This document discusses the collaboration between molecular medicine and bioinformatics. It defines bioinformatics as the science of storing, retrieving, and analyzing large amounts of biological data, cutting across biology, computer science, and mathematics. It gives examples of how bioinformatics can be applied in molecular medicine for studying pathogenicity, therapeutic targets, molecular diagnostics, and host-pathogen interactions. The document also outlines how bioinformatics supports molecular medicine through genome analysis, database and tool development, and describes some catalysts like genome sequencing that have expanded bioinformatics.
1
Molecular Medicine inCollaboration with
Bioinformatics
M. Kamran Azim, Ph.D.
International Center for Chemical and Biological Sciences
H.E.J. Research Institute of Chemistry,
Dr. Panjwani Center for Molecular Medicine and Drug Research
University of Karachi
2.
2
What is Bioinformatics?
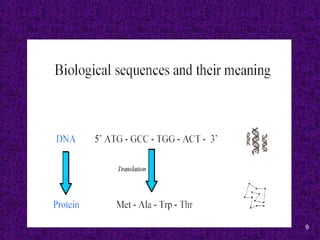
Bioinformaticsis the science of storing, retrieving and
analyzing large amounts of biological information.
It cuts across many disciplines, including biology,
computer science and mathematics. (as defined by EBI)
3.
3
Application of Bioinformaticsin
Molecular Medicine
Molecular basis of pathogenicity;
e.g. Amyloid protein in neurodegenerative
diseases
Novel targets of therapeutic
intervention;
e.g. Caspase inhibitors in diseases
characterized by tissue degradation
Molecular Diagnostics;
e.g. Bird Flu
Host-pathogen interaction;
e.g. Bacterial adherence factors
Novel Research tools;
e.g. GFP-based techniques
4.
4
How Bioinformatics cansupport
Molecular Medicine?
Genome-level sequence analysis of medically important
organisms in order to;
gain comprehensive knowledge for their life cycle,
characterization of disease causing factors,
identify new targets for therapeutic intervention
Development of Bioinformatics such as novel
algorithms, specialized databases and java-based
tools for application in genomics and proteomics.
5.
5
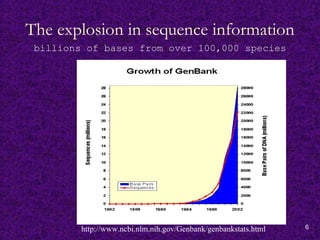
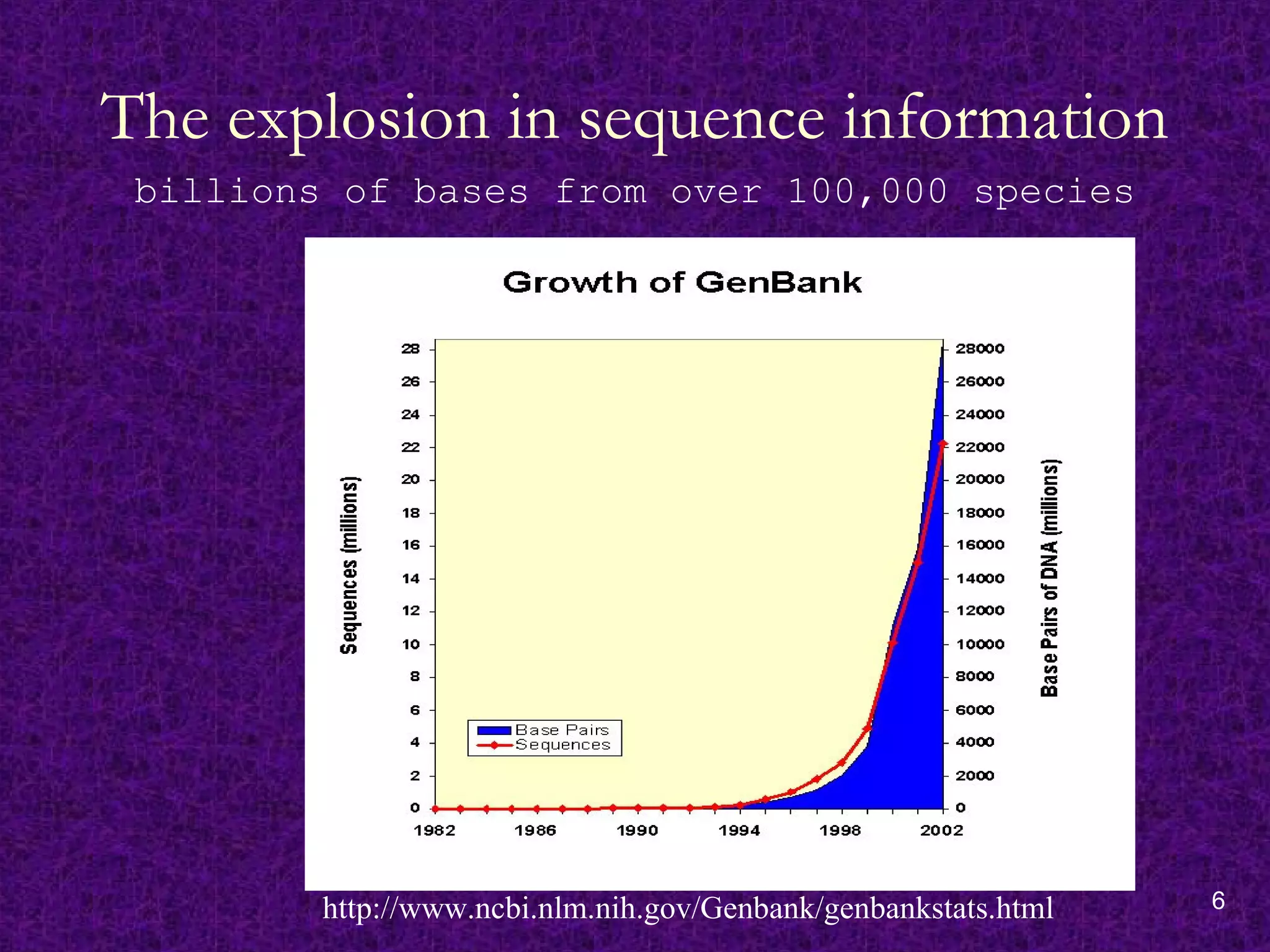
Catalysts for Bioinformatics
Large-scale DNA/genome sequencing projects have led
to an explosion of information concerning the DNA and
protein sequence data.
Development in the field of computer technology
including the use of computerized databases for storing,
retrieving and comparing sequences; computer graphics
for displaying and manipulating three-dimensional
structures.
