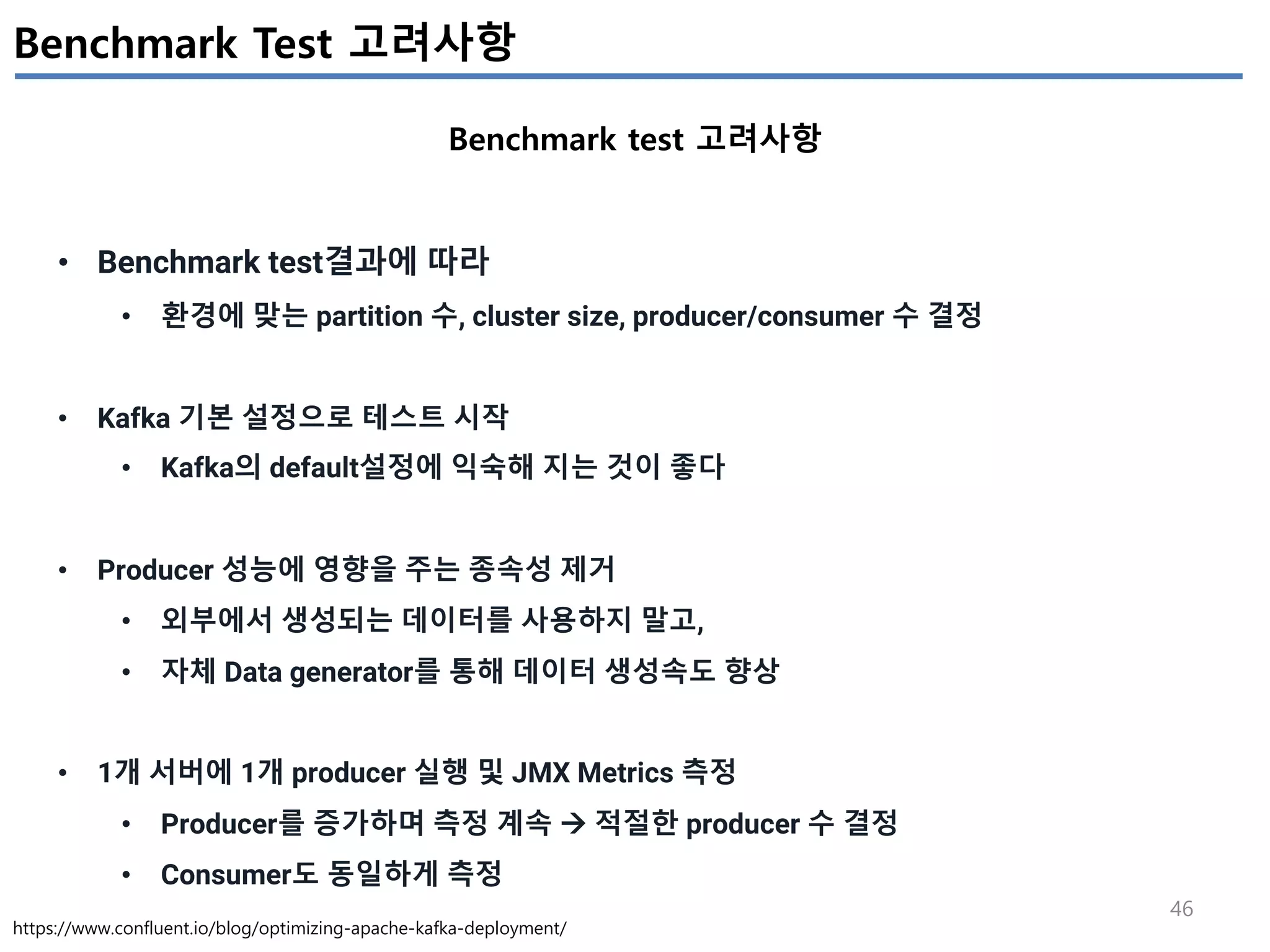
Apache Kafak의 빅데이터 아키텍처에서 역할이 점차 커지고, 중요한 비중을 차지하게 되면서, 성능에 대한 고민도 늘어나고 있다.
다양한 프로젝트를 진행하면서 Apache Kafka를 모니터링 하기 위해 필요한 Metrics들을 이해하고, 이를 최적화 하기 위한 Configruation 설정을 정리해 보았다.
[Apache kafka 모니터링을 위한 Metrics 이해 및 최적화 방안]
