Downloaded 113 times

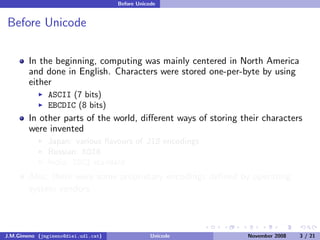

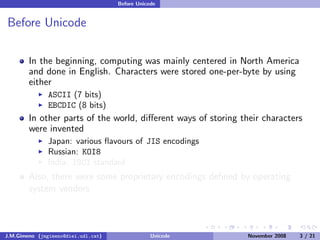
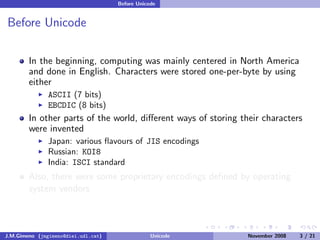

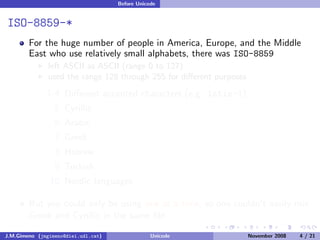









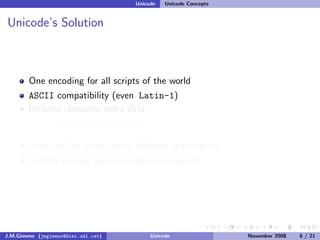





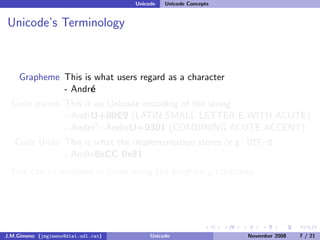




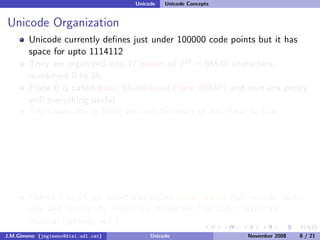

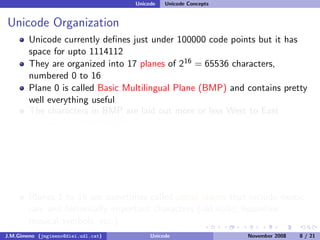





















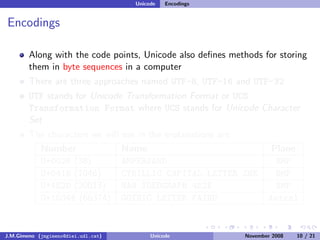
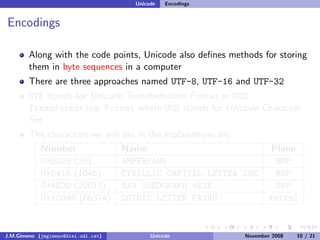
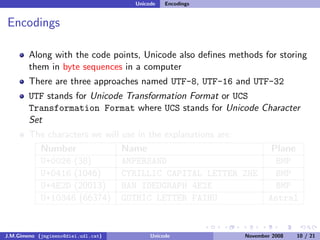
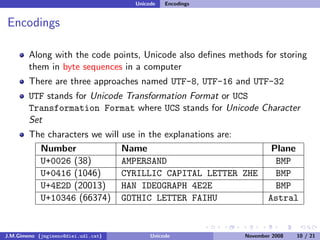
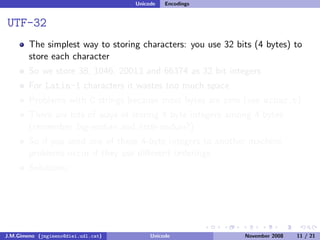
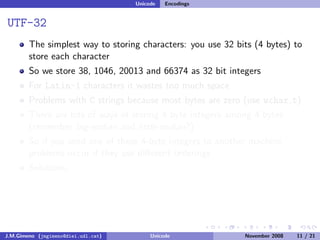
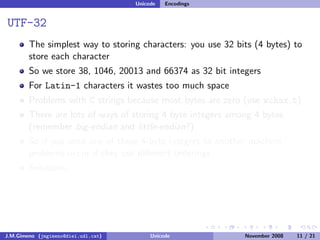
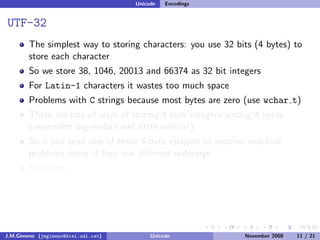
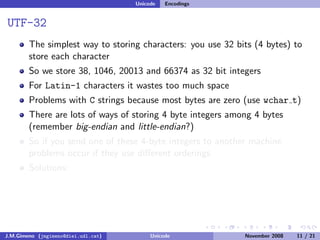




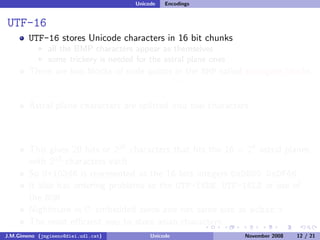



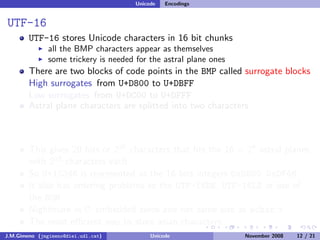
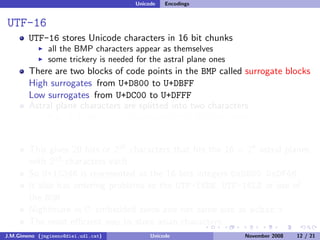

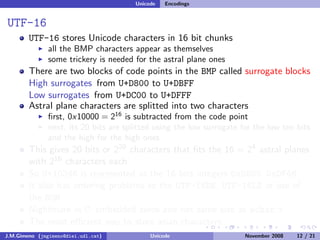













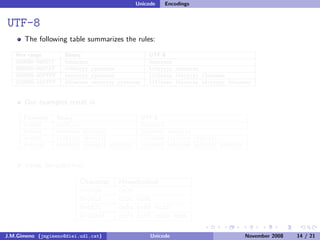
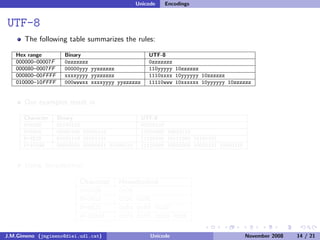
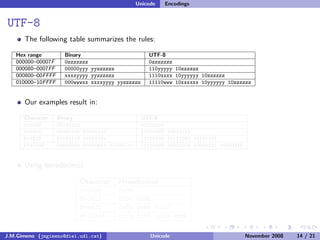
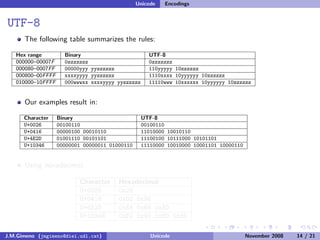
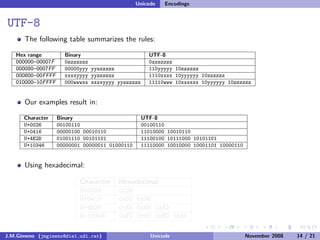
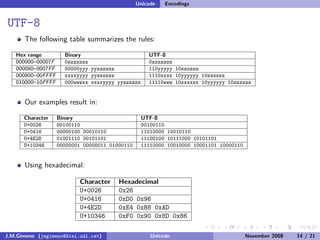






































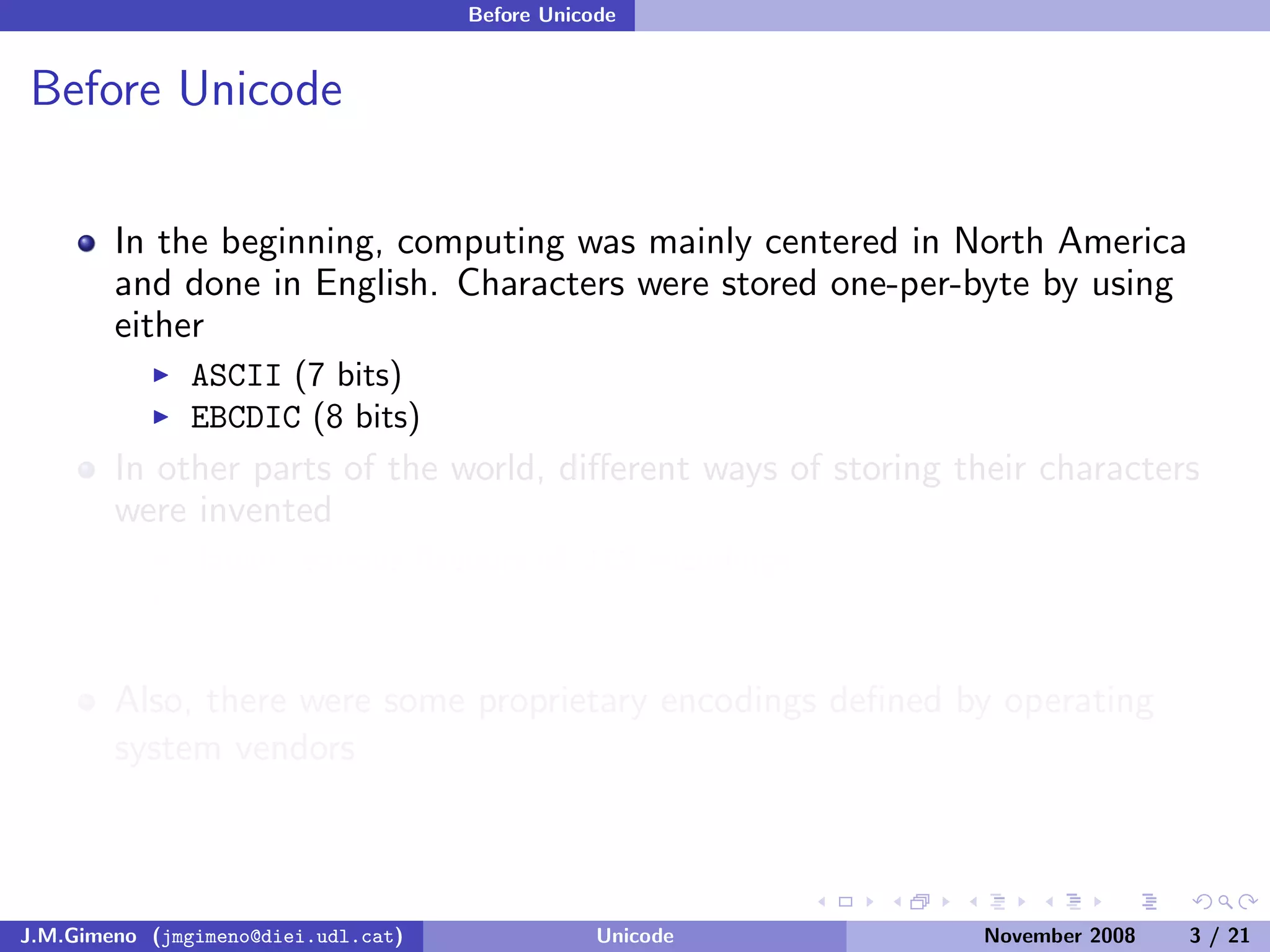
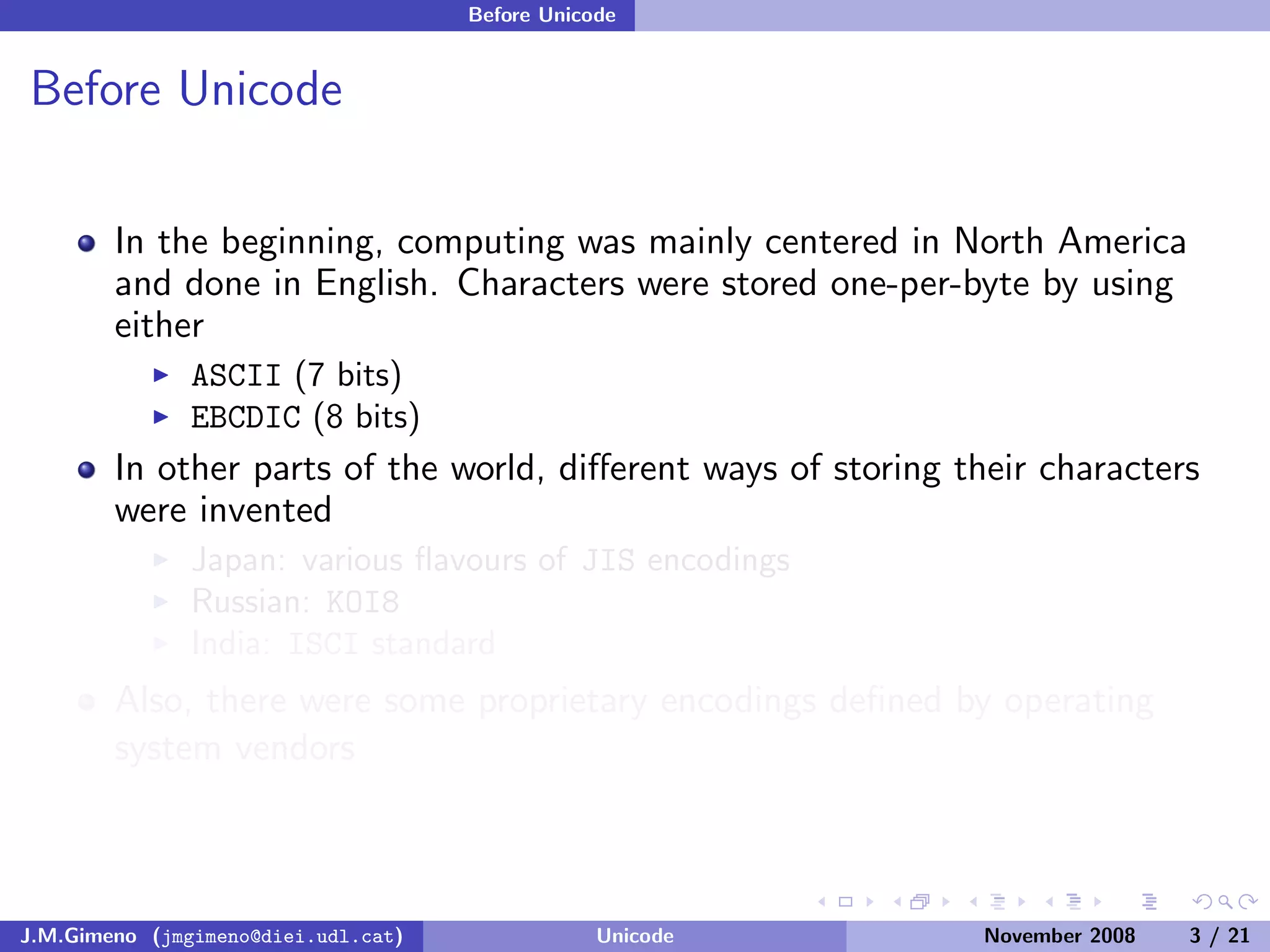




