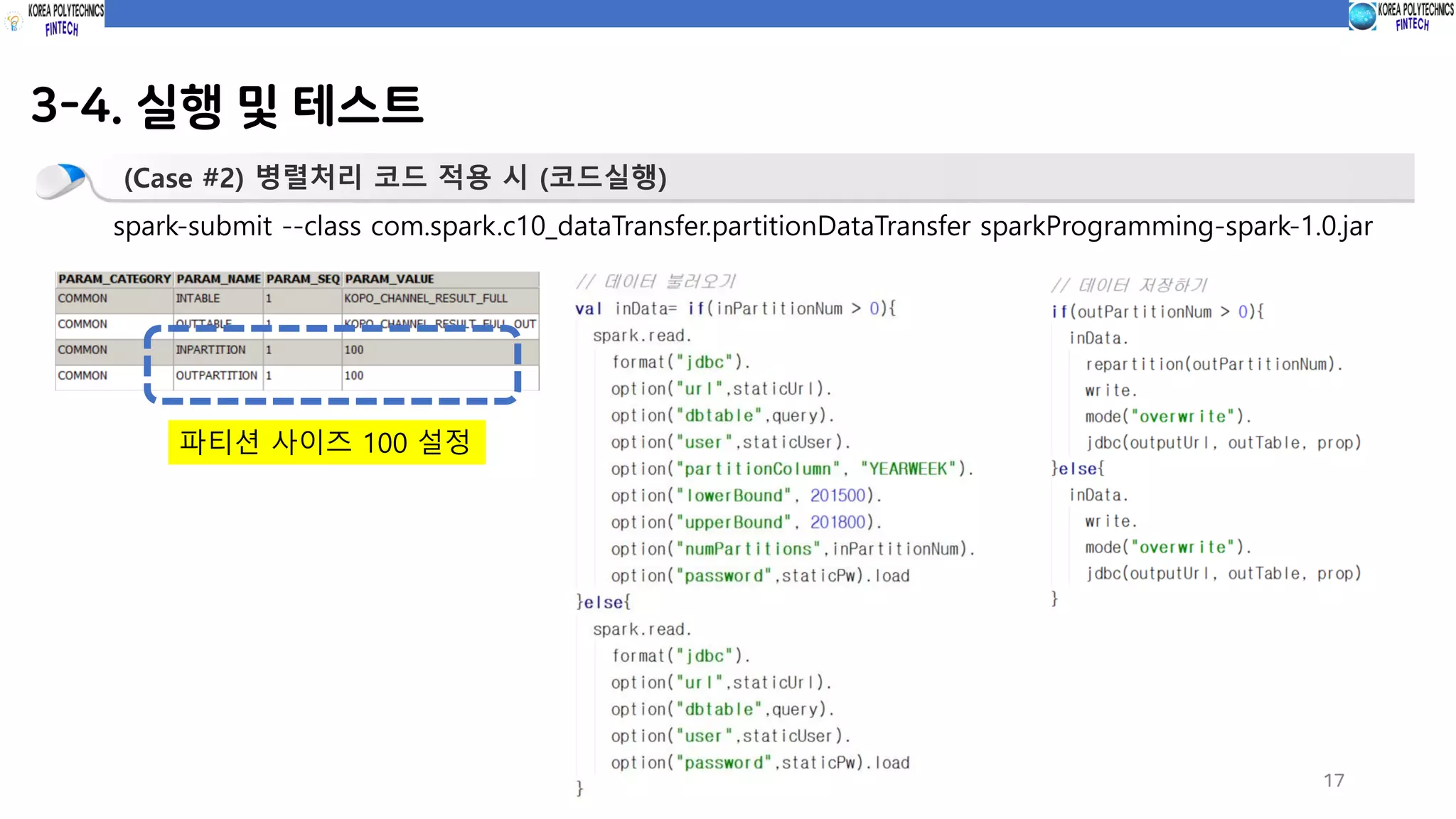
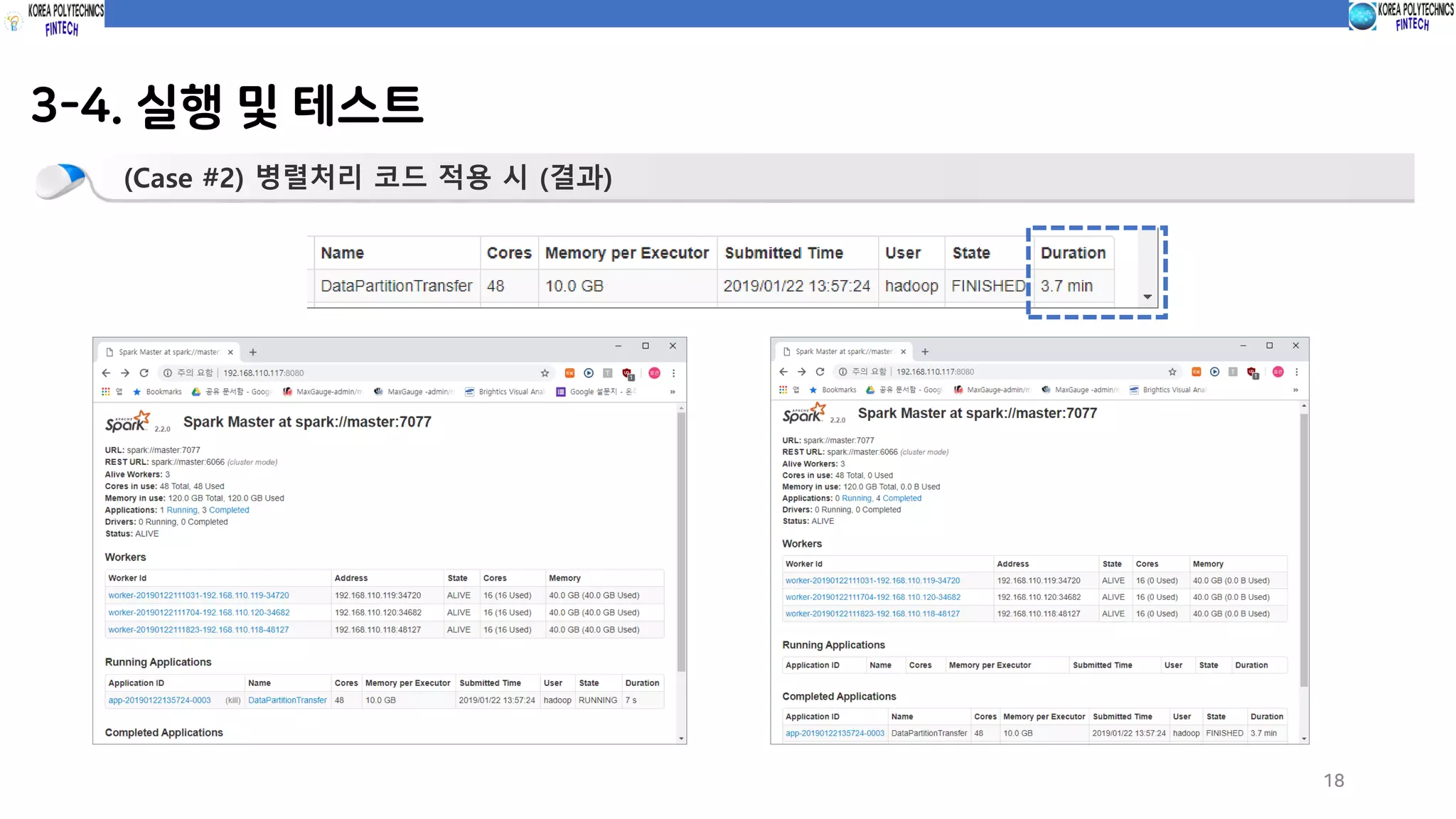
3-4. 실행 및테스트
17
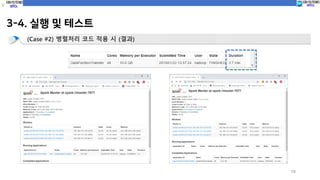
(Case #2) 병렬처리 코드 적용 시 (코드실행)
spark-submit --class com.spark.c10_dataTransfer.partitionDataTransfer sparkProgramming-spark-1.0.jar
파티션 사이즈 100 설정
