Downloaded 1,263 times








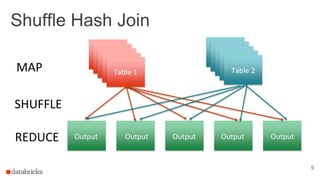

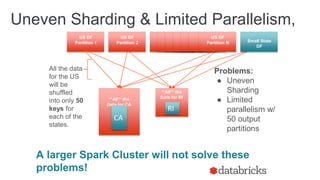
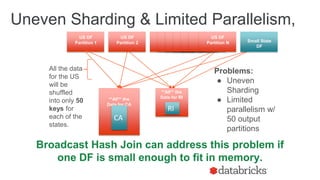

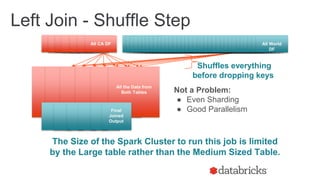
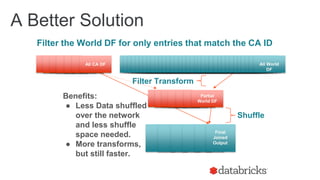


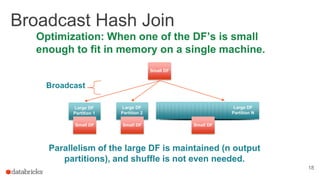














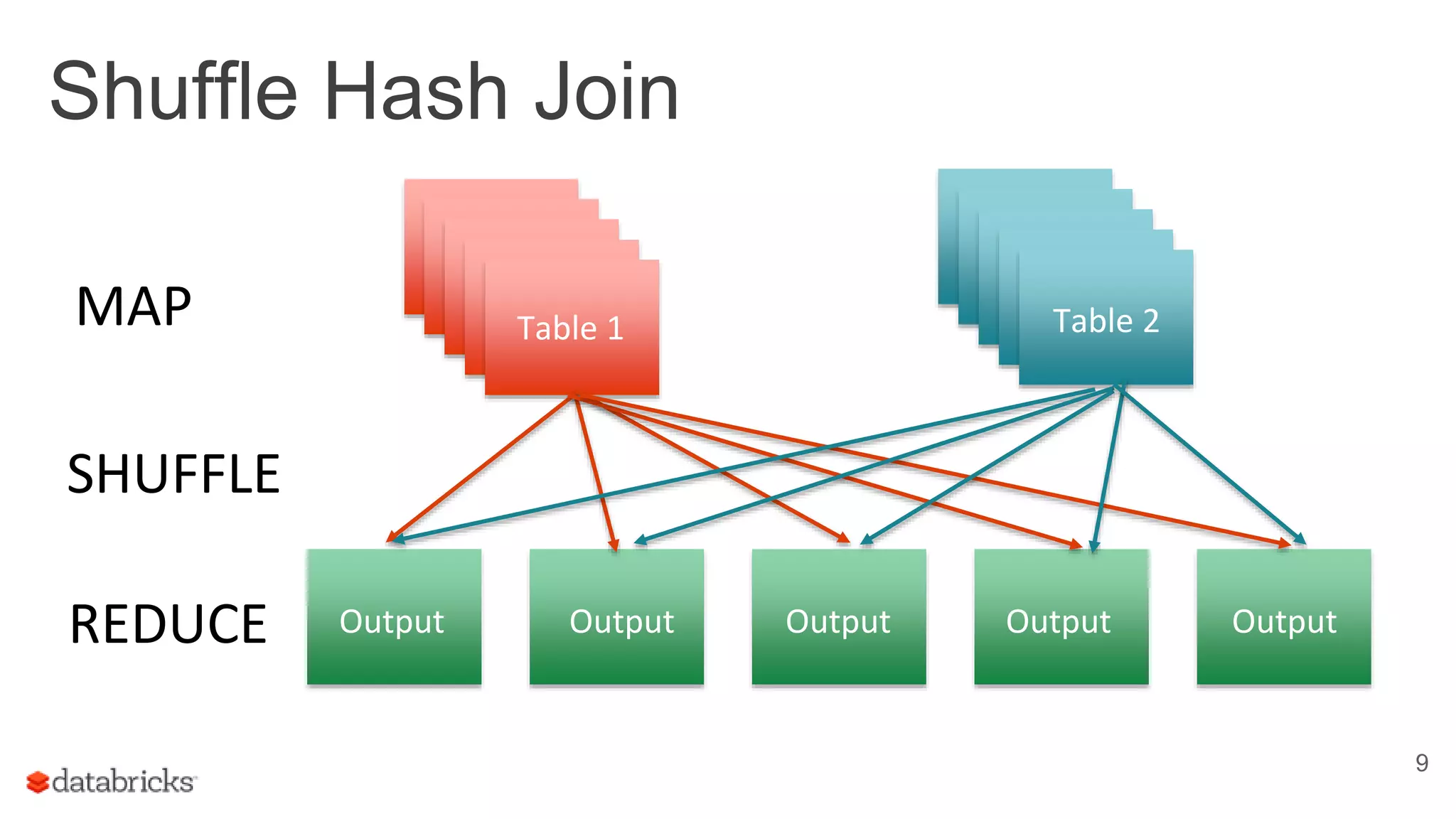

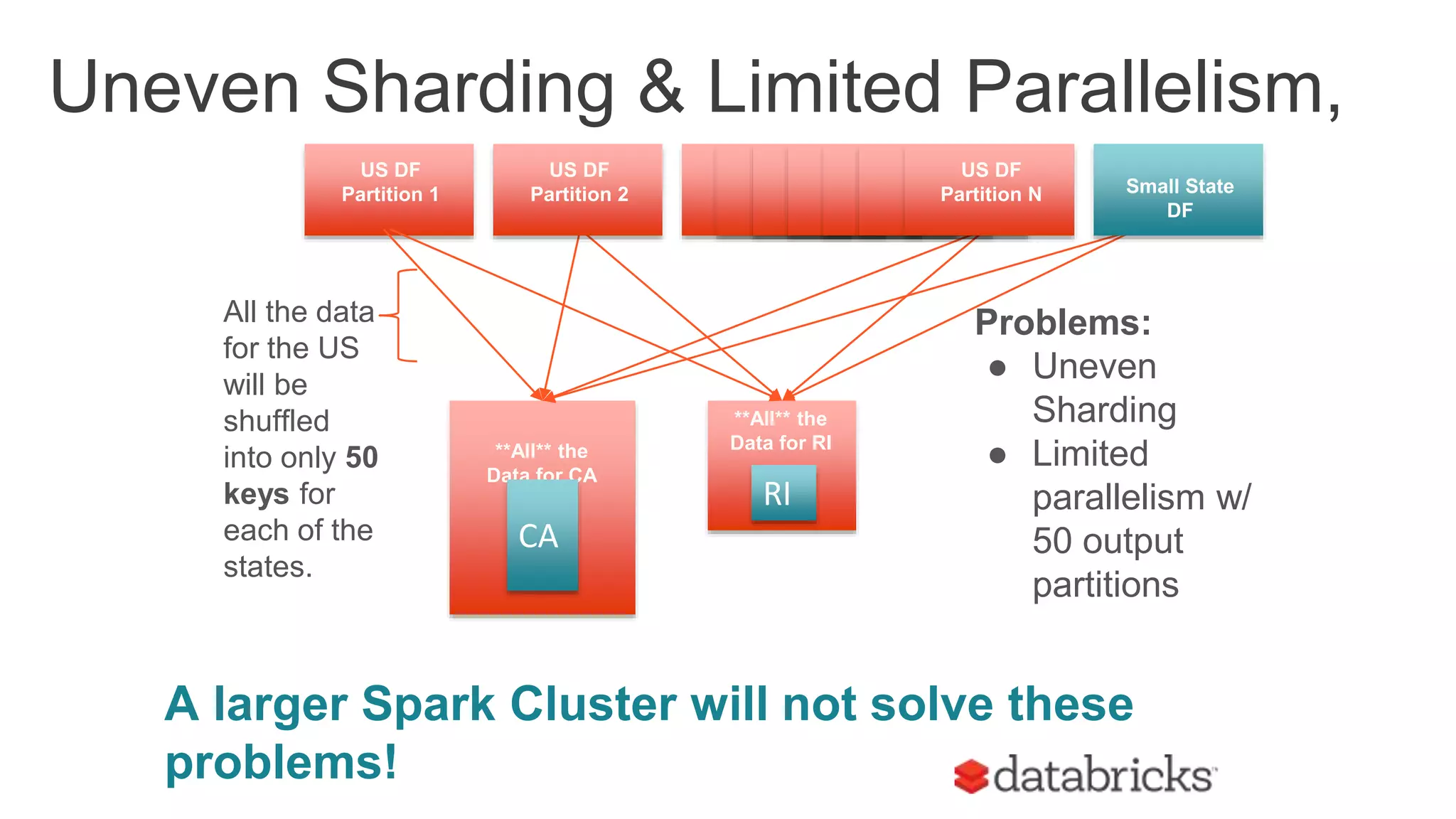
