






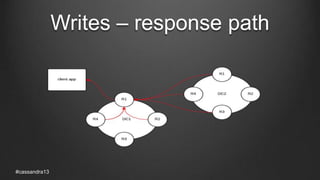




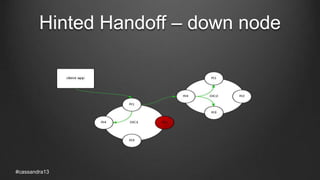
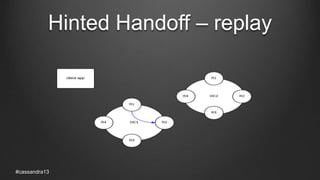
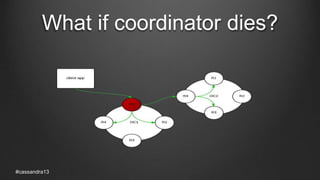



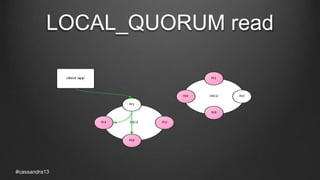


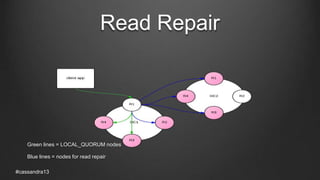





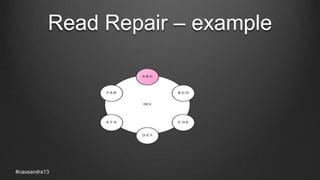
