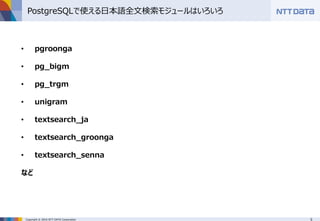
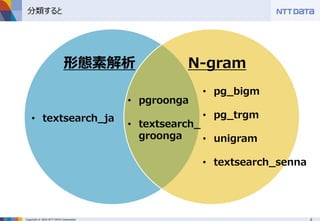
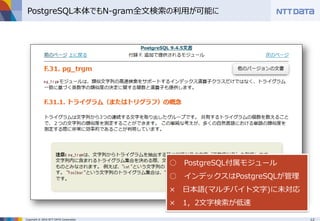
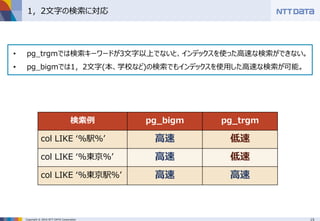
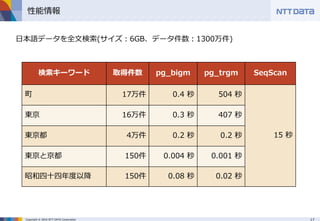
■PostgreSQLでpg_bigmを使って日本語全文検索 ~pg_bigmで全文検索するときに知っておくべき8のこと~ (MySQLとPostgreSQLの日本語全文検索勉強会 発表資料) NTTデータ 澤田 雅彦













































































![[B23] PostgreSQLのインデックス・チューニング by Tomonari Katsumata](https://cdn.slidesharecdn.com/ss_thumbnails/b23ntt-140624233630-phpapp02-thumbnail.jpg?width=600ounds&width=560&fit=bounds)





