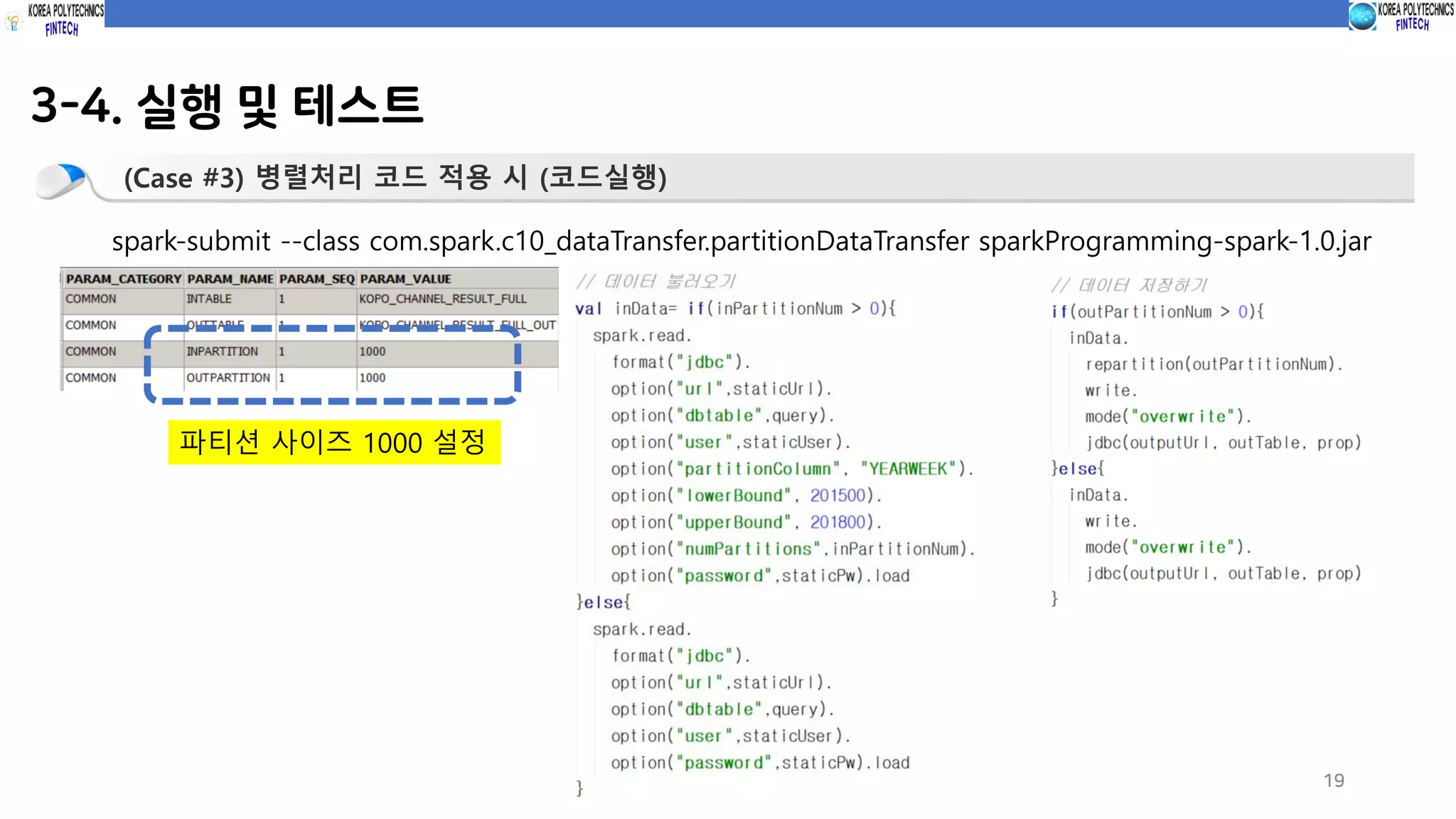
3-4. 실행 및테스트
19
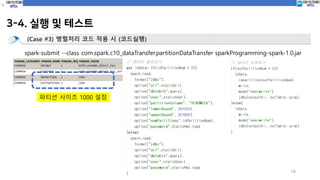
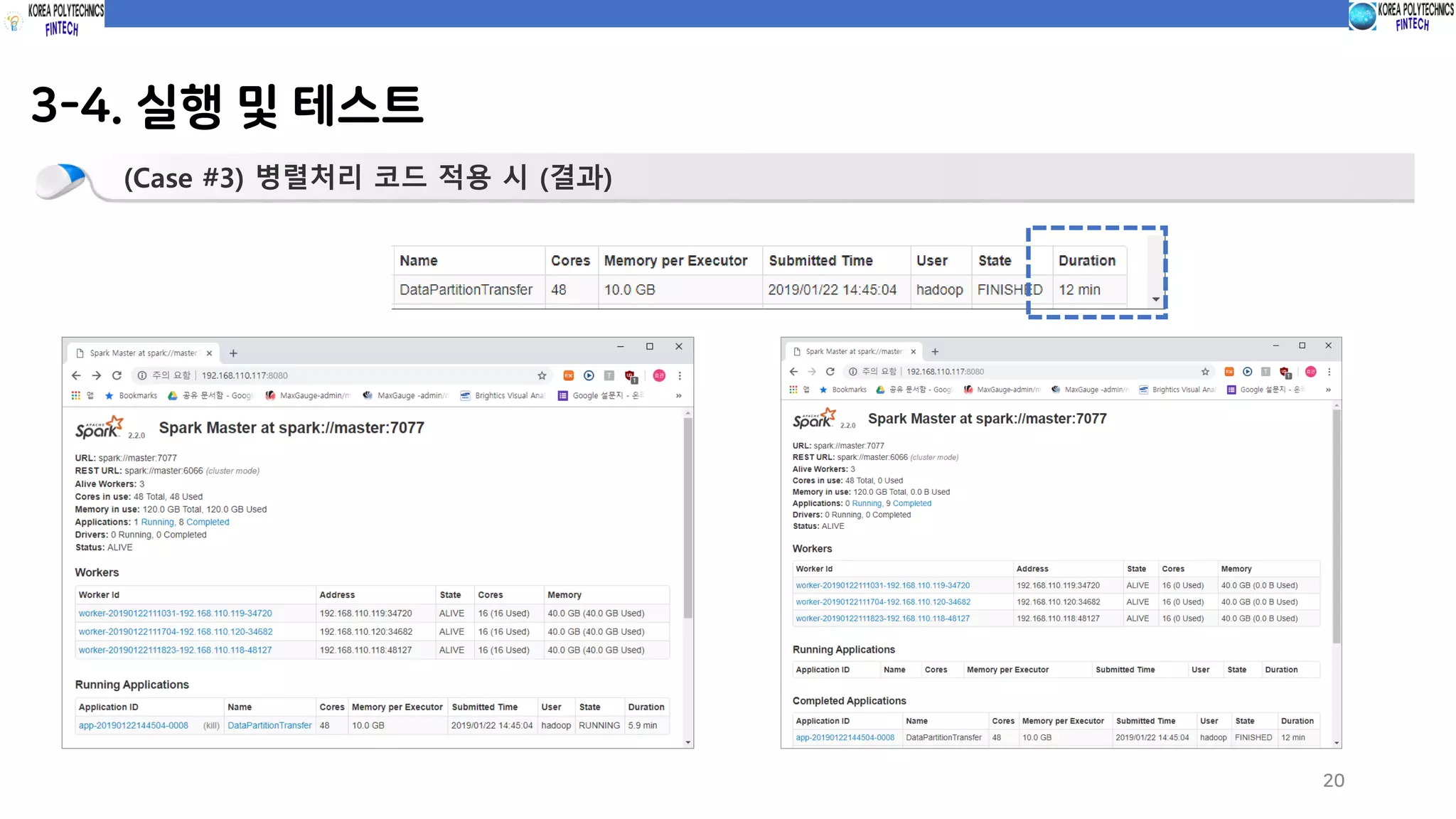
(Case #3) 병렬처리 코드 적용 시 (코드실행)
spark-submit --class com.spark.c10_dataTransfer.partitionDataTransfer sparkProgramming-spark-1.0.jar
파티션 사이즈 1000 설정
3-4. 실행 및테스트