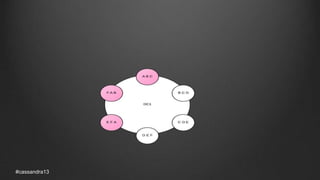
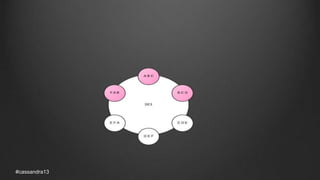
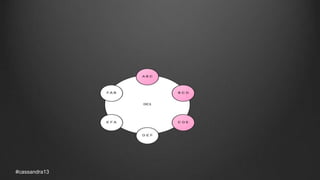








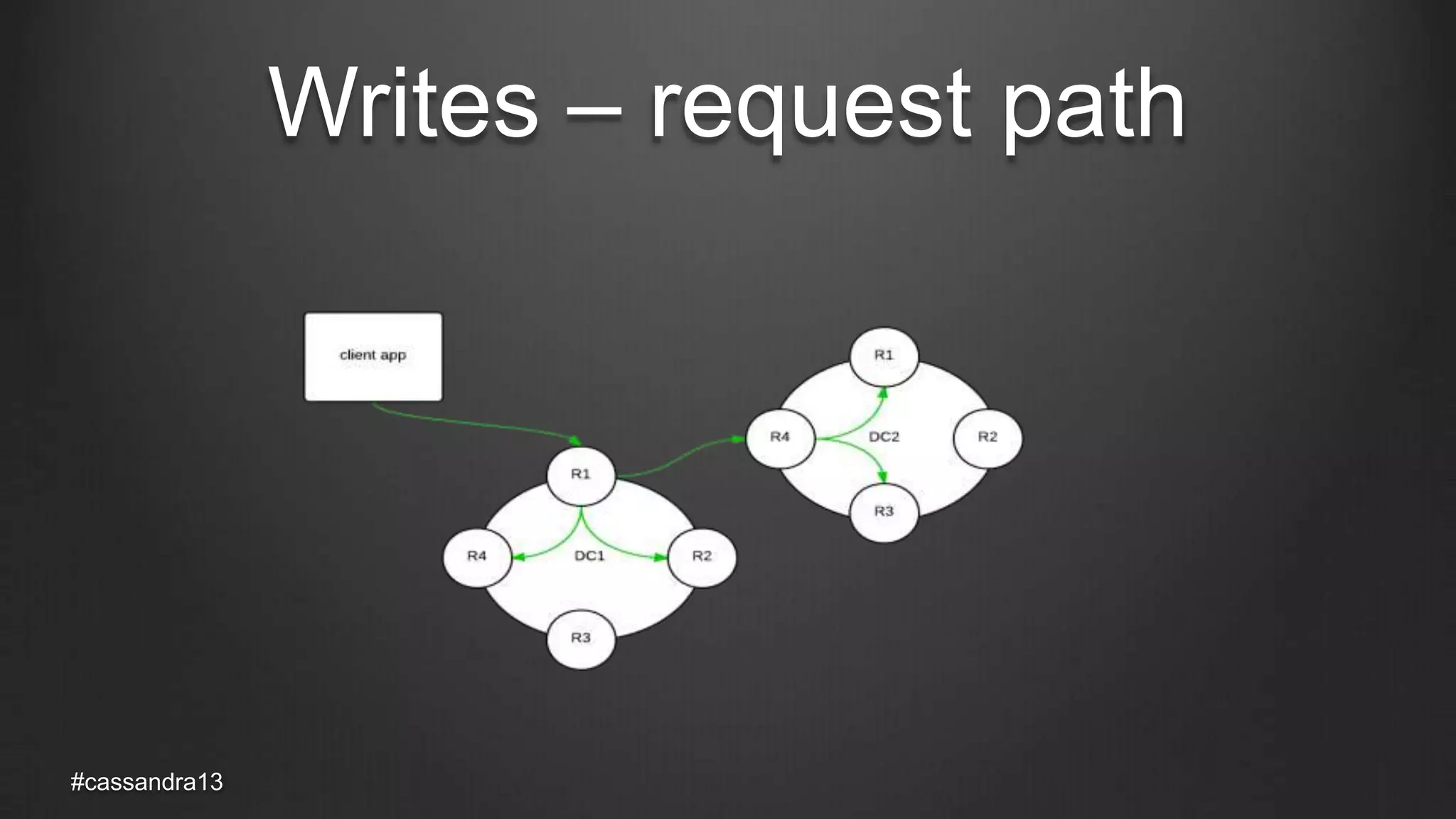