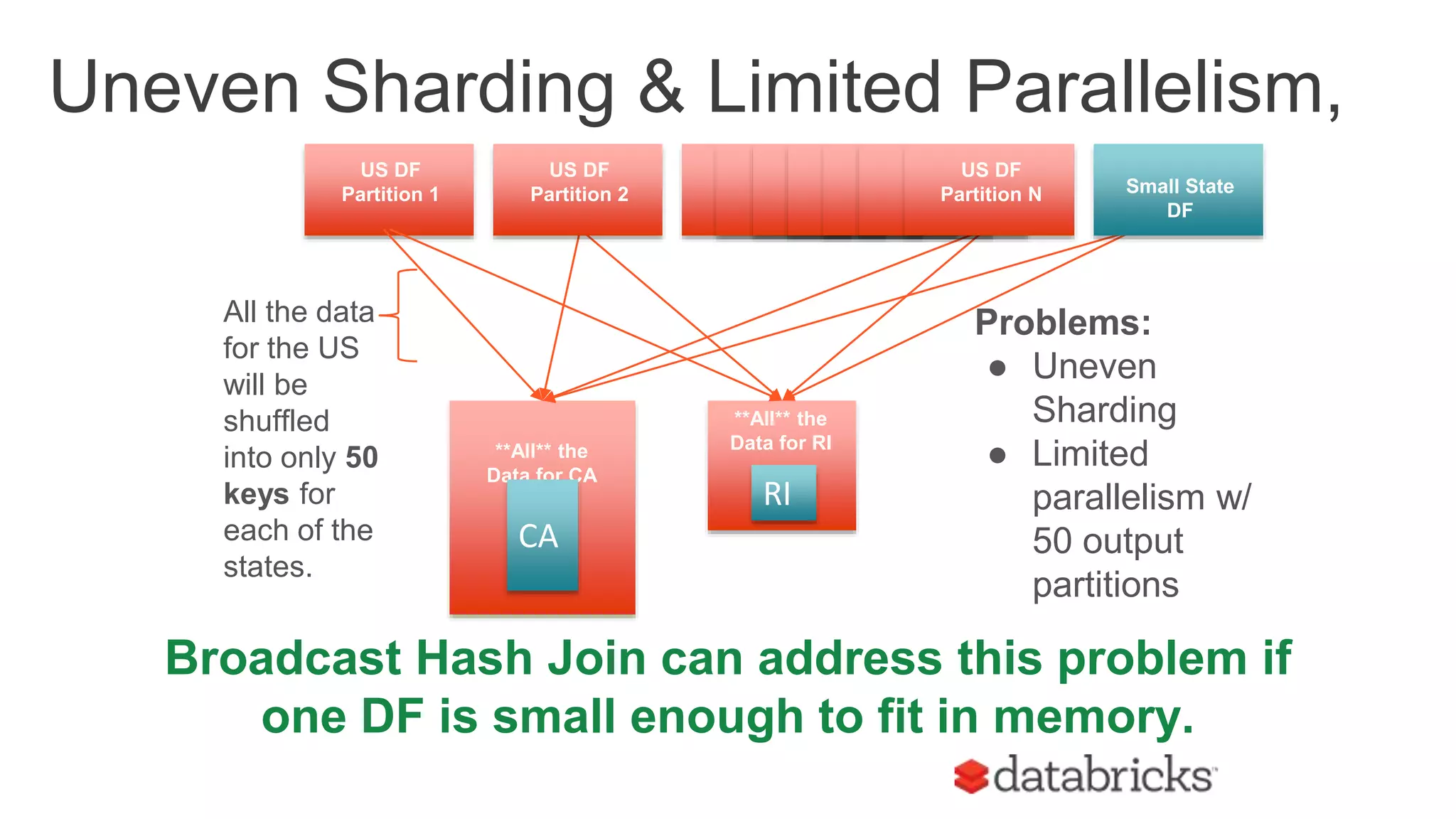

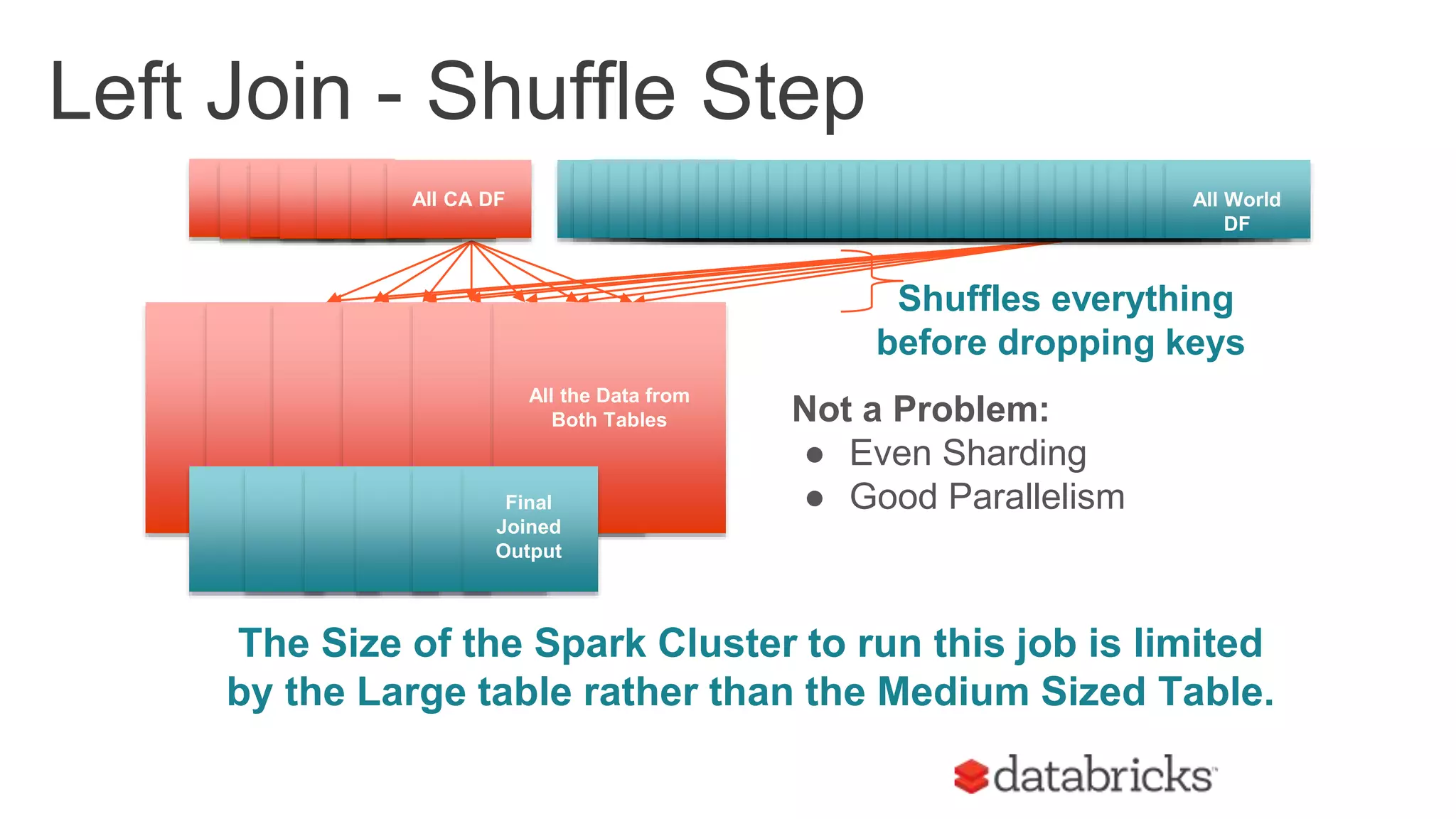
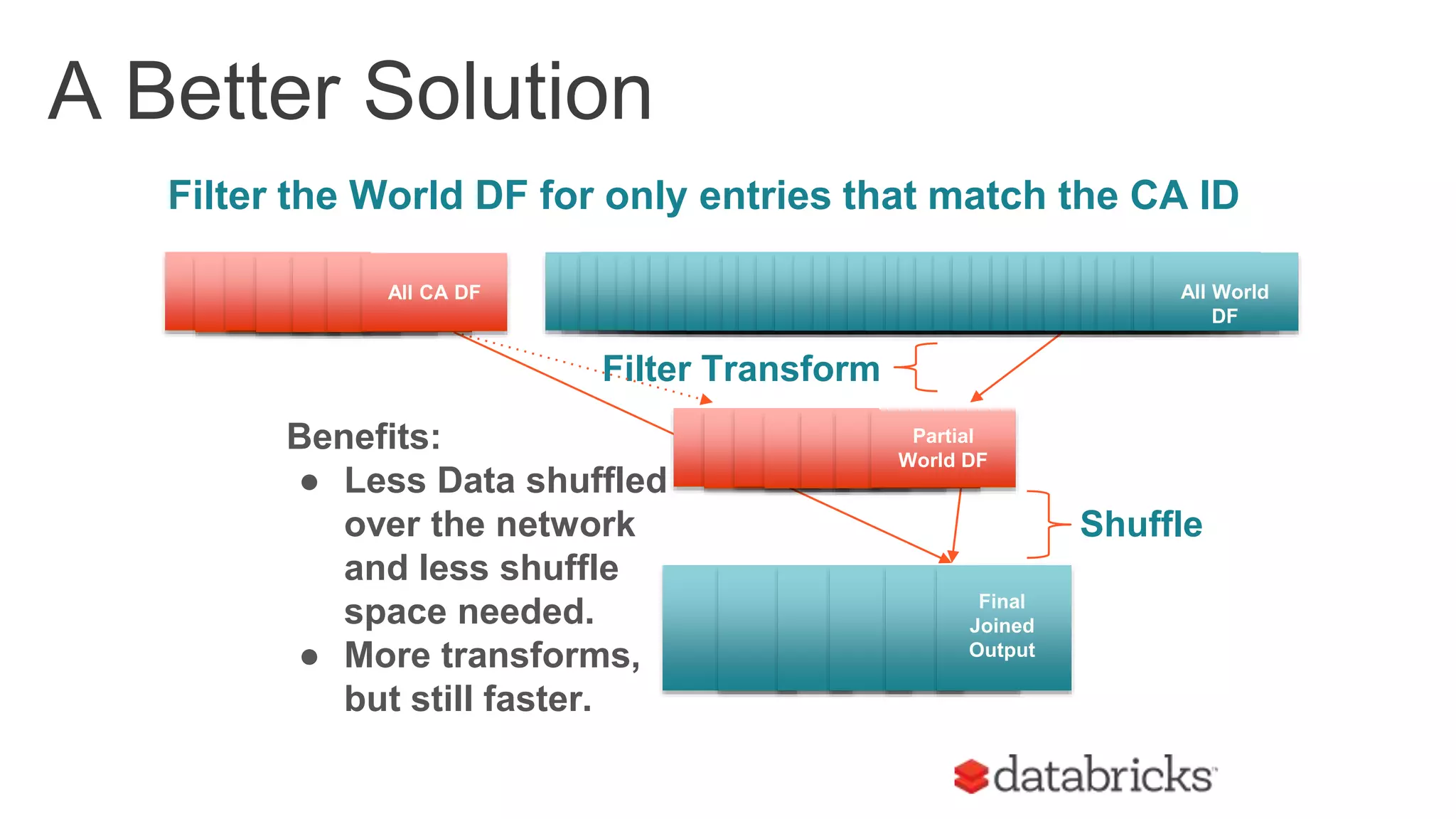


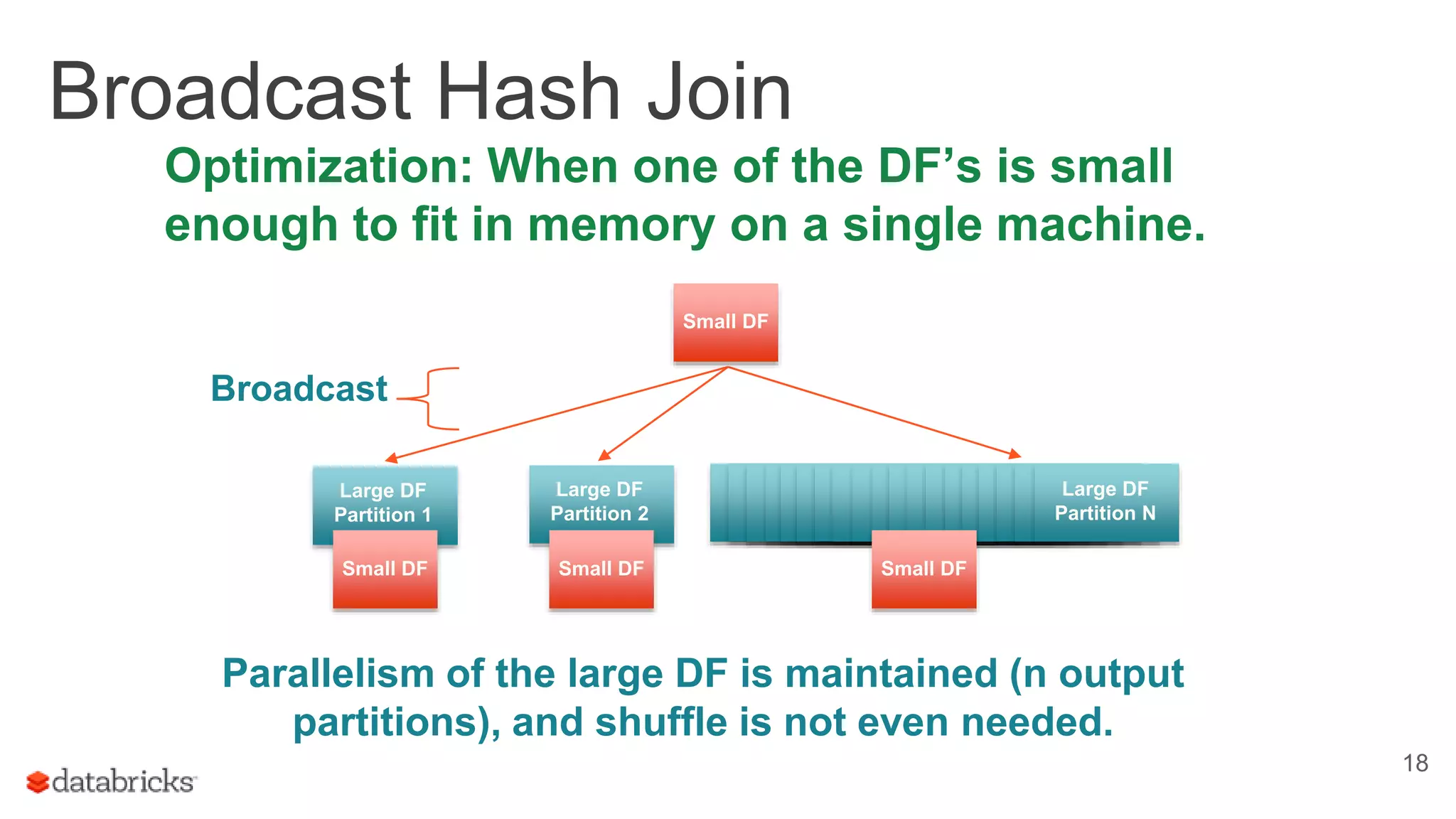







The document discusses optimizing Apache Spark SQL joins, focusing on various types of joins such as shuffle hash join, broadcast hash join, and cartesian join. It outlines performance considerations, common problems like uneven sharding and limited parallelism, and strategies for improving join efficiency through filtering and understanding data properties. The document emphasizes the importance of using tools like the Spark UI for detecting shuffle issues and highlights considerations for specific join types.























































