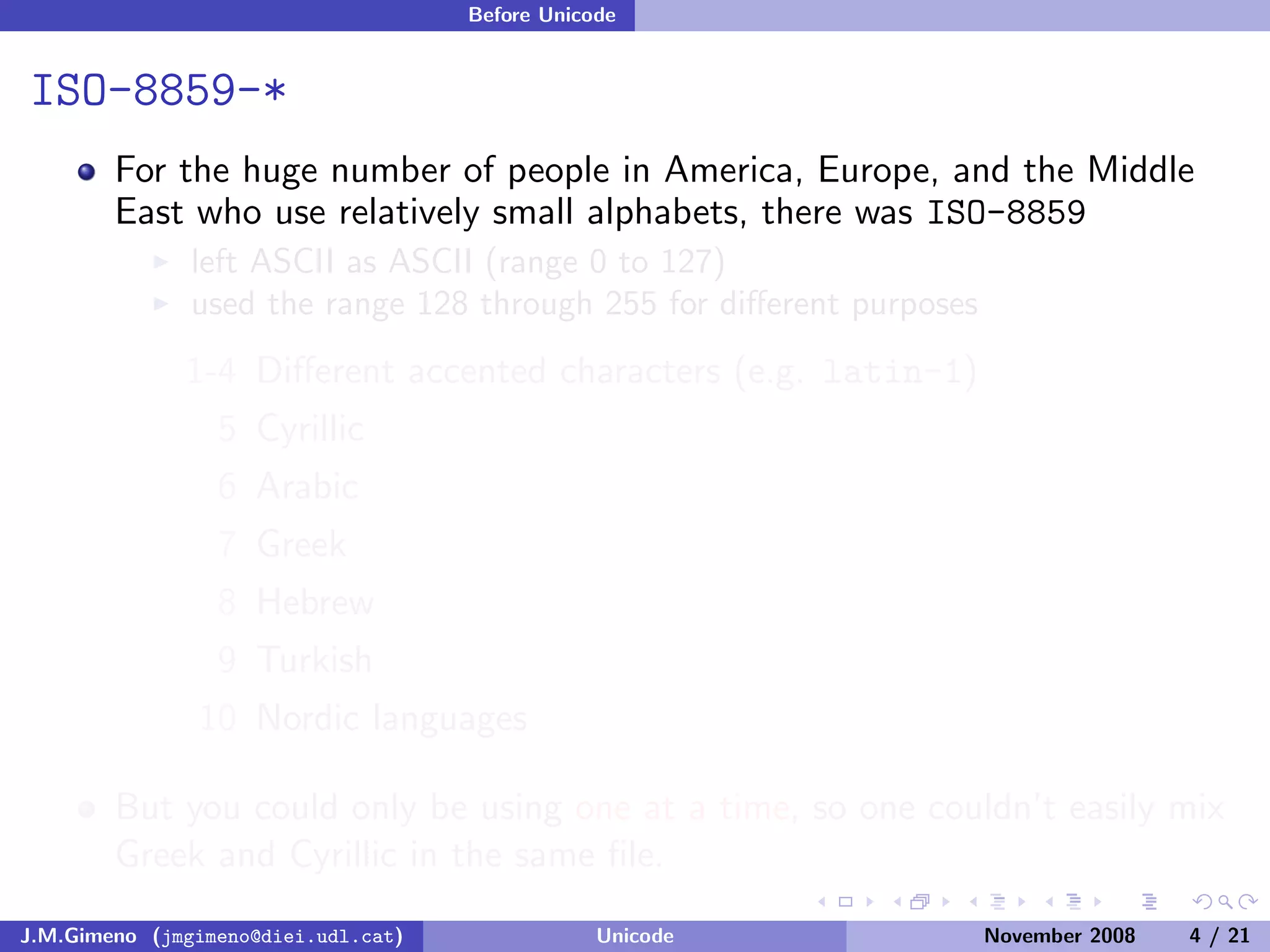
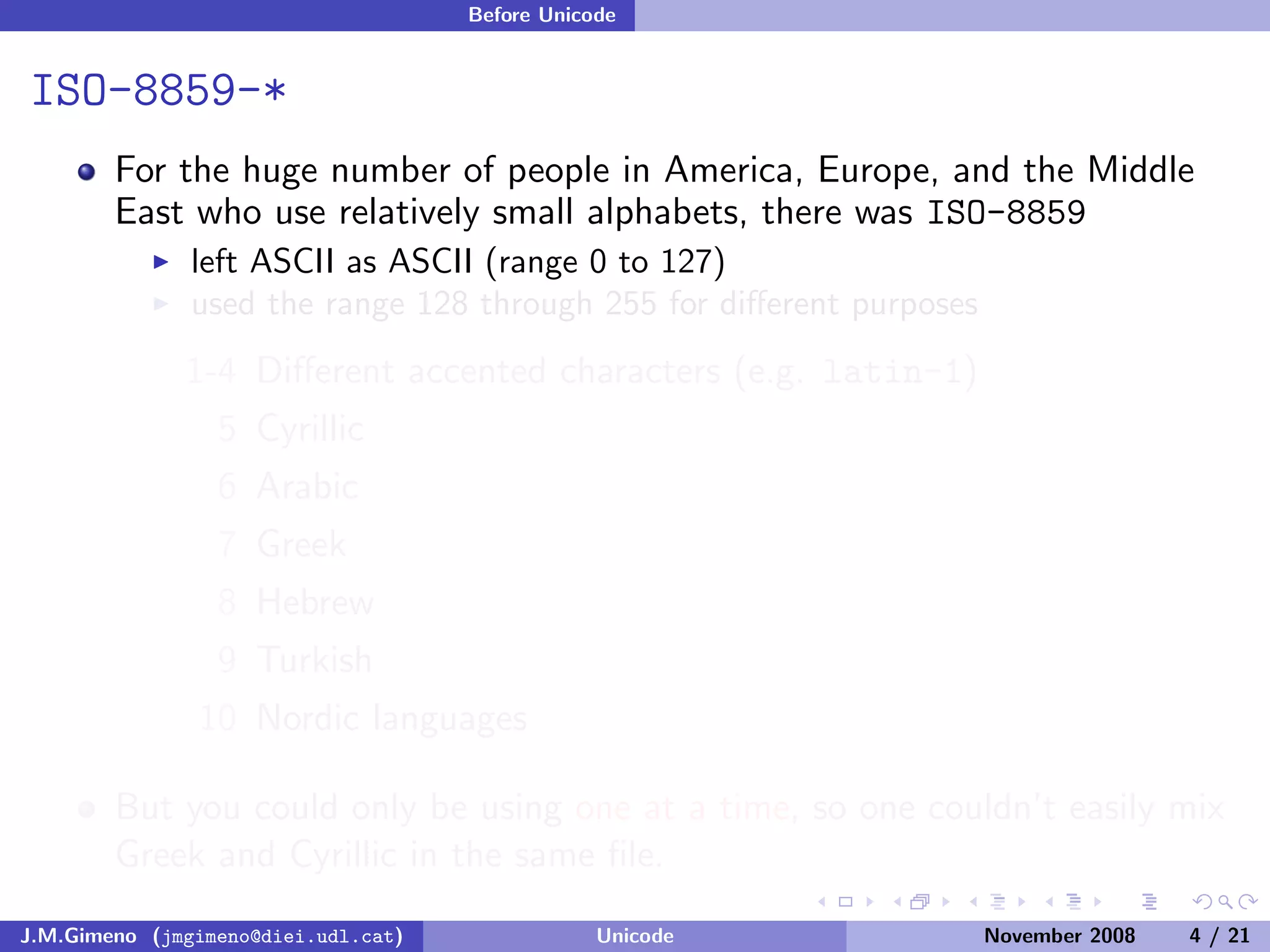
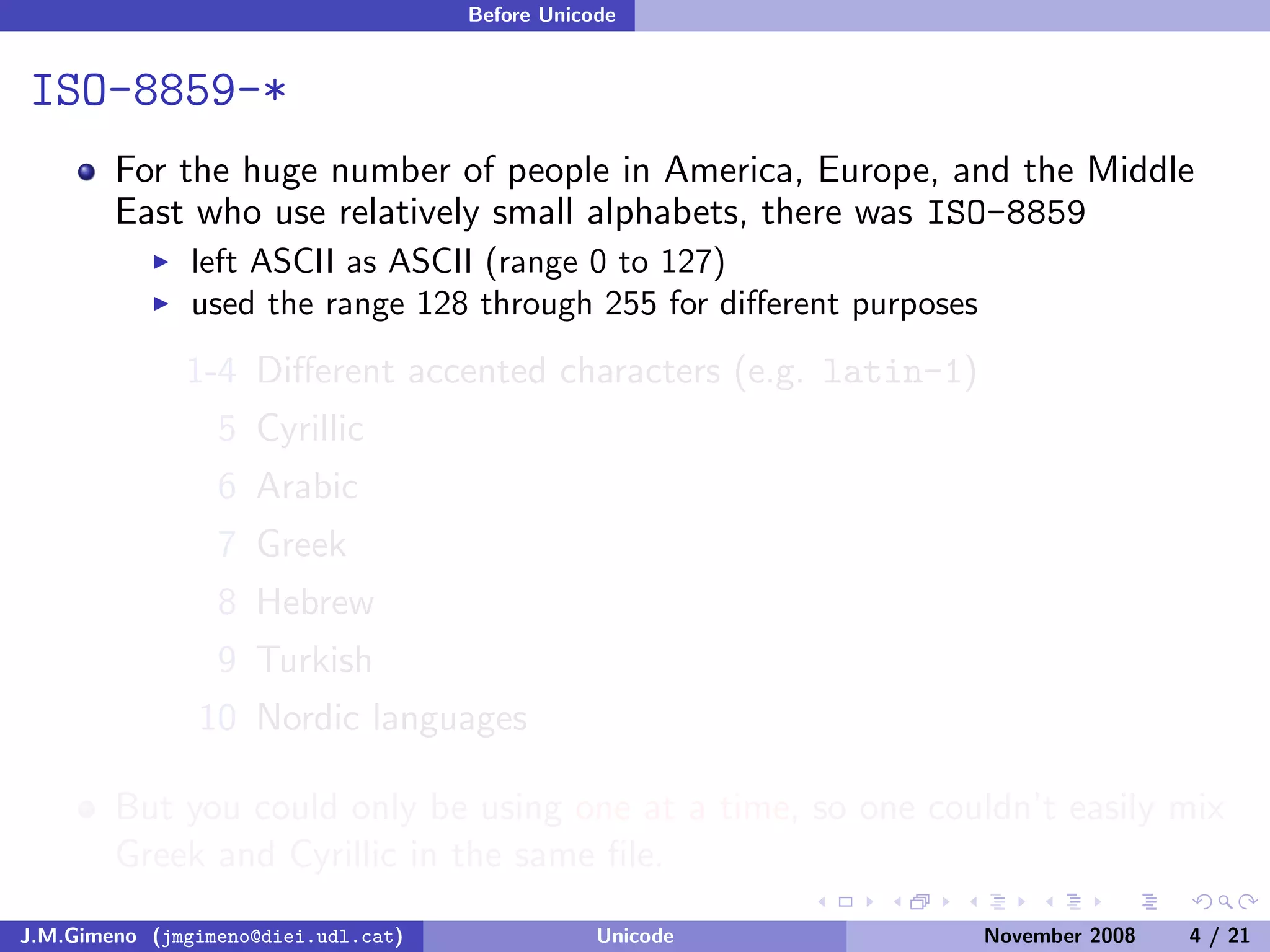
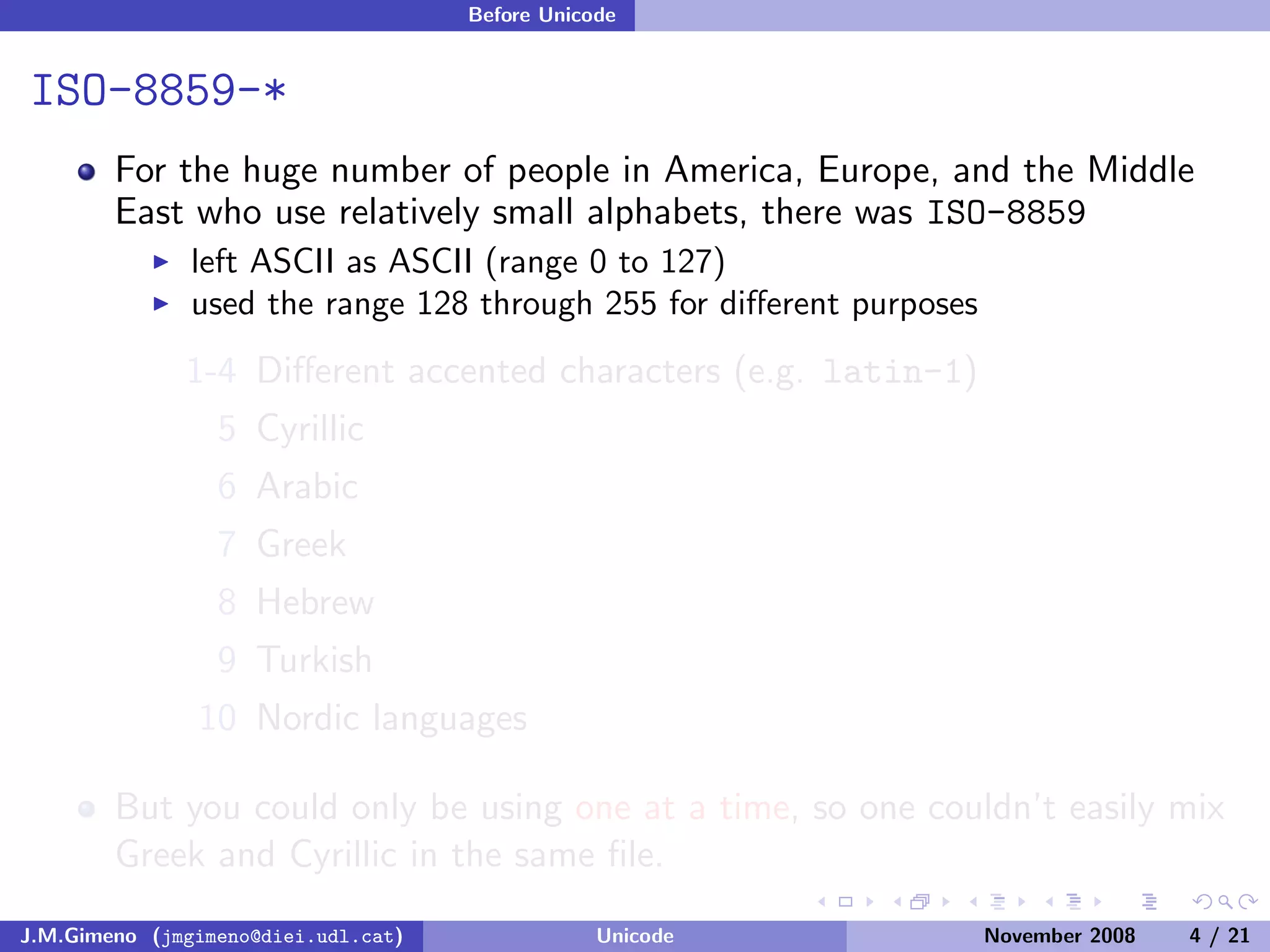