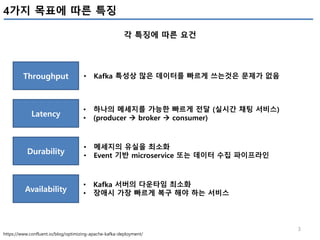
Apache Kafka 성능 모니터링에 필요한 metrics에 대해 이해하고, 4가지 관점(처리량, 지연, Durability, 가용성)에서 성능을 최적화 하는 방안을 정리함. Kafka를 구성하는 3개 모듈(Producer, Broker, Consumer)별로 성능 최적화를 위한 …
[Apache Kafka 모니터링을 위한 Metrics 이해]
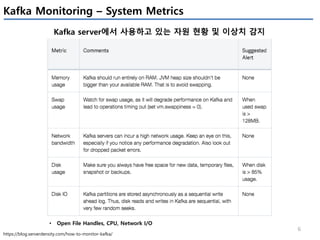
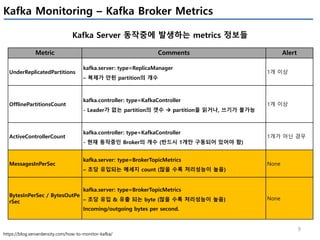
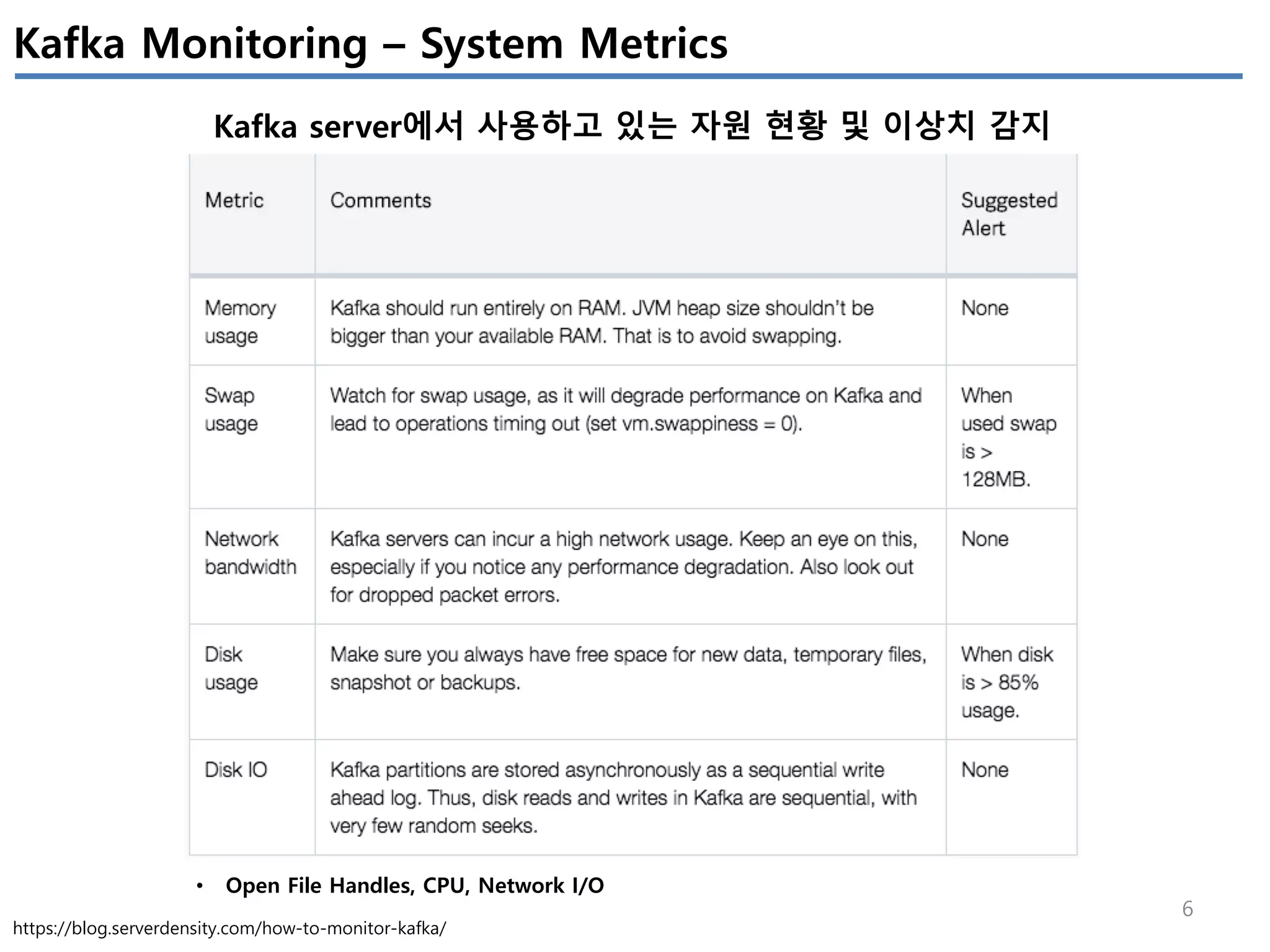
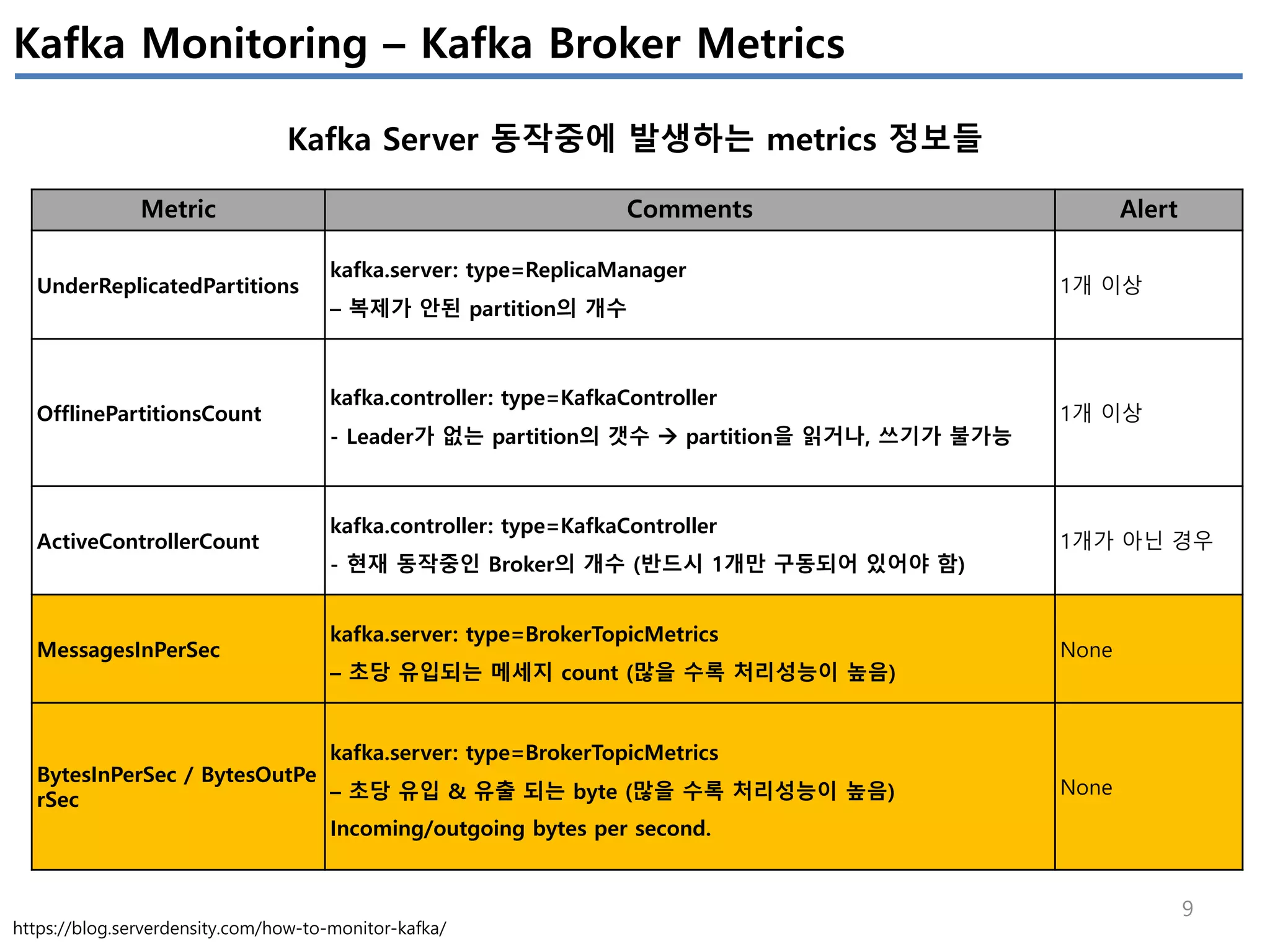
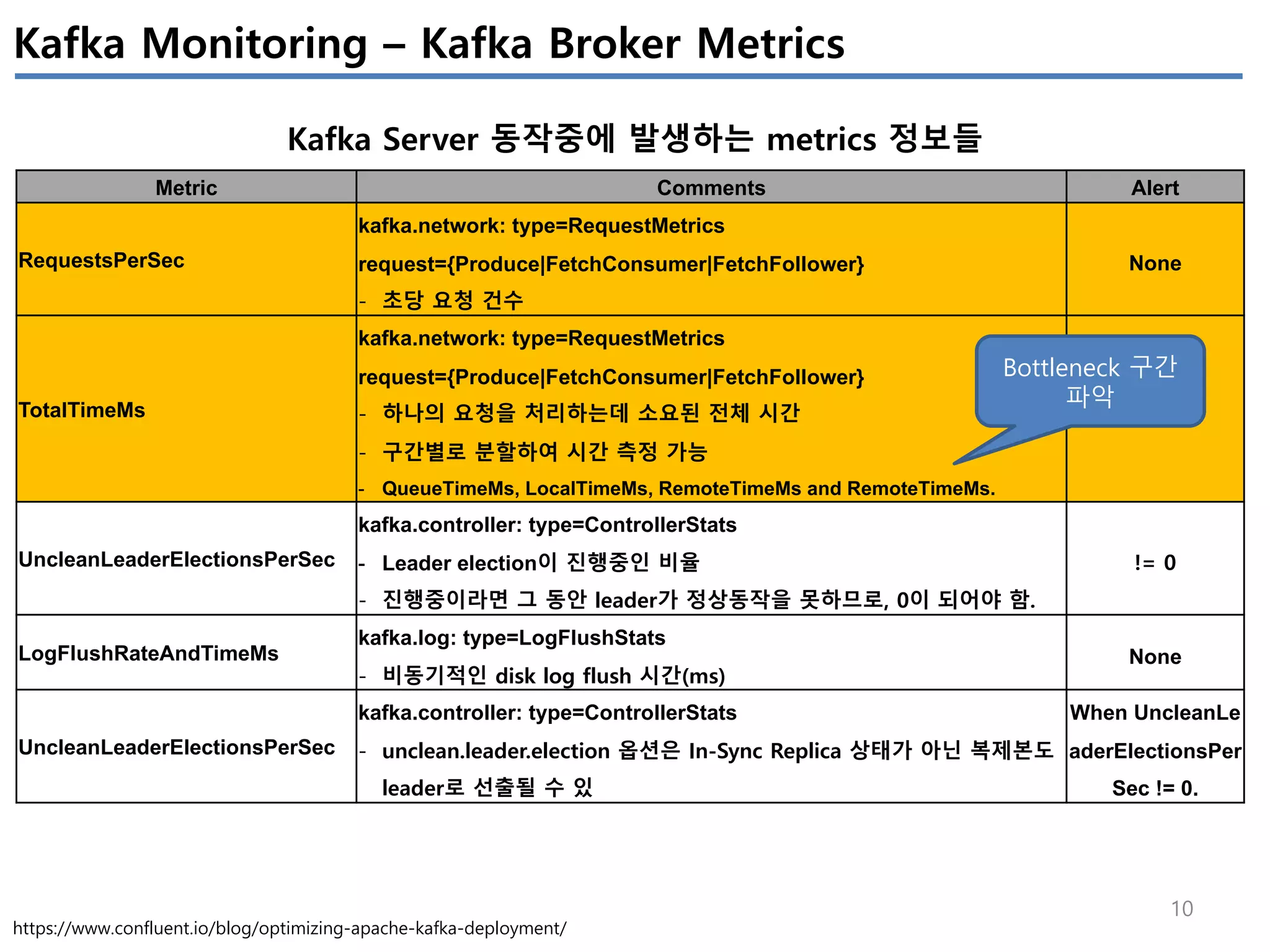
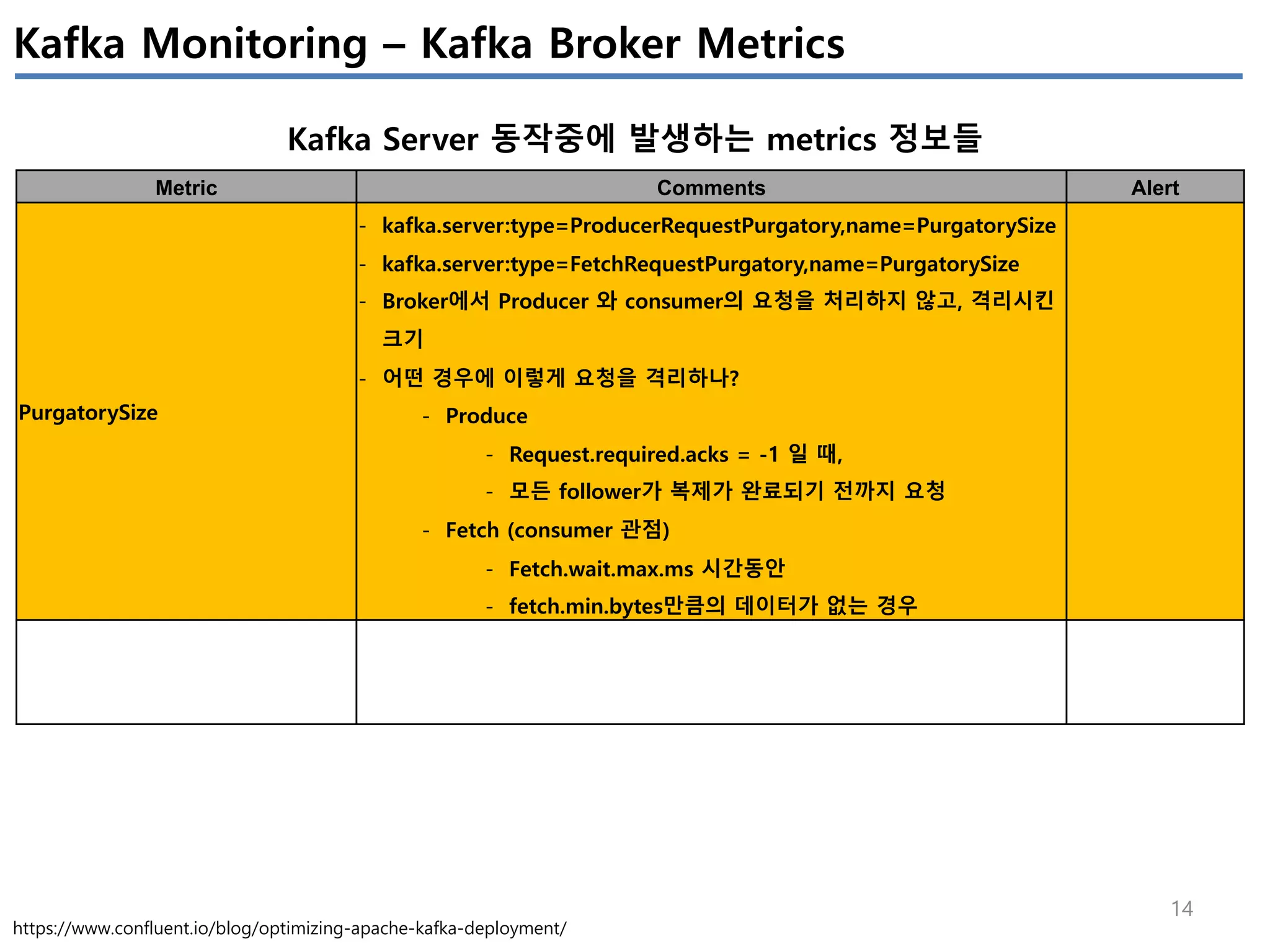
