Downloaded 193 times


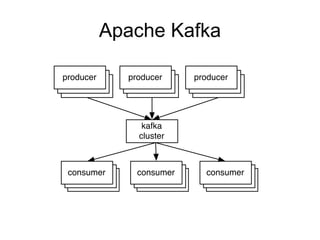


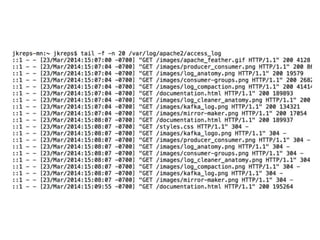
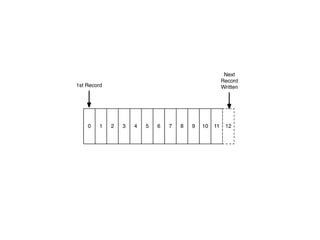
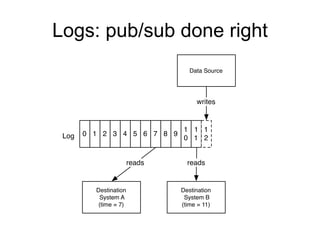
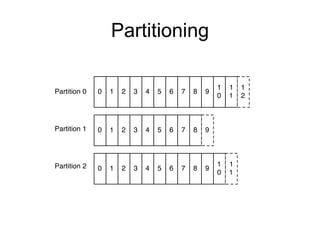
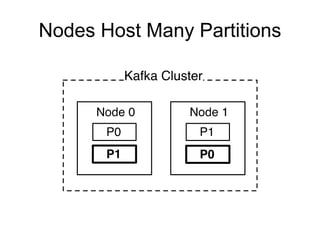
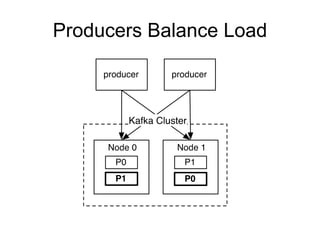

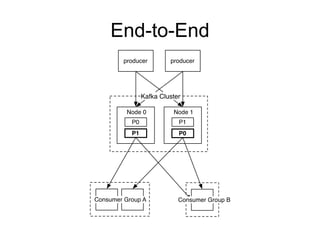


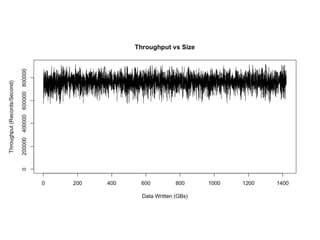


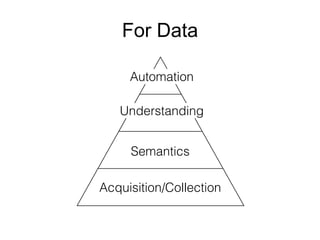



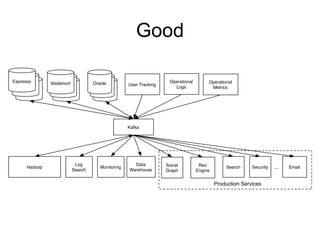
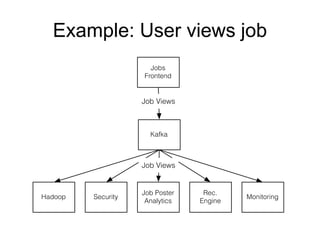




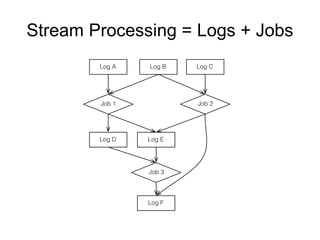


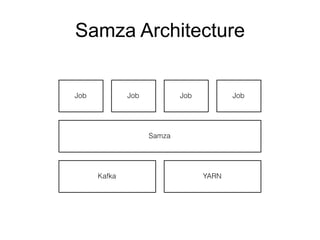
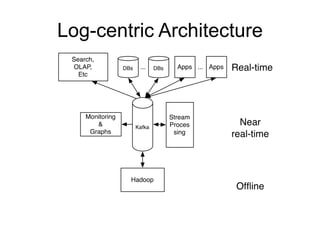



