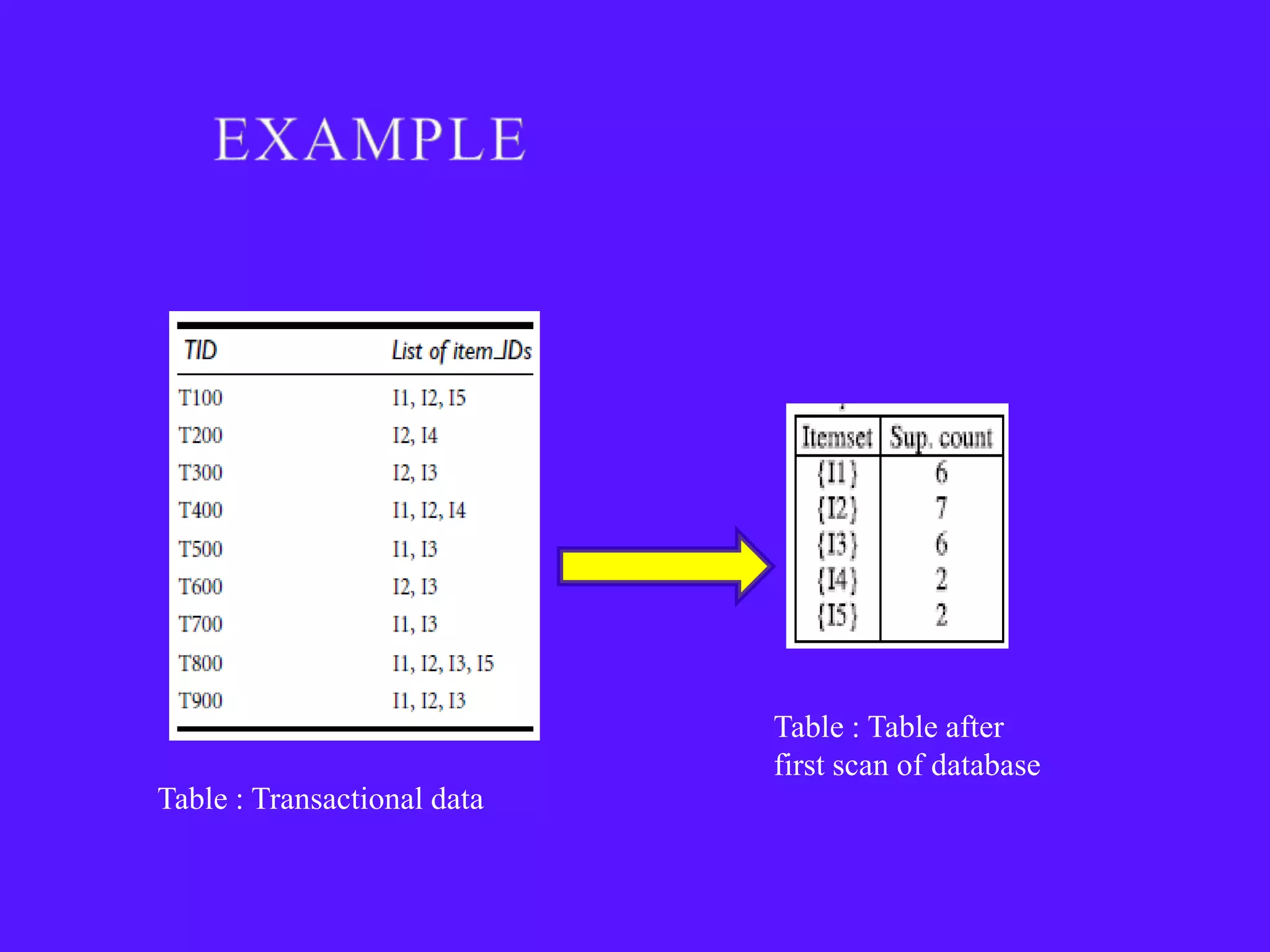
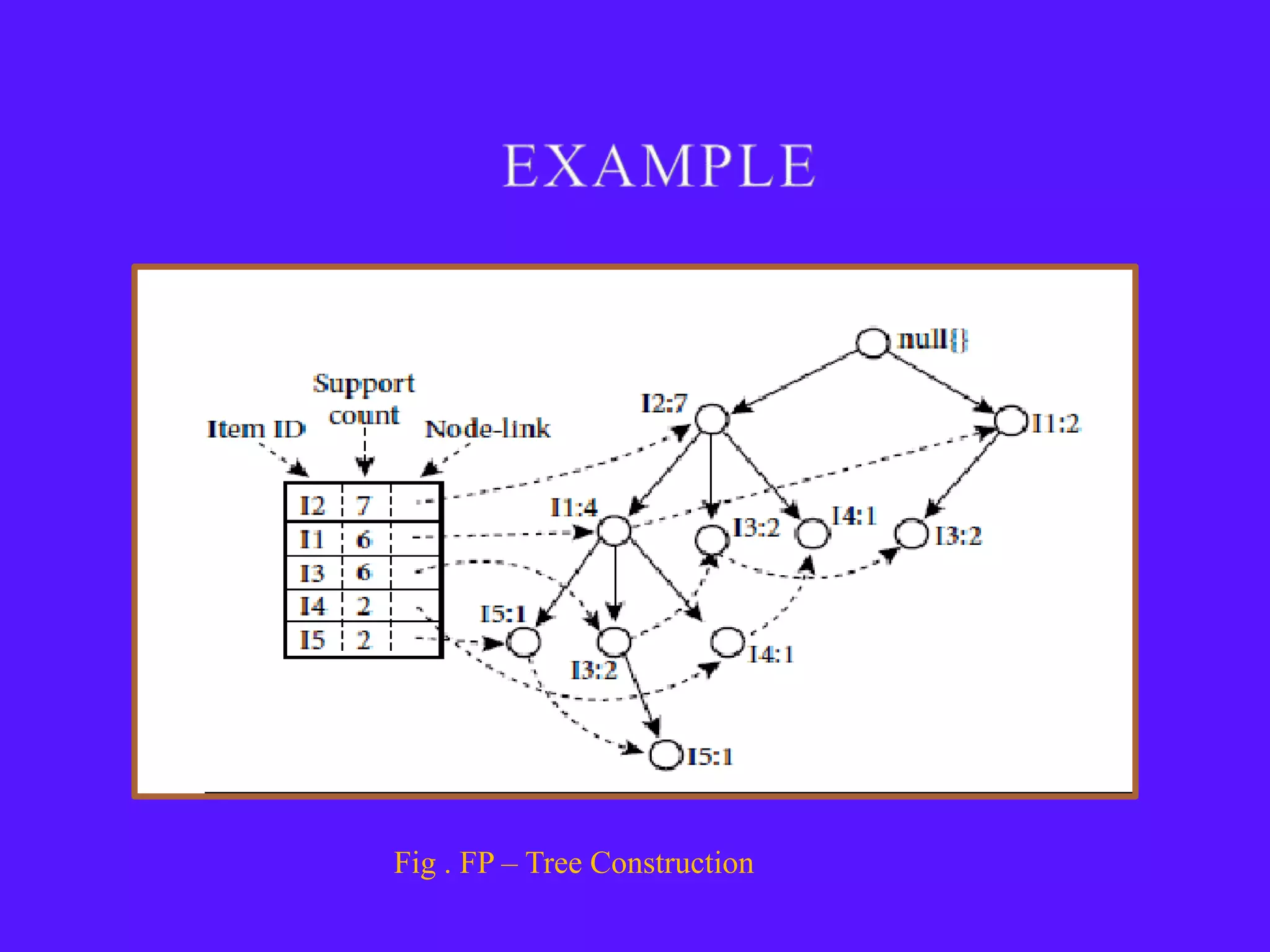
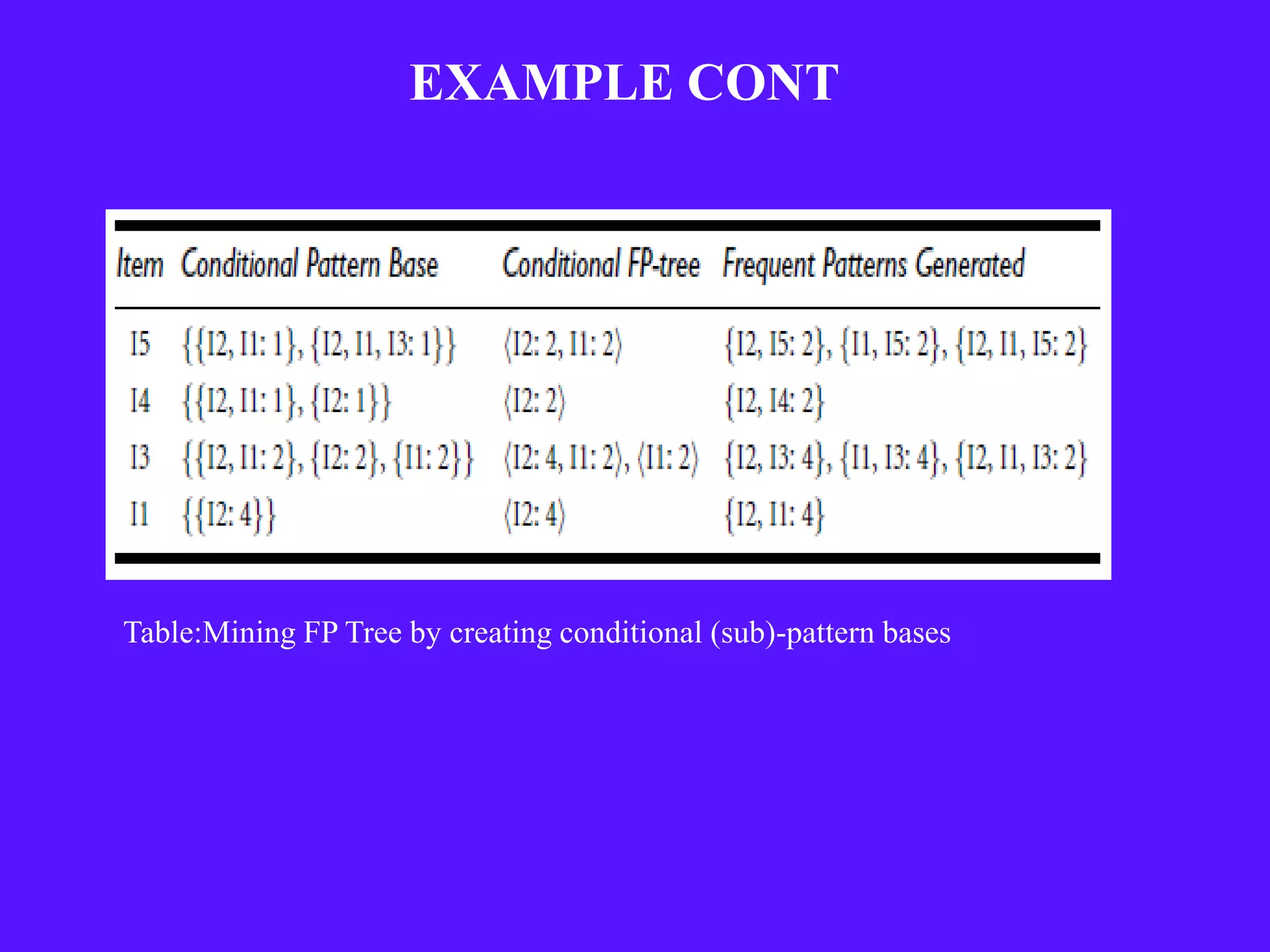
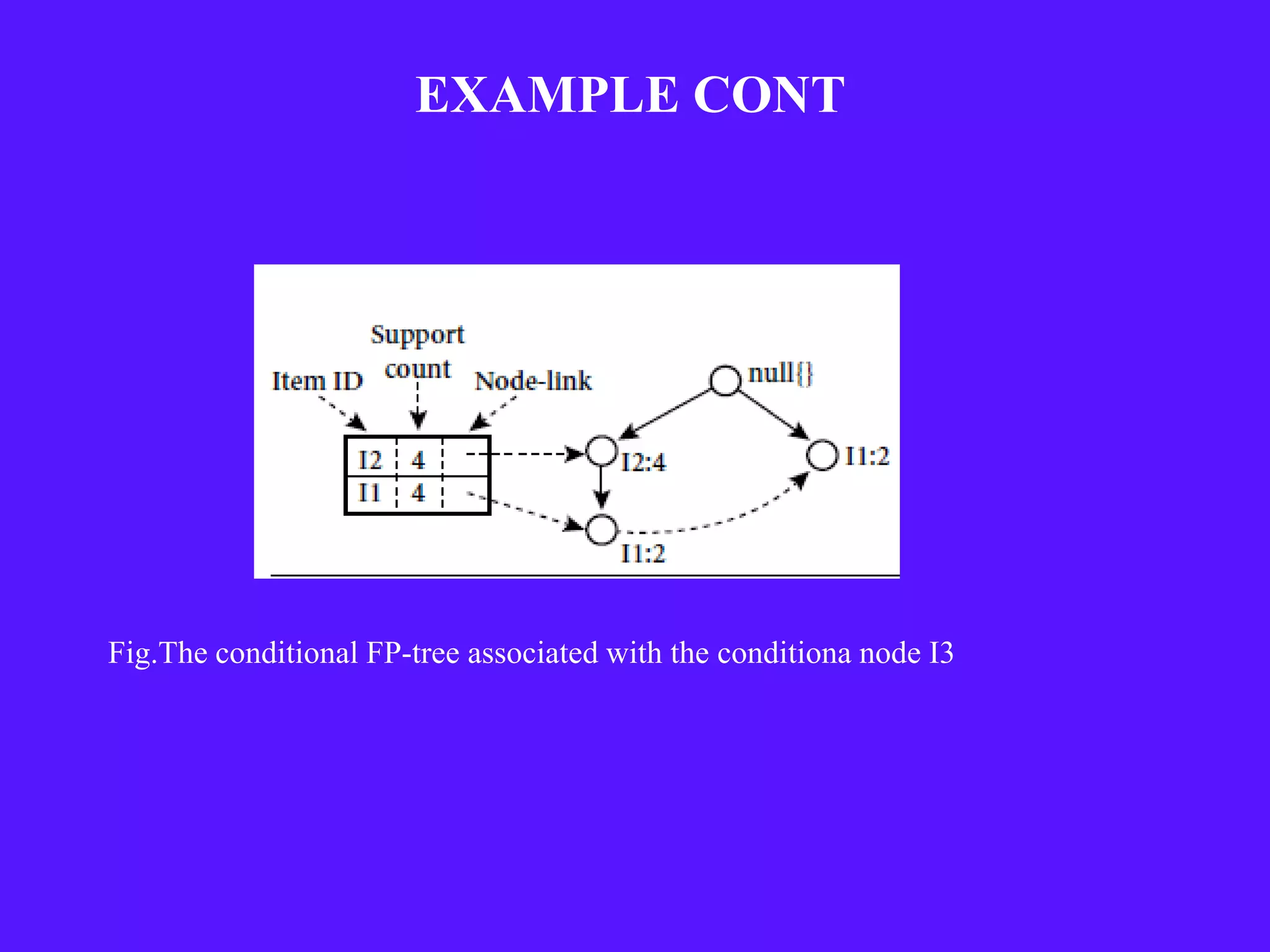
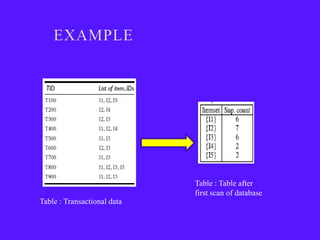
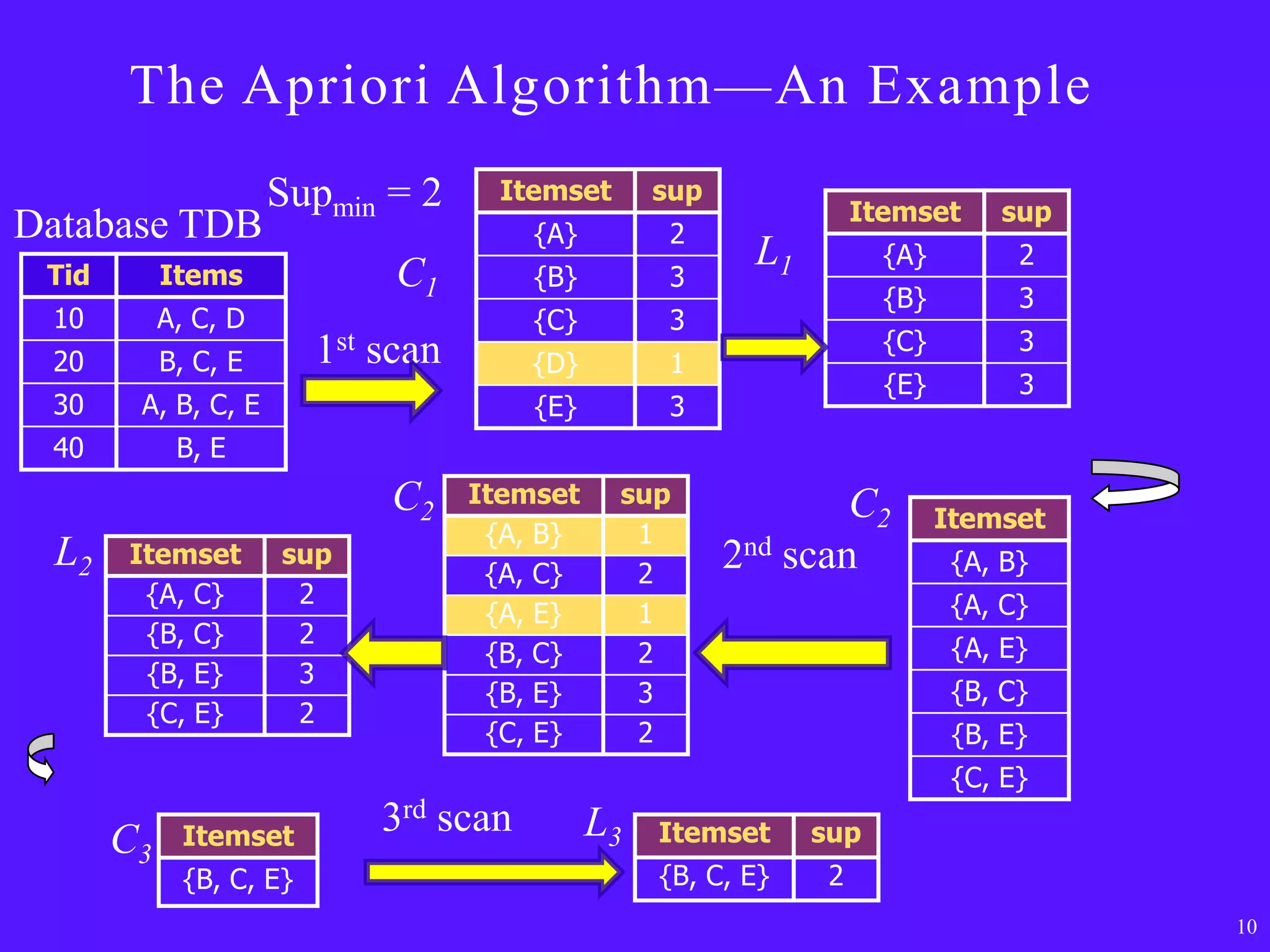
The document provides an overview of sequential pattern mining. It discusses the challenges of mining sequential patterns from large databases due