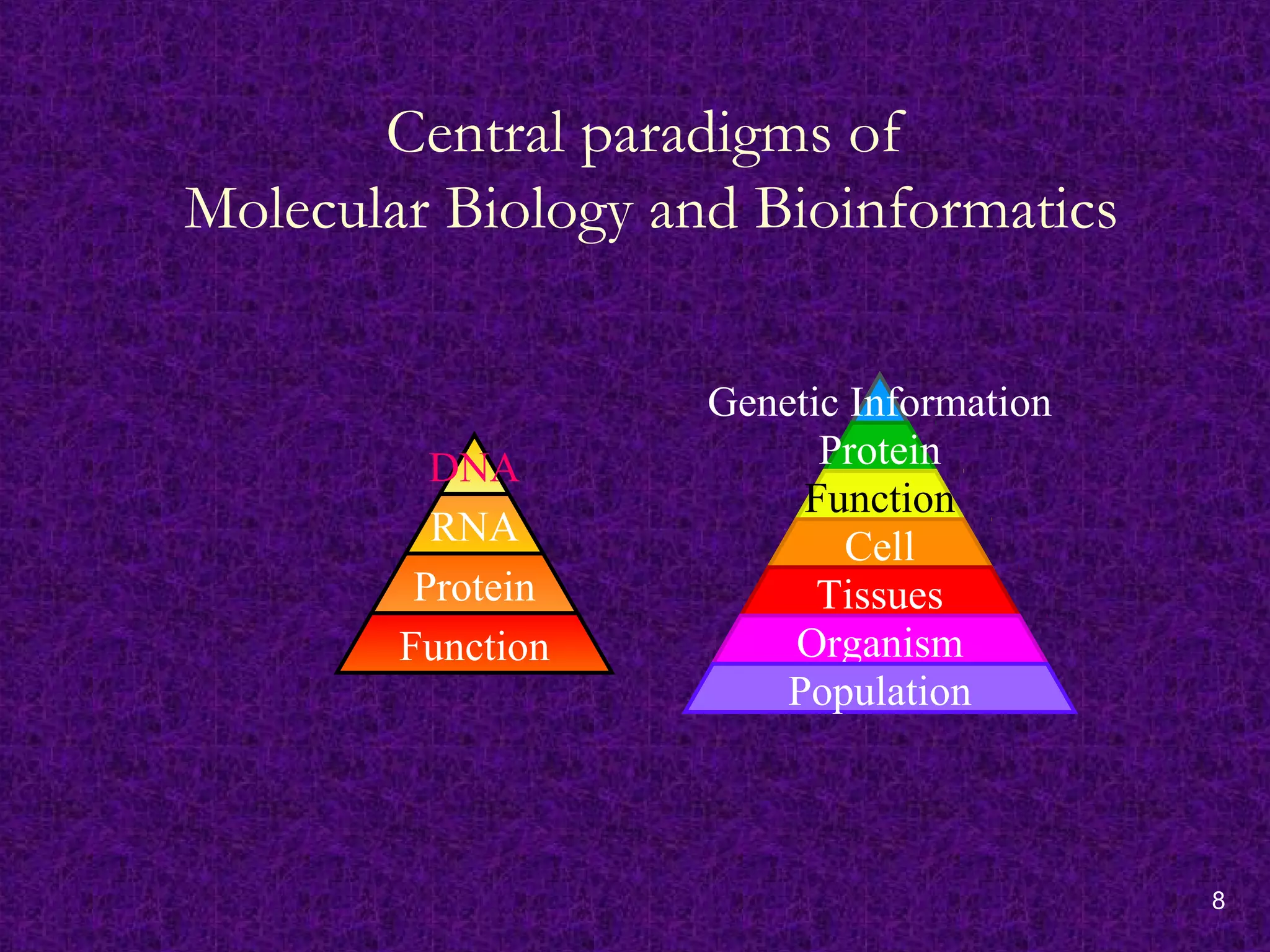
8
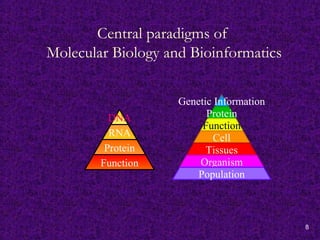
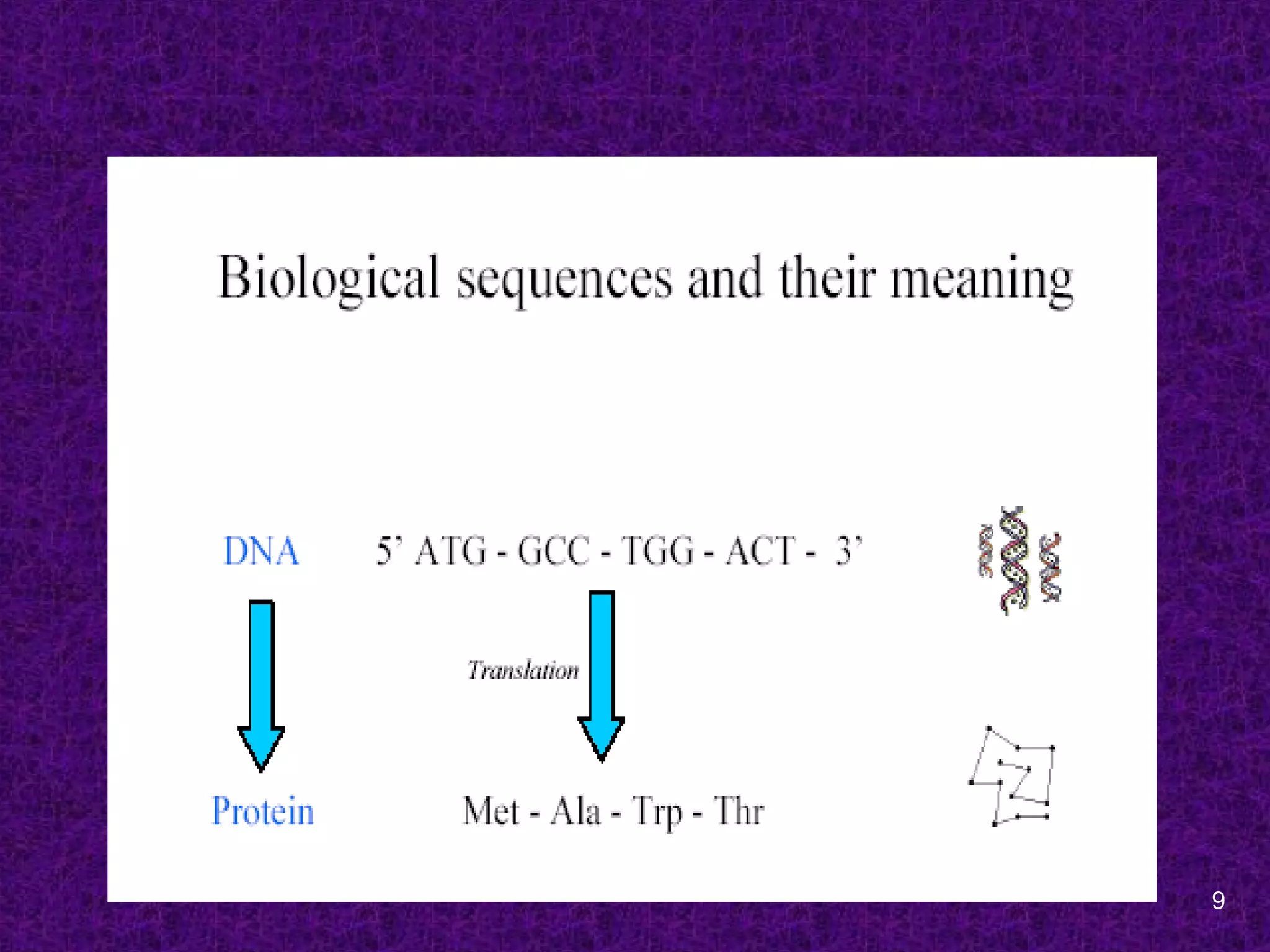
Central paradigms of
MolecularBiology and Bioinformatics
DNA
RNA
Protein
Function
Genetic Information
Protein
Function
Cell
Tissues
Organism
Population
21
Frederick Sanger andthe Science of Sequence
at MRC, Cambridge University
First Nobel Prize (1958)
was awarded for developing
methods to determine the
order (sequence) of the
building blocks of the
protein, insulin.
Second Nobel Prize (1980)
for developing several and
ever-improving methods to
sequence nucleic acids
(DNA and RNA).
22.
