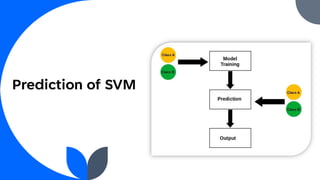
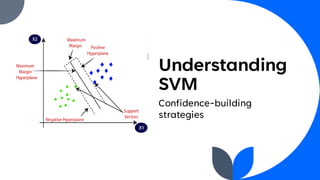
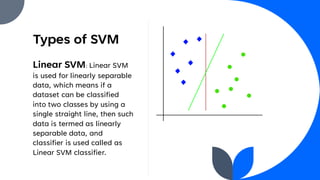
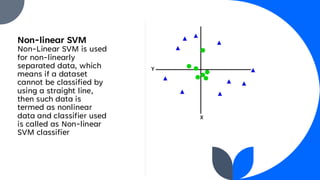
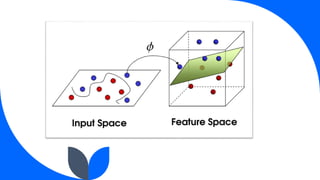
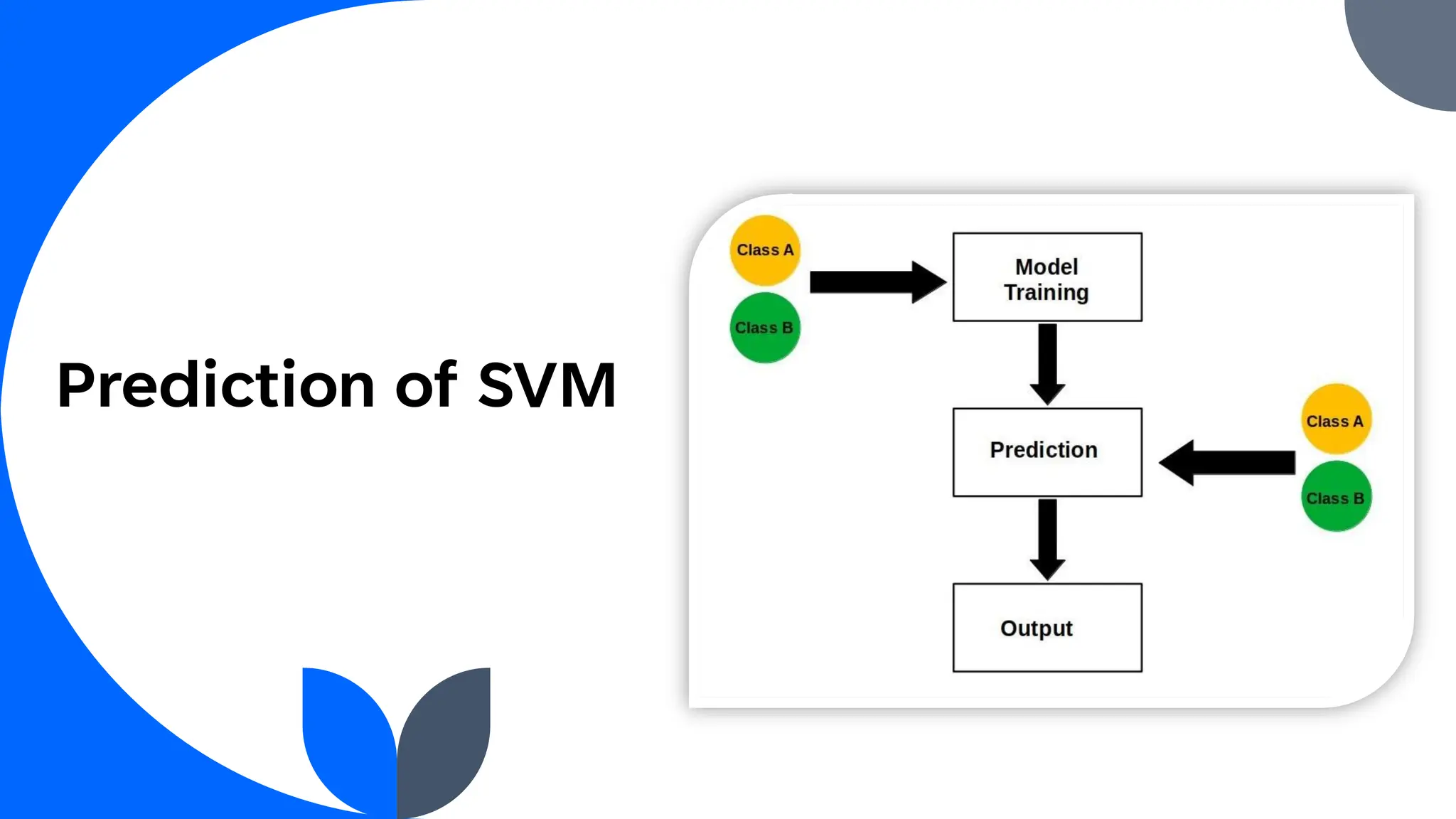