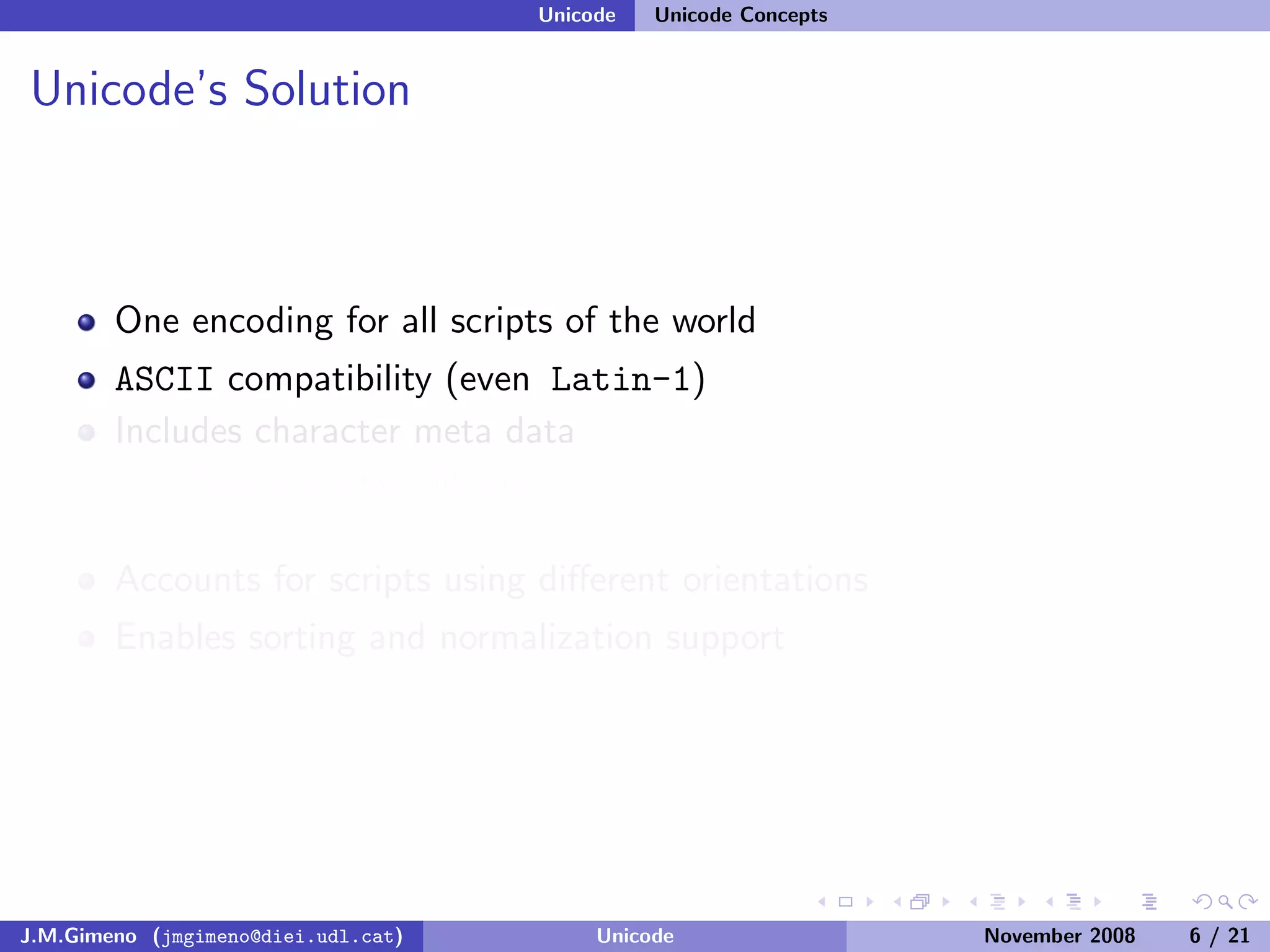

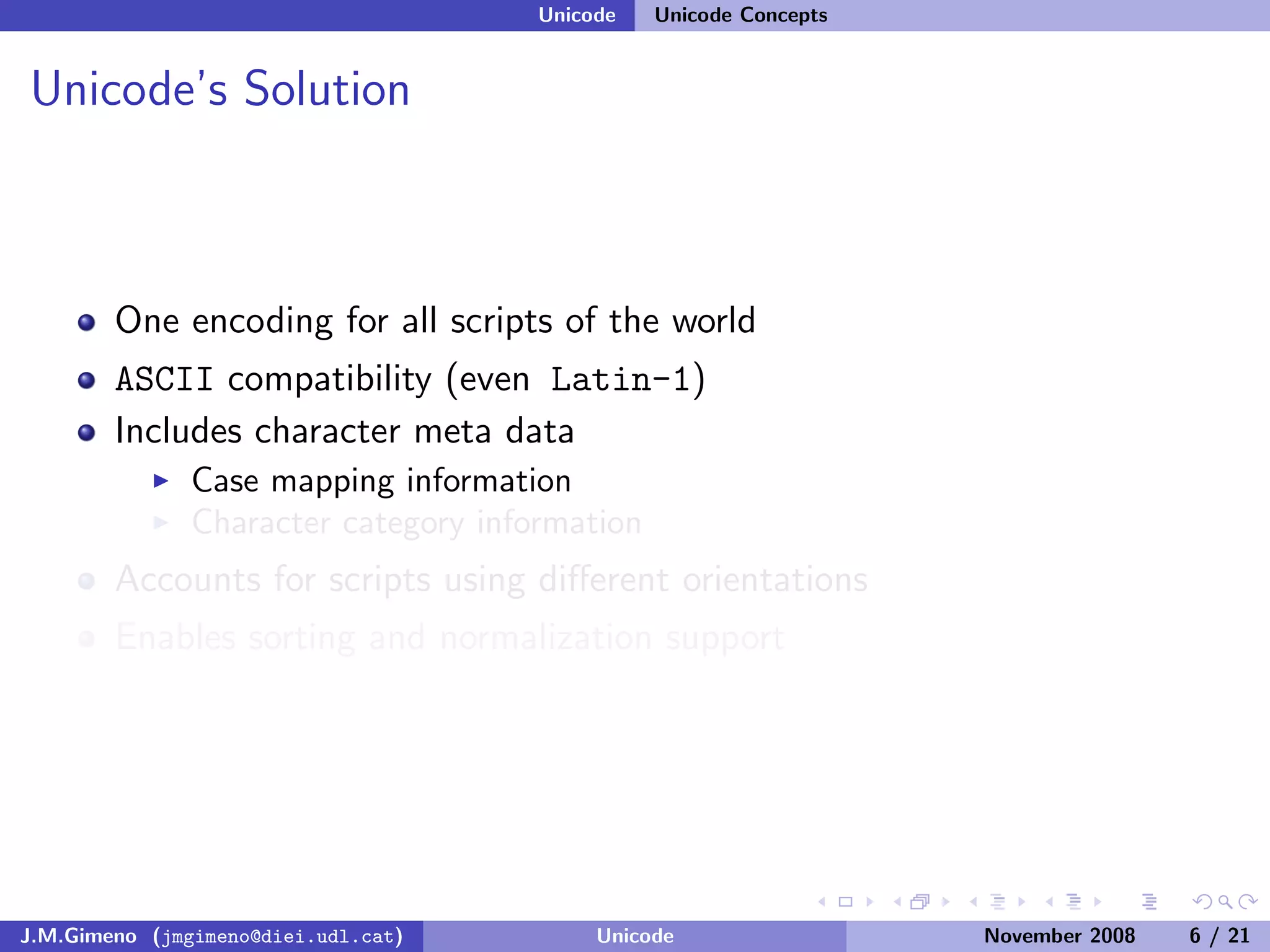








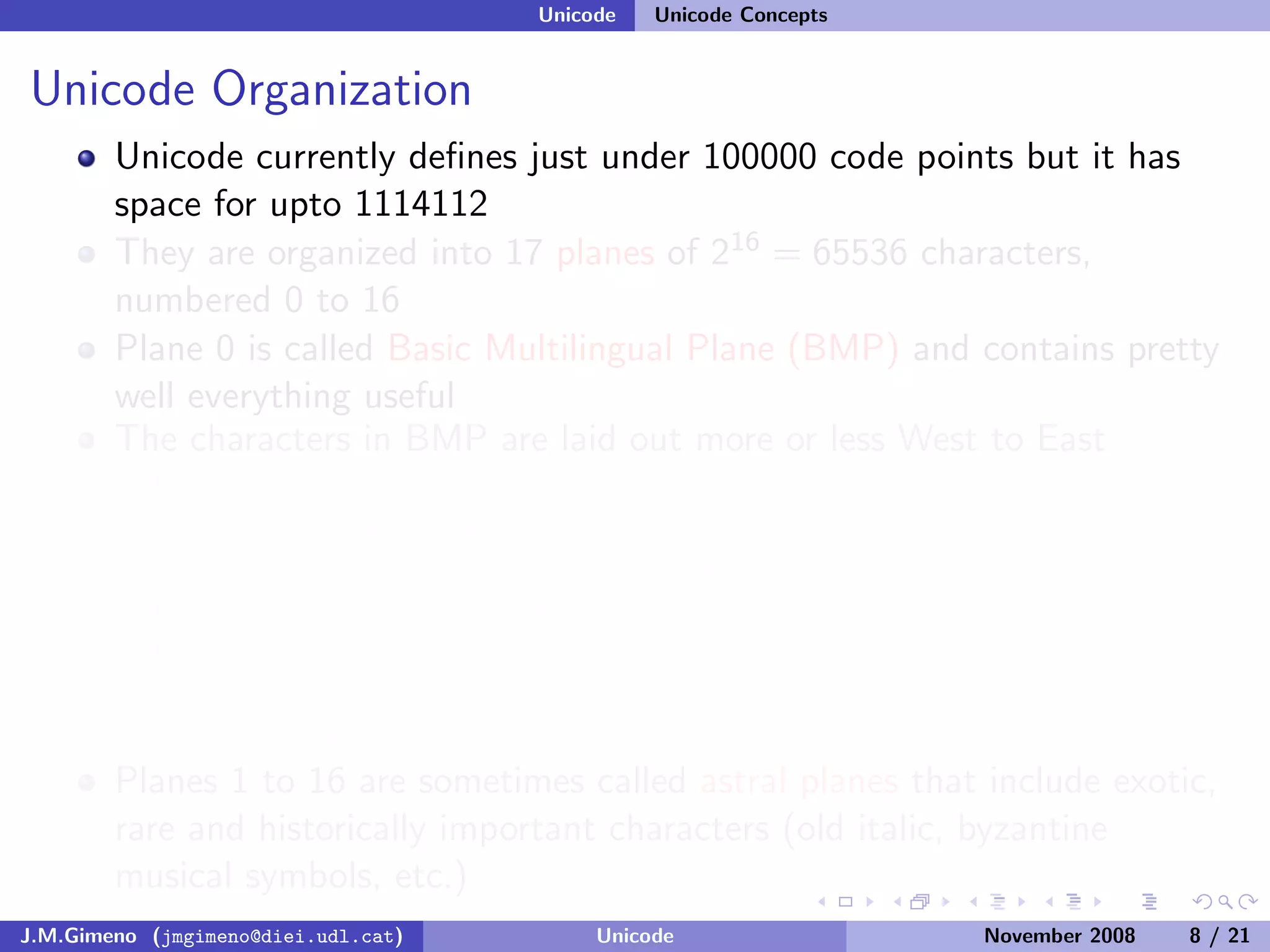

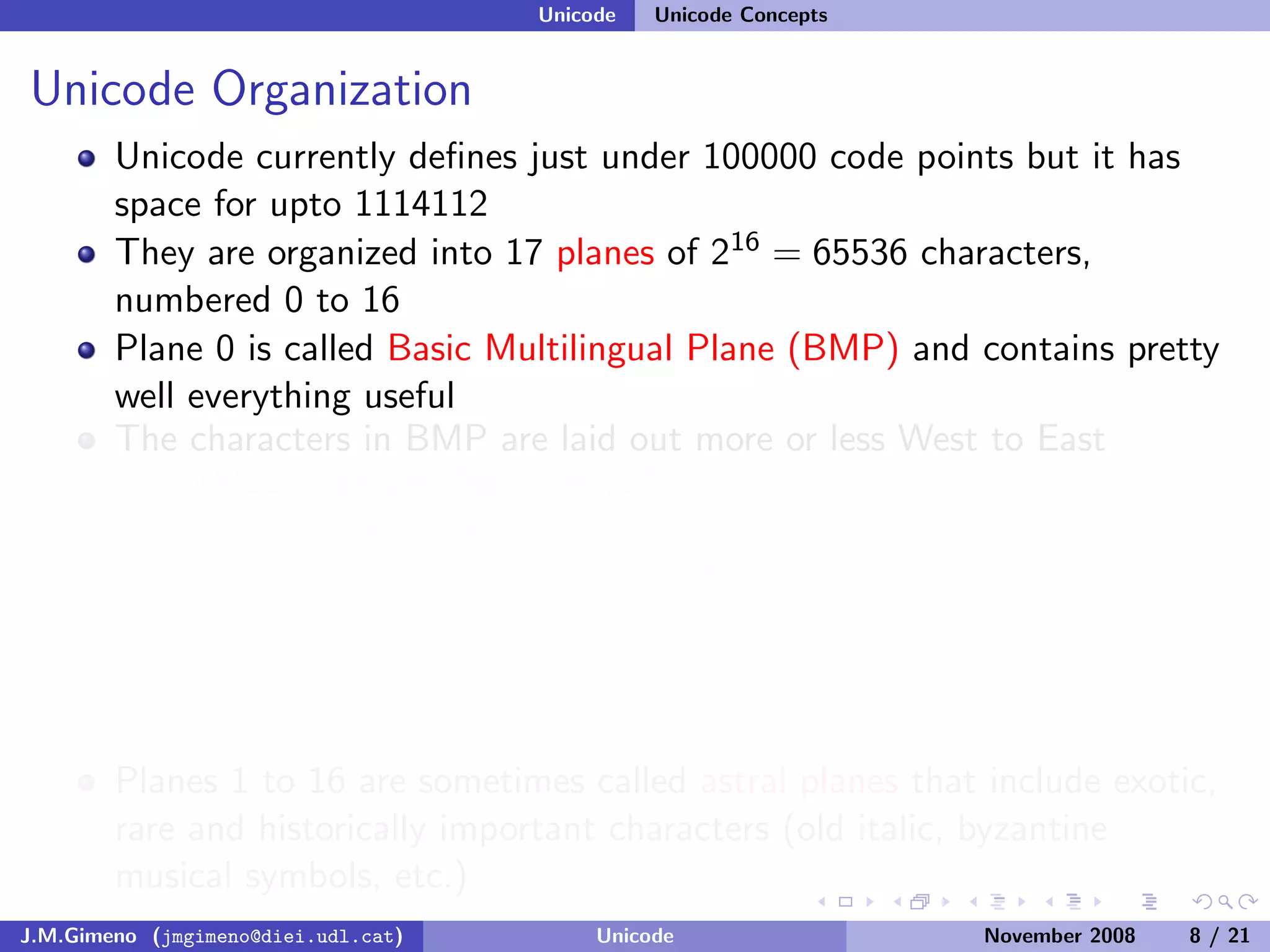





