to the huge number of possible patterns. It then describes the Apriori algorithm as an example approach, showing the pseudocode. It works in multiple passes over the database, generating candidate itemsets in each pass and pruning those that don't meet the minimum support threshold. The document also summarizes the FP-Growth algorithm, which avoids candidate generation by building a compact FP-tree structure and mining it recursively to extract patterns. Applications mentioned include customer shopping sequences, medical treatments, and DNA sequences.










![The Apriori Algorithm [Pseudo-Code]
Ck: Candidate itemset of size k
Lk : frequent itemset of size k
L1 = {frequent items};
for (k = 1; Lk != ; k++) do begin
Ck+1 = candidates generated from Lk;
for each transaction t in database do
increment the count of all candidates in Ck+1 that are
contained in t
Lk+1 = candidates in Ck+1 with min_support
end
return k Lk;
11](https://image.slidesharecdn.com/sequentialpatternmining-130315093139-phpapp02/85/Sequential-pattern-mining-11-320.jpg)
























![The Apriori Algorithm [Pseudo-Code]
Ck: Candidate itemset of size k
Lk : frequent itemset of size k
L1 = {frequent items};
for (k = 1; Lk != ; k++) do begin
Ck+1 = candidates generated from Lk;
for each transaction t in database do
increment the count of all candidates in Ck+1 that are
contained in t
Lk+1 = candidates in Ck+1 with min_support
end
return k Lk;
11](https://image.slidesharecdn.com/sequentialpatternmining-130315093139-phpapp02/75/Sequential-pattern-mining-11-2048.jpg)