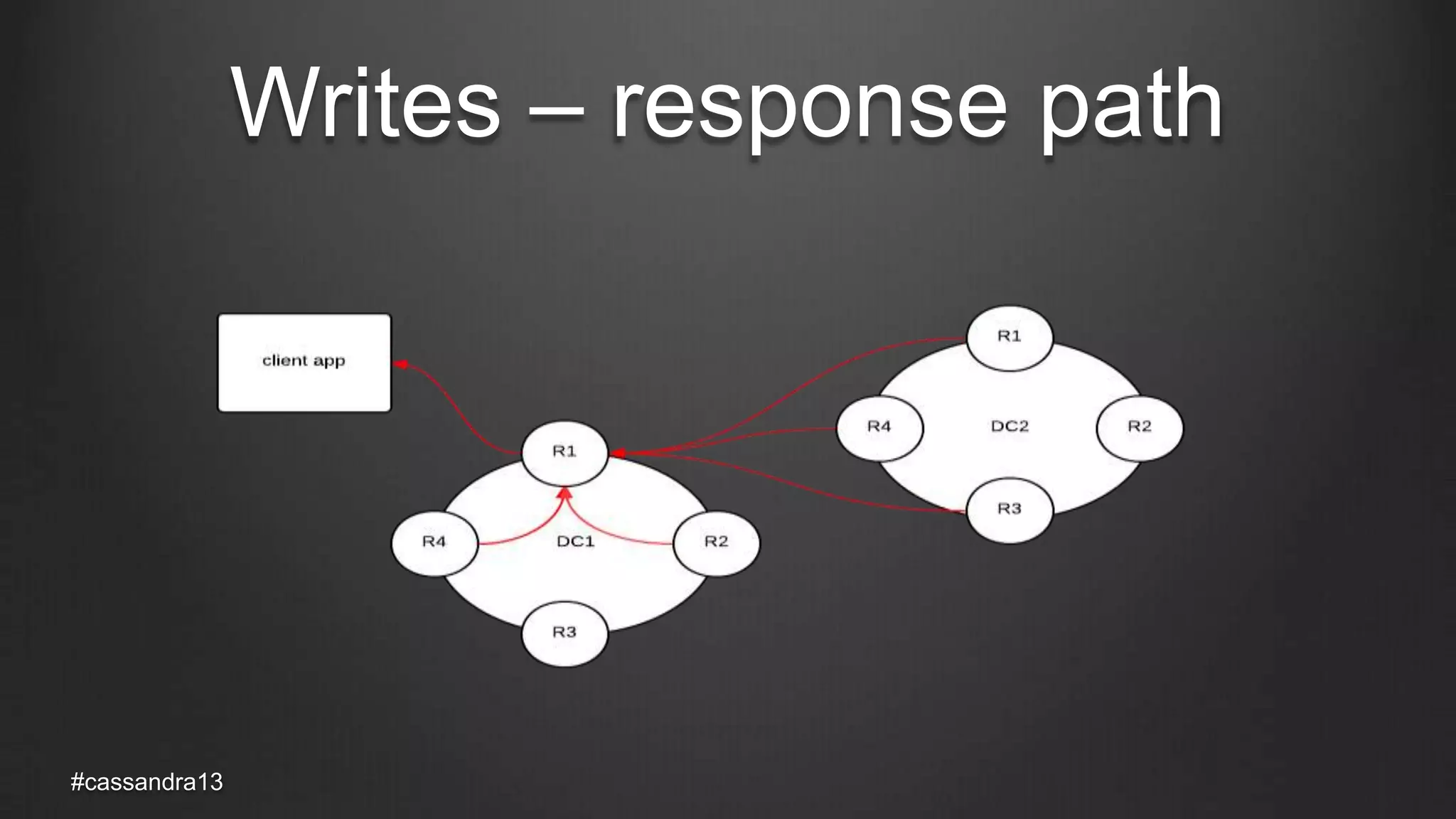




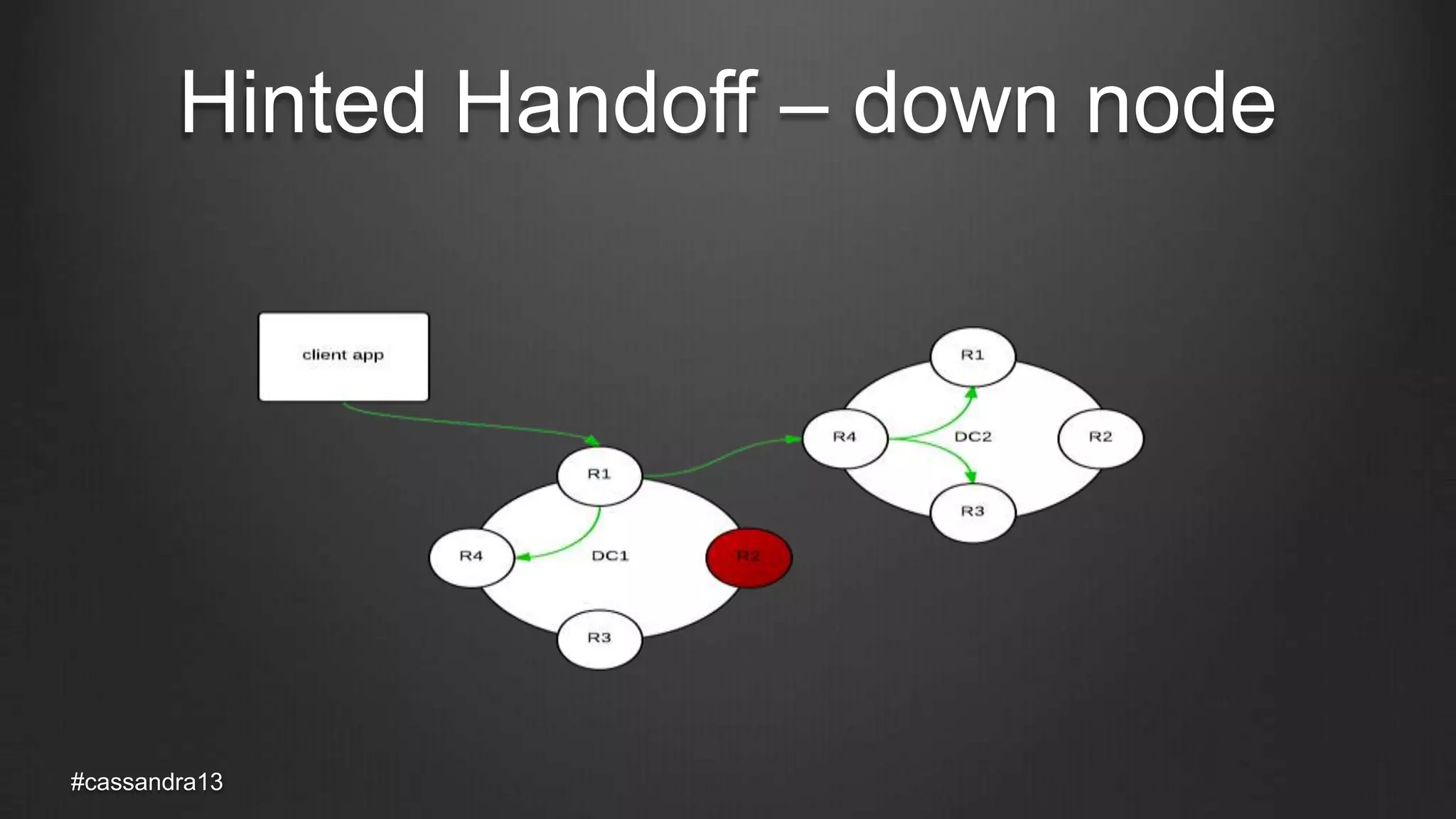