22
Prof. Zafar H.Zaidi and Bioinformatics
Pioneered Protein
Chemistry;
Protein Sequencing;
Sequence analysis
(1975-2001)
Initiated Bioinformatics;
Protein Structure Prediction,
Homology modeling
(1991-2001)
23.
23
Scope of topics
Biological databases (utilization, development and
integration etc.)
Analyses of nucleotide and protein sequence information
Analyses of 3D structural data of macromolecules.
Assessment of how small molecules interact with
macromolecules in biological systems.
Studies on networks of protein-protein interactions
Simulation of biological processes
More
24.
24
Scope of topics
Biological databases (utilization, development and
integration etc.)
Analyses of nucleotide and protein sequence information
Analyses of 3D structural data of macromolecules.
Assessment of how small molecules interact with
macromolecules in biological systems.
Studies on networks of protein-protein interactions
Simulation of biological processes
More
25.
25
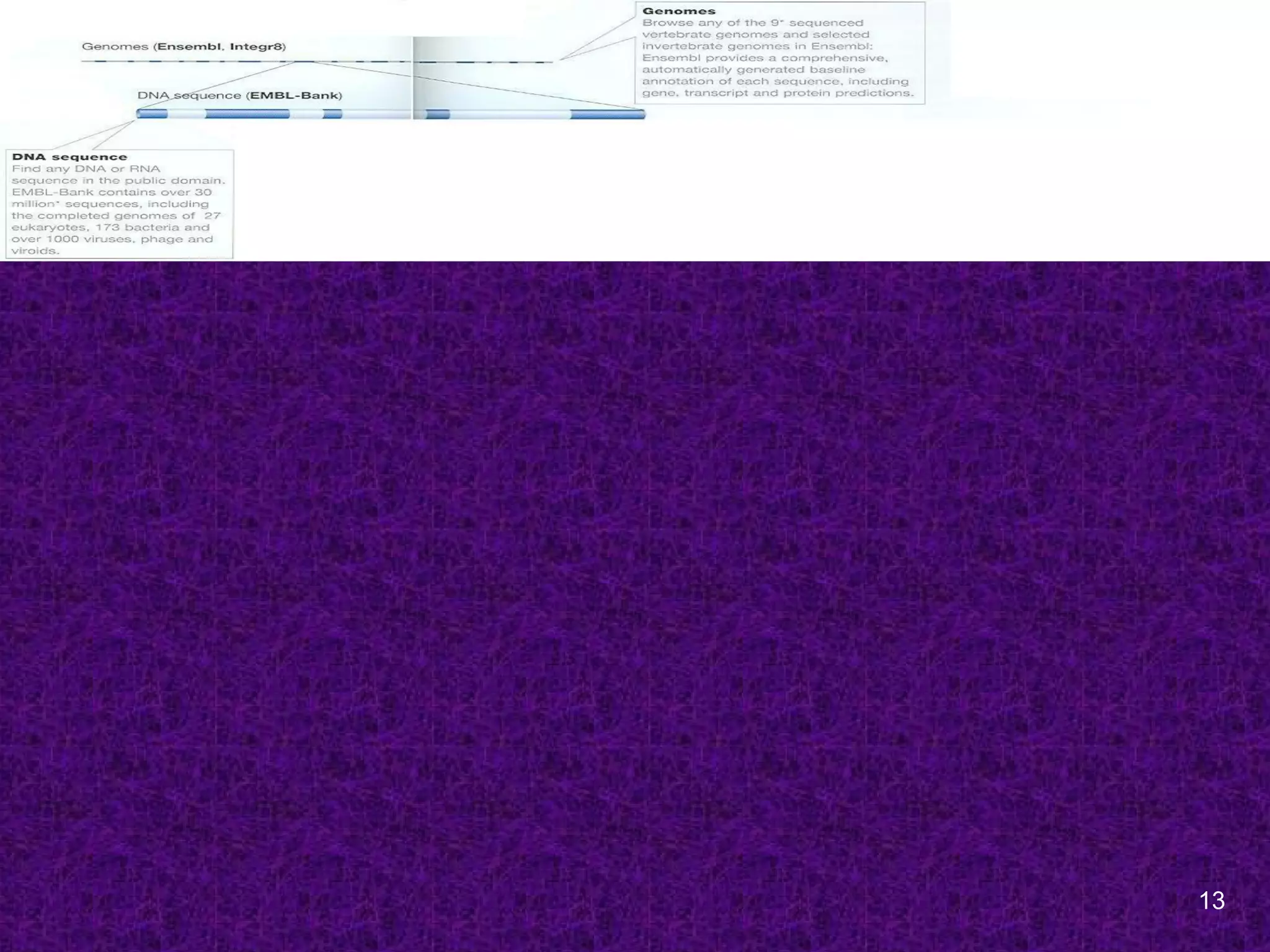
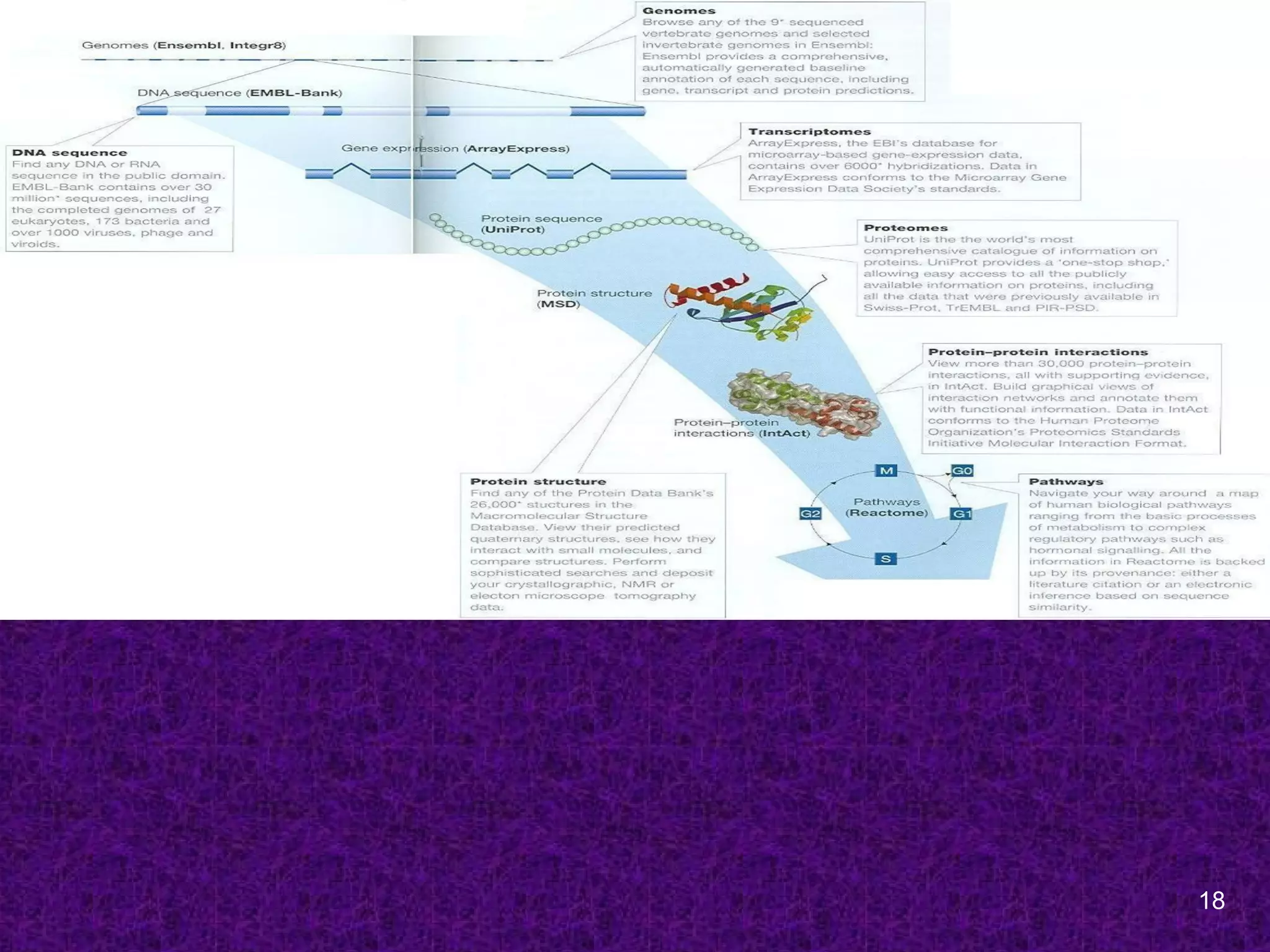
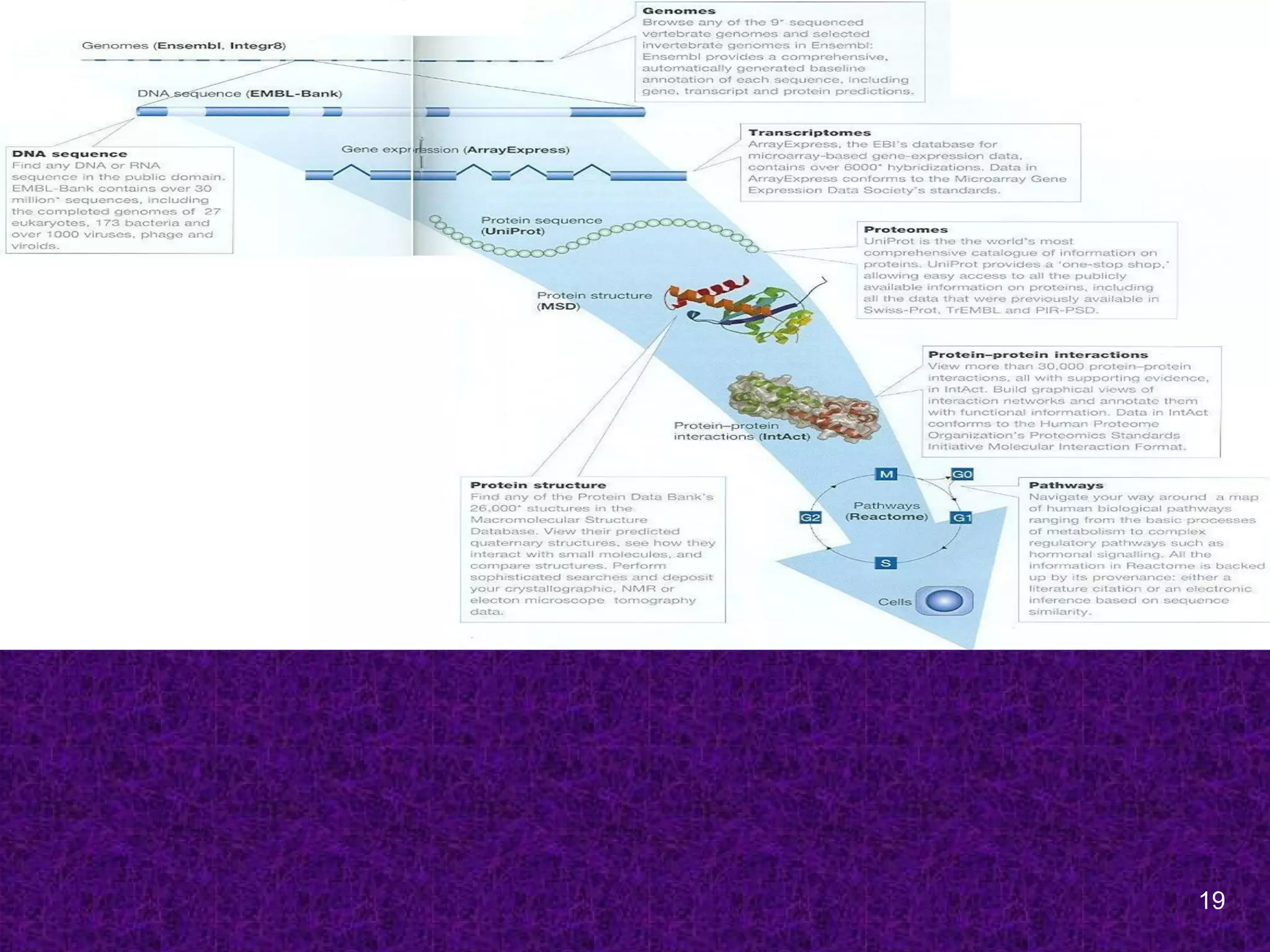
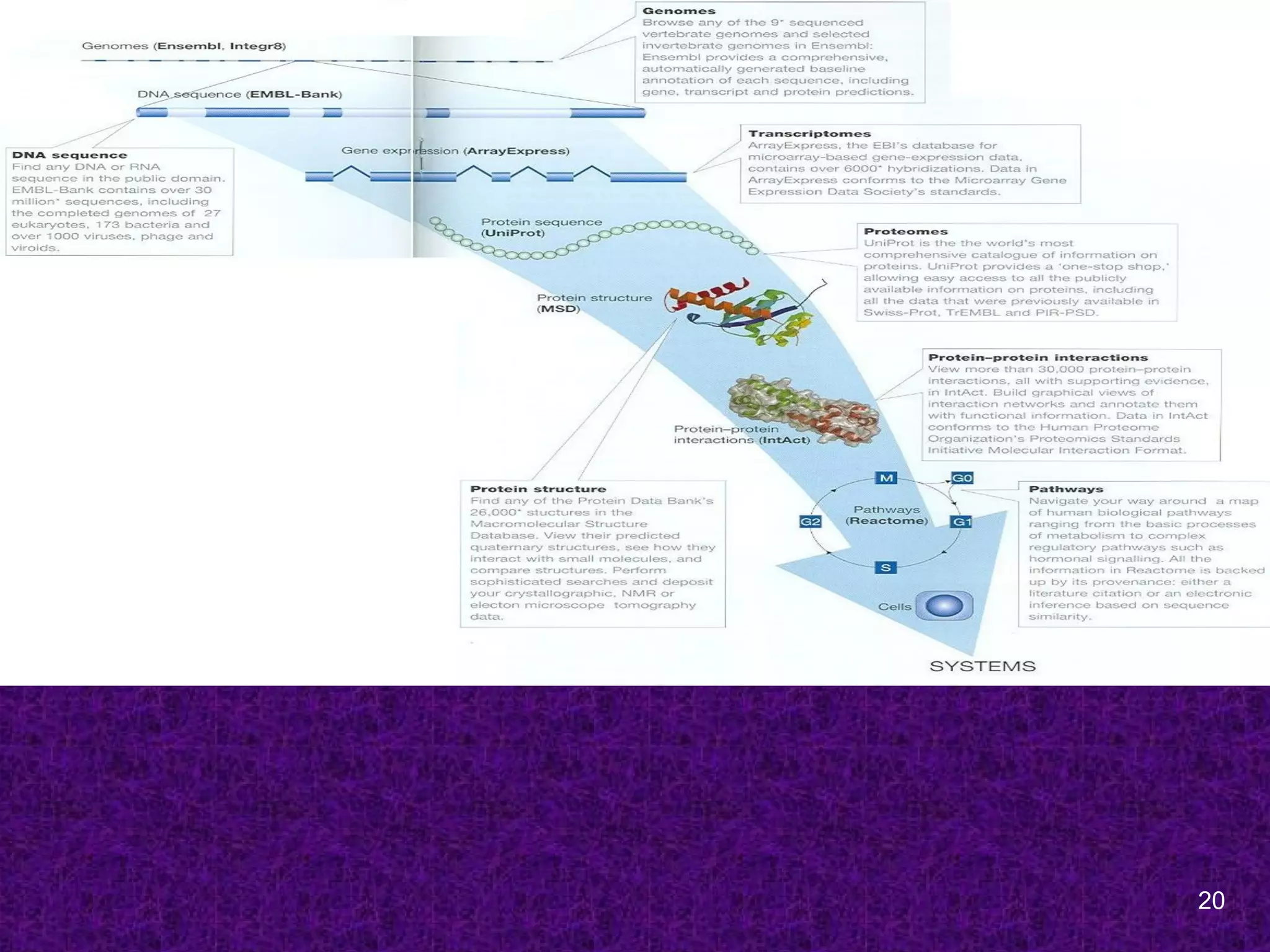
Bioinformatics Resources
Sequence Databases
1960s; The first sequences to be collected
were those of proteins by Margaret Dayhoff
at the NBRF, Washington, USA.
