



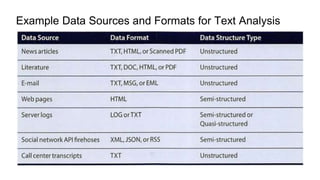



























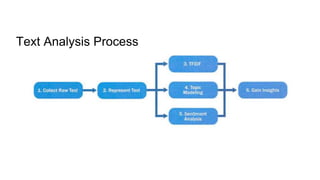




































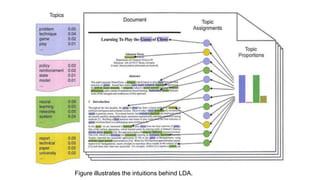







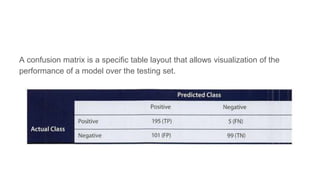









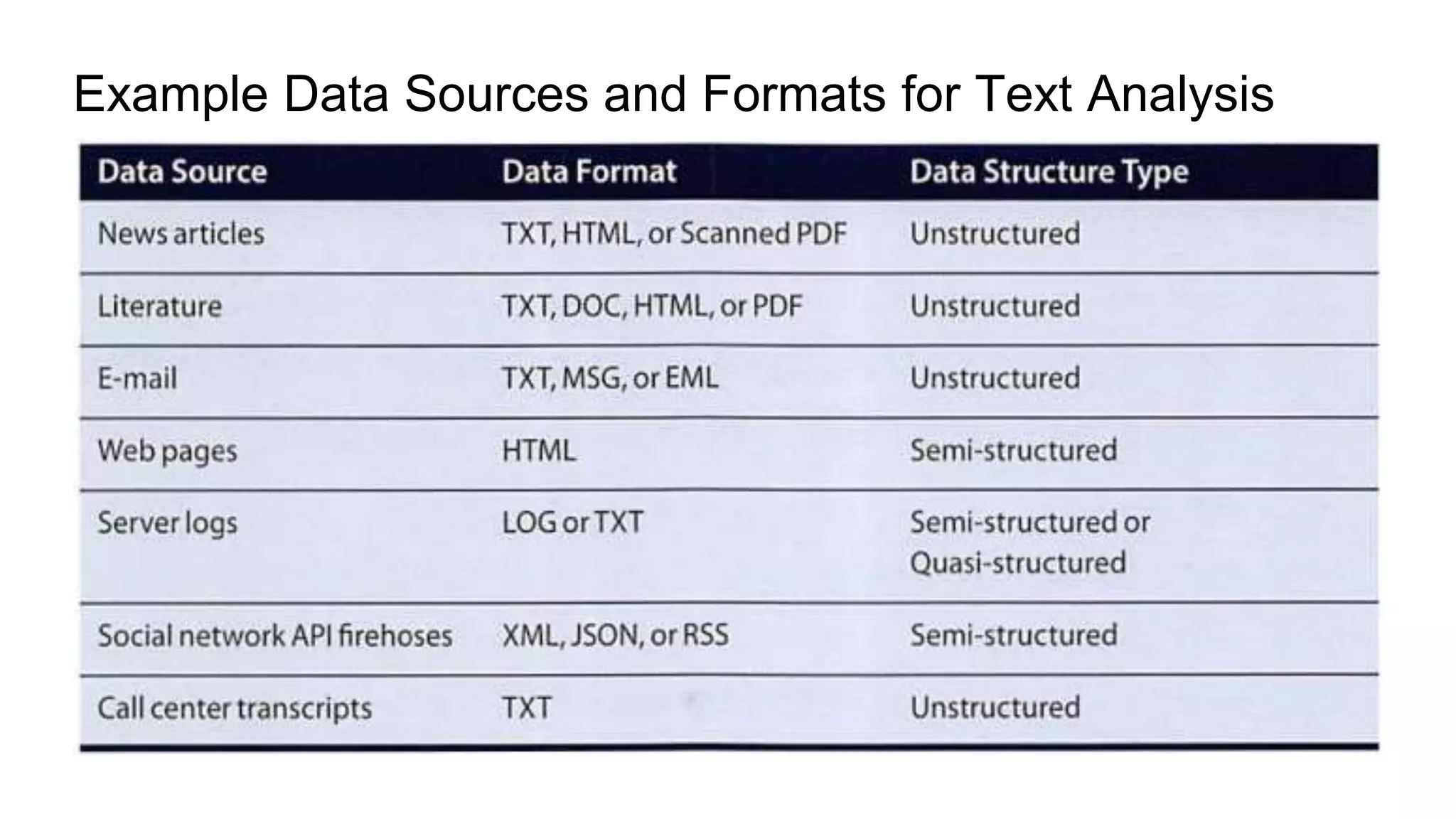

















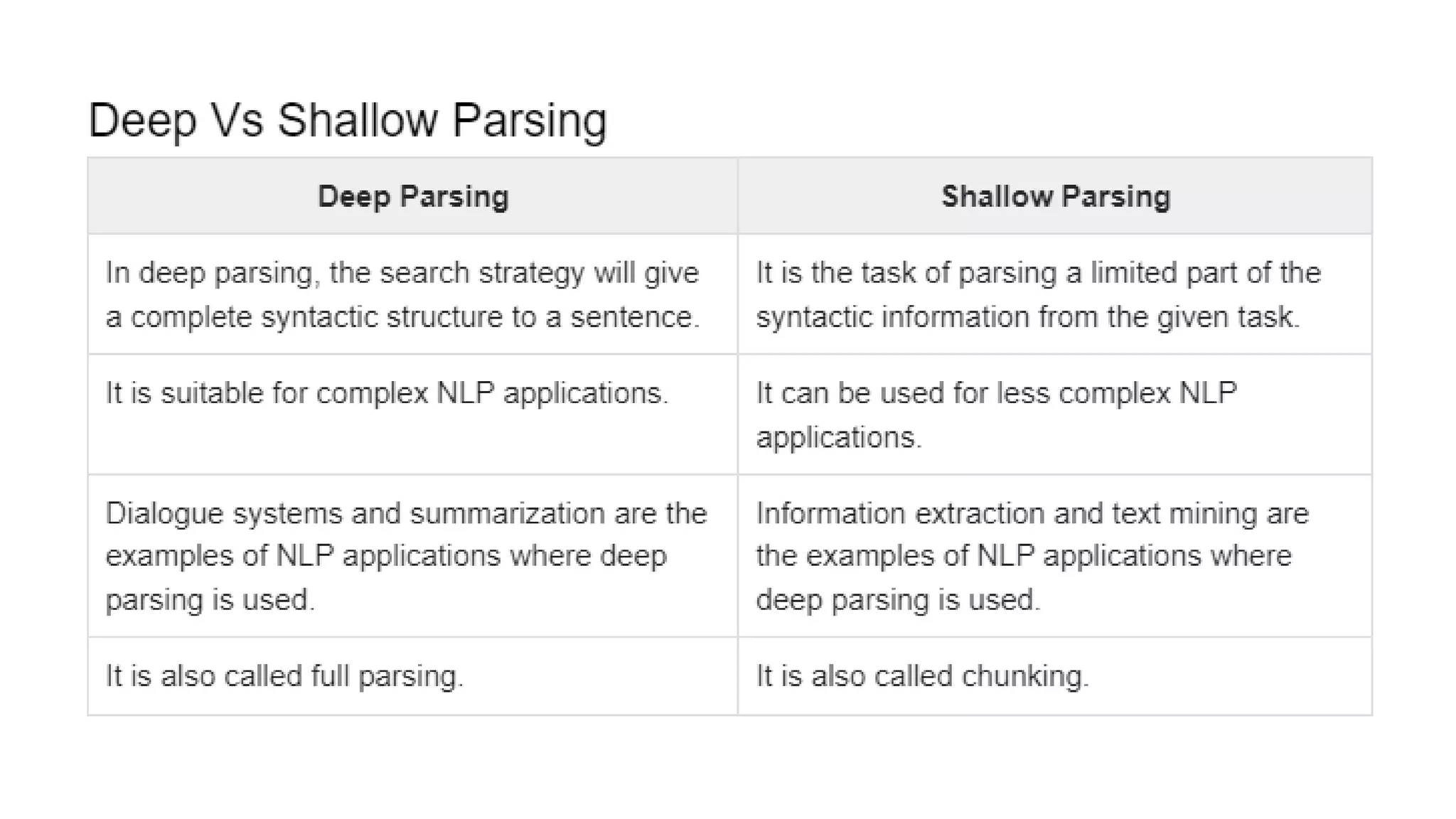









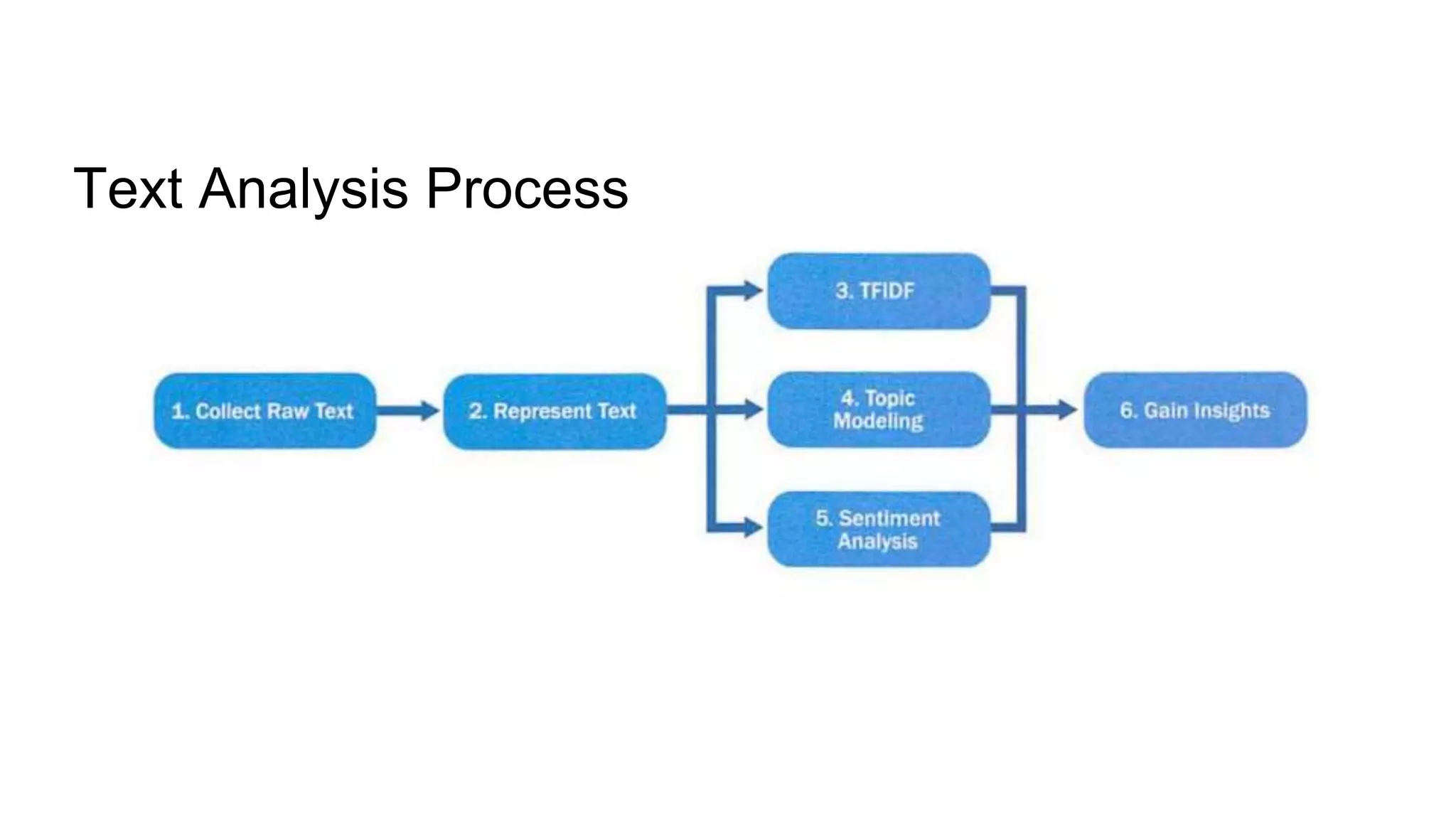




































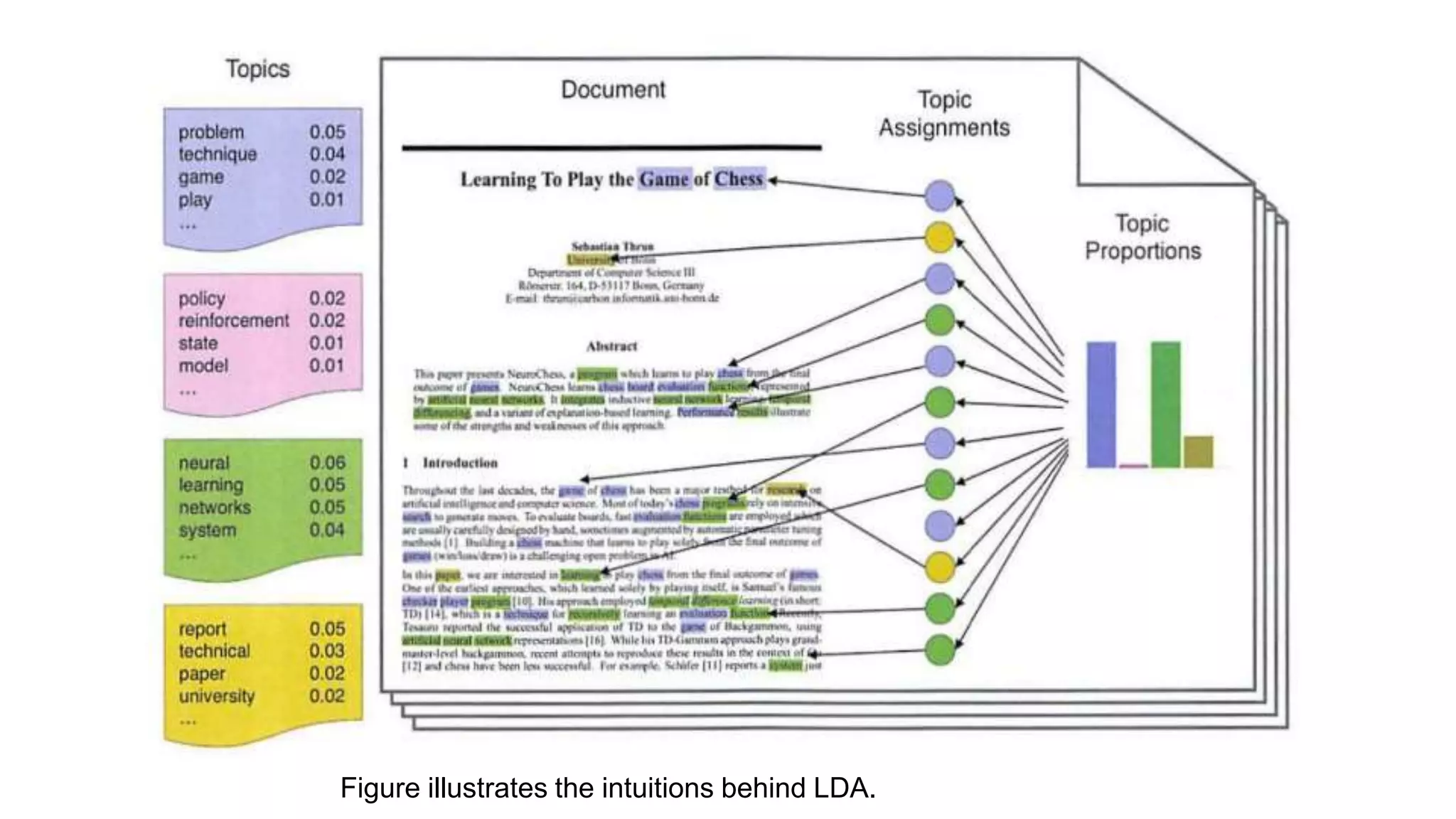