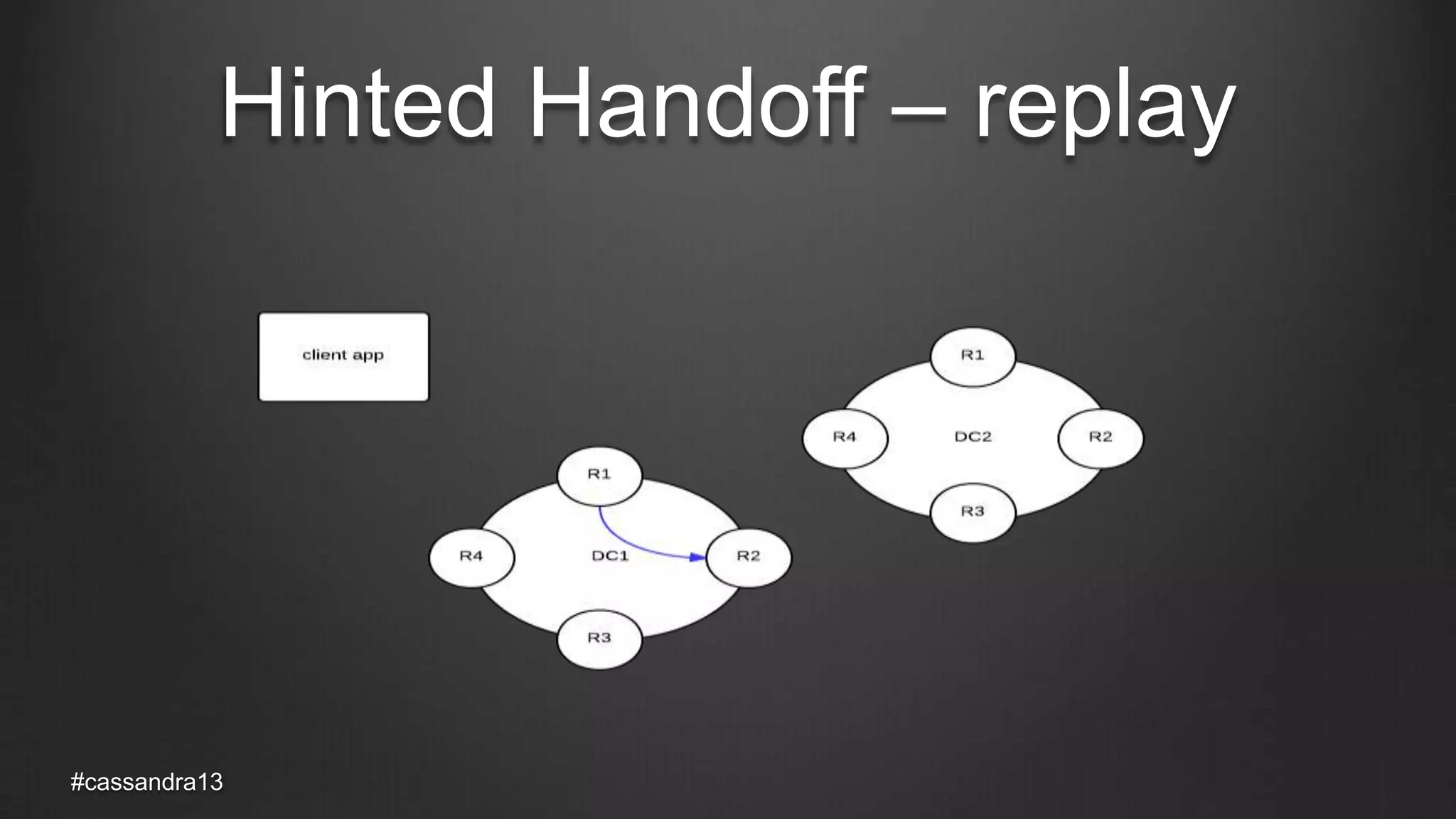
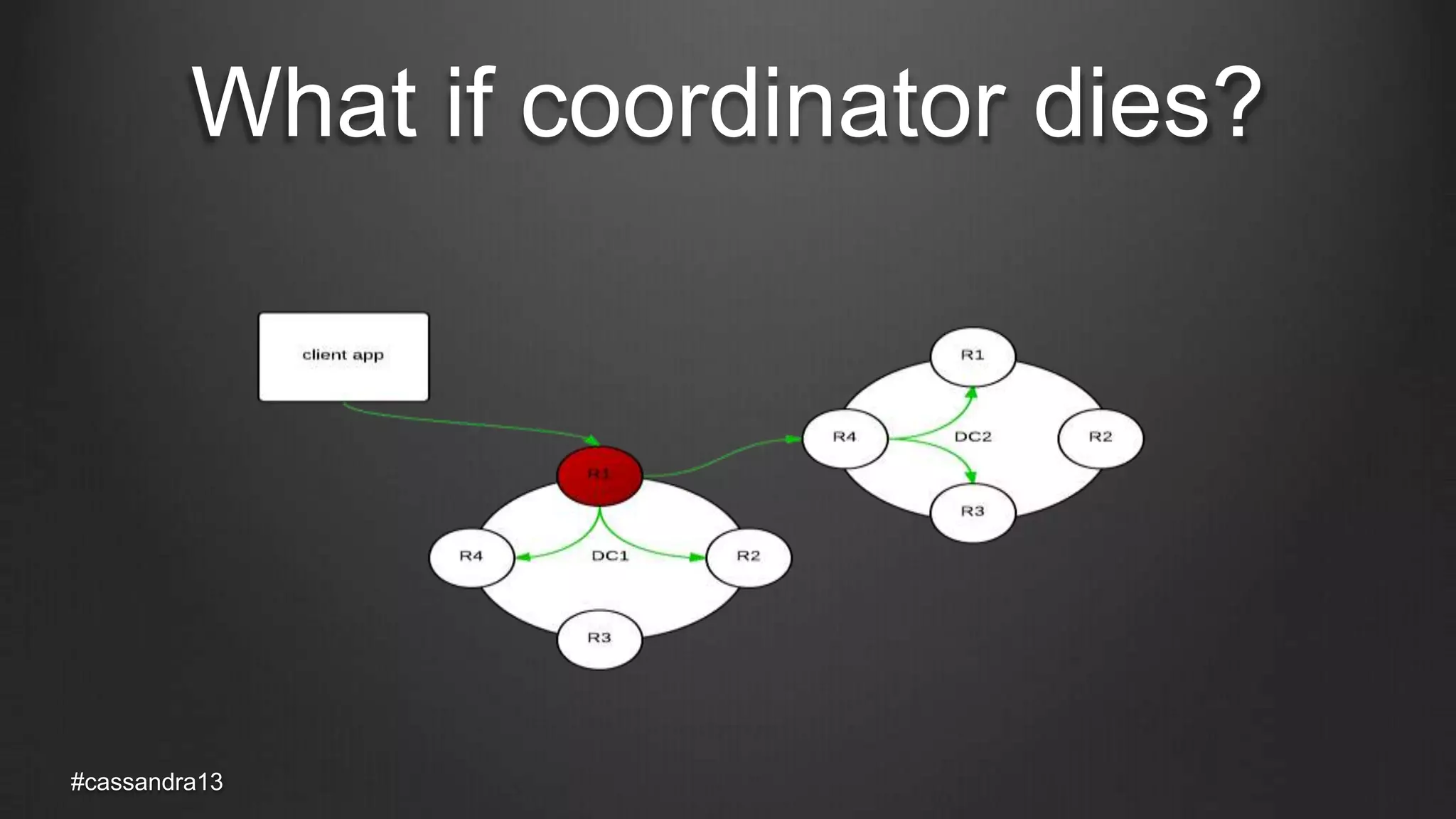


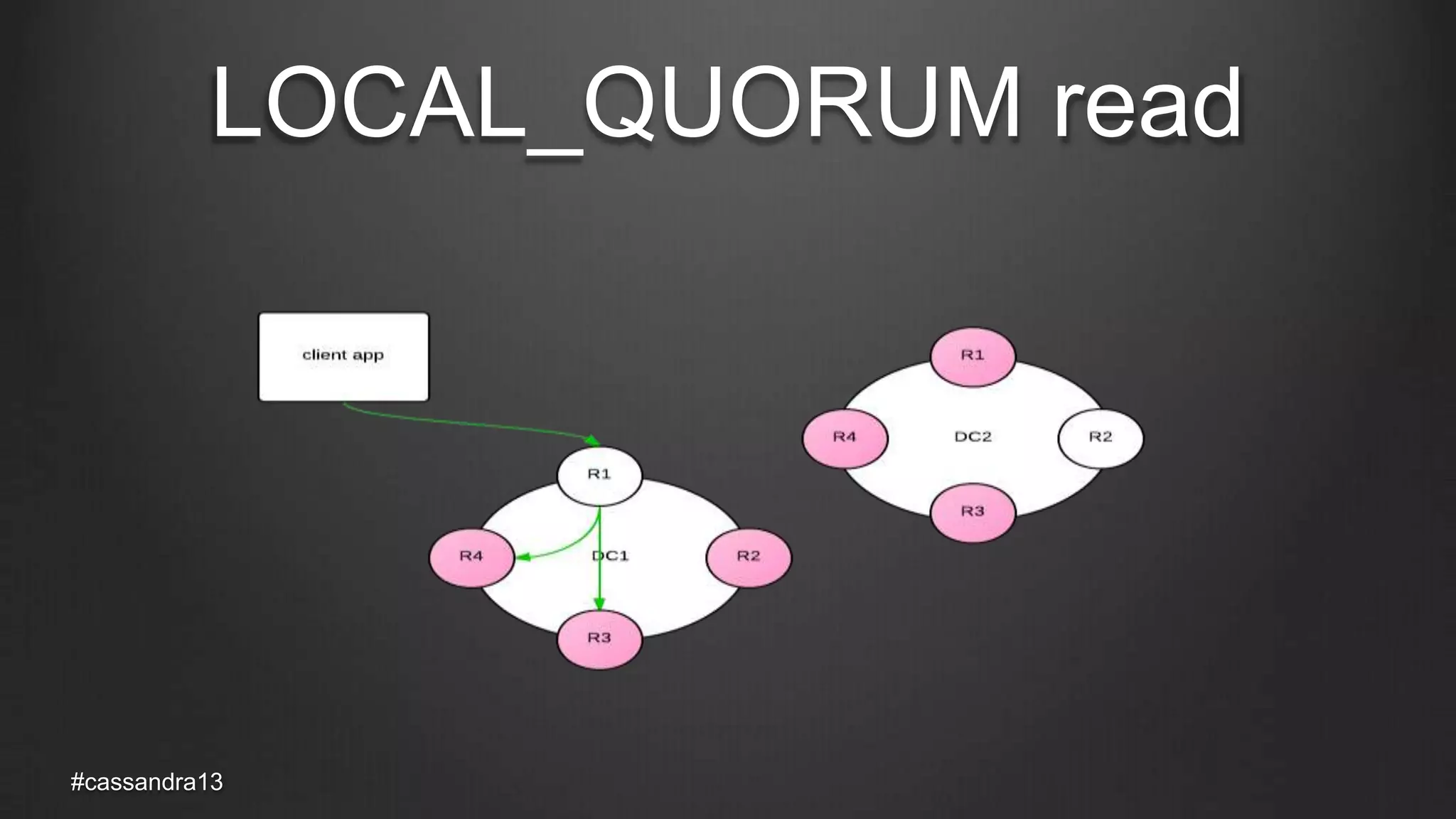