[Protein sequence atlas; PIR]
1970s; First DNA sequences databases were
(a) the GenBank at Los Alamos National
Labotaroy, New Maxico, USA
(b) EMBL at the European Molecular Biology
Laboratory at Heidelberg, Germany.
26.
26
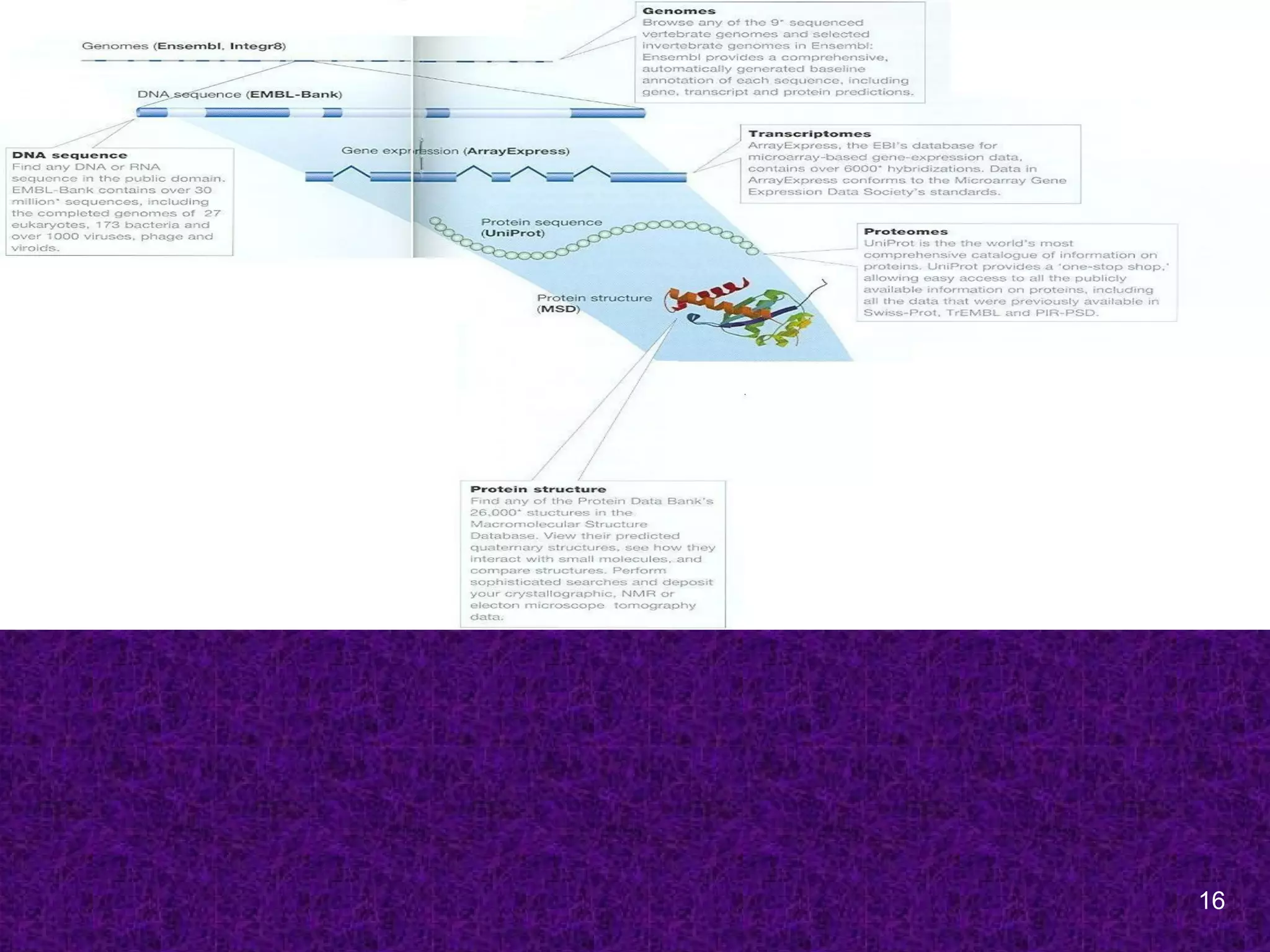
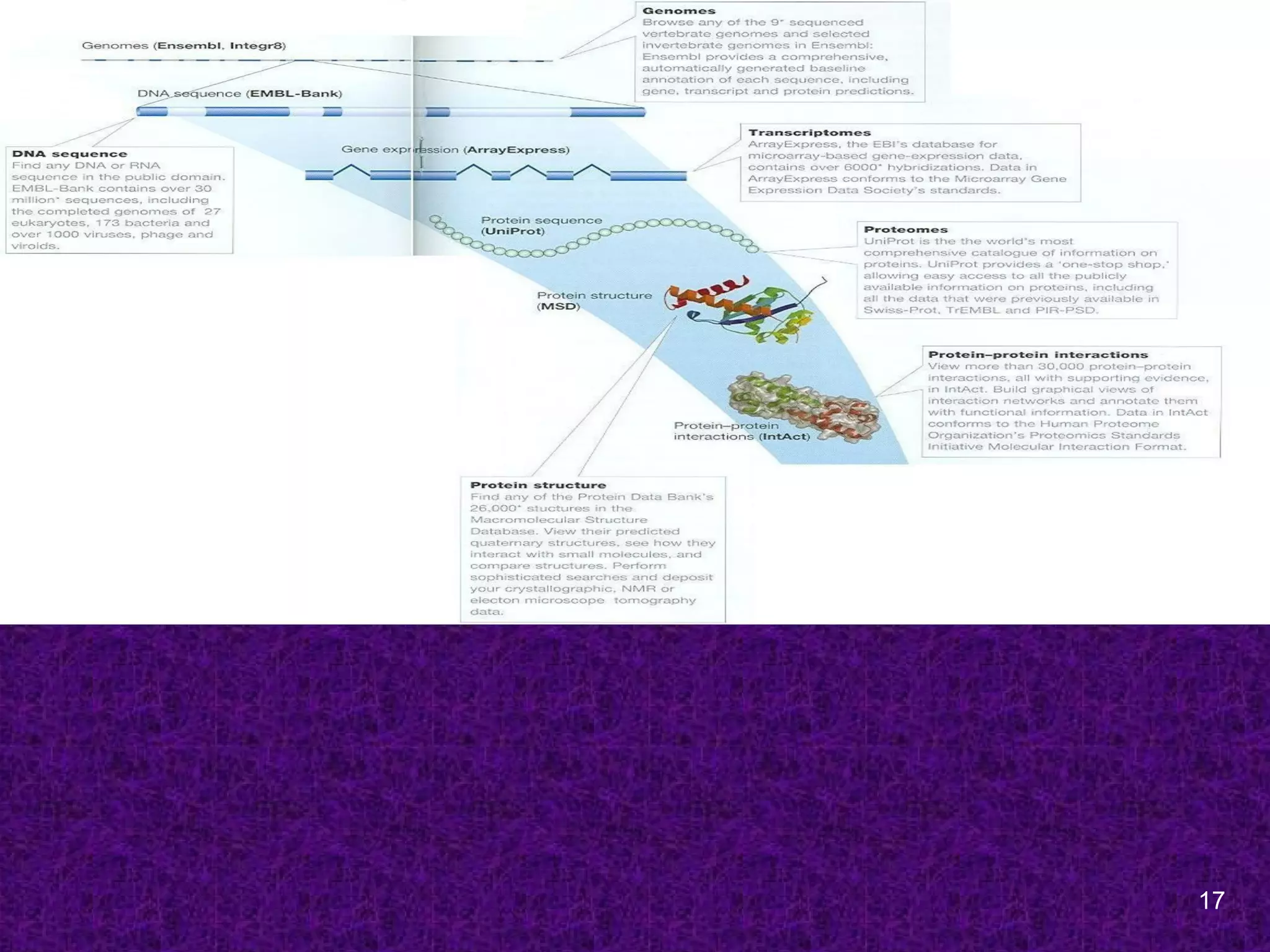
Primary Bioinformatics Databases
DNA sequence databases
GenBank, EMBL and DDBJ
Genome Centers databases
Sanger Center, TIGR
Protein sequence Databases
SwissProt, PIR, UniProt
Protein 3D structure databases
PDB, SCOP, CATH
Specialized databases
MEROPS, Protein Kinase Resource
27.