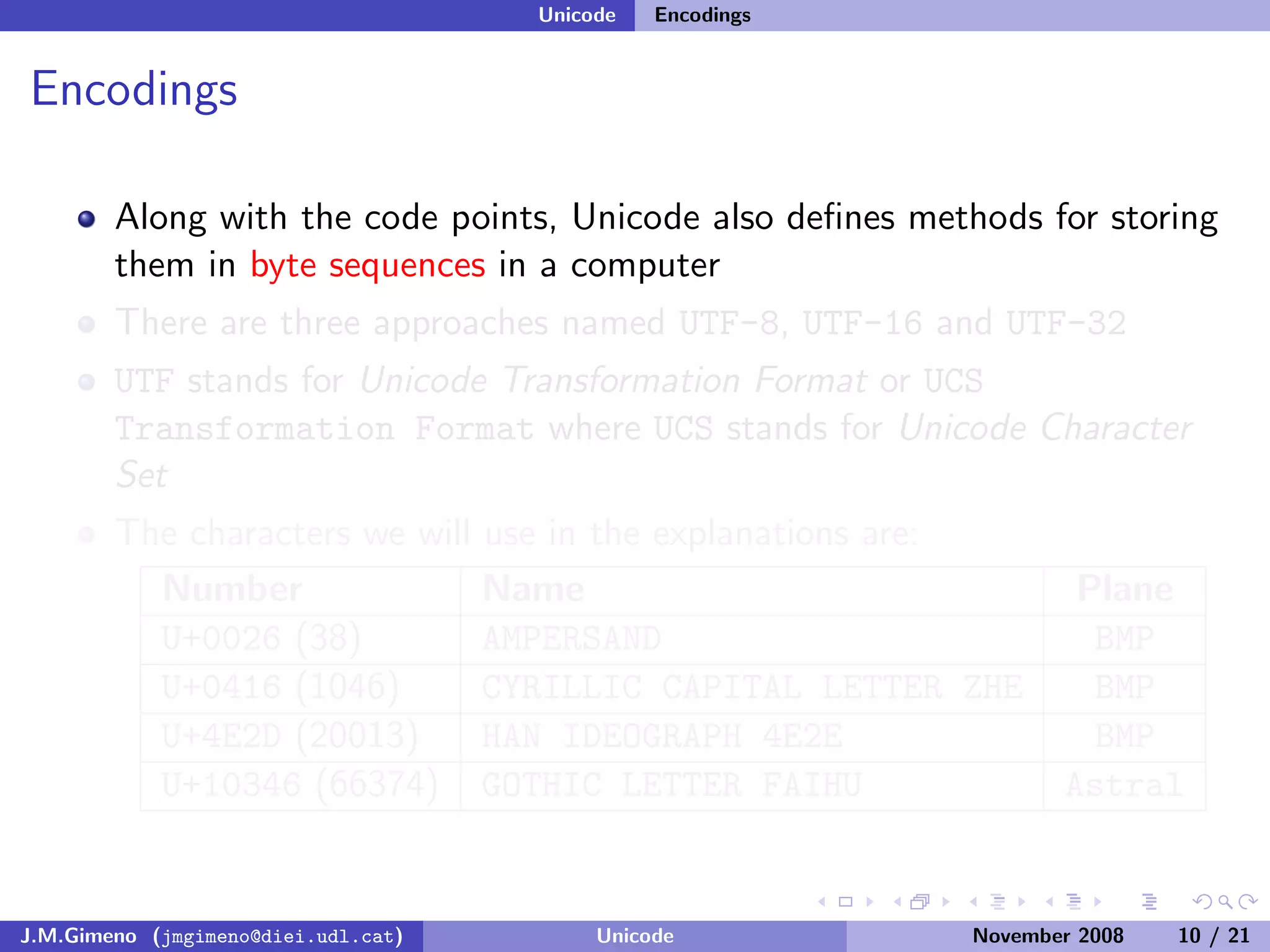
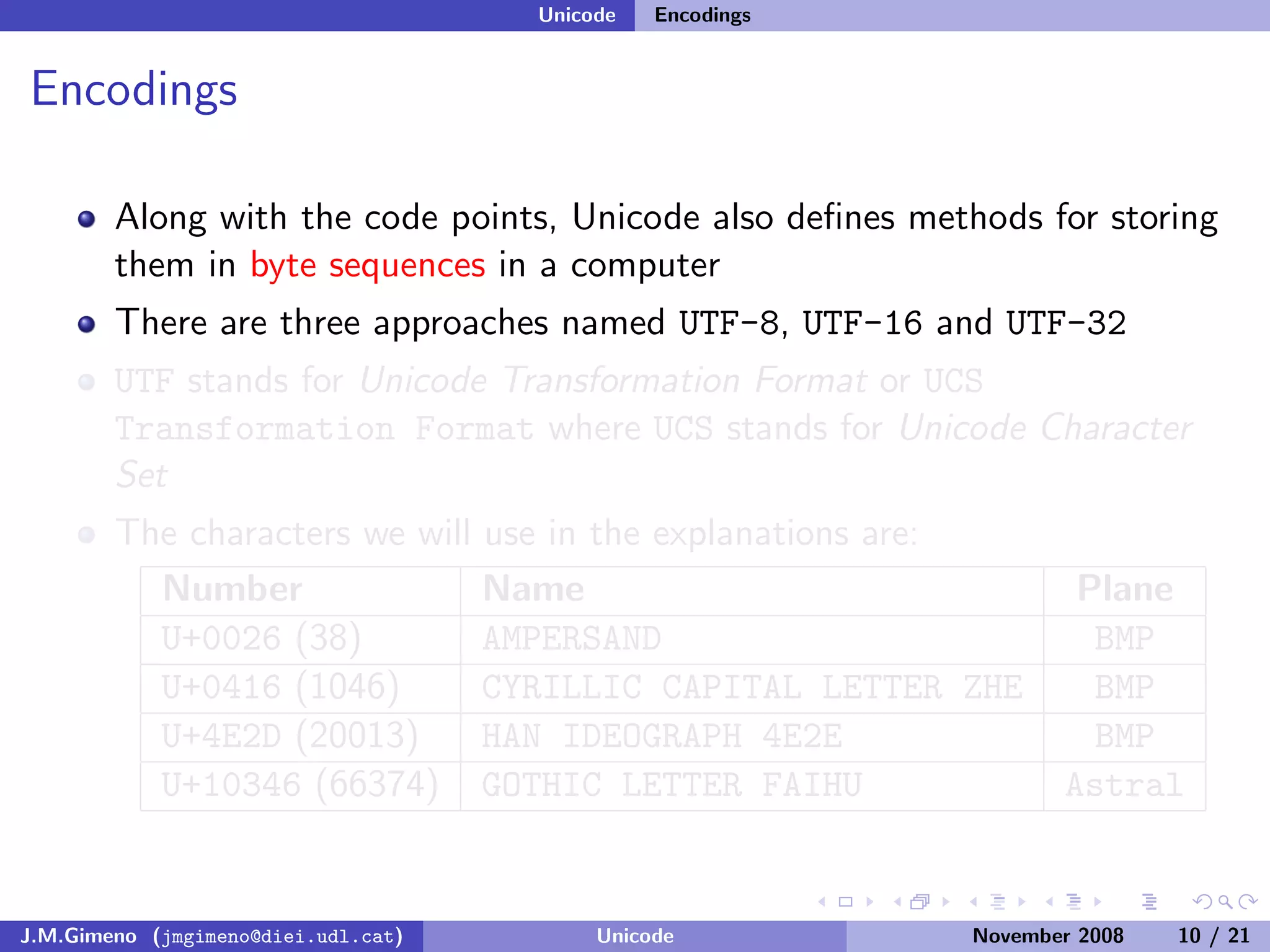
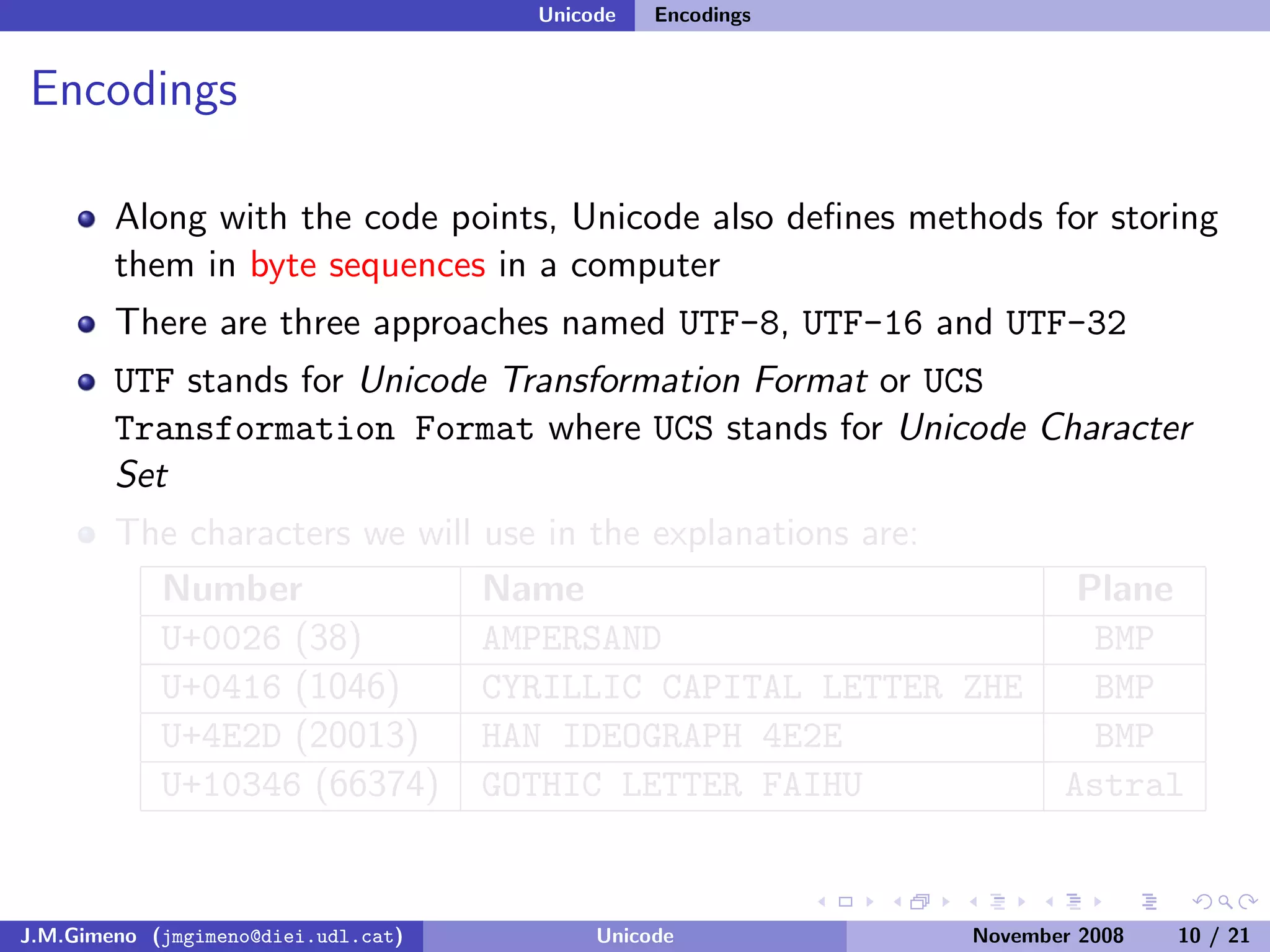
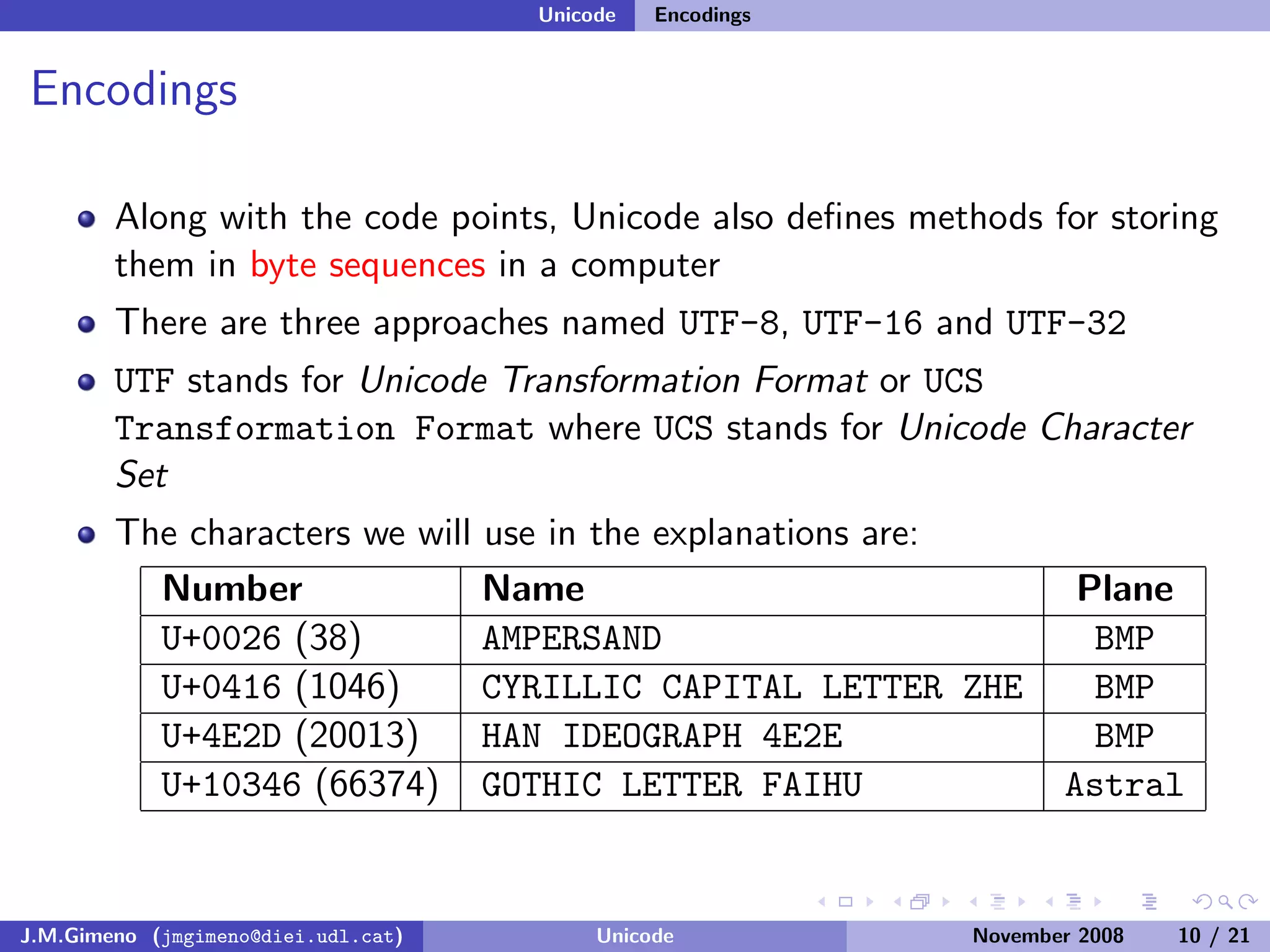