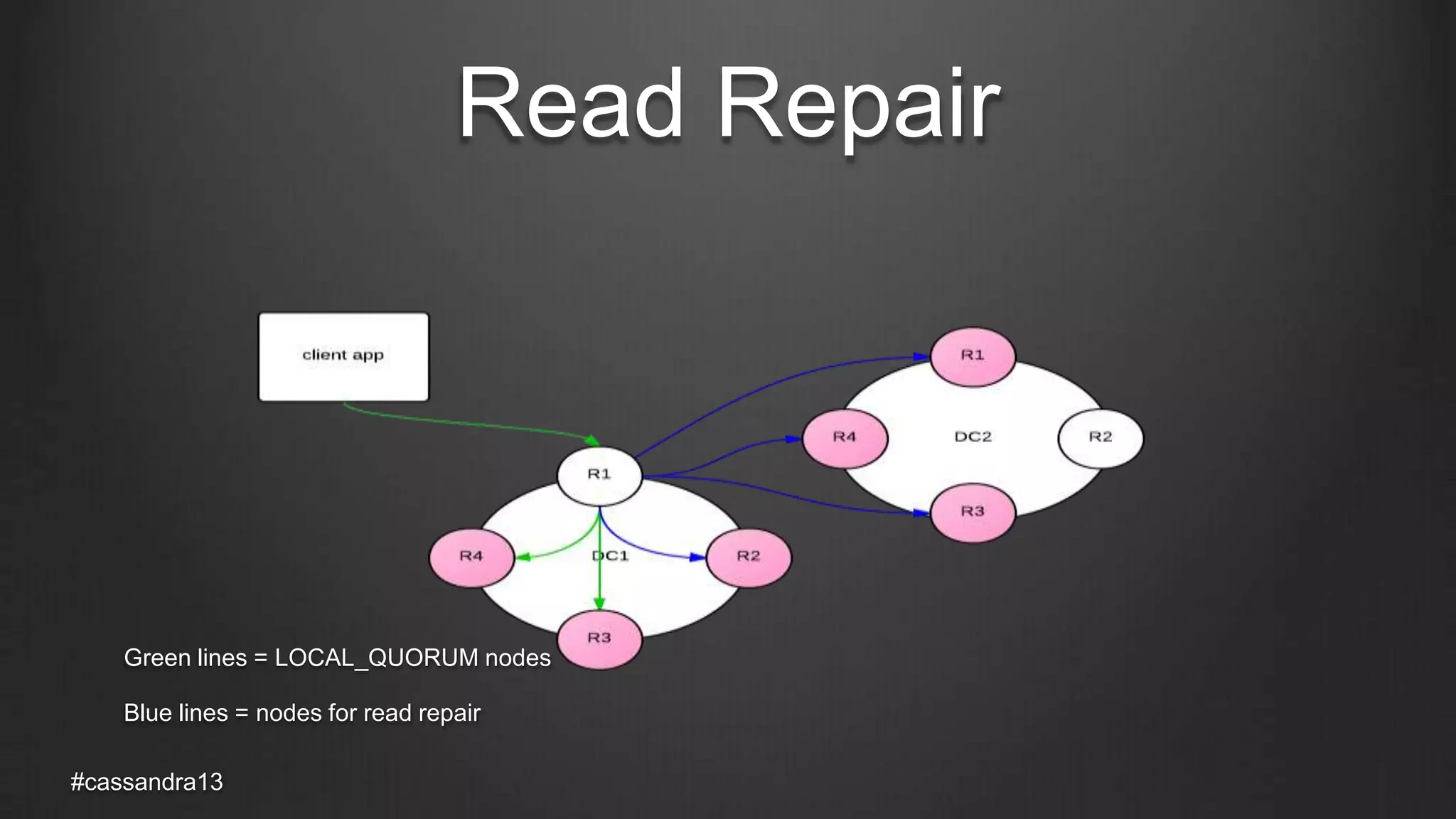






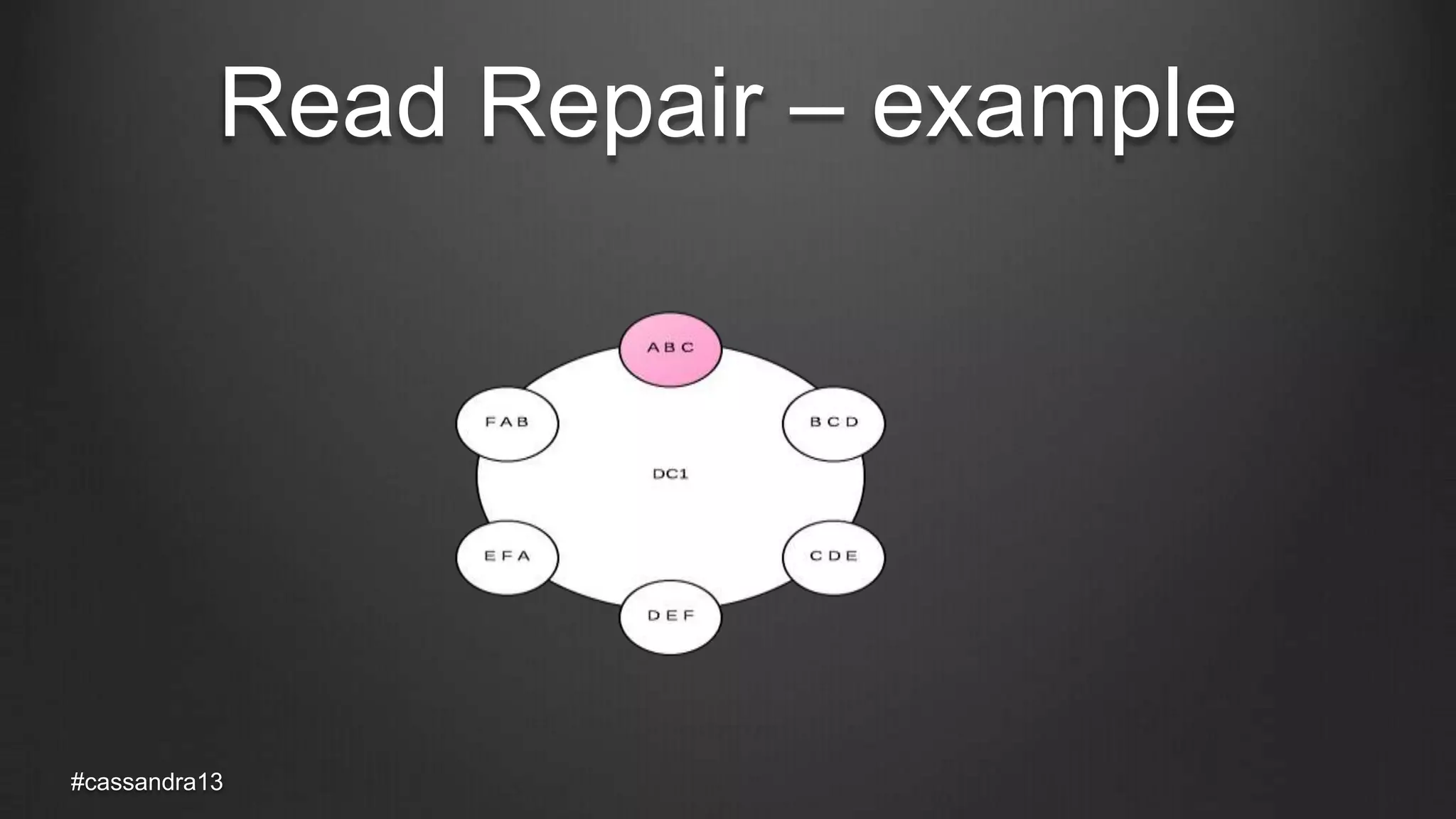