27
Accessing Bioinformatics Databases
ENTREZ; a window-based program with
a web-based interface developed at
the NCBI, USA.
SRS; similar service at the EBI, UK.
29
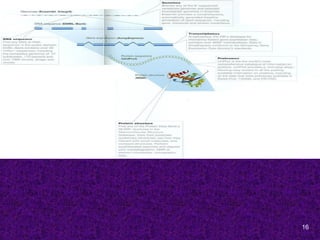
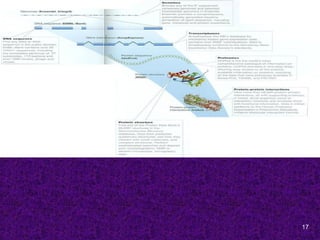
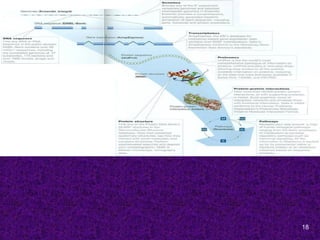
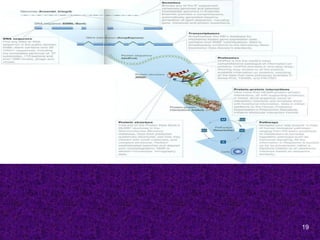
Specialized databases usefulin Molecular Medicine
OMIM- Online Mendelian Inheritance in Man. This
database is a catalog of human genes and genetic disorders.
ENSEMBL- is designed to allow free access to all the genetic
information available about the Human Genome.
Human Gene Mutation DB- contains sequences and
phenotypes of human disease-causing mutations.
KEGG- to computerize knowledge of molecular interactions
namely metabolic pathways, regulatory pathways and molecular
assemblies.
dbSNP- Single Nucleotide Polymorphisms DB
GeneCards- an integrated DB of human genes that includes
automatically-mined genomic, proteomic and transcriptomic
information, as well as orthologies, disease relationships, SNPs,
gene expression, gene function etc.
30.
30
Scope of topics
Biological databases (utilization, development and
integration etc.)
Analyses of nucleotide and protein sequence information
Analyses of 3D structural data of macromolecules.
Assessment of how small molecules interact with
macromolecules in biological systems.
Studies on networks of protein-protein interactions
Simulation of biological processes
More
31.
31
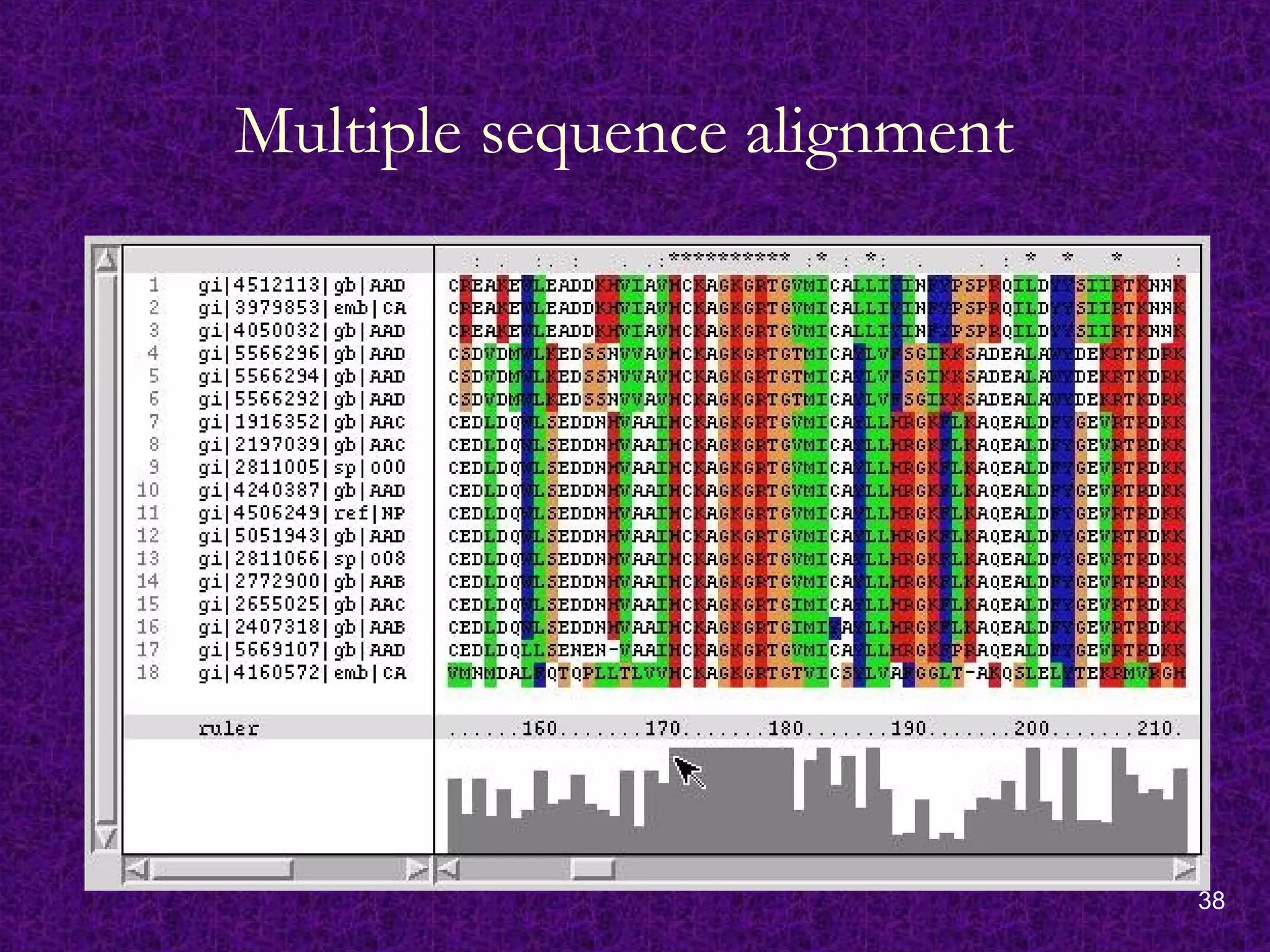
Sequence Analysis
Sequence AnalysisPrograms
As more DNA sequences became available in the late
1970s, interest also increased in developing computer
programs to analyze the sequences.