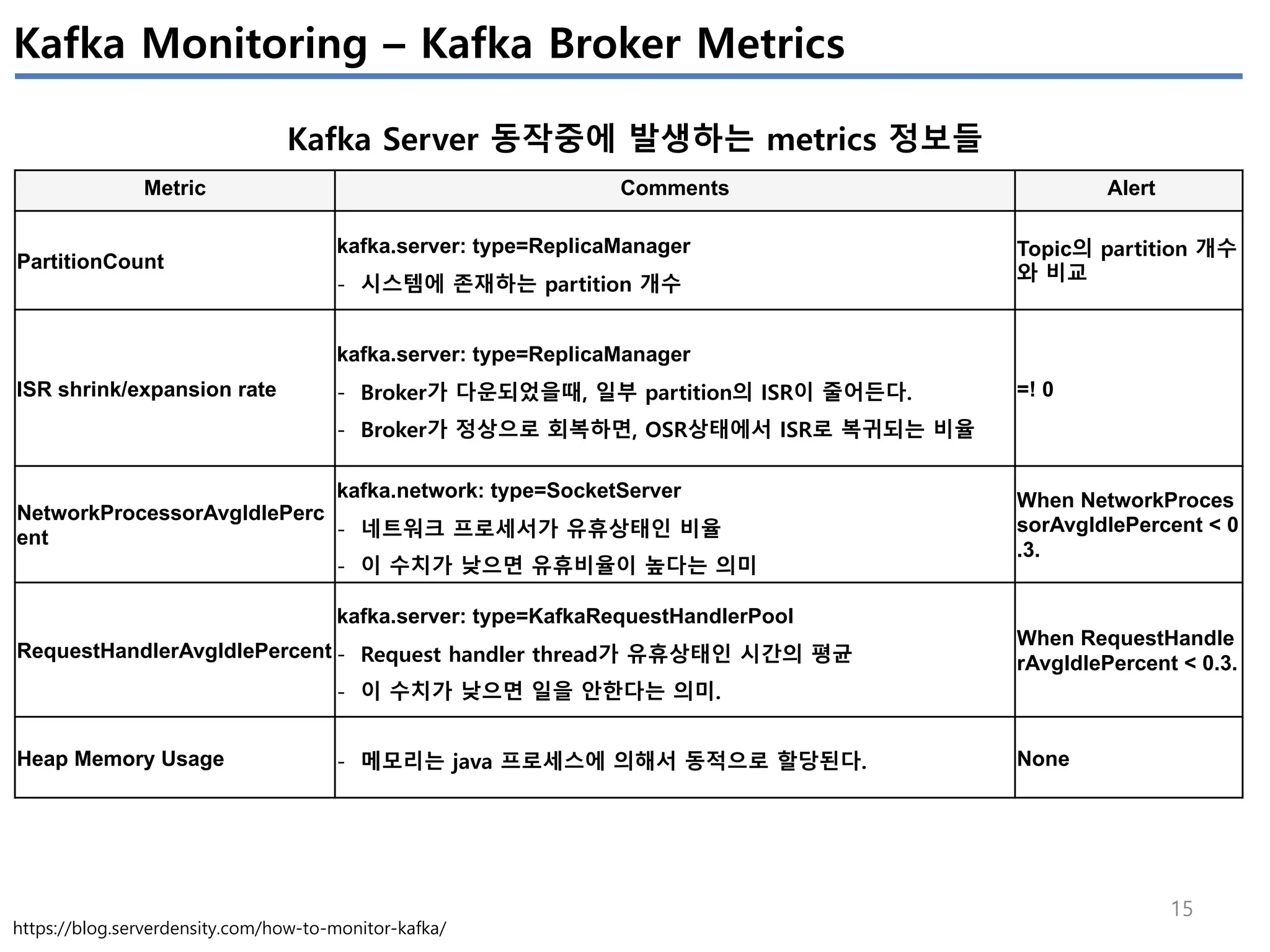
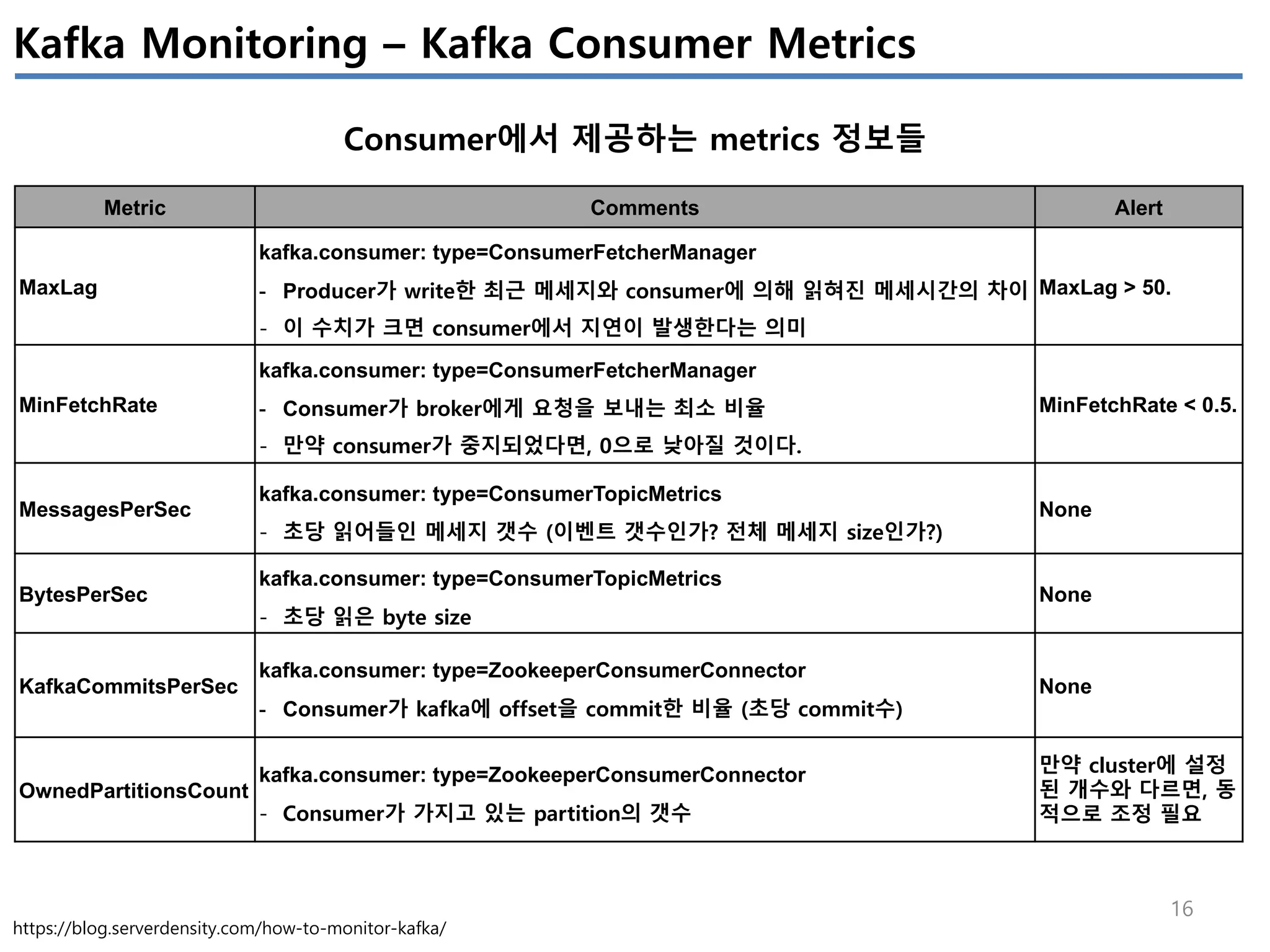
Apache Kafka의 상태를 모니터링 하기 위해서는 4개(System(OS), Producer, Broker, Consumer)에서 발생하는 metrics들을 살펴봐야 한다.
이번 글에서는 JVM에서 제공하는 JMX metrics를 중심으로 producer/broker/consumer의 지표를 정리하였다.