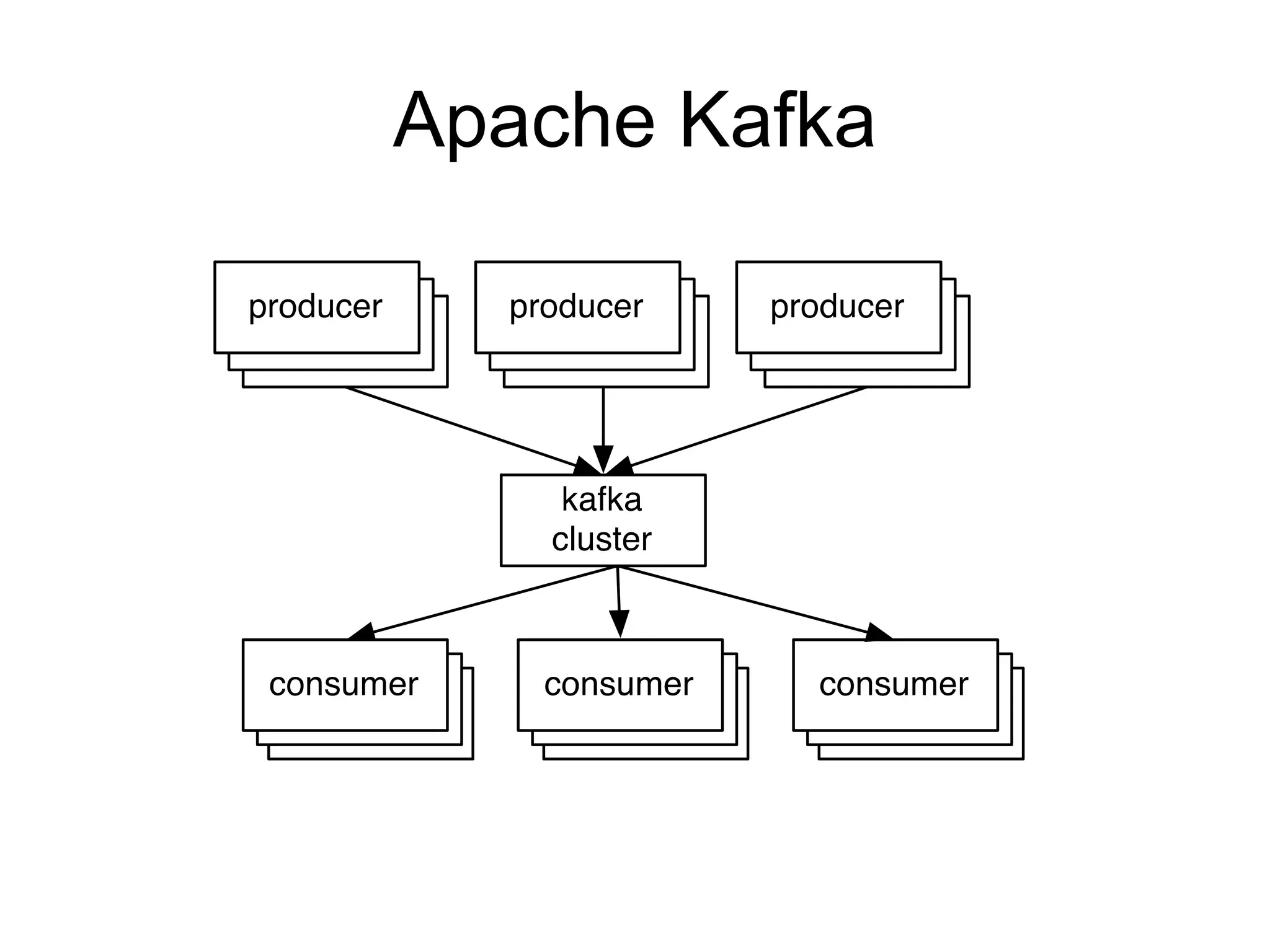



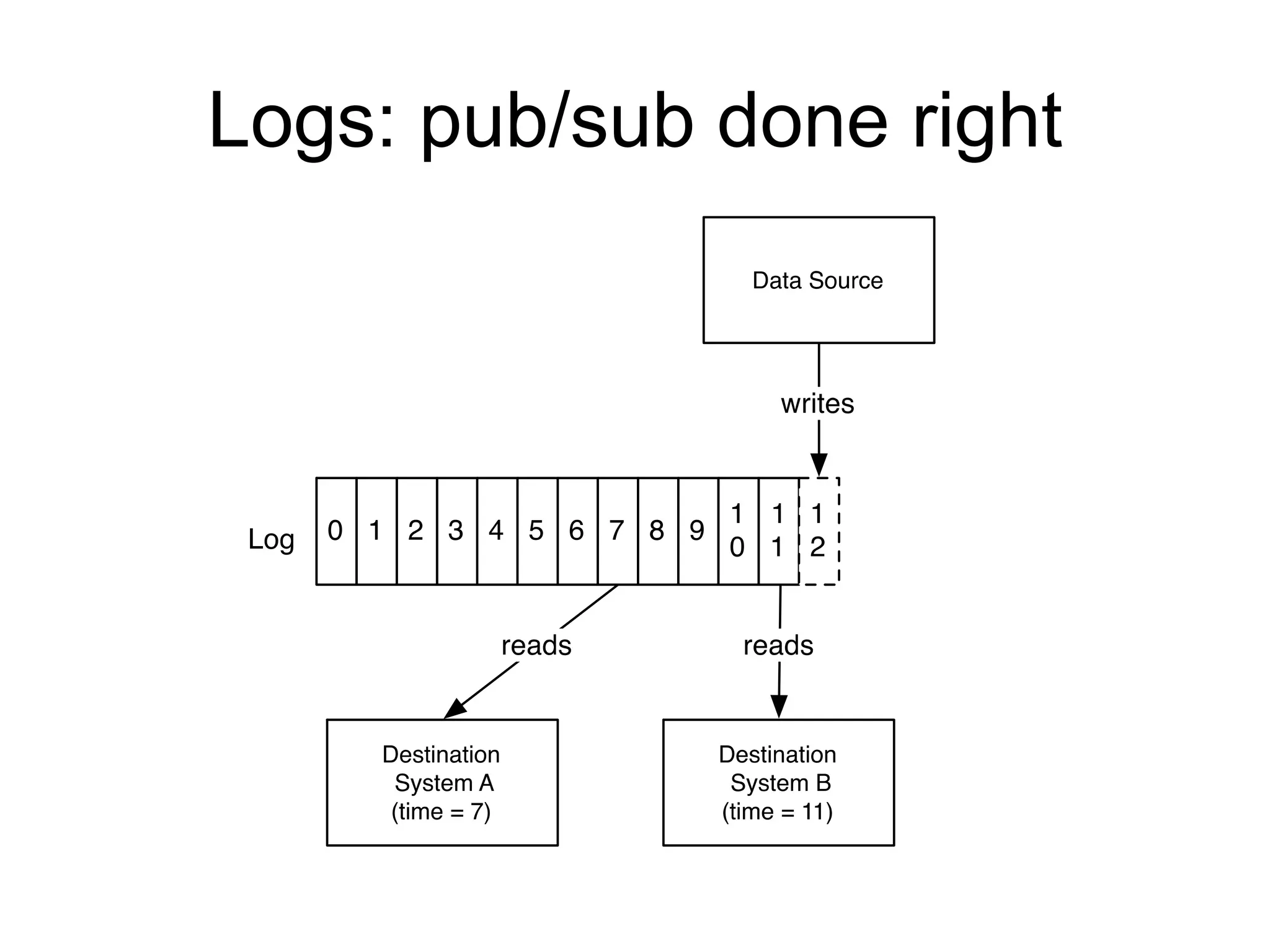