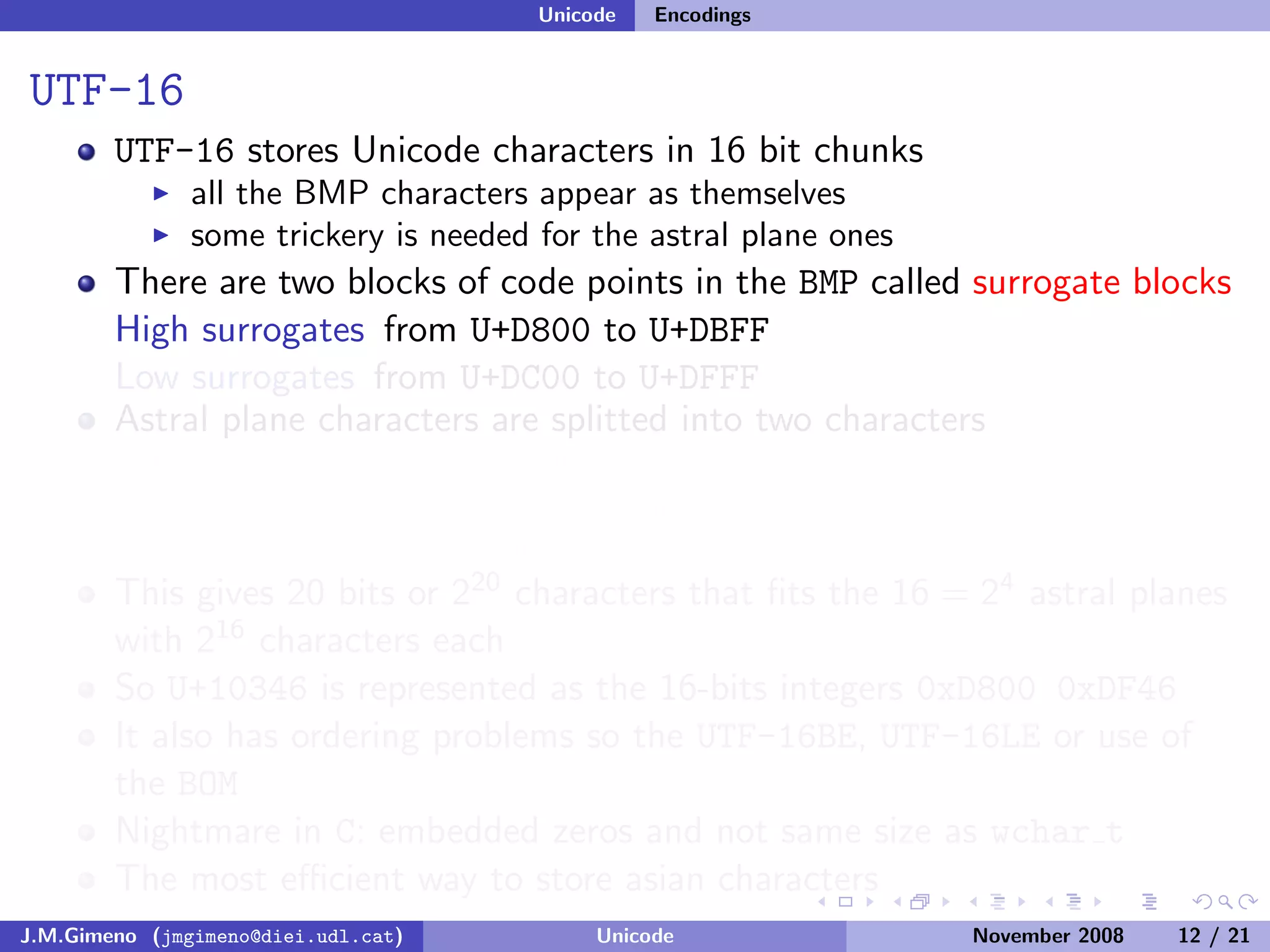
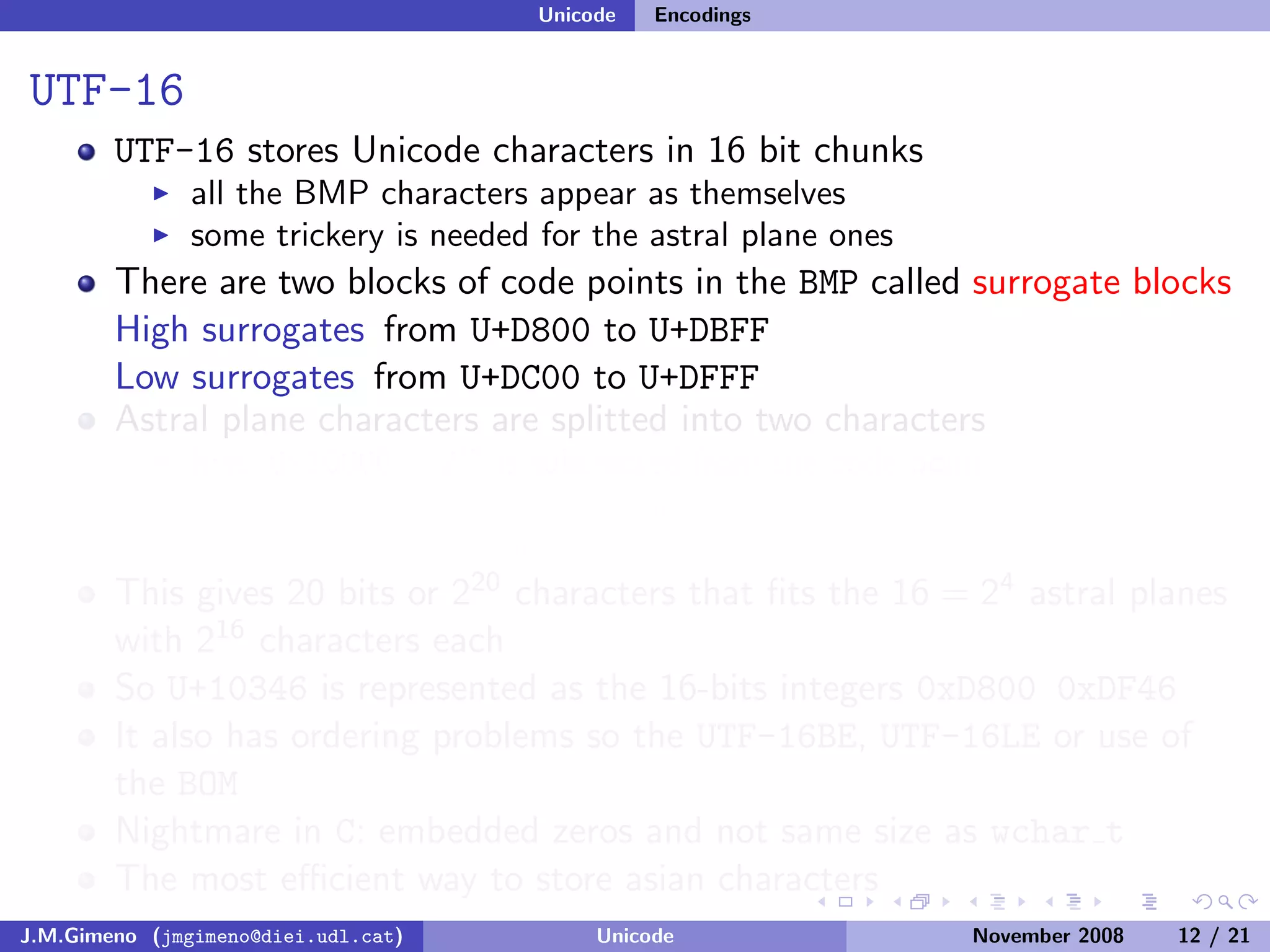
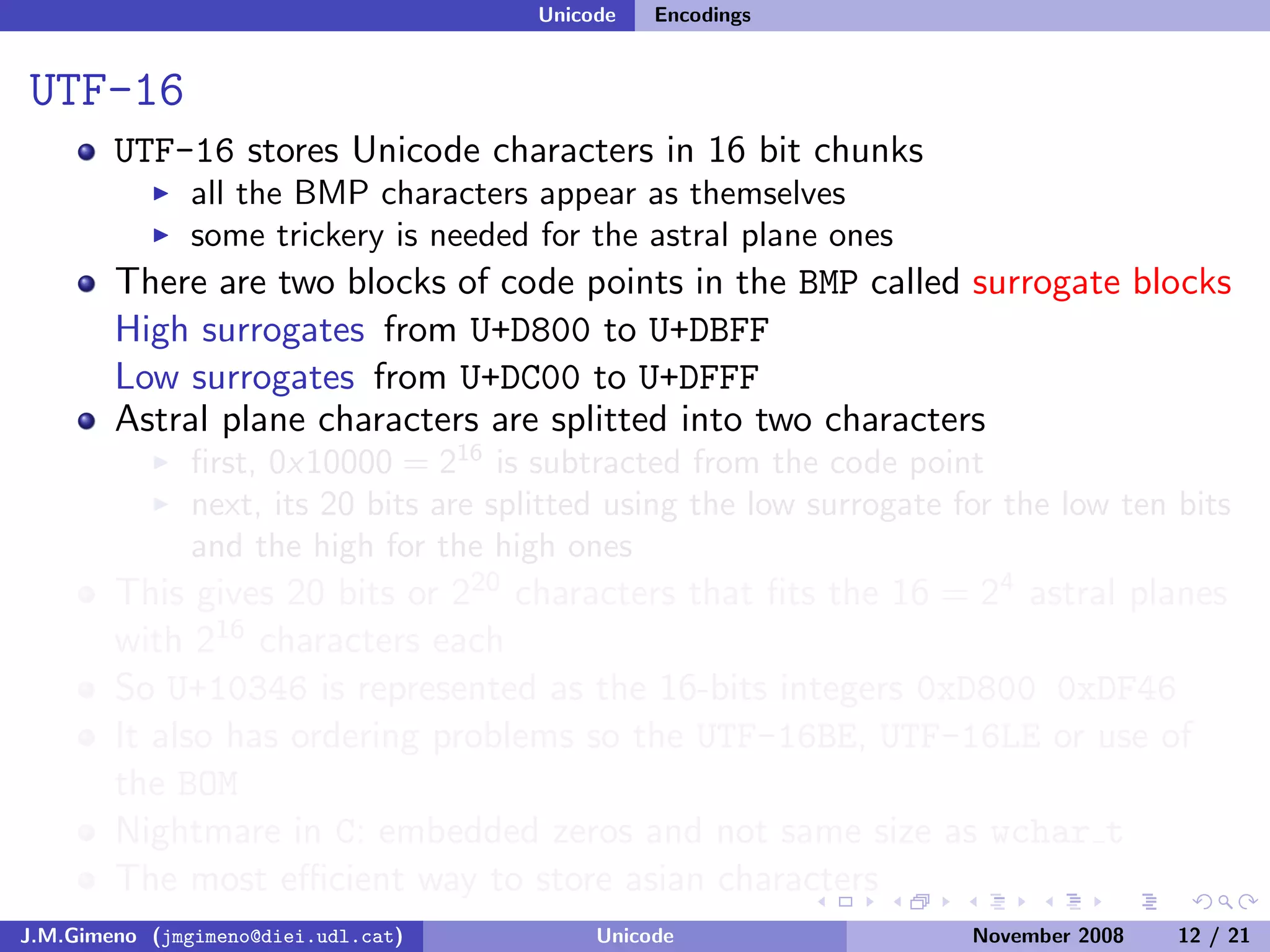
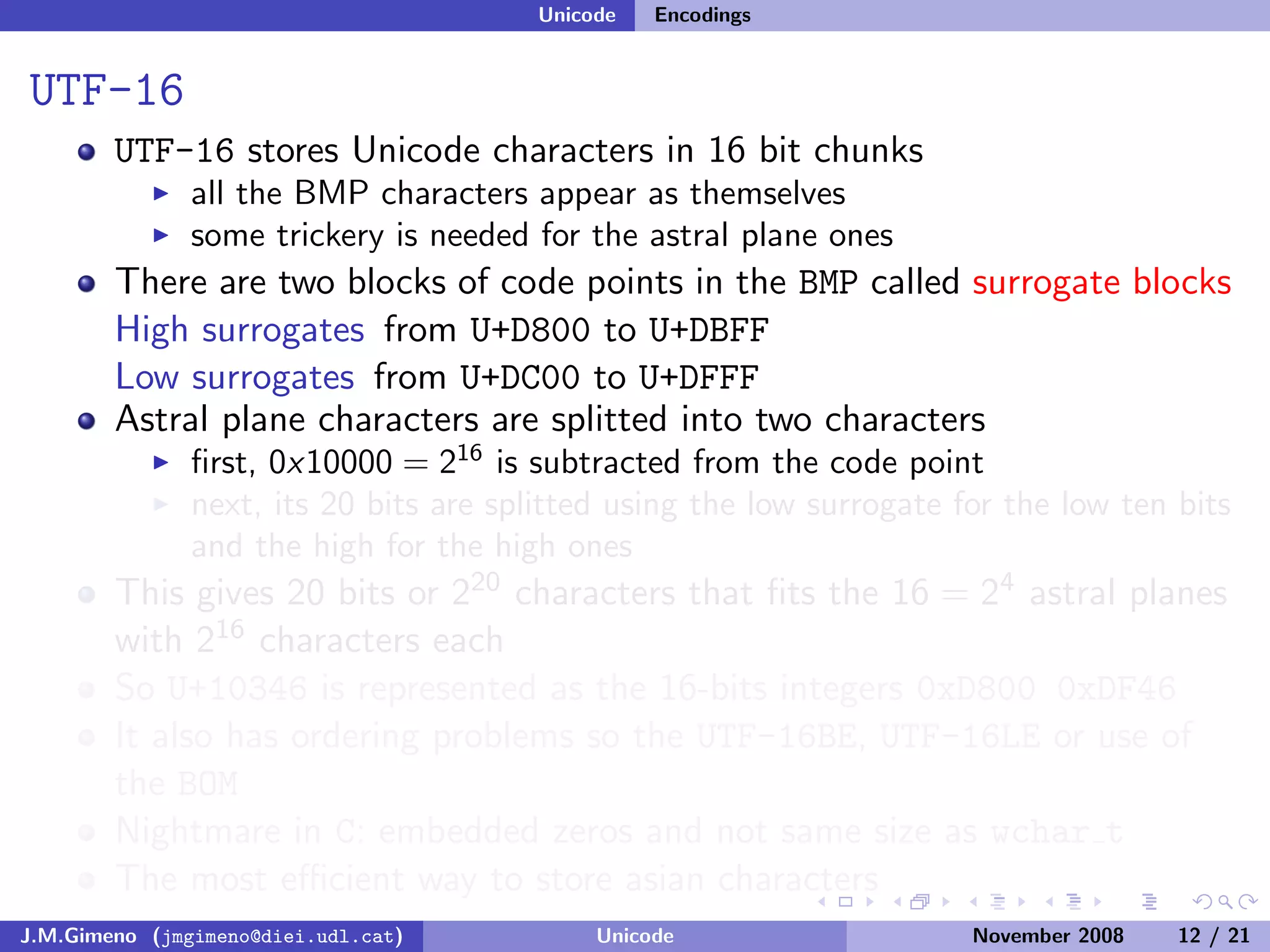