모든 지표를 정리하진 않았고, 내 관점에서 유의미한 지표들을 중심으로 이해한 내용임
[Apache Kafka 성능 Configuration 최적화]
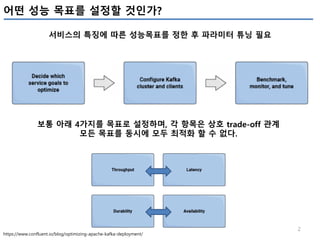
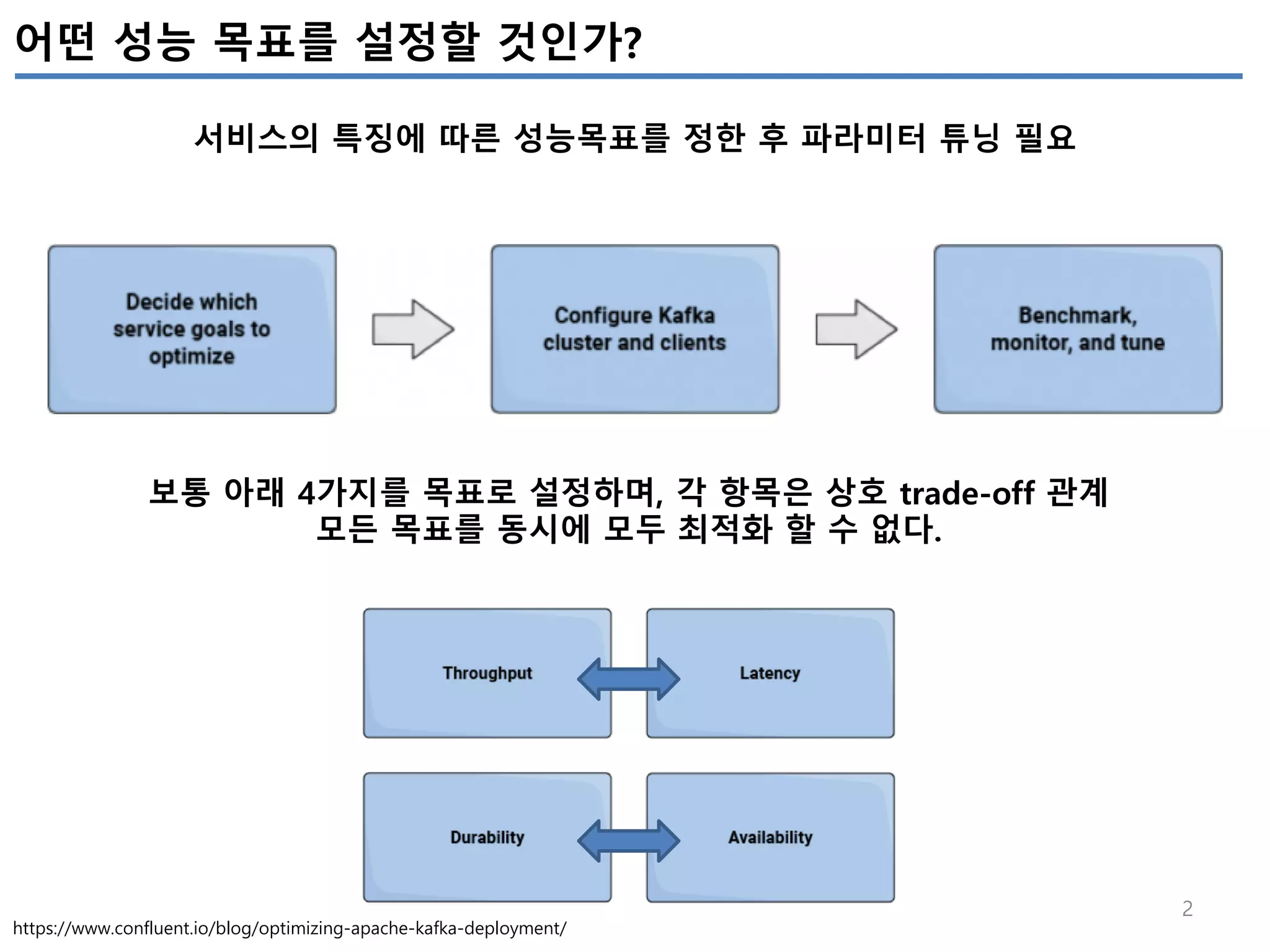
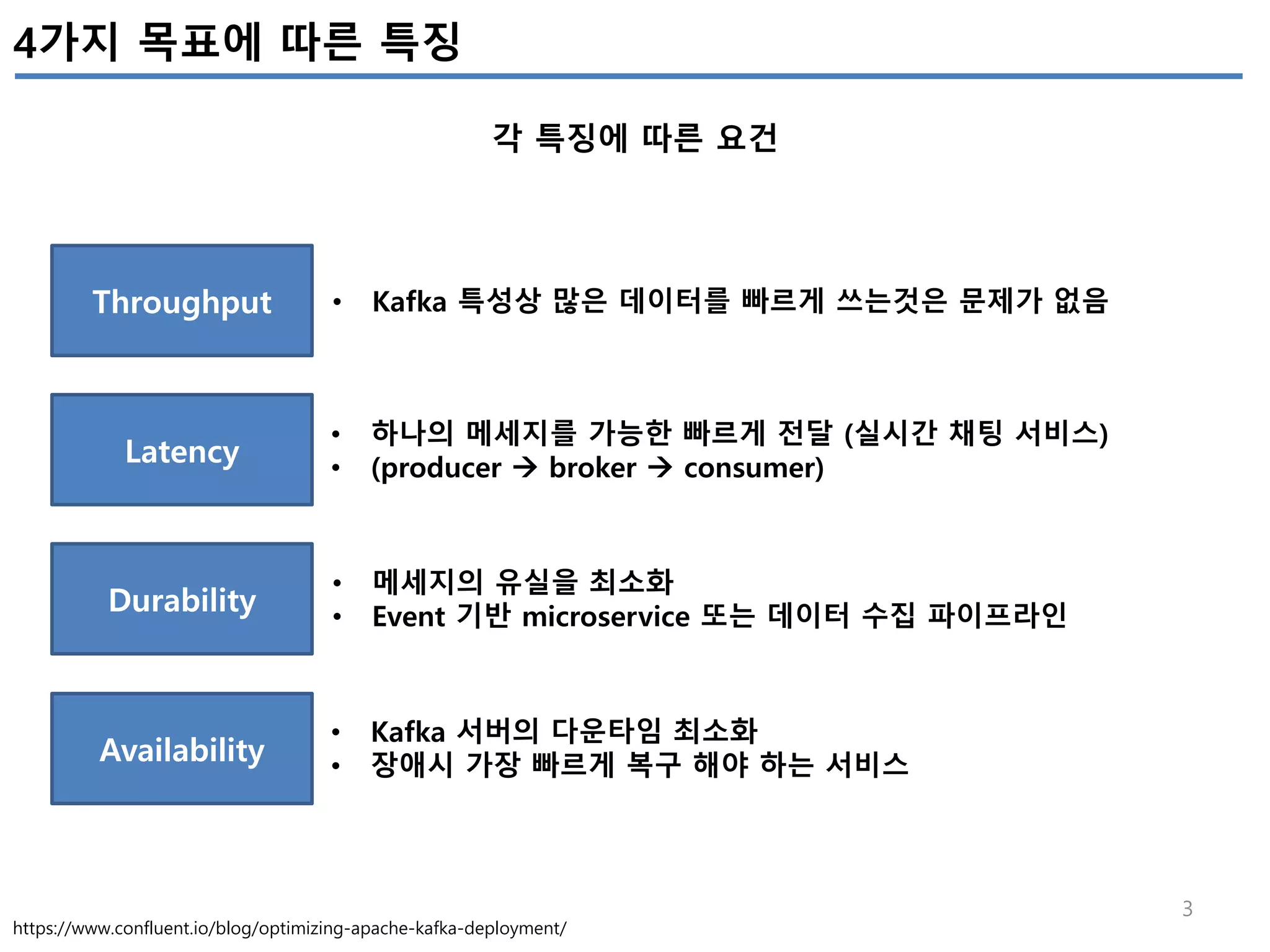
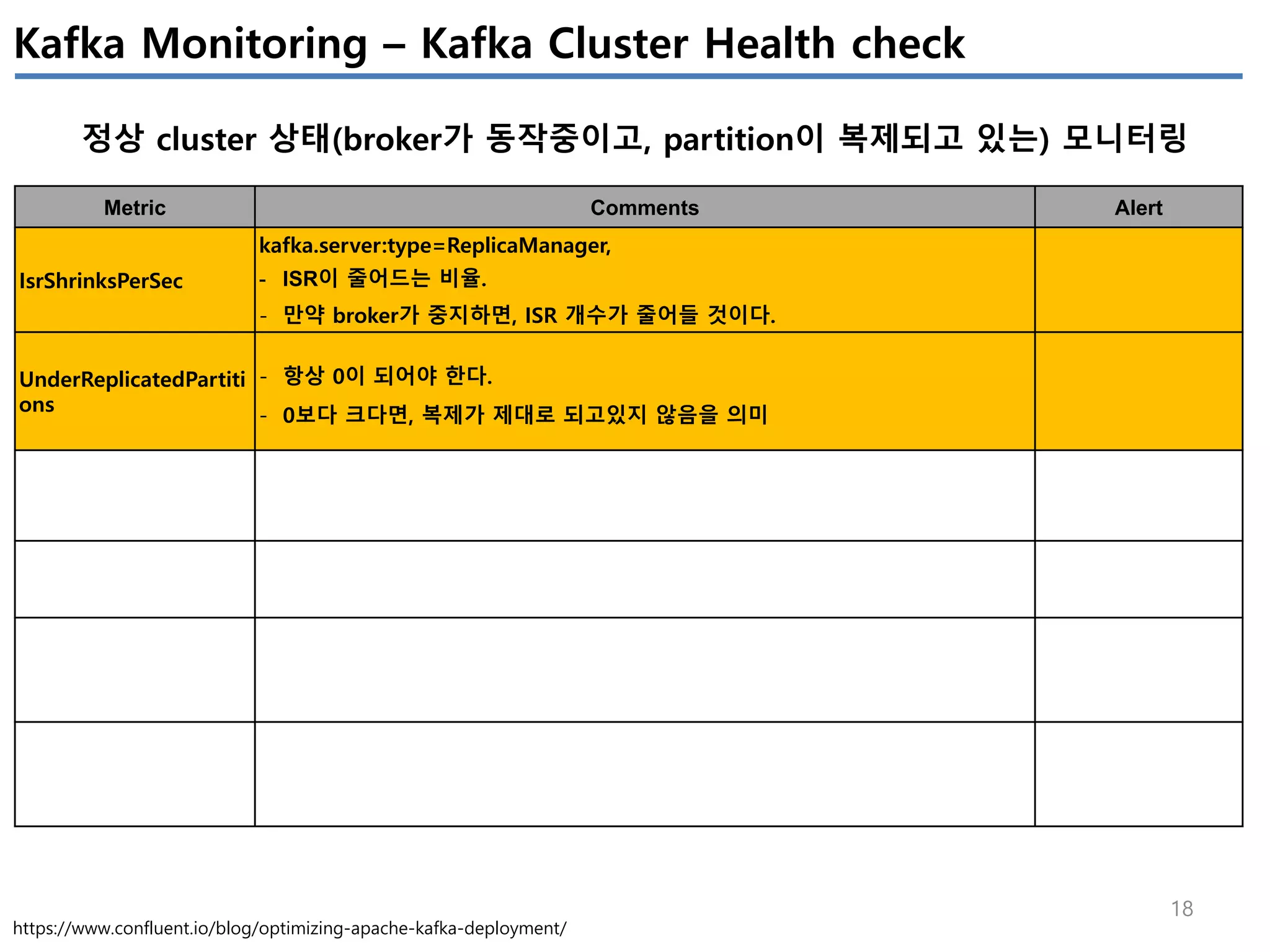
성능목표를 4개로 구분(Throughtput, Latency, Durability, Avalibility)하고, 각 목표에 따라 어떤 Kafka configuration의 조정을 어떻게 해야하는지 정리하였다.