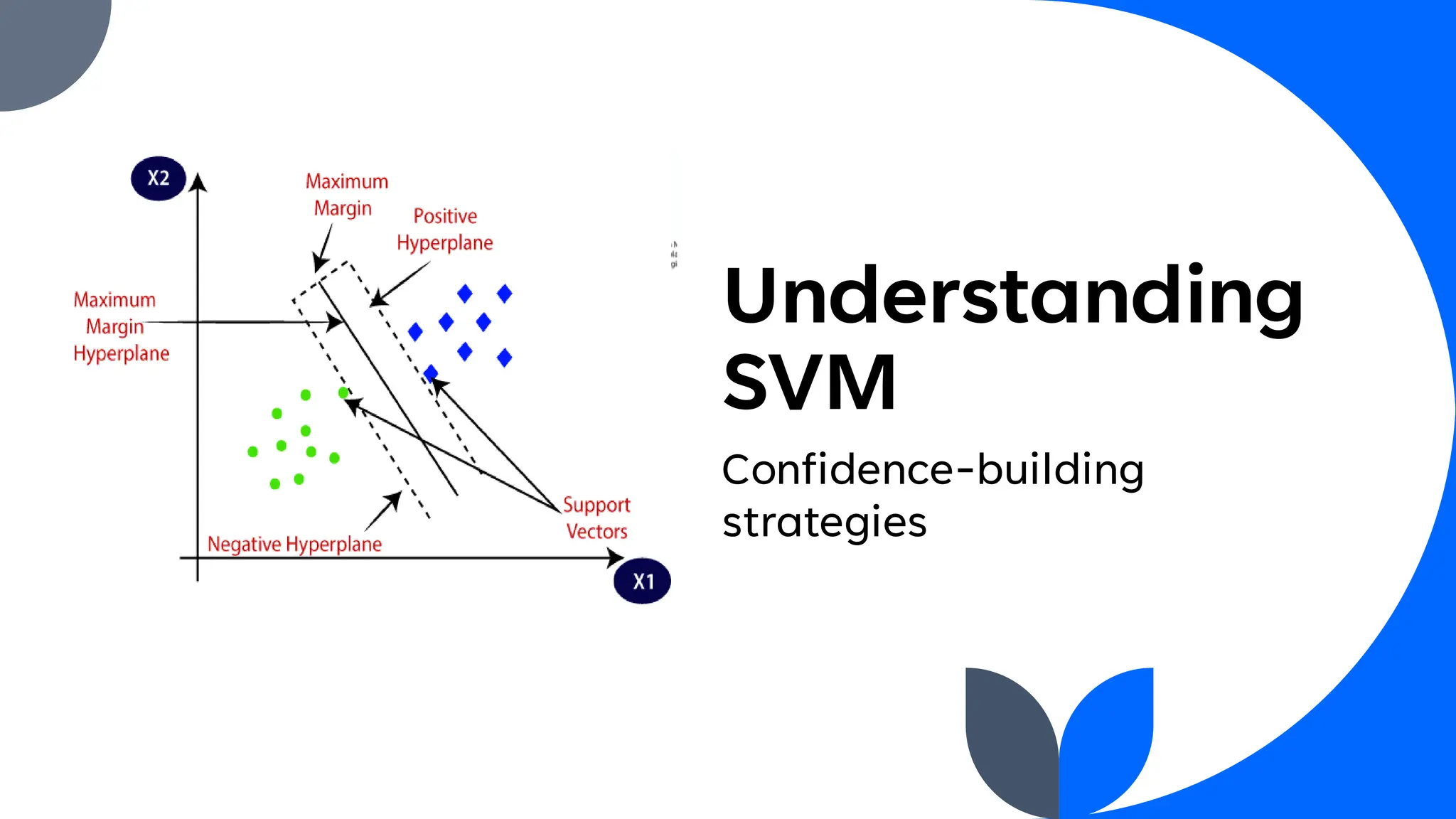
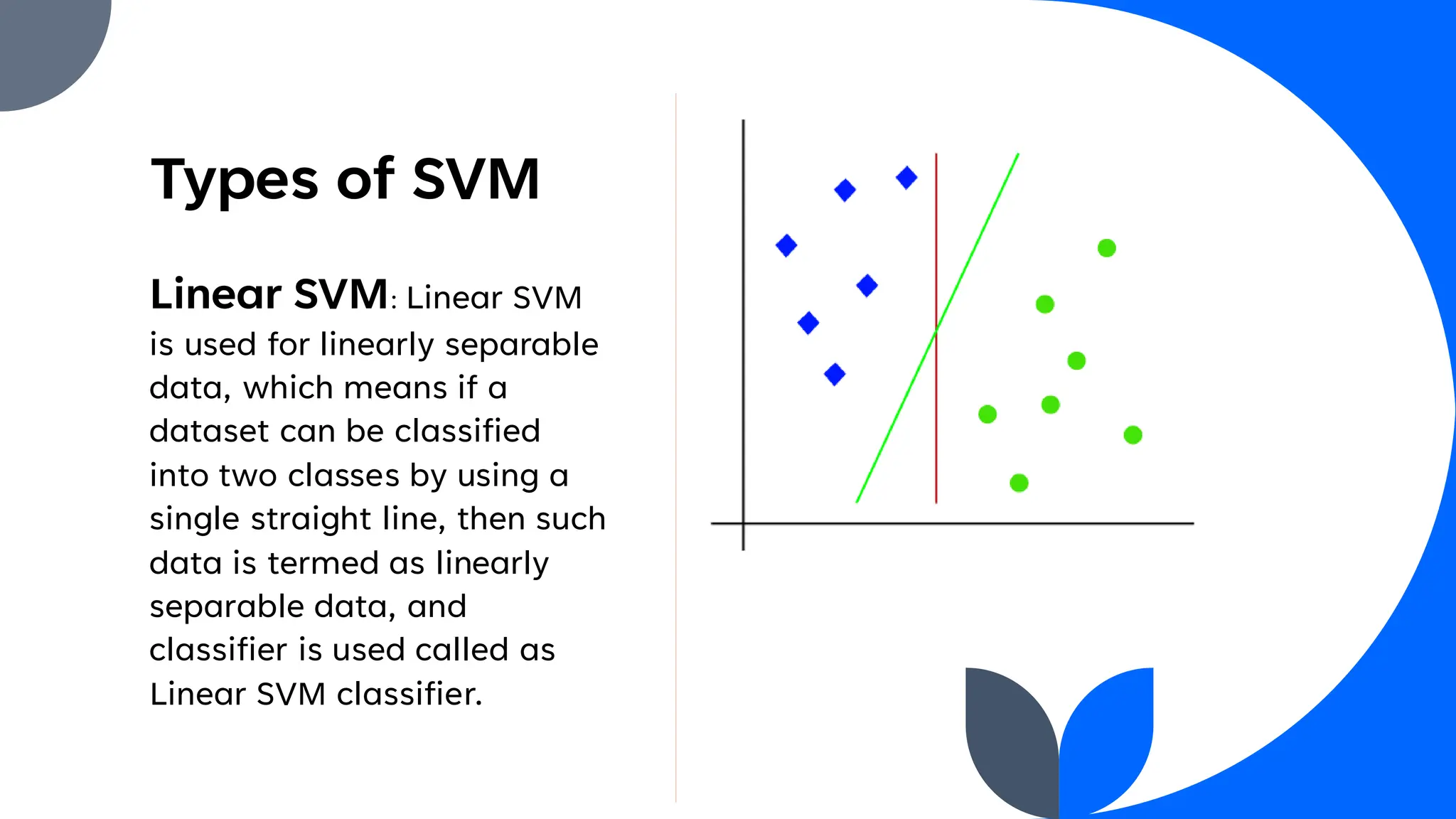
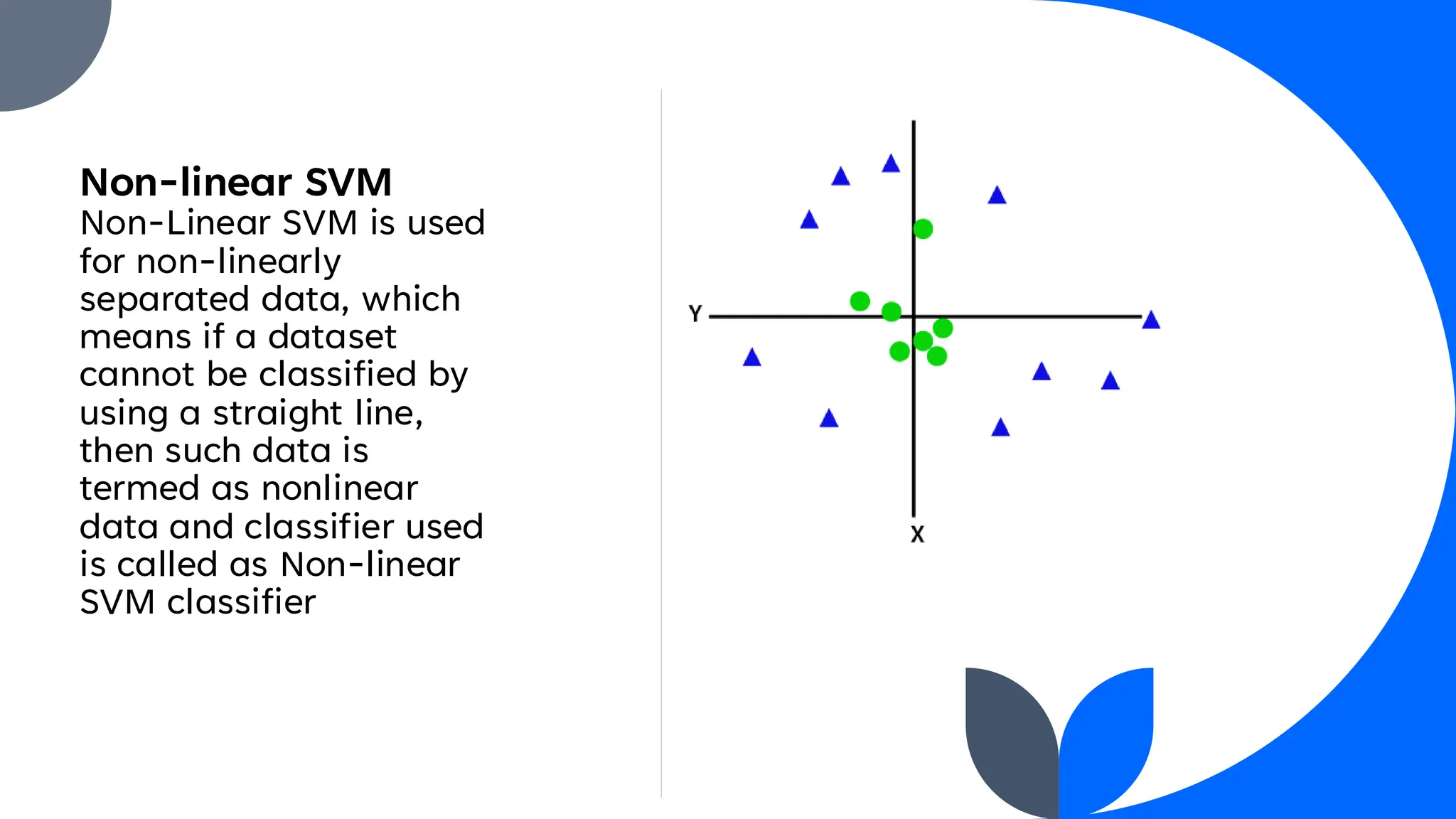
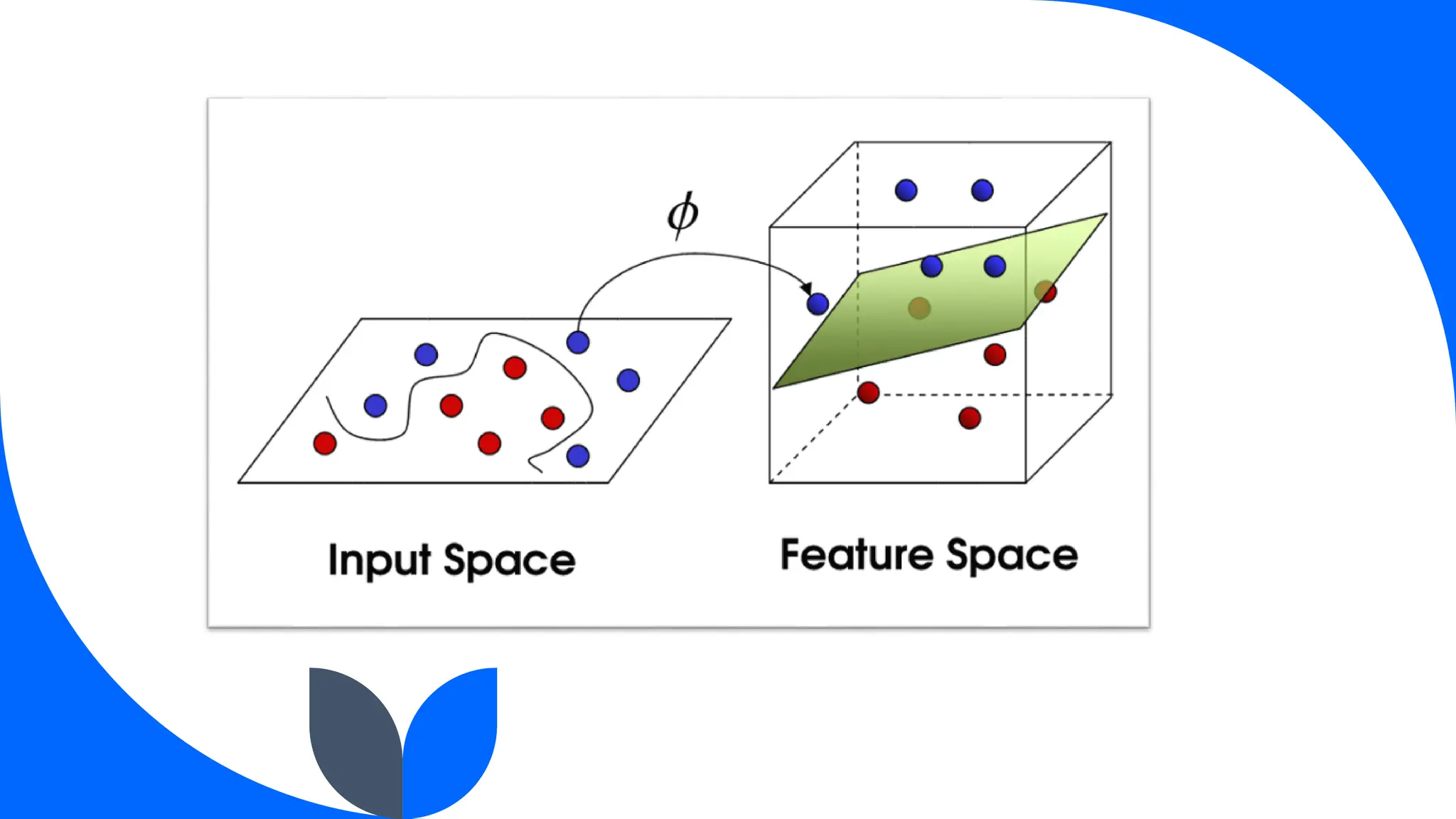
Support Vector Machine (SVM) is a widely used supervised learning algorithm for classification and regression, primarily focusing on classification. It identifies the optimal hyperplane that separates data points into classes, with support vectors being the closest points to this hyperplane. SVM can handle both linear and non-linear datasets using the kernel trick but may struggle with large datasets and high noise.














































![SVM[Support vector Machine] Machine learning](https://cdn.slidesharecdn.com/ss_thumbnails/svm-250403184638-1cd9afdb-thumbnail.jpg?width=600ounds&width=560&fit=bounds)











![SUPPORT VECTOR MACHINE ( SVM)akjhgaskjdgjksdgajkgdagdaakg[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/supportvectormachinesvm1-240702134610-f37092eb-thumbnail.jpg?width=600ounds&width=560&fit=bounds)






