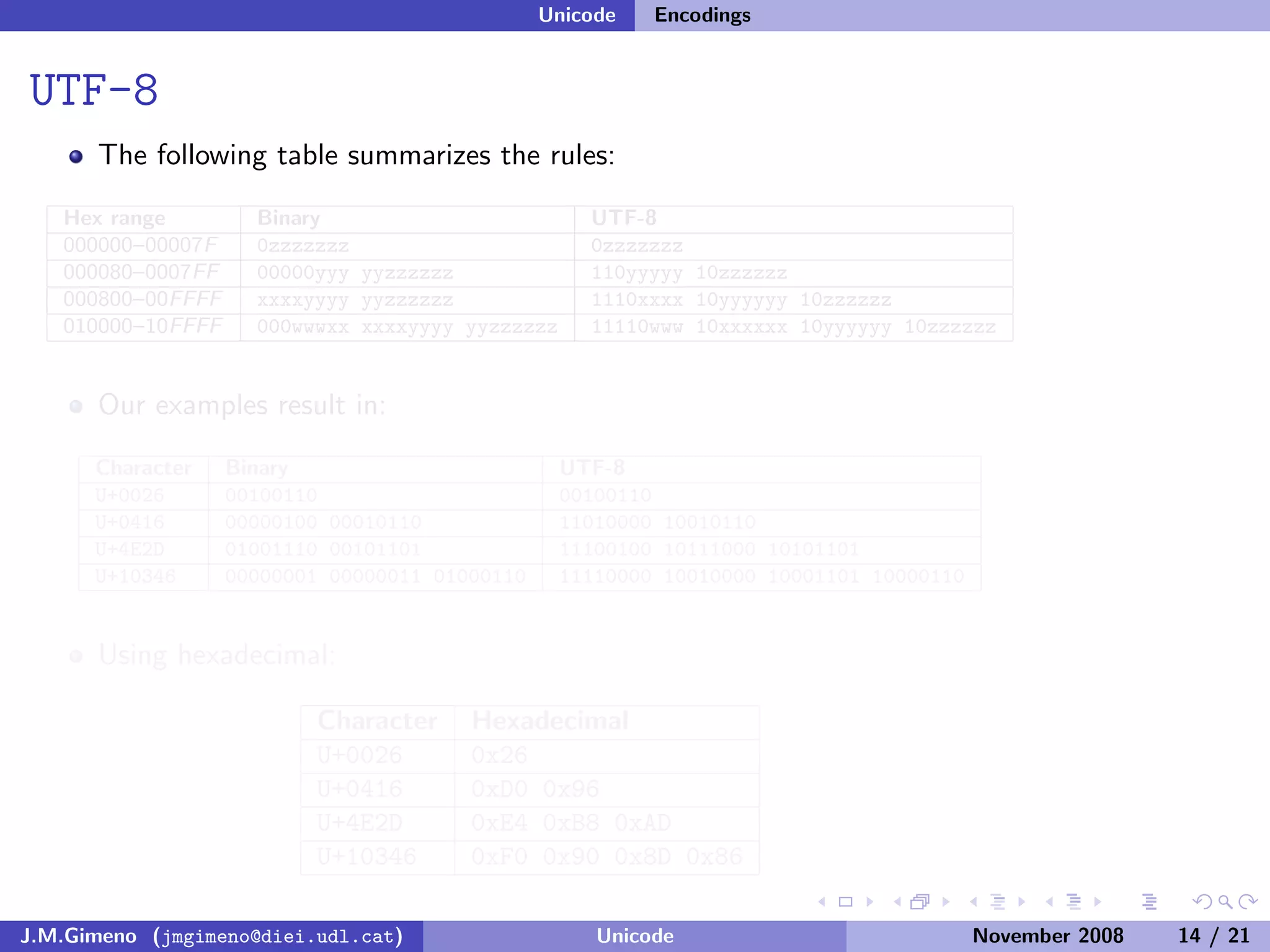
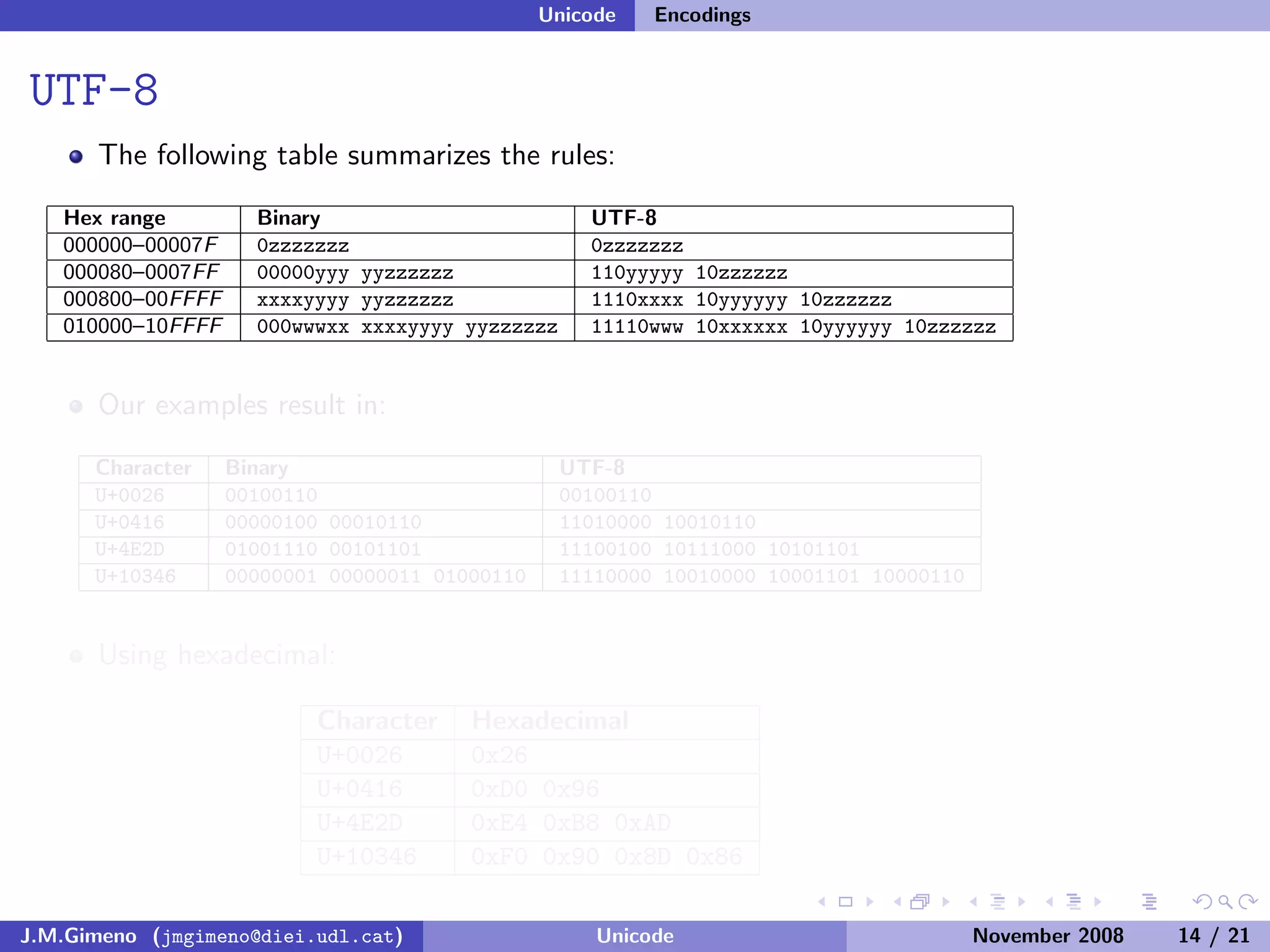
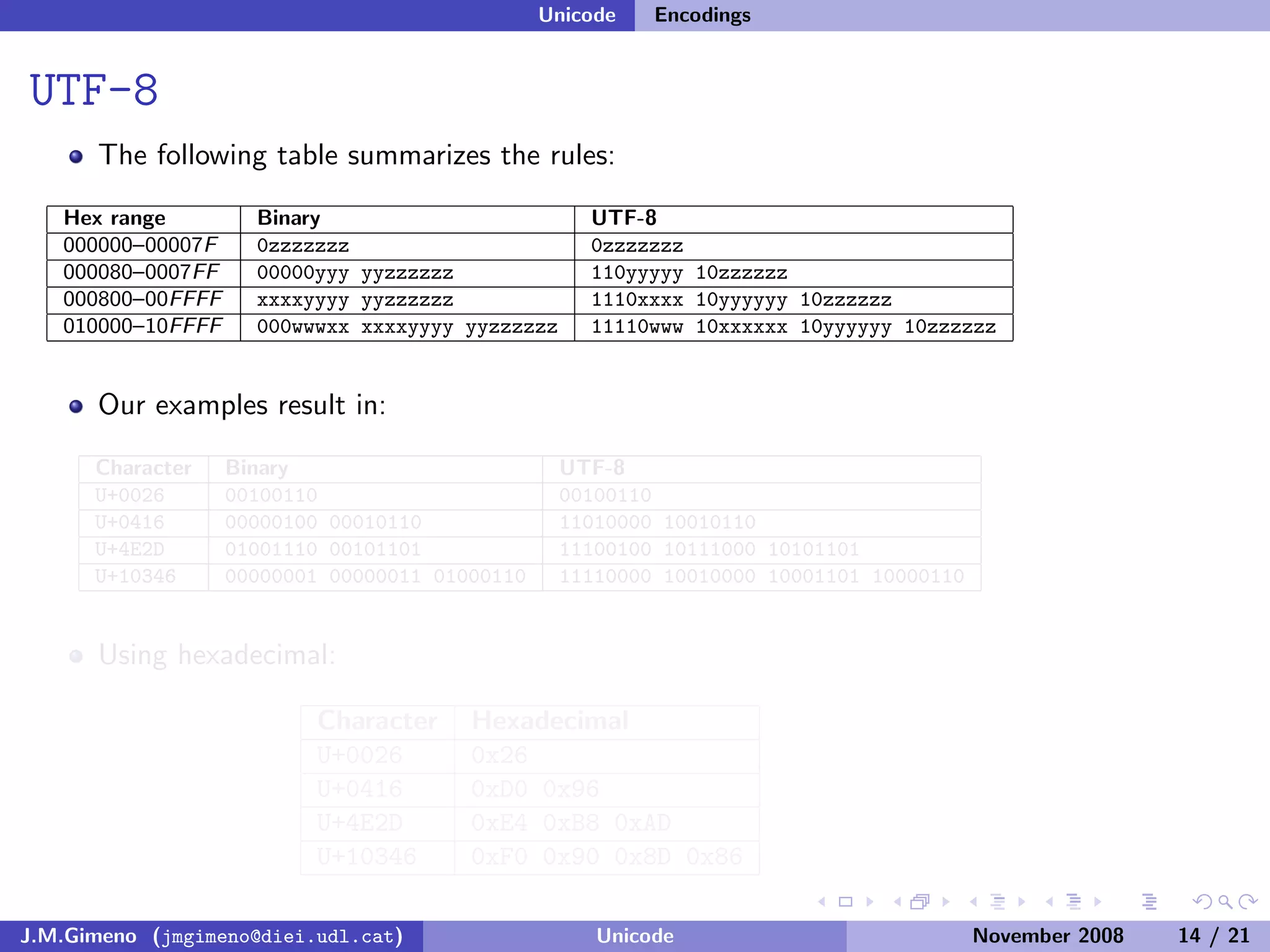
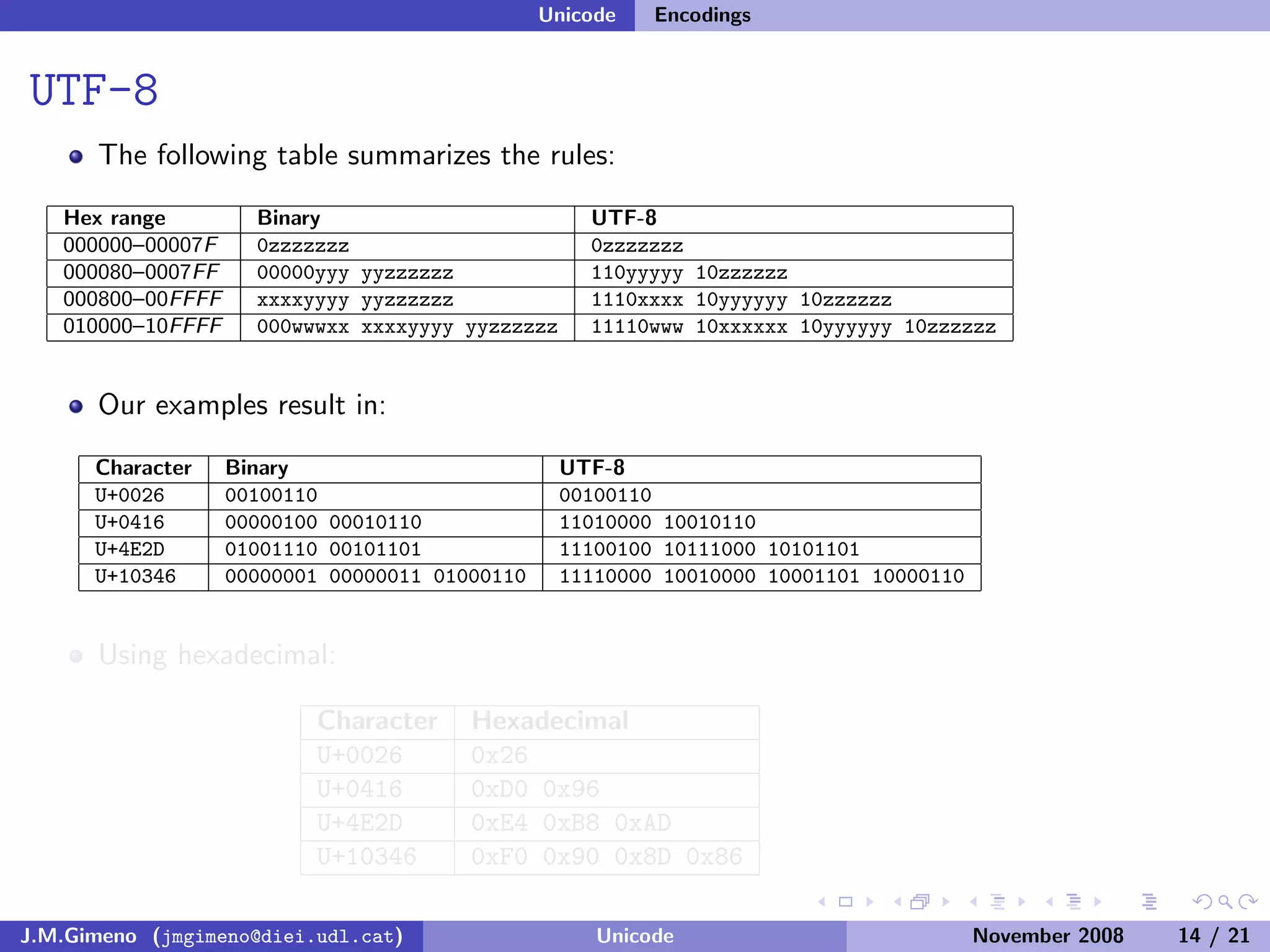
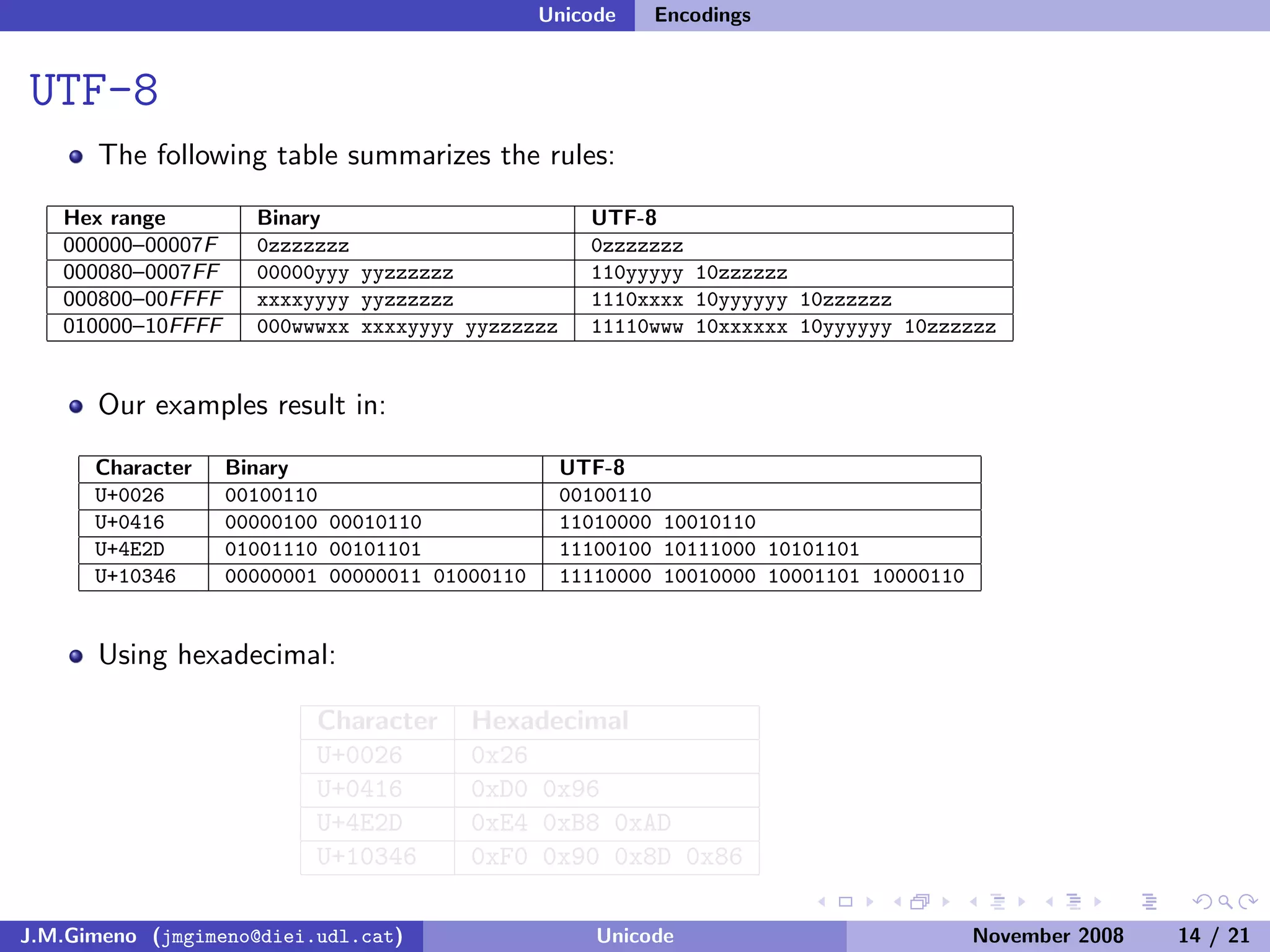
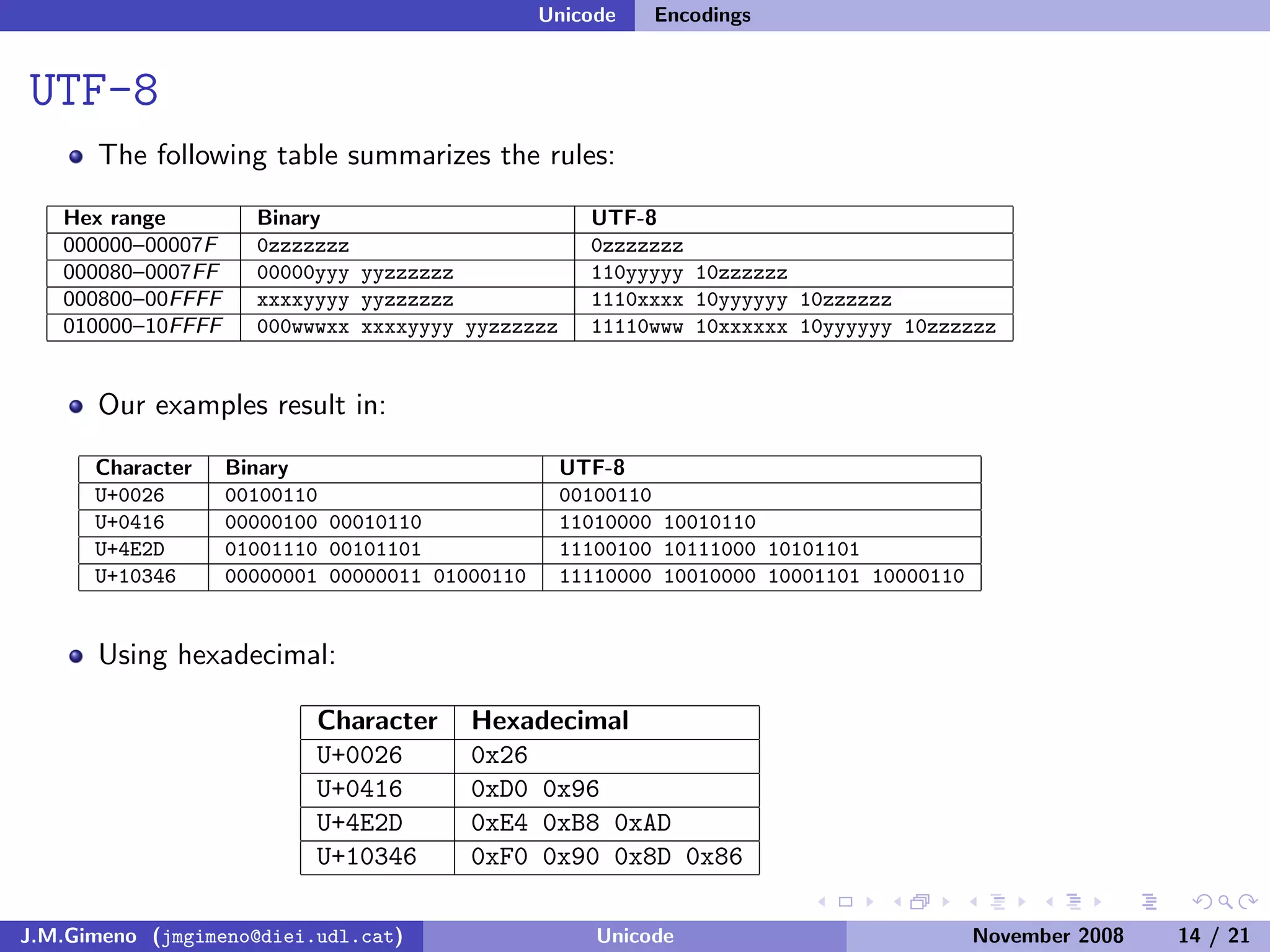