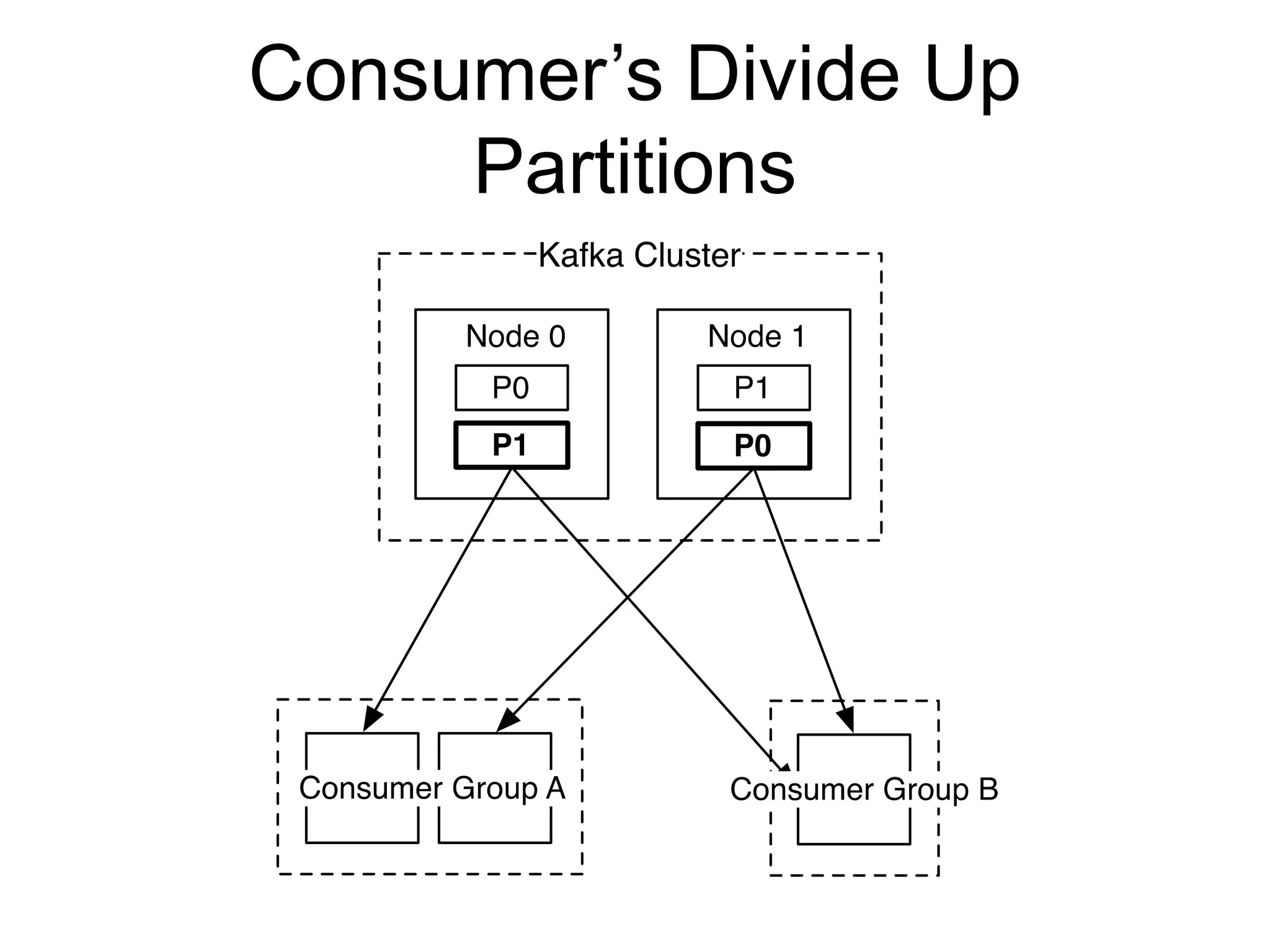
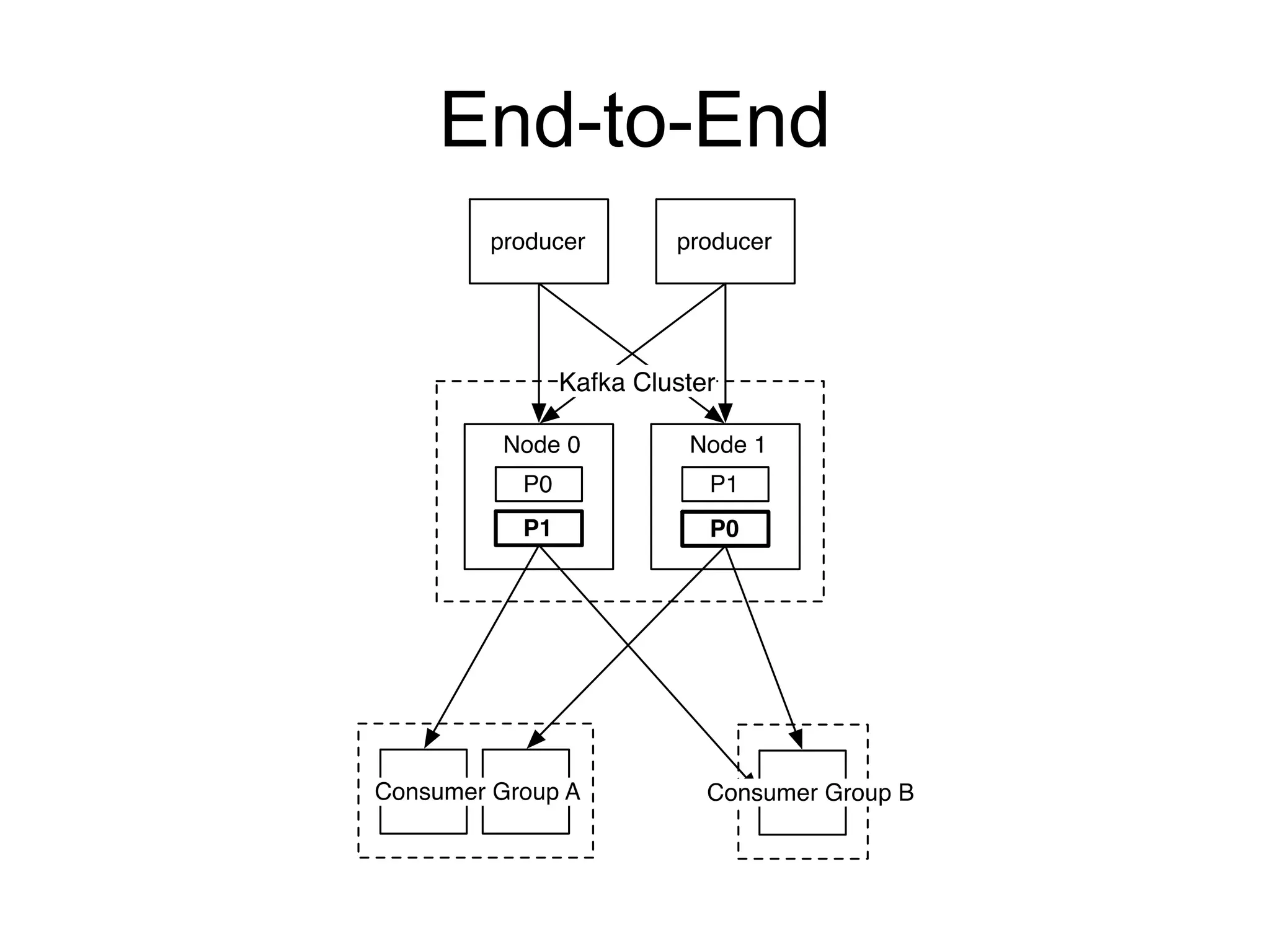




