Downloaded 12 times














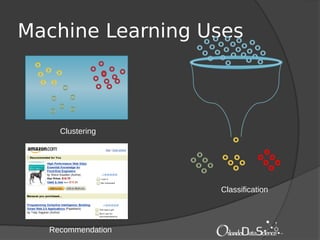



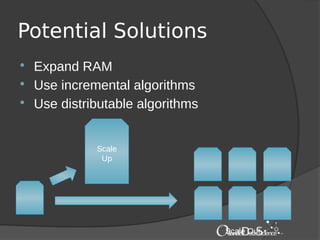
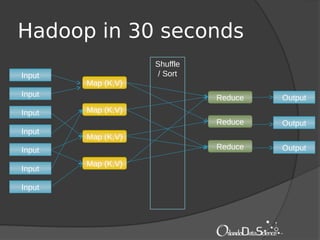





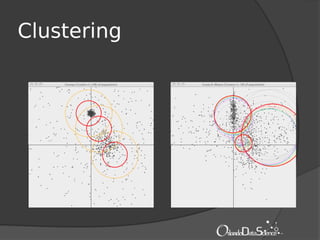
















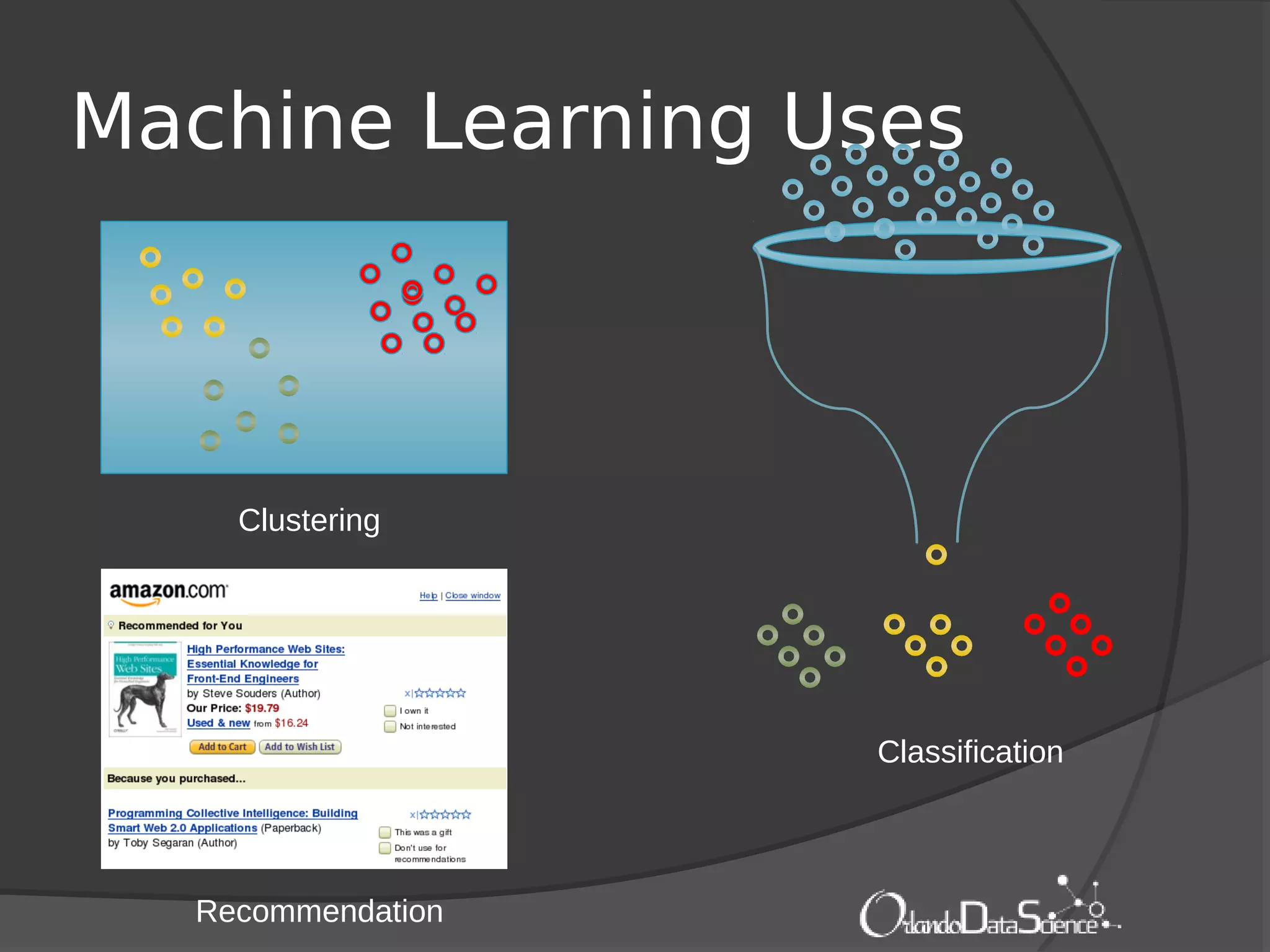