In early 1980s, the Genetics Computer Group (GCG)
was started at the University of Wisconsin, USA, offering
a set of programs for sequence analysis.
32.
32
Sequence Analysis
Methods forComparing Sequences
The Dot Matrix method (DOTPLOT, COMPARE)
Dynamic programming matrices
Word or k-tuple methods (FASTA, BLAST)
33.
33
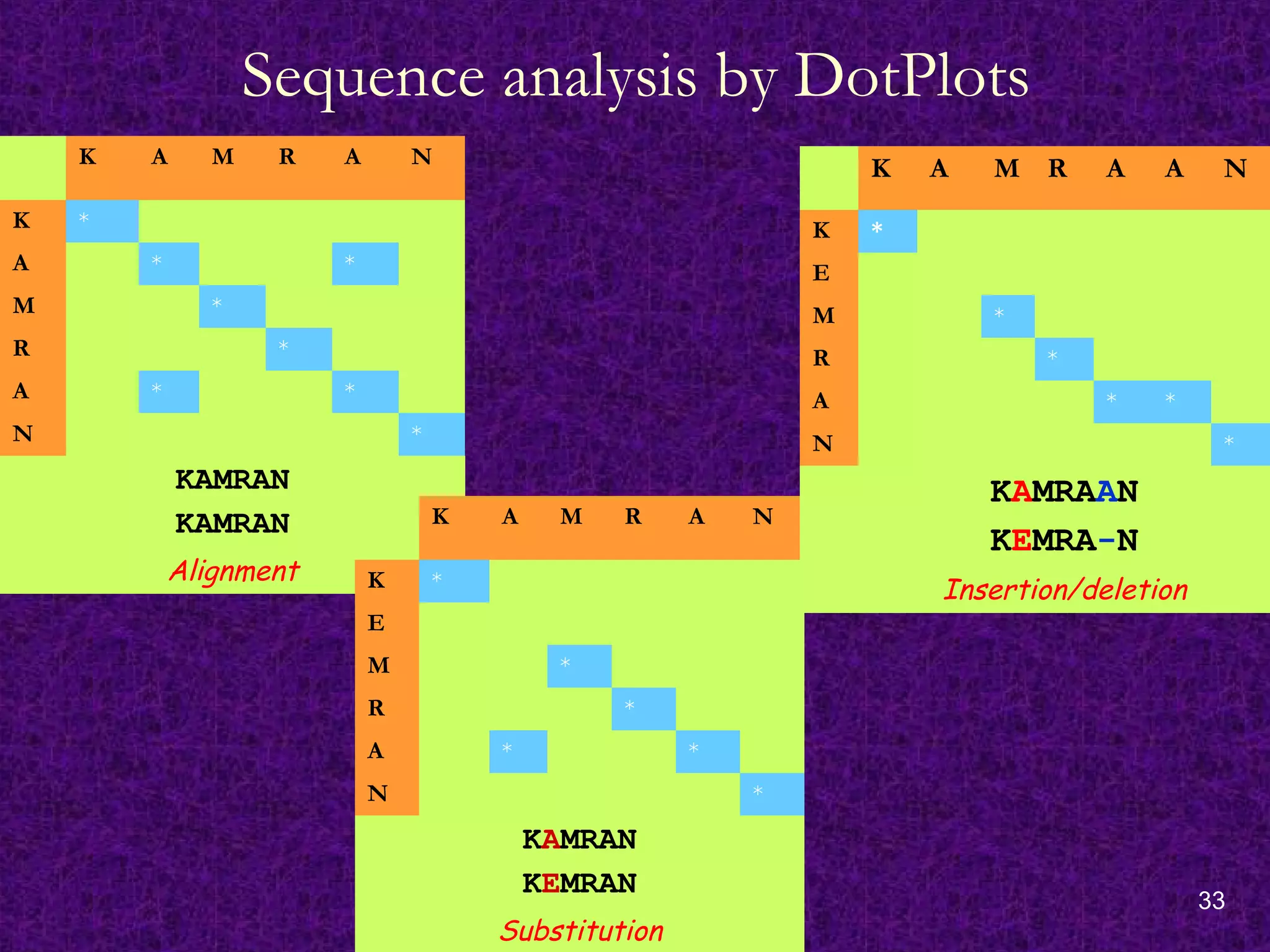
Sequence analysis byDotPlots
K A M R A N
K *
A * *
M *
R *
A * *
N *
KAMRAN
KAMRAN
Alignment
K A M R A N
K *
E
M *
R *
A * *
N *
KAMRAN
KEMRAN
Substitution
K A M R A A N
K *
E
M *
R *
A * *
N *
KAMRAAN
KEMRA-N
Insertion/deletion
34.