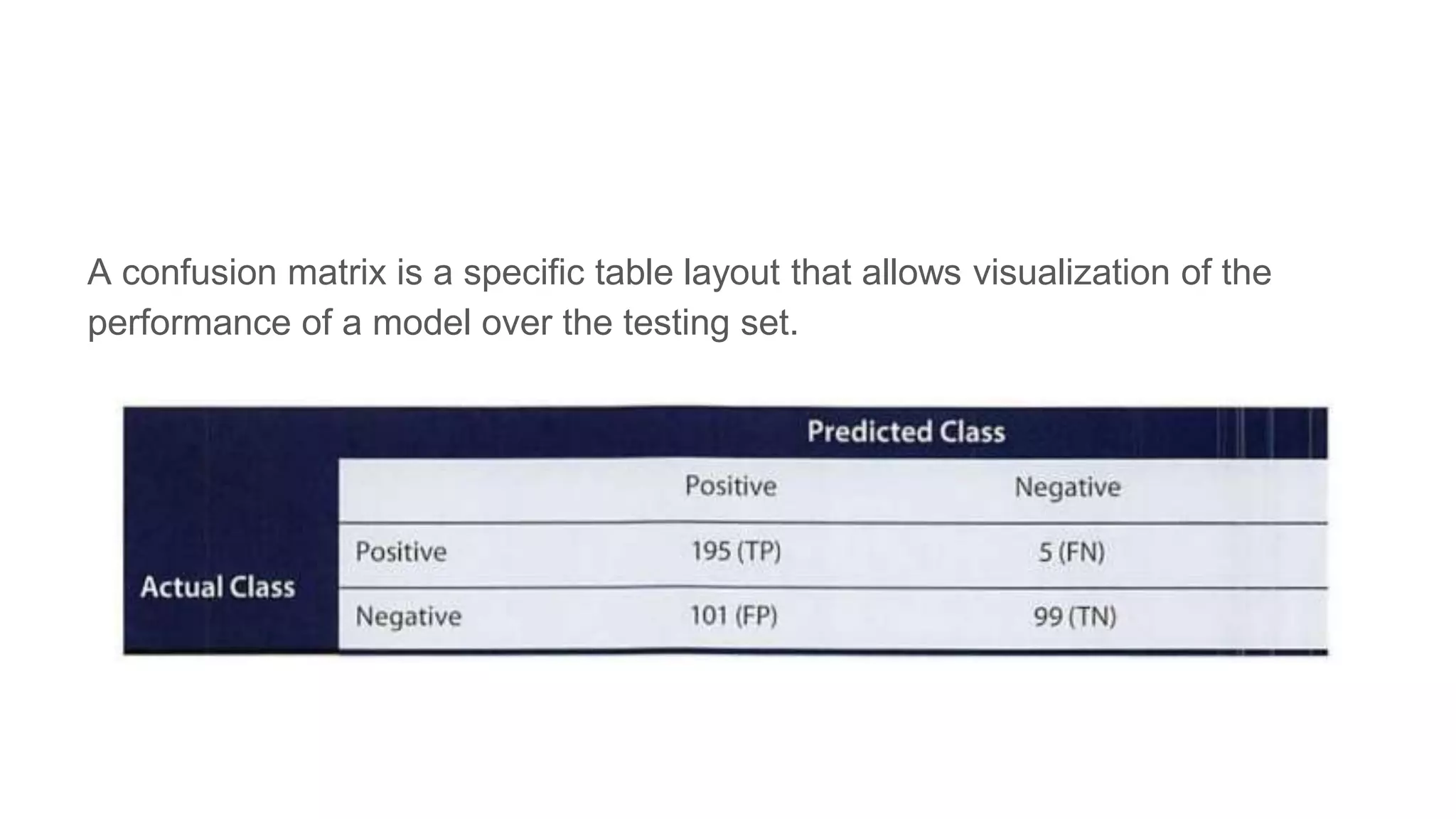





This document provides an overview of text analysis and mining. It discusses key concepts like text pre-processing, representation, shallow parsing, stop words, stemming and lemmatization. Specific techniques covered include tokenization, part-of-speech tagging, Porter stemming algorithm. Applications mentioned are sentiment analysis, document similarity, cluster analysis. The document also provides a multi-step example of text analysis involving collecting raw text, representing text, computing TF-IDF, categorizing documents by topics, determining sentiments and gaining insights.























































