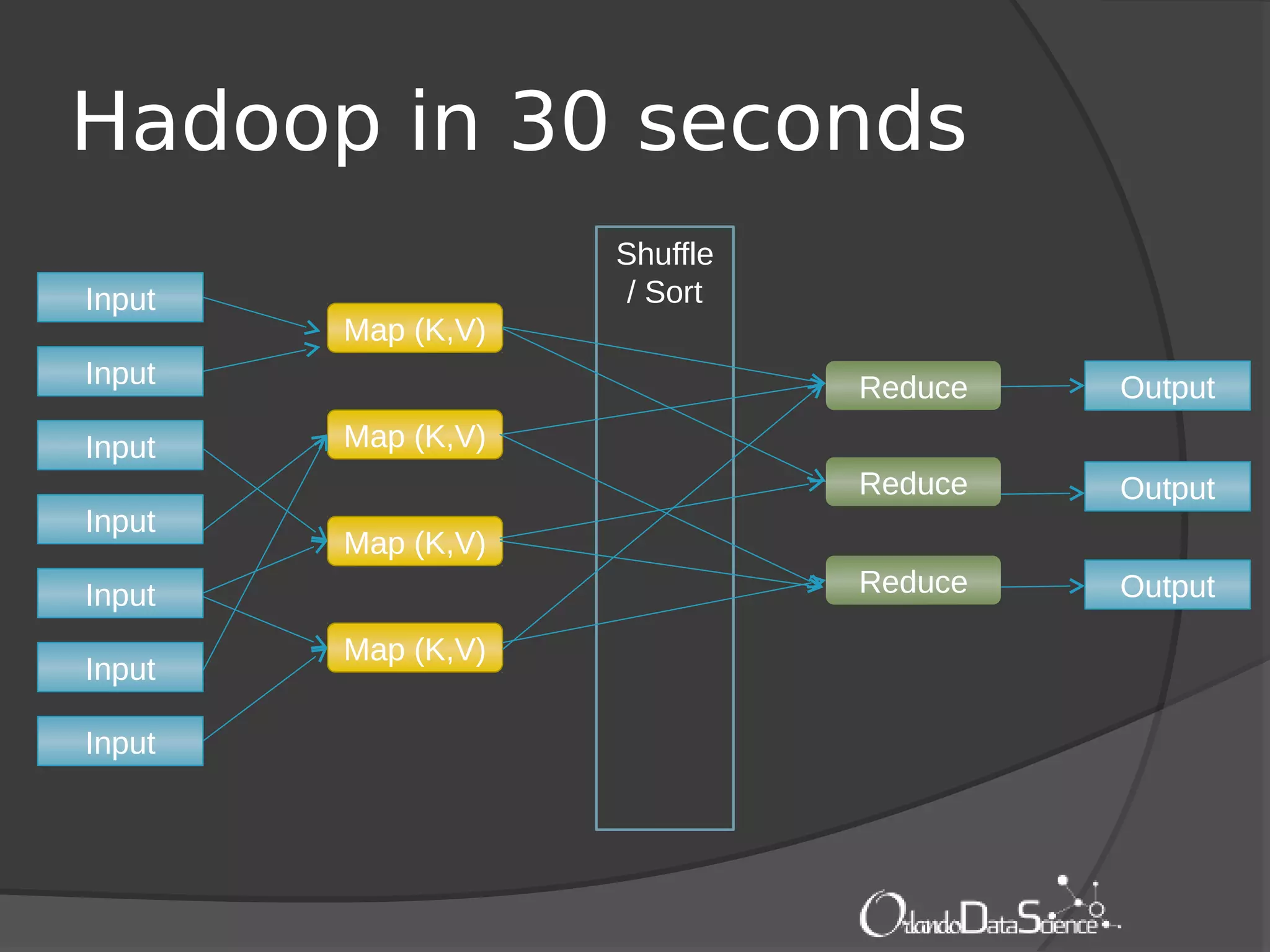





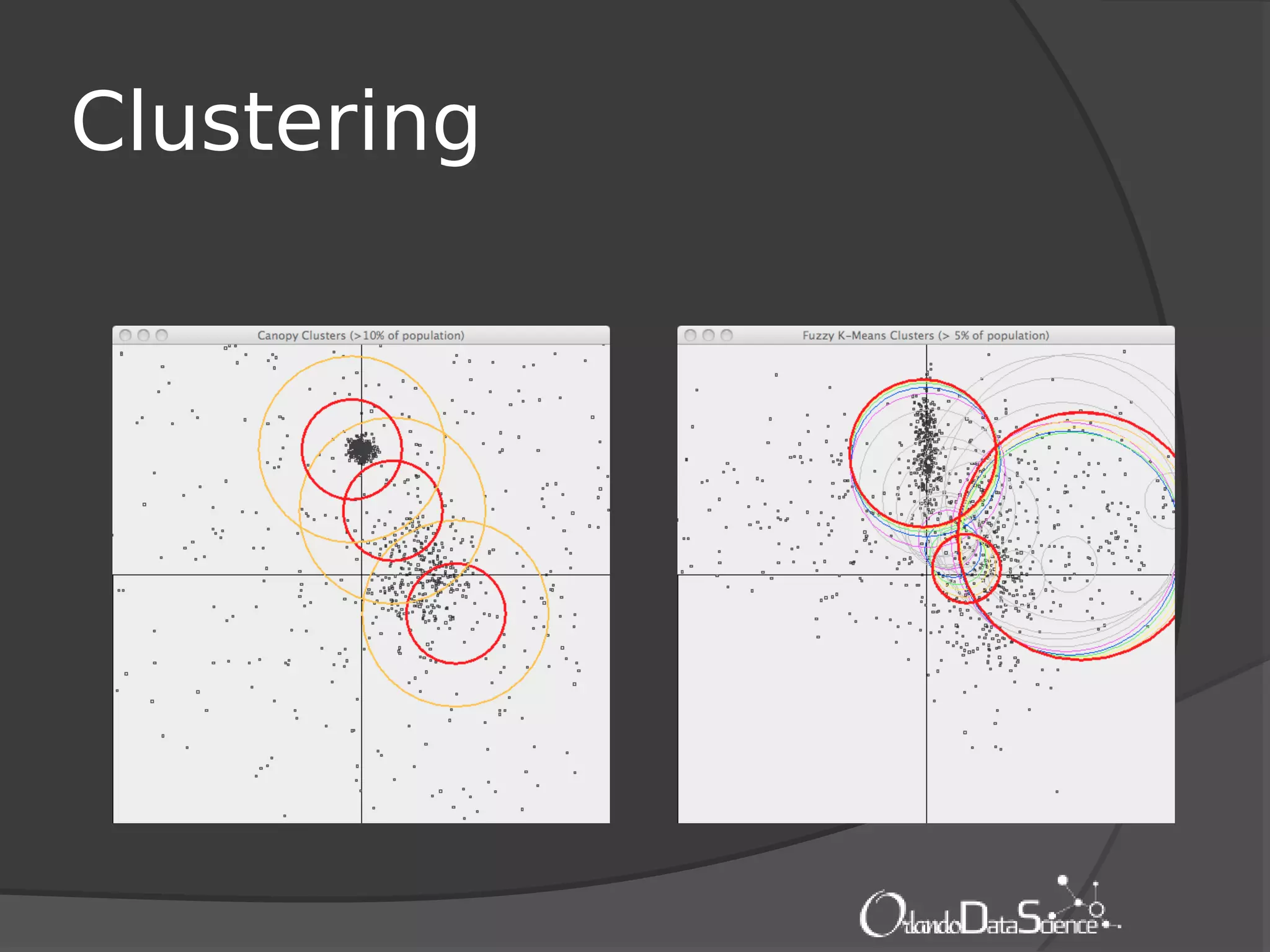


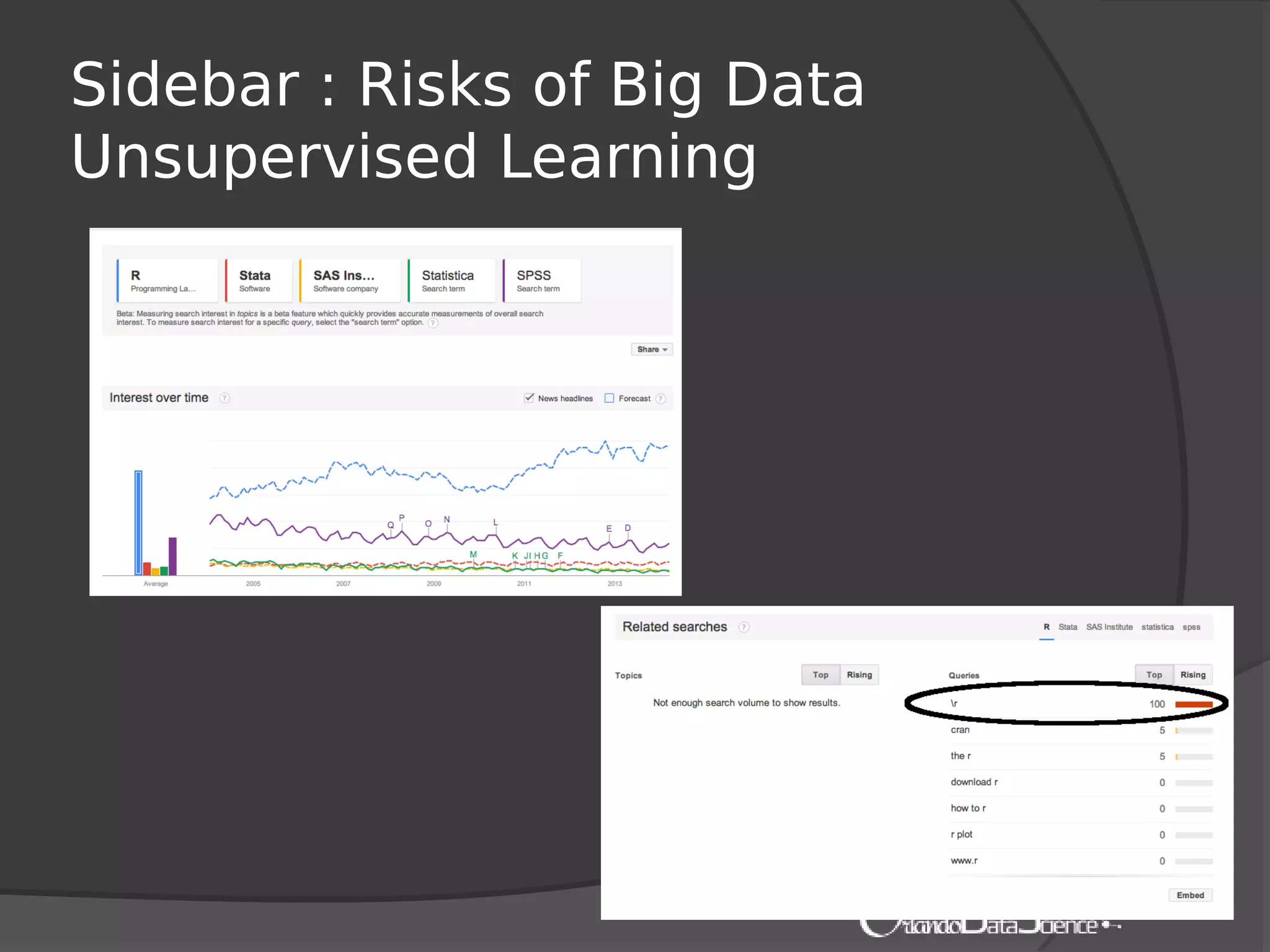

The document provides an introduction to machine learning with Mahout. It discusses machine learning concepts and algorithms like clustering, classification, and recommendation. It introduces Hadoop as a framework for distributed processing of big data and Mahout as an open-source library for machine learning algorithms on Hadoop. The document demonstrates how to run recommendation algorithms and clustering algorithms using Mahout on local machines or cloud platforms like Amazon EC2 and EMR. It also discusses preprocessing text data and classifiers.



































