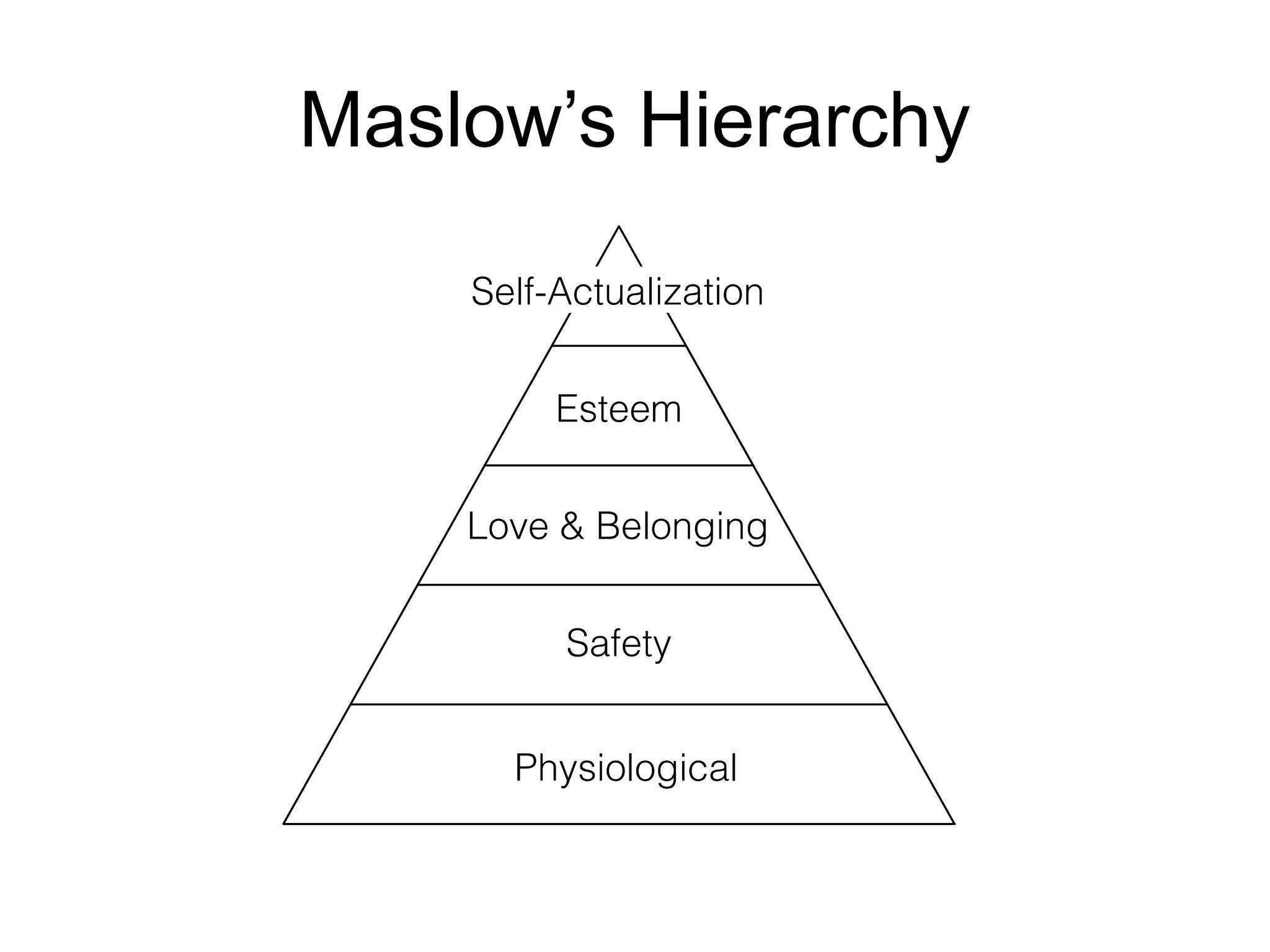
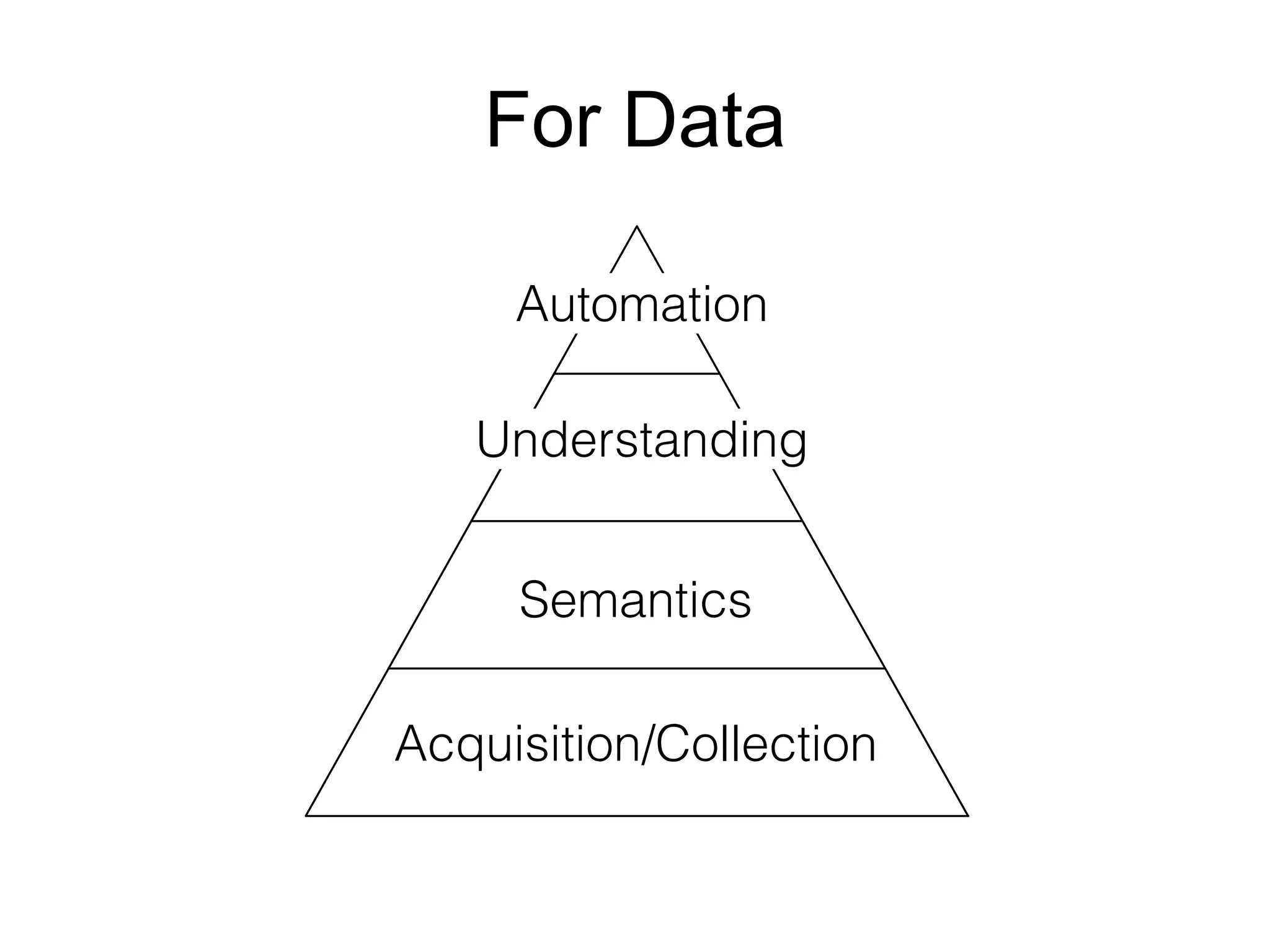