21
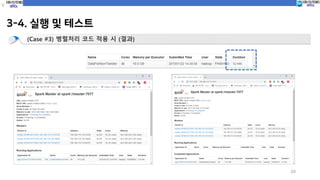
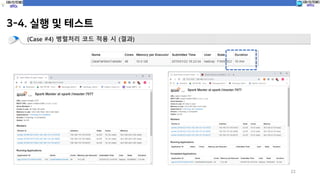
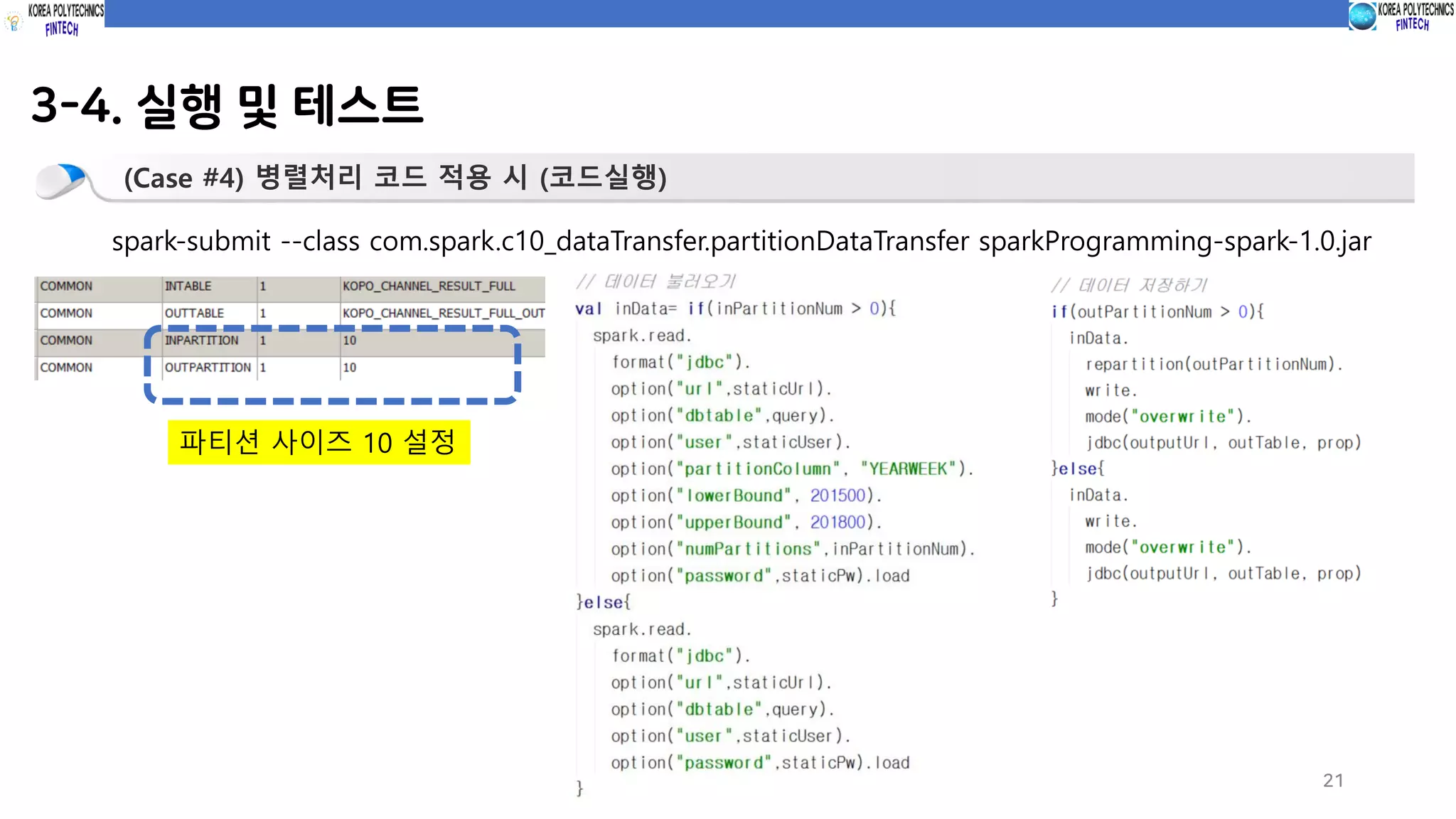
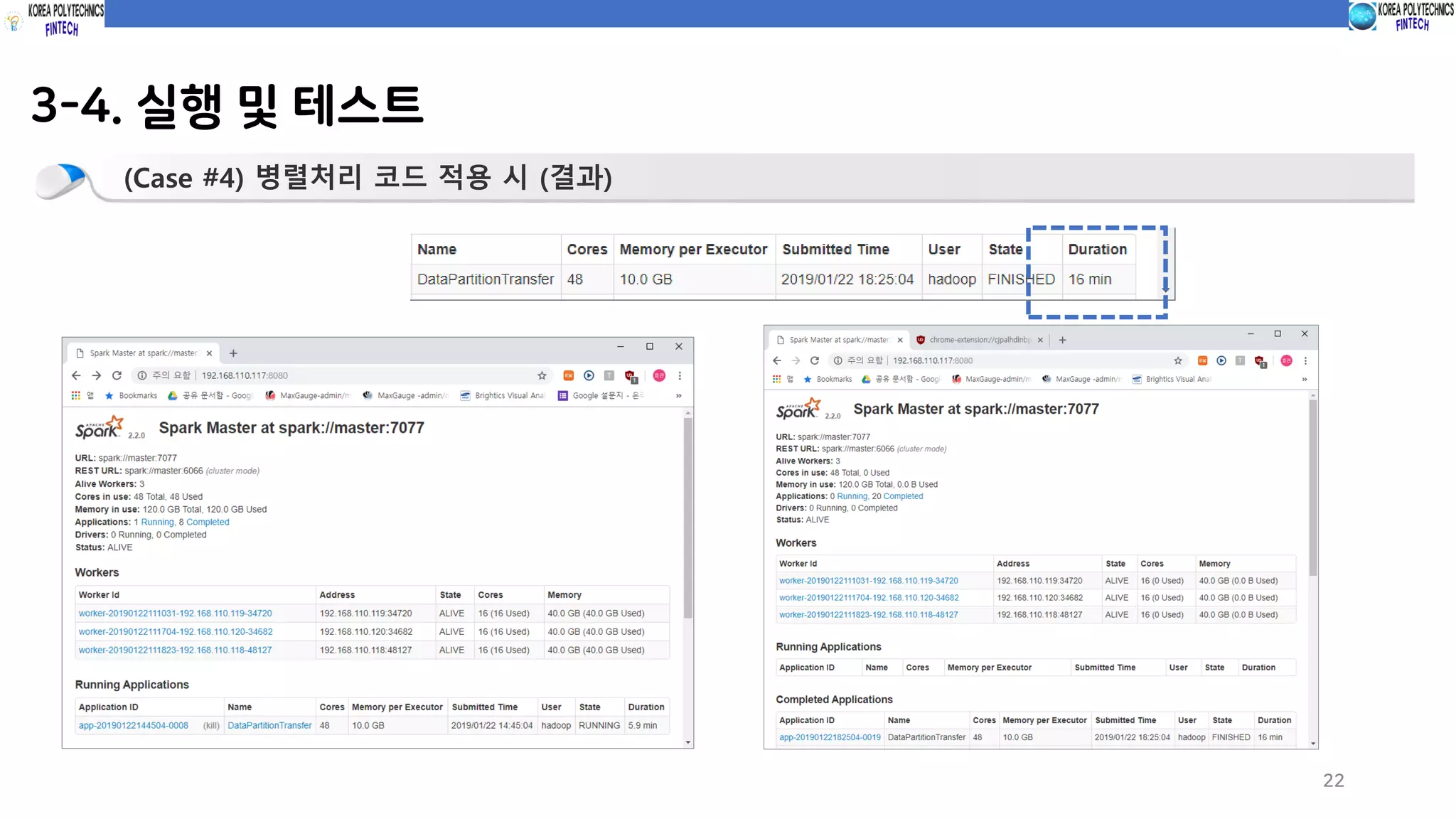
(Case #4) 병렬처리 코드 적용 시 (코드실행)
spark-submit --class com.spark.c10_dataTransfer.partitionDataTransfer sparkProgramming-spark-1.0.jar