튜닝한 파라미터를 적용한 후, 성능테스트를 수행하면서 추출된 Metrics를 모니터링하여 현재 업무에 최적화 되도록 최적화를 수행하는 것이 필요하다.






![17
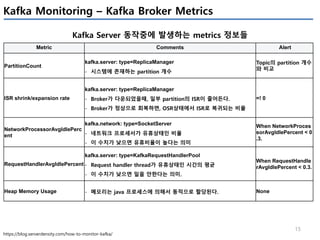
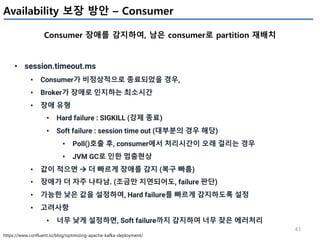
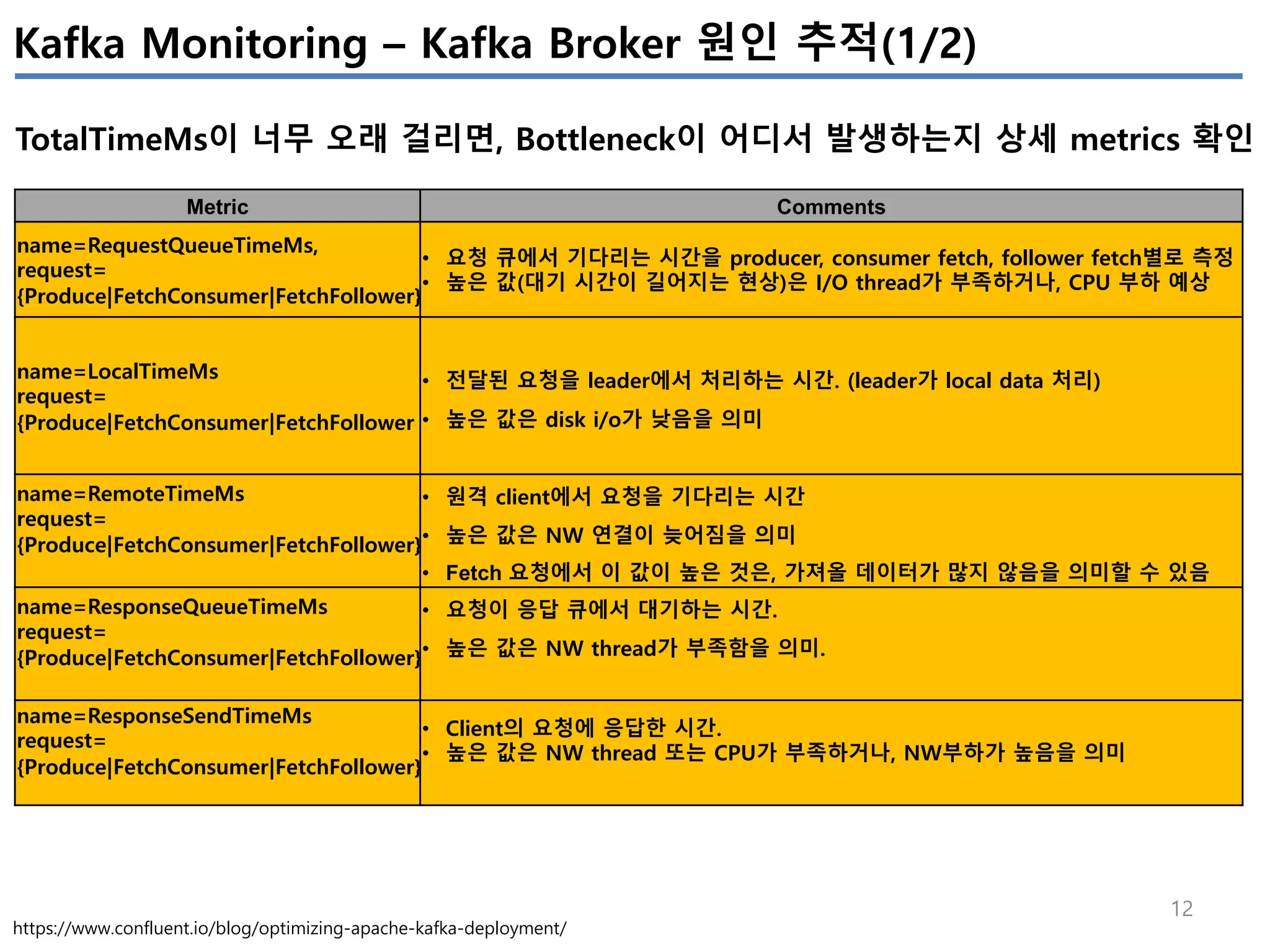
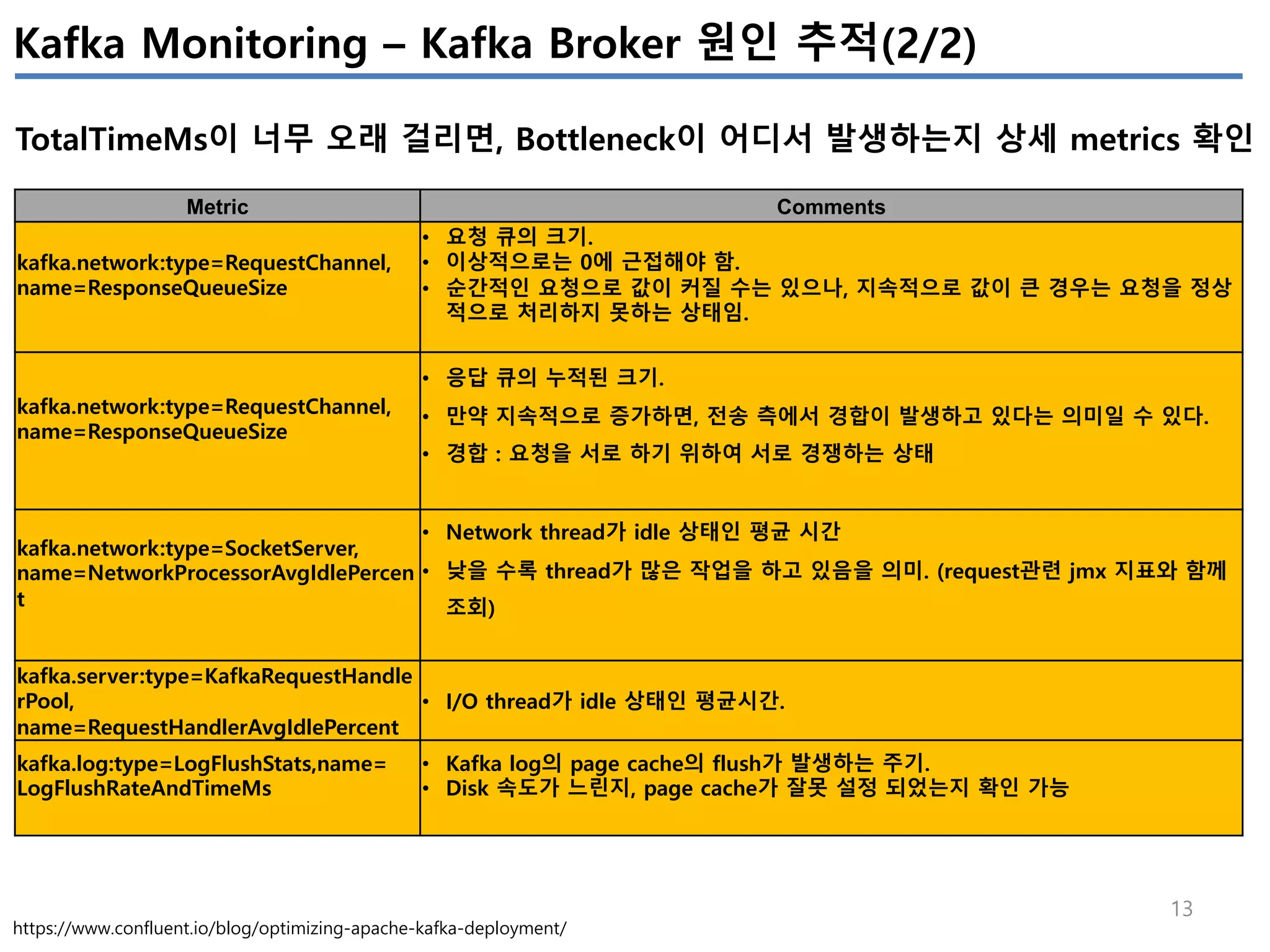
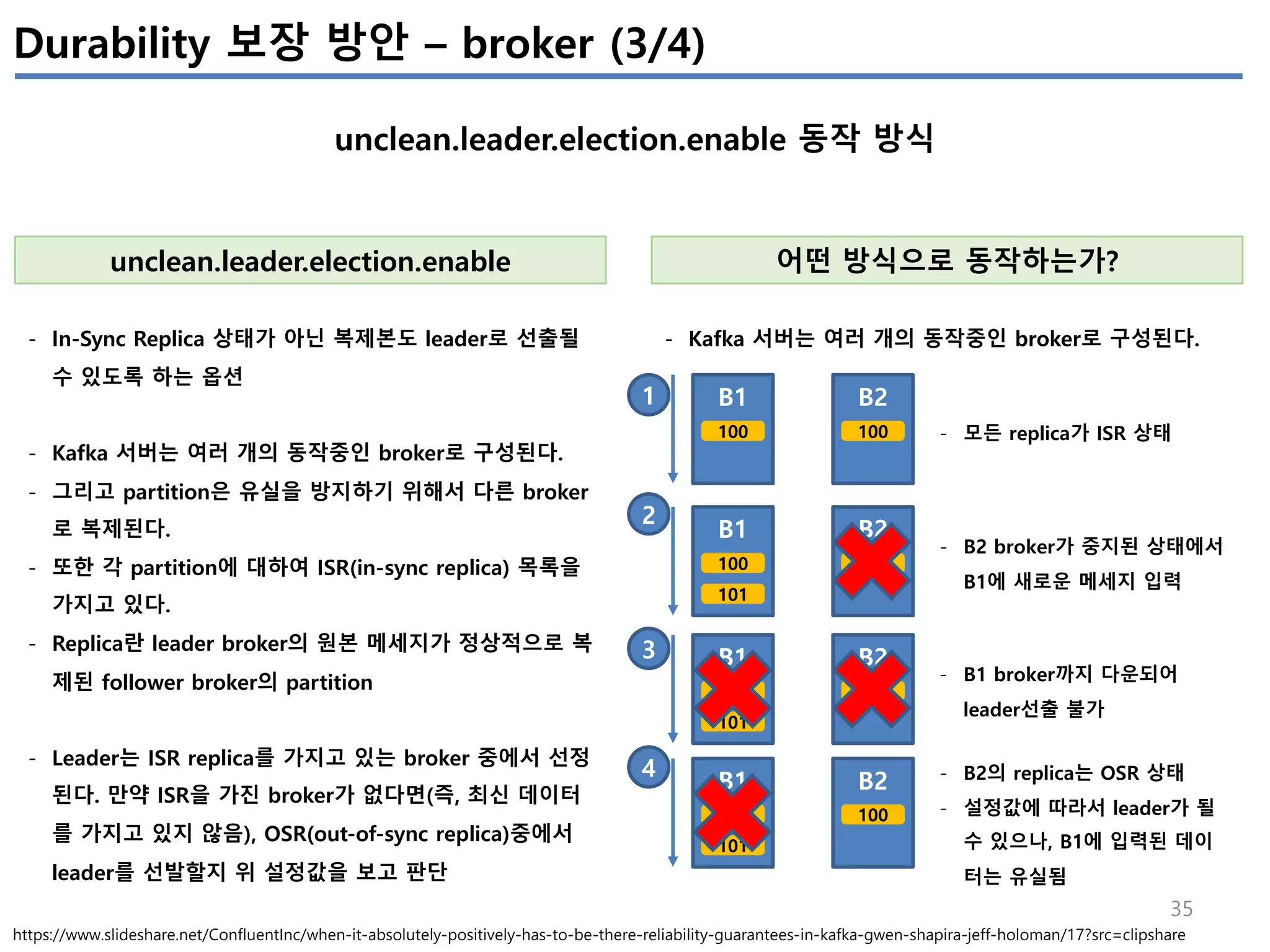
Kafka Monitoring – Kafka Procuder Metrics
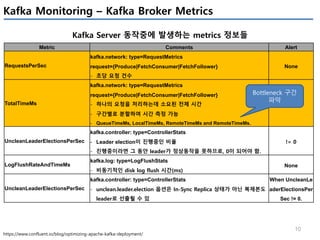
Producer의 성능관련 지표
Metric Comments Alert
io-ratio
kafka.producer:type=producer-metrics,client-id=([- .w]+)
- I/O 작업을 위해 I/O thread가 사용한 시간
io-wait-ratio
kafka.producer:type=producer-metrics,client-id=([- .w]+)
- I/O thread가 waiting에 소요한 시간
User processing time
- à 위 2개 시간을 제외하면, user processing time을 계산 가능
- à 만약 위 2개 수치가 낮다면, user processing time이 높아지고,
- à 그 의미는 producer I/O thread가 바쁘다는 의미이다.