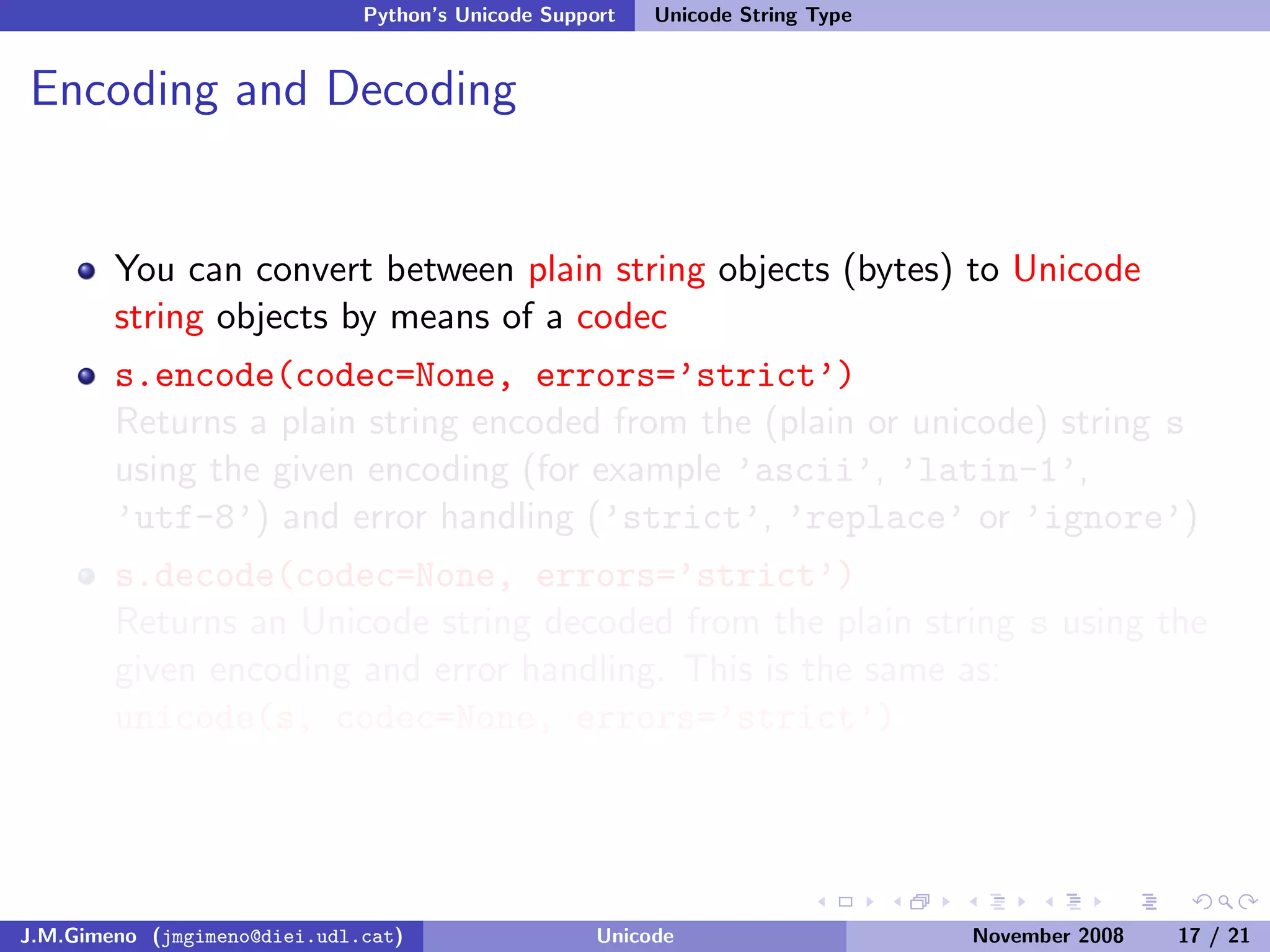
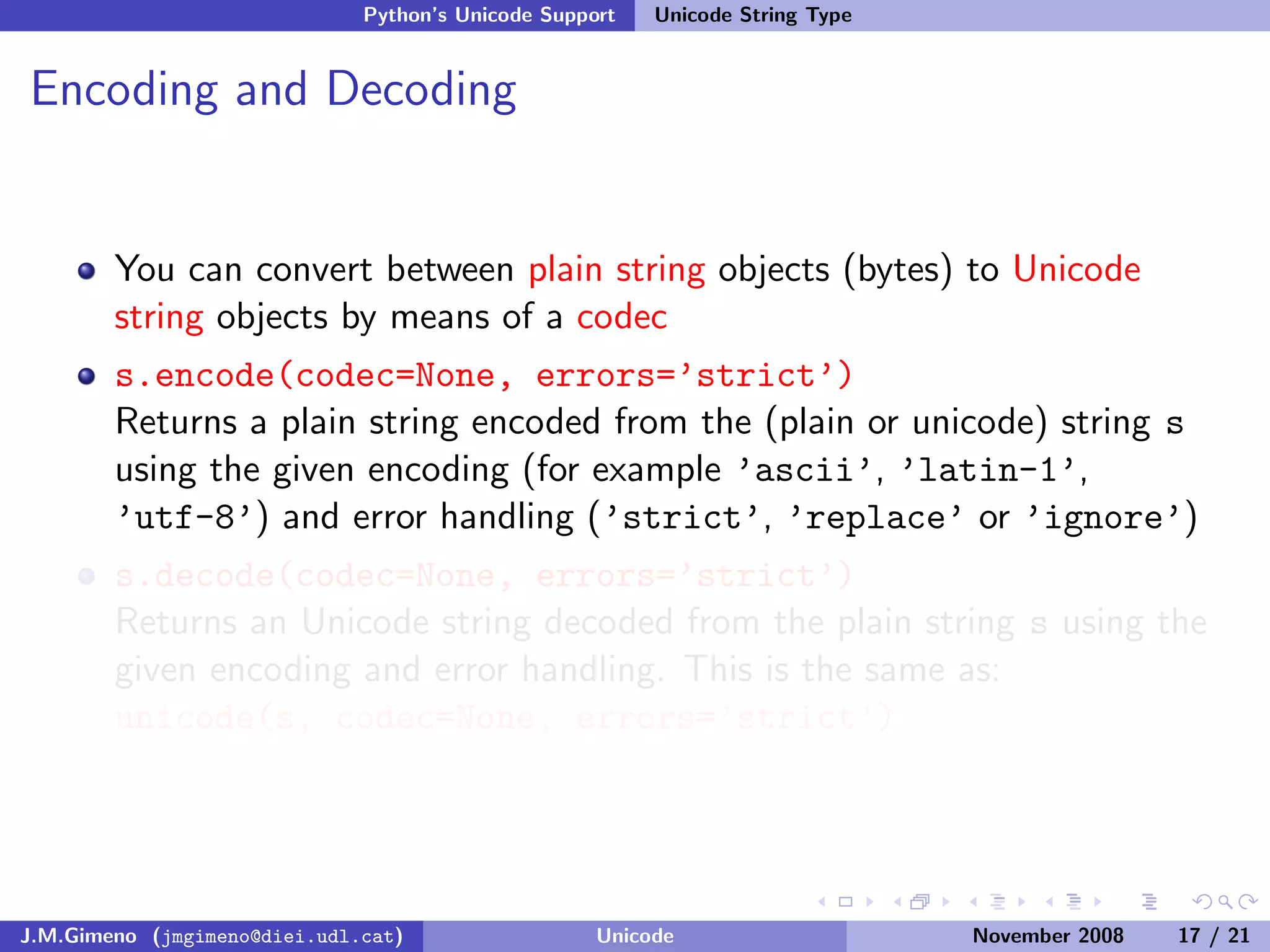