파티션 사이즈 10 설정
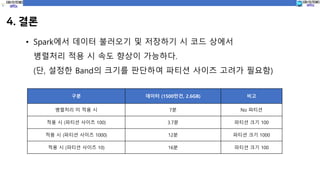
4. 결론
• Spark에서데이터 불러오기 및 저장하기 시 코드 상에서
병렬처리 적용 시 속도 향상이 가능하다.
(단, 설정한 Band의 크기를 판단하여 파티션 사이즈 고려가 필요함)
구분 데이터 (1500만건, 2.6GB) 비고
병렬처리 미 적용 시 7분 No 파티션
적용 시 (파티션 사이즈 100) 3.7분 파티션 크기 100
적용 시 (파티션 사이즈 1000) 12분 파티션 크기 1000
적용 시 (파티션 사이즈 10) 16분 파티션 크기 100























![[OpenInfra Days Korea 2018] Day 2 - E1: 딥다이브 - OpenStack 생존기](https://cdn.slidesharecdn.com/ss_thumbnails/e11300openinfradaysizingv1-180705030216-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[OpenInfra Days Korea 2018] Day 2 - CEPH 운영자를 위한 Object Storage Performance T...](https://cdn.slidesharecdn.com/ss_thumbnails/openinfradayobjectstorageperformancefinal2-180704062033-thumbnail.jpg?width=600ounds&width=560&fit=bounds)


![[Pgday.Seoul 2018] Greenplum의 노드 분산 설계](https://cdn.slidesharecdn.com/ss_thumbnails/02-20181103pgdayseminarv1-181112041352-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
















![[D2 COMMUNITY] Spark User Group - 스파크를 통한 딥러닝 이론과 실제](https://cdn.slidesharecdn.com/ss_thumbnails/520160211-160307085845-thumbnail.jpg?width=600ounds&width=560&fit=bounds)

