https://www.confluent.io/blog/optimizing-apache-kafka-deployment/](https://image.slidesharecdn.com/apachekafkaperformancev0-181121234632/85/Apache-kafka-Metrics-17-320.jpg)
![19
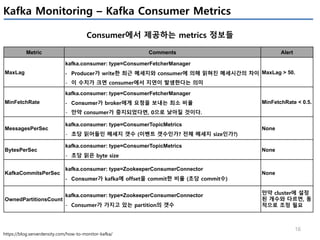
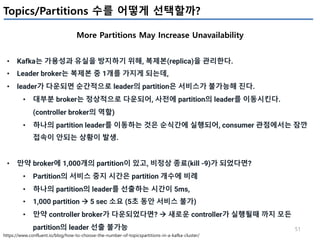
Kafka Monitoring – Latency 관련
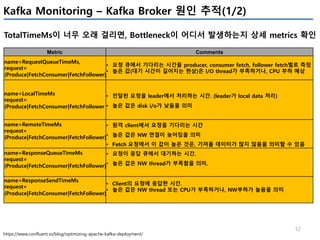
Offset의 상태
Metric Comments Alert
records-lag-max
kafka.consumer:type=consumer-fetch-manager- metrics,client-id=([-.w]+)
- Procucer가 쓰는 최신의 메세지 offset값과, consumer가 읽어간 offset값의
최대 차이(partition 들 중)
- 값이 증가한다면, consumer group이 데이터를 빠르게 가져가지 못함을 의미
https://www.confluent.io/blog/optimizing-apache-kafka-deployment/](https://image.slidesharecdn.com/apachekafkaperformancev0-181121234632/85/Apache-kafka-Metrics-19-320.jpg)





































![17
Kafka Monitoring – Kafka Procuder Metrics
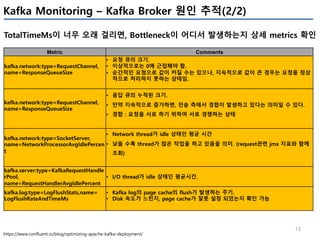
Producer의 성능관련 지표
Metric Comments Alert
io-ratio
kafka.producer:type=producer-metrics,client-id=([- .w]+)
- I/O 작업을 위해 I/O thread가 사용한 시간
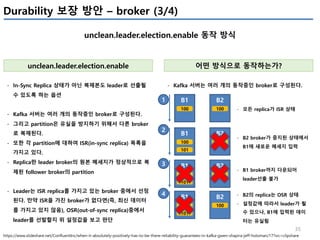
io-wait-ratio
kafka.producer:type=producer-metrics,client-id=([- .w]+)
- I/O thread가 waiting에 소요한 시간
User processing time
- à 위 2개 시간을 제외하면, user processing time을 계산 가능
- à 만약 위 2개 수치가 낮다면, user processing time이 높아지고,
- à 그 의미는 producer I/O thread가 바쁘다는 의미이다.
https://www.confluent.io/blog/optimizing-apache-kafka-deployment/](https://image.slidesharecdn.com/apachekafkaperformancev0-181121234632/75/Apache-kafka-Metrics-17-2048.jpg)
![19
Kafka Monitoring – Latency 관련
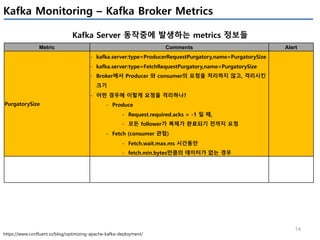
Offset의 상태
Metric Comments Alert
records-lag-max
kafka.consumer:type=consumer-fetch-manager- metrics,client-id=([-.w]+)
- Procucer가 쓰는 최신의 메세지 offset값과, consumer가 읽어간 offset값의
최대 차이(partition 들 중)
- 값이 증가한다면, consumer group이 데이터를 빠르게 가져가지 못함을 의미
https://www.confluent.io/blog/optimizing-apache-kafka-deployment/](https://image.slidesharecdn.com/apachekafkaperformancev0-181121234632/75/Apache-kafka-Metrics-19-2048.jpg)
































![[오픈소스컨설팅] 스카우터 사용자 가이드 2020](https://cdn.slidesharecdn.com/ss_thumbnails/2020scouteruserguide-200122014357-thumbnail.jpg?width=600ounds&width=560&fit=bounds)




![[오픈소스컨설팅]RHEL7/CentOS7 Pacemaker기반-HA시스템구성-v1.0](https://cdn.slidesharecdn.com/ss_thumbnails/rhel-centos7-pacemaker-based-ha-admin-guidev1-151215000535-thumbnail.jpg?width=600ounds&width=560&fit=bounds)























![[오픈소스컨설팅]Kafka message system 맛보기](https://cdn.slidesharecdn.com/ss_thumbnails/kafkamessagesystem-180730044904-thumbnail.jpg?width=600ounds&width=560&fit=bounds)

![[Main Session] 카프카, 데이터 플랫폼의 최강자](https://cdn.slidesharecdn.com/ss_thumbnails/180519-kafka-oraclefin-180521125323-thumbnail.jpg?width=600ounds&width=560&fit=bounds)



![[월간 슬라이드] 단기완성 Apache kafka](https://cdn.slidesharecdn.com/ss_thumbnails/monthlyslideapachekafka-190302052656-thumbnail.jpg?width=600ounds&width=560&fit=bounds)






![[ 2021 AI + X 여름 캠프 ] 2. 장비 상호 연결 kafka를 이용한 매체 전송](https://cdn.slidesharecdn.com/ss_thumbnails/2-210731153335-thumbnail.jpg?width=600ounds&width=560&fit=bounds)


