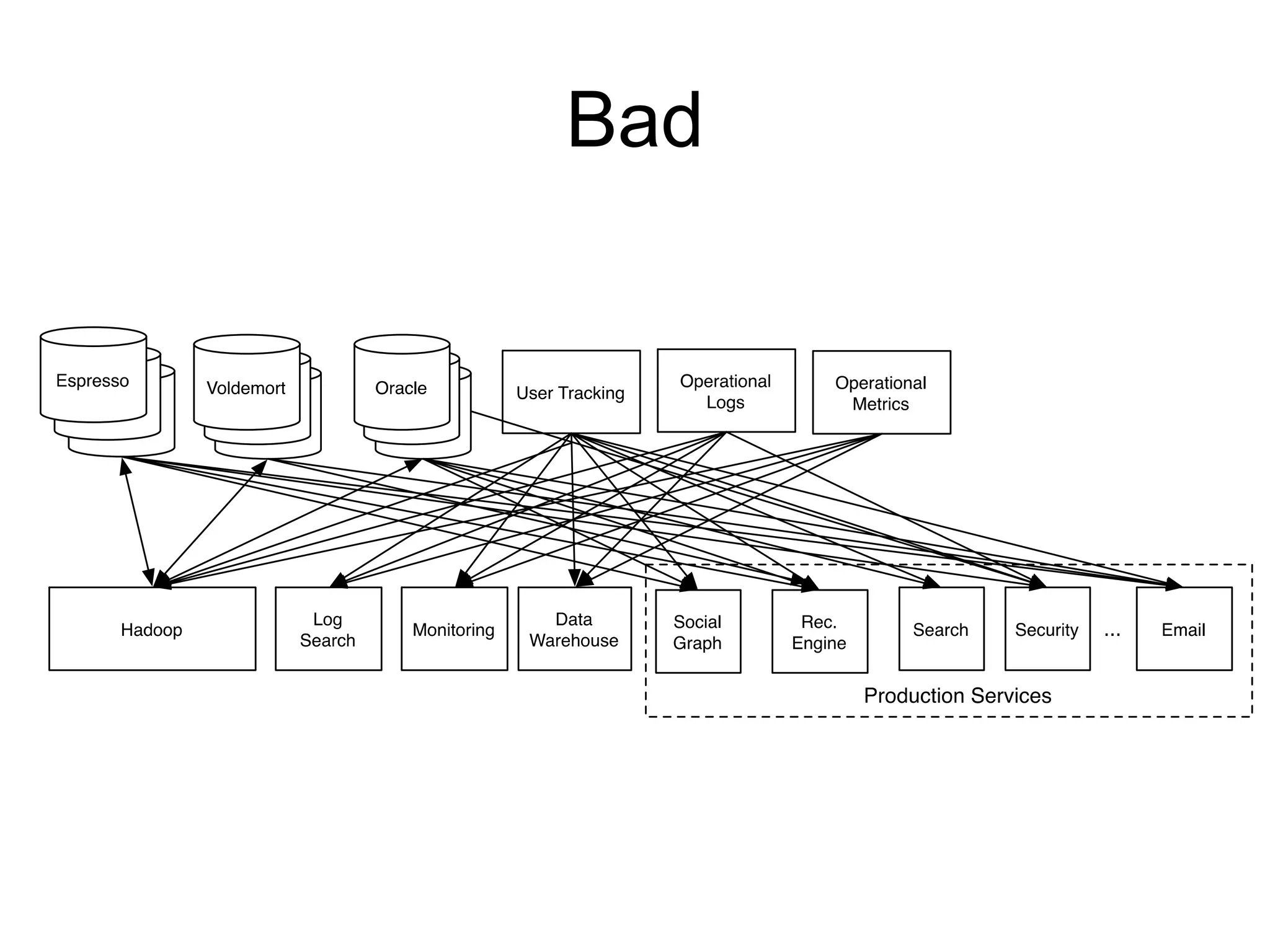
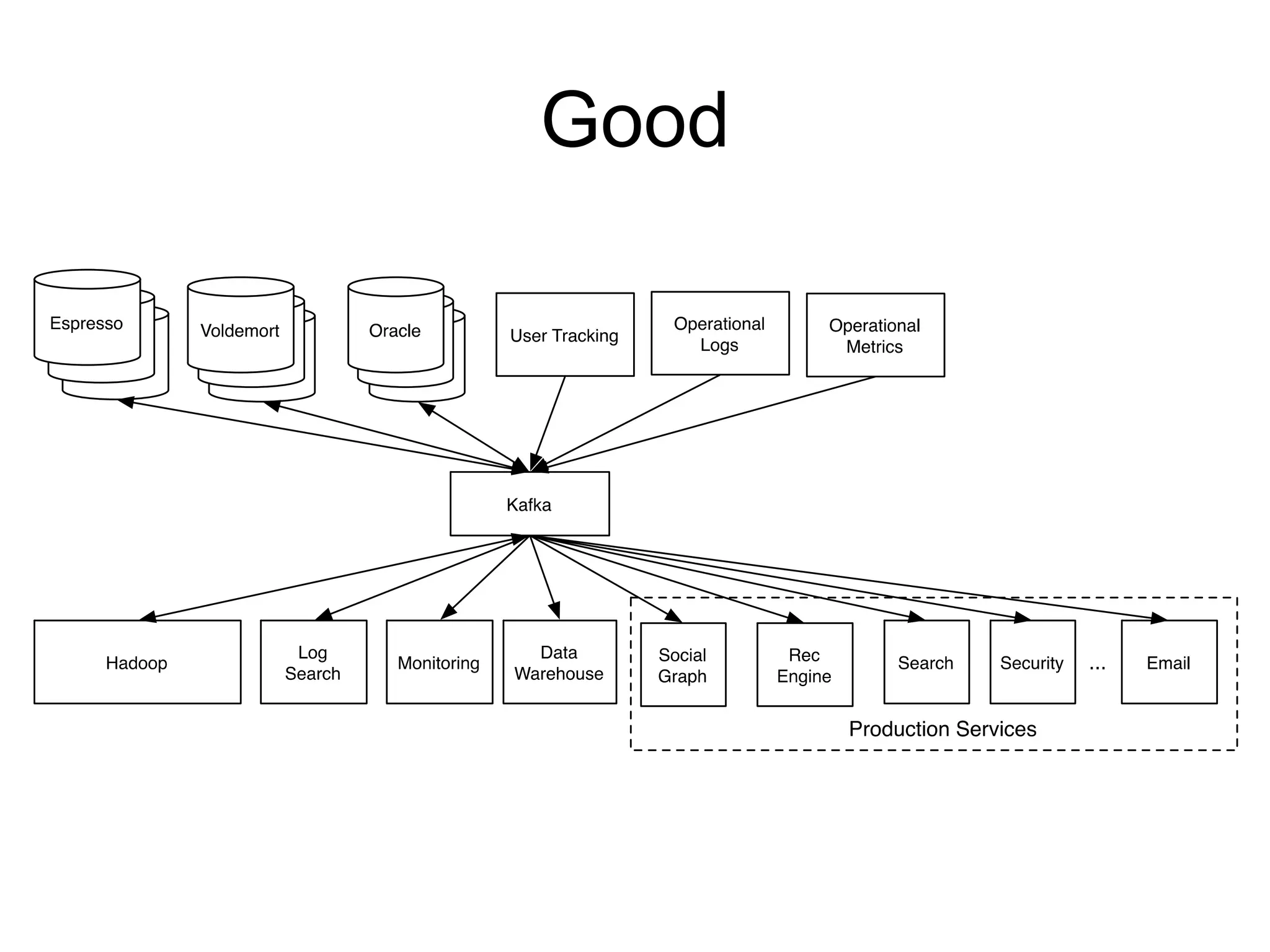