34
DotDlot analysis; repetitivesequences
K A M R A N K A M R A N
K
* *
E
M
* *
R
* *
A
* * * *
N
* *
K
* *
E
M
* *
R
* *
A
* * * *
N
* *
37
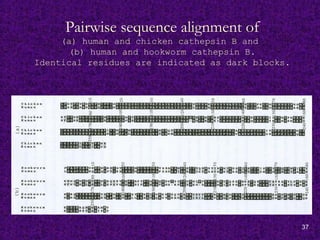
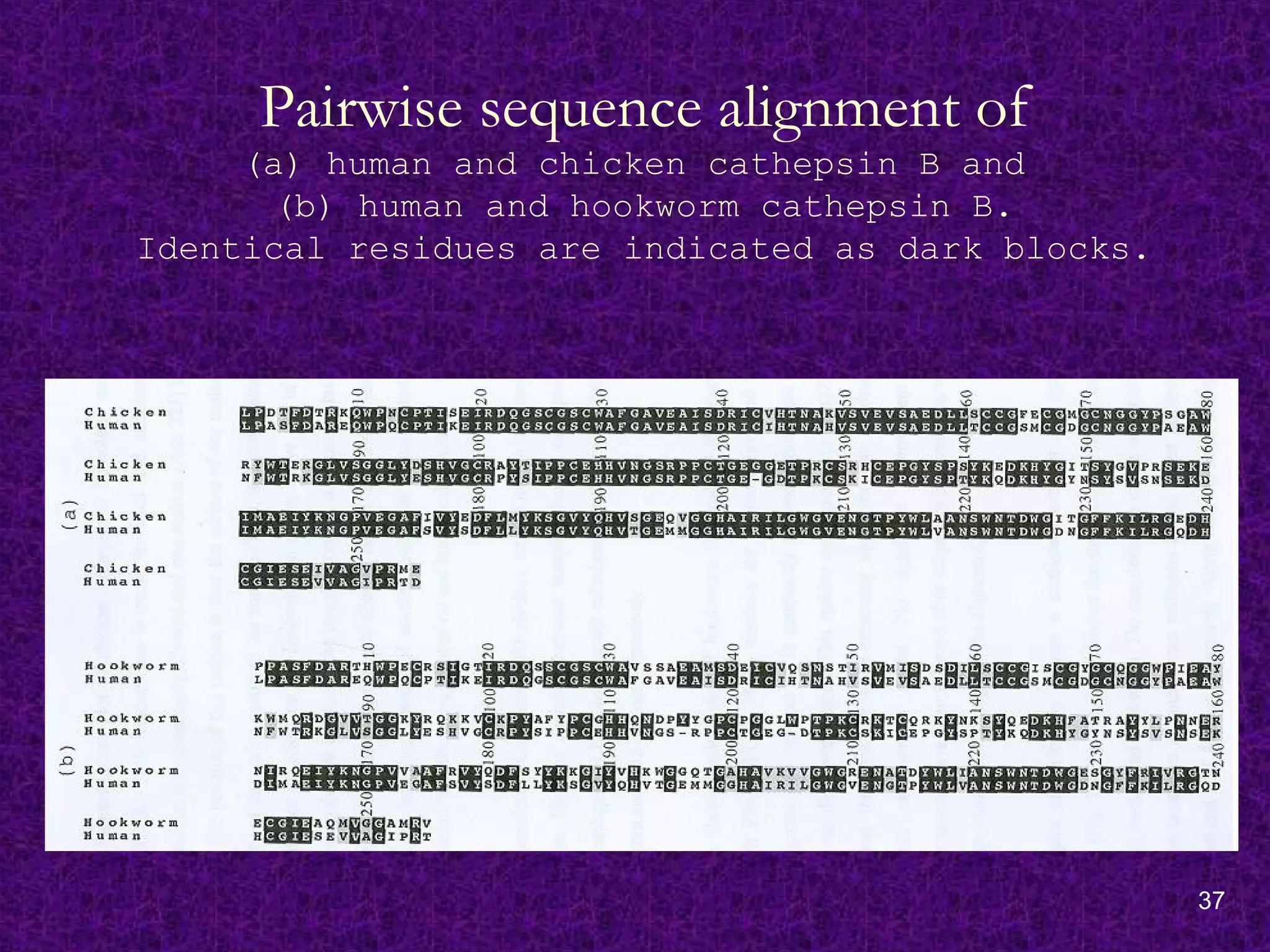
Pairwise sequence alignmentof
(a) human and chicken cathepsin B and
(b) human and hookworm cathepsin B.
Identical residues are indicated as dark blocks.
41
Scope of topics
Biological databases (utilization, development and
integration etc.)
Analyses of nucleotide and protein sequence information
Analyses of 3D structural data of macromolecules.
three dimensional strutures and Structural Bioinformatics
Assessment of how small molecules interact with
macromolecules in biological systems.
Studies on networks of protein-protein interactions
Simulation of biological processes
More
42.
42
End Note
Bioinformaticsis the body of Knowledge;
A wealth of data on sequences and
structures.
Key Resource is KNOWLEDGE
And the key technology is INFORMATION
HANDLING
43.
43
Leading Bioinformatics Institutions
EuropeanBioinformatics Institute, Cambridge, UK
National Center for Biotechnology Information, USA
National Human Genome Research Institute, USA
EMBL, Heidelberg, Germany
J. Craig Ventor Institute, USA
[formerly The Institute of Genome Research (TIGR)]
The Sanger Institute, UK
Bioinformatics Journals and Books
Bioinformatics
Genome Research
Nucleic Acid Research
Bioinformatics by D.W. Mount
Introduction to Bioinformatics by Attwood
Structural Bioinformatics by P.E. Bourne
Bioinformatics; A beginner’s Guide by Claverie
Bioinformatics Computing by B. Bergeron
Bioinformatics Societies
International Society for Computational Biology (ICSB)
Asia Pacific Bioinformatics Network (APBioNet)
European Conference on Computational Biology (ECCB)















![25
Bioinformatics Resources
Sequence Databases
1960s; The first sequences to be collected
were those of proteins by Margaret Dayhoff
at the NBRF, Washington, USA.
[Protein sequence atlas; PIR]
1970s; First DNA sequences databases were
(a) the GenBank at Los Alamos National
Labotaroy, New Maxico, USA
(b) EMBL at the European Molecular Biology
Laboratory at Heidelberg, Germany.](https://image.slidesharecdn.com/pcmd-bioinformatics-lecturei-160805125941/85/Pcmd-bioinformatics-lecture-i-25-320.jpg)
















![43
Leading Bioinformatics Institutions
European Bioinformatics Institute, Cambridge, UK
National Center for Biotechnology Information, USA
National Human Genome Research Institute, USA
EMBL, Heidelberg, Germany
J. Craig Ventor Institute, USA
[formerly The Institute of Genome Research (TIGR)]
The Sanger Institute, UK
Bioinformatics Journals and Books
Bioinformatics
Genome Research
Nucleic Acid Research
Bioinformatics by D.W. Mount
Introduction to Bioinformatics by Attwood
Structural Bioinformatics by P.E. Bourne
Bioinformatics; A beginner’s Guide by Claverie
Bioinformatics Computing by B. Bergeron
Bioinformatics Societies
International Society for Computational Biology (ICSB)
Asia Pacific Bioinformatics Network (APBioNet)
European Conference on Computational Biology (ECCB)](https://image.slidesharecdn.com/pcmd-bioinformatics-lecturei-160805125941/85/Pcmd-bioinformatics-lecture-i-43-320.jpg)















![25
Bioinformatics Resources
Sequence Databases
1960s; The first sequences to be collected
were those of proteins by Margaret Dayhoff
at the NBRF, Washington, USA.
[Protein sequence atlas; PIR]
1970s; First DNA sequences databases were
(a) the GenBank at Los Alamos National
Labotaroy, New Maxico, USA
(b) EMBL at the European Molecular Biology
Laboratory at Heidelberg, Germany.](https://image.slidesharecdn.com/pcmd-bioinformatics-lecturei-160805125941/75/Pcmd-bioinformatics-lecture-i-25-2048.jpg)













![43
Leading Bioinformatics Institutions
European Bioinformatics Institute, Cambridge, UK
National Center for Biotechnology Information, USA
National Human Genome Research Institute, USA
EMBL, Heidelberg, Germany
J. Craig Ventor Institute, USA
[formerly The Institute of Genome Research (TIGR)]
The Sanger Institute, UK
Bioinformatics Journals and Books
Bioinformatics
Genome Research
Nucleic Acid Research
Bioinformatics by D.W. Mount
Introduction to Bioinformatics by Attwood
Structural Bioinformatics by P.E. Bourne
Bioinformatics; A beginner’s Guide by Claverie
Bioinformatics Computing by B. Bergeron
Bioinformatics Societies
International Society for Computational Biology (ICSB)
Asia Pacific Bioinformatics Network (APBioNet)
European Conference on Computational Biology (ECCB)](https://image.slidesharecdn.com/pcmd-bioinformatics-lecturei-160805125941/75/Pcmd-bioinformatics-lecture-i-43-2048.jpg)

























































































