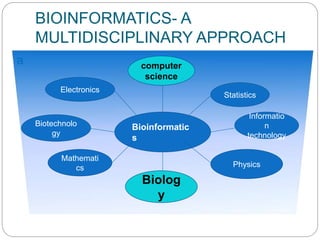
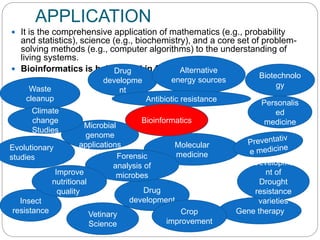
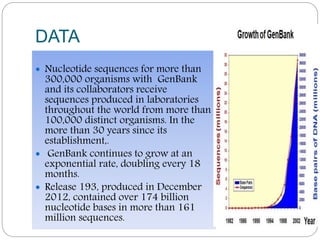
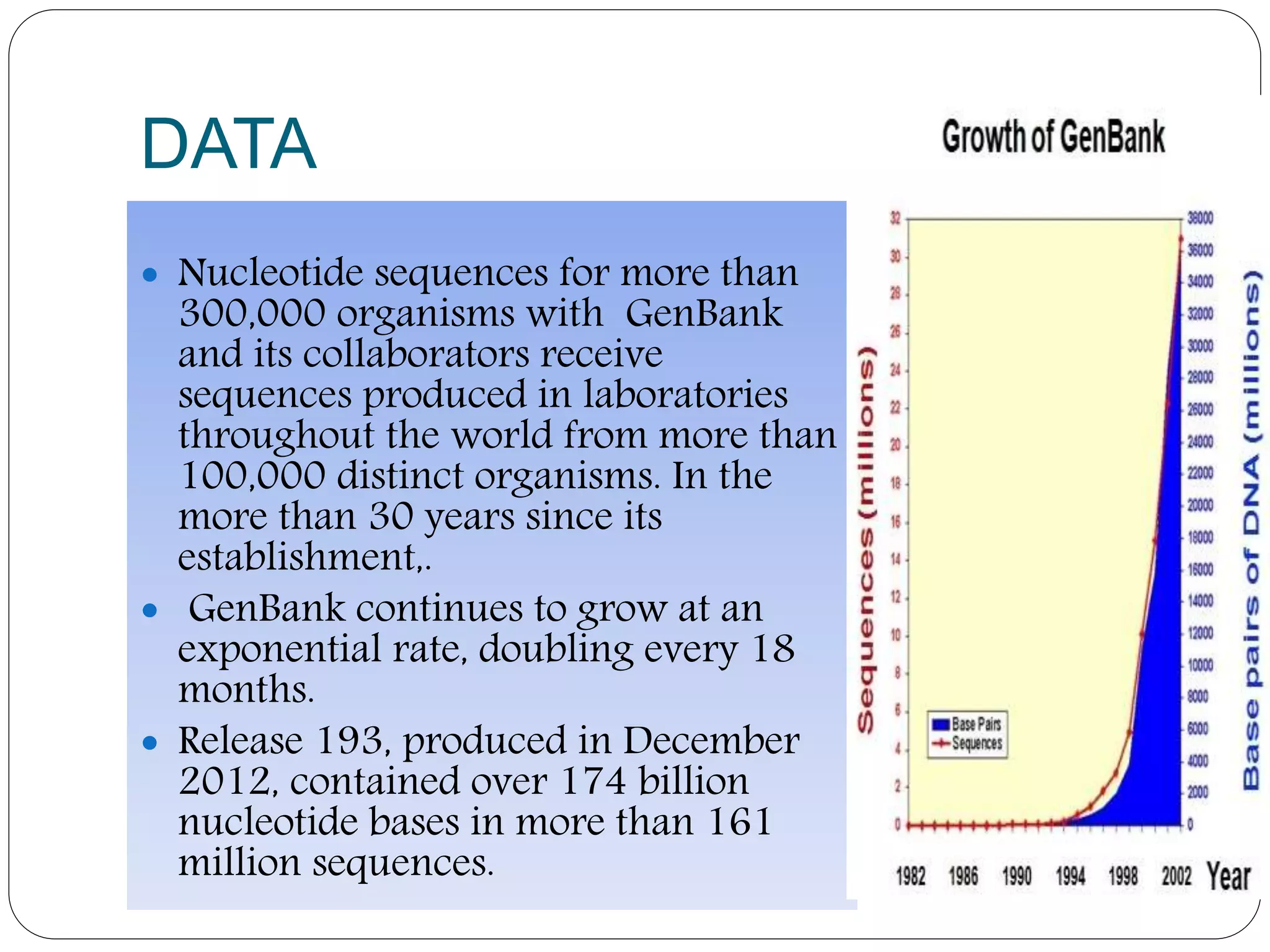
The document provides an overview of the history and scope of bioinformatics. It discusses how bioinformatics emerged from the fields of computer science and biology. The history section outlines major developments from Mendel's work in 1865 to the sequencing of the human genome in 2001. Bioinformatics has various applications in areas like drug development, personalized medicine, and biotechnology. It also has significant scope in India, with growing job opportunities in both the public and private sectors.