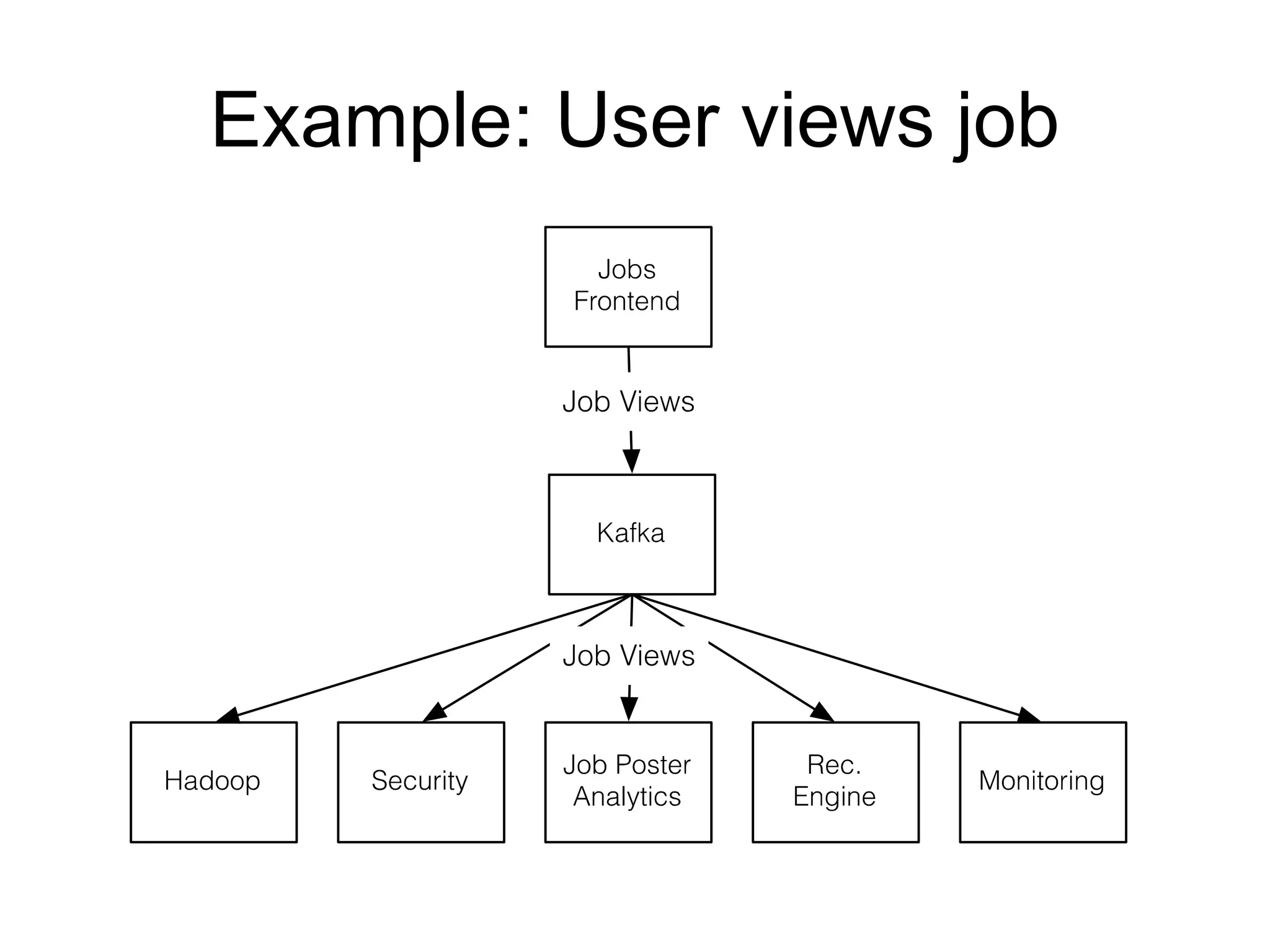