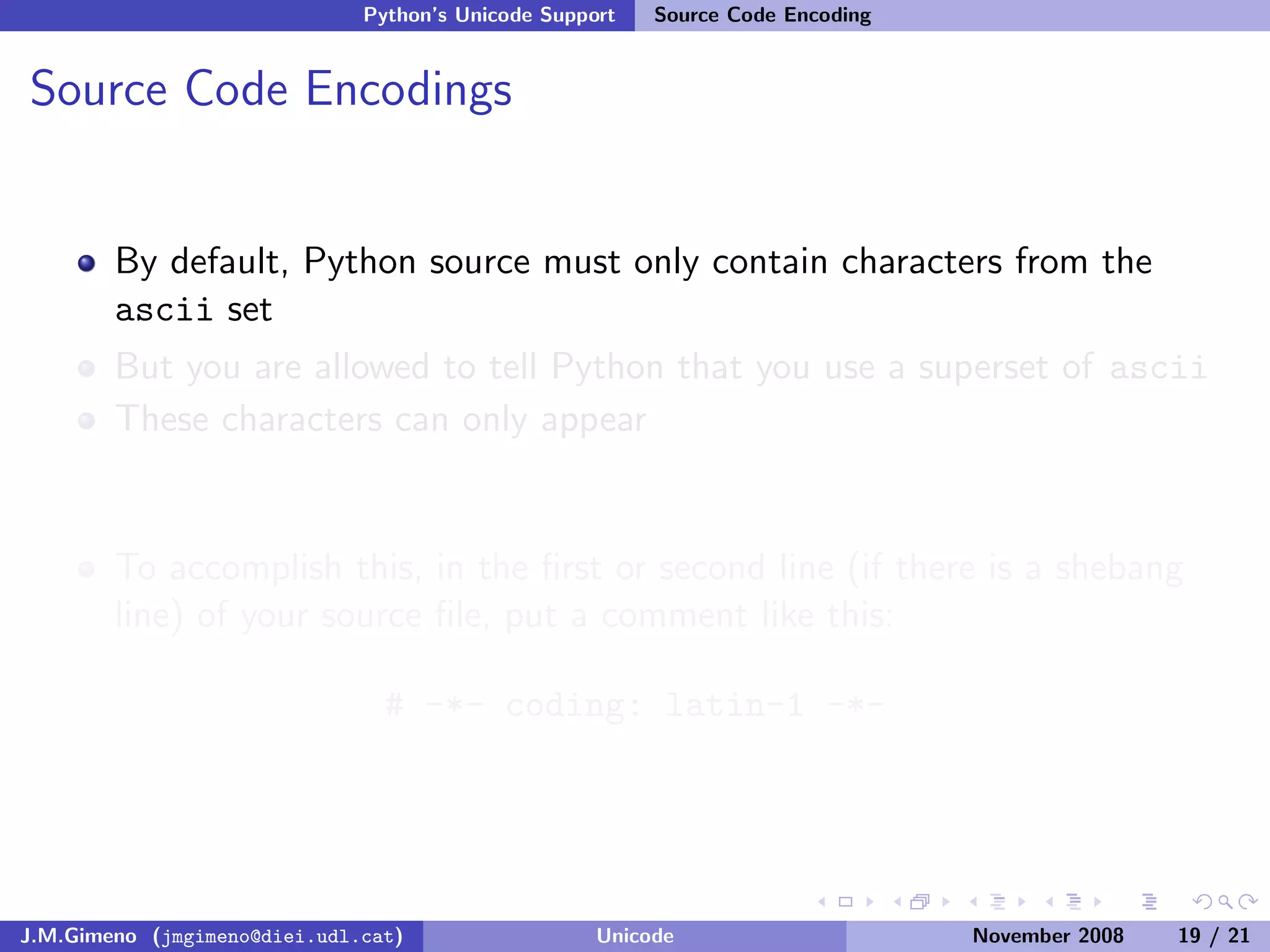









The document discusses the history of character encoding before Unicode. Originally, computing focused on English and used ASCII or EBCDIC encodings to store characters. Other regions developed their own encodings like JIS for Japan. Later, ISO-8859 provided separate encodings for different languages and scripts but text could only use one encoding. This led to the development of Unicode, which provides a single encoding to represent all languages and includes metadata about characters.











































