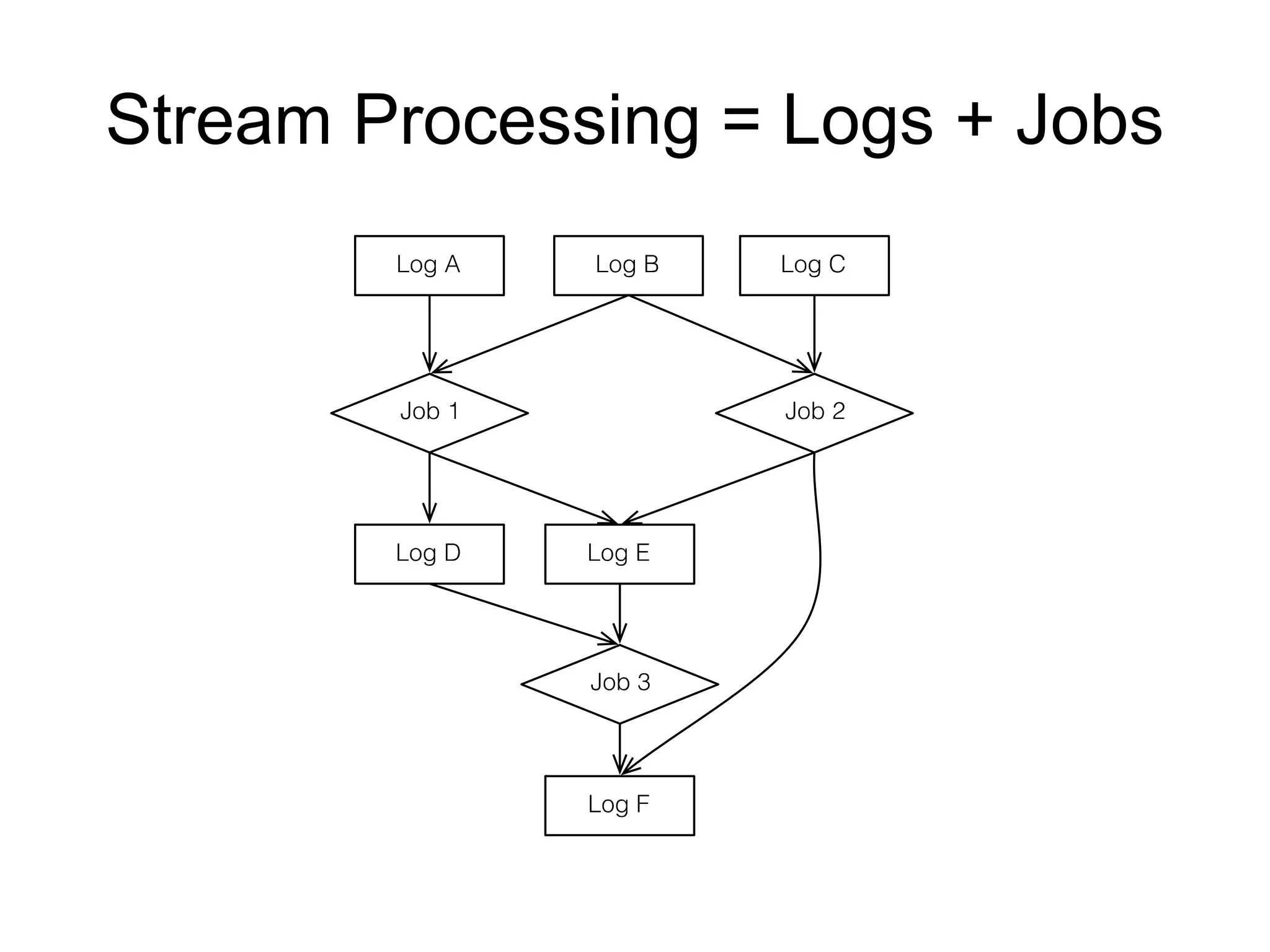


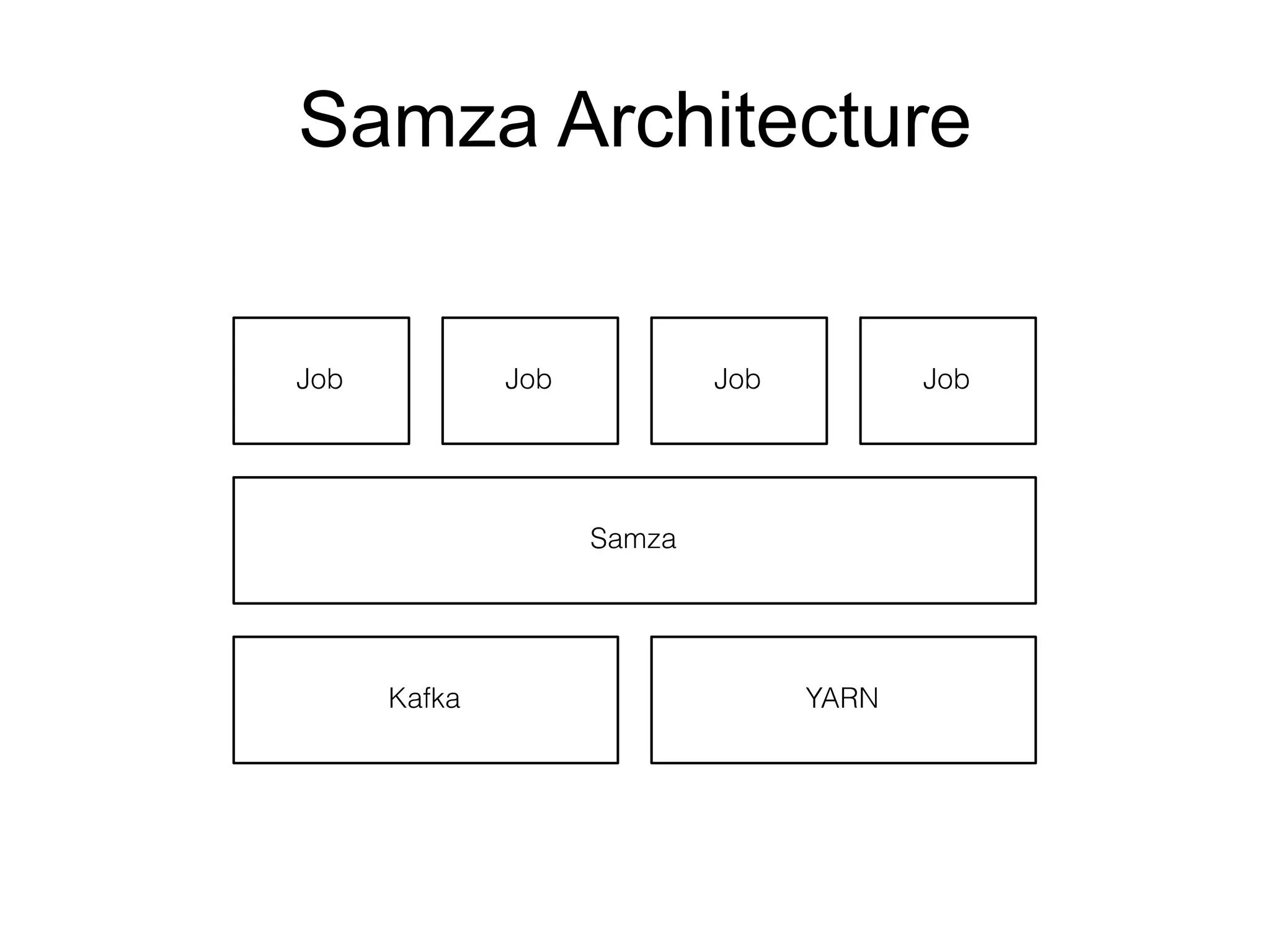
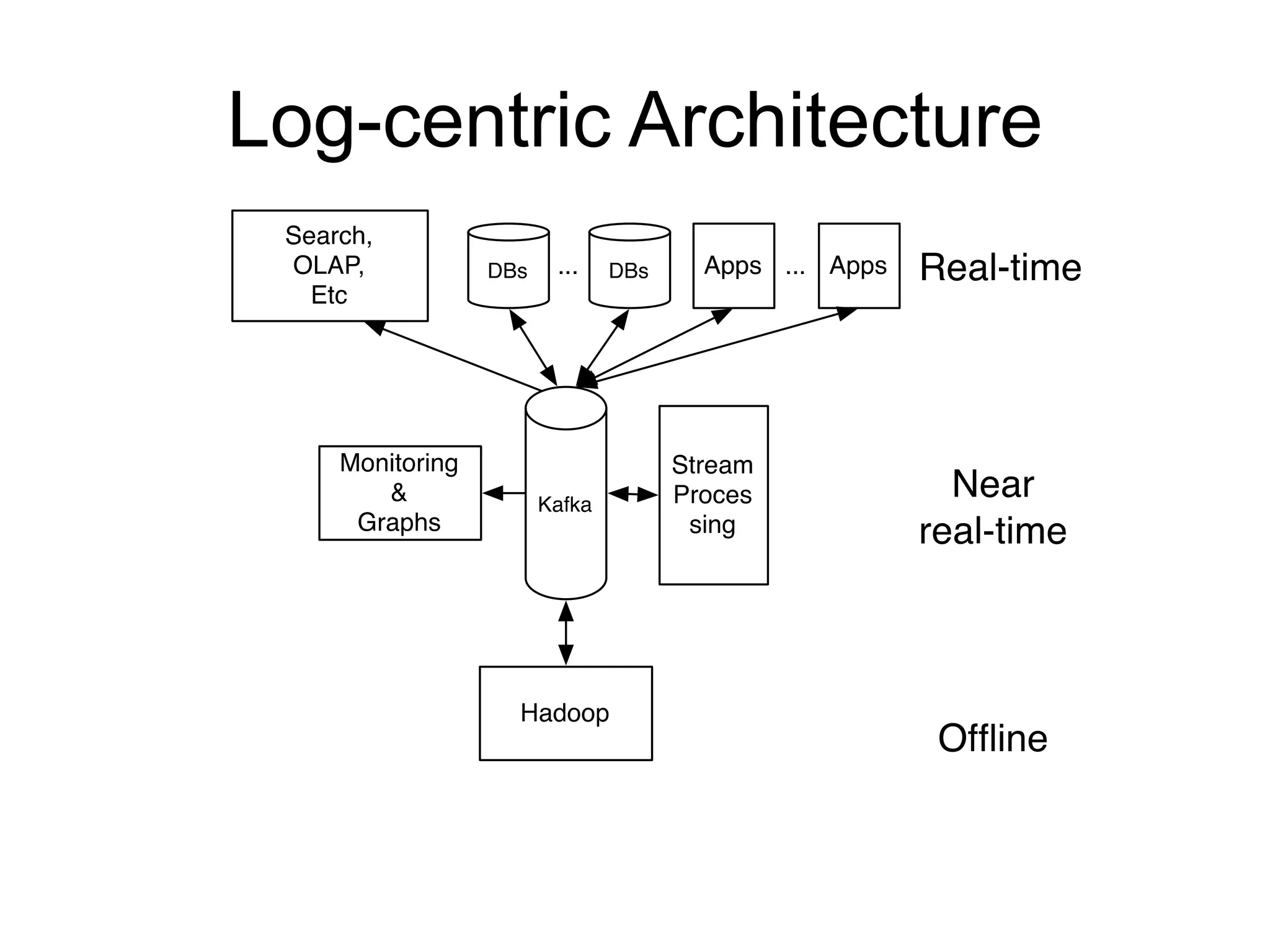


The document provides an introduction to Apache Kafka, covering its scalability, characteristics, and applications in data integration and stream processing. It highlights Kafka's history and performance metrics, including usage at LinkedIn with substantial throughput and latency figures. Additionally, it discusses the evolution of data types and systems, emphasizing the importance of log-centric architectures in modern data processing.













































![Building streaming data applications using Kafka*[Connect + Core + Streams] b...](https://cdn.slidesharecdn.com/ss_thumbnails/buildingstreamingdataapplicationsusingapachekafka-171011211455-thumbnail.jpg?width=600ounds&width=560&fit=bounds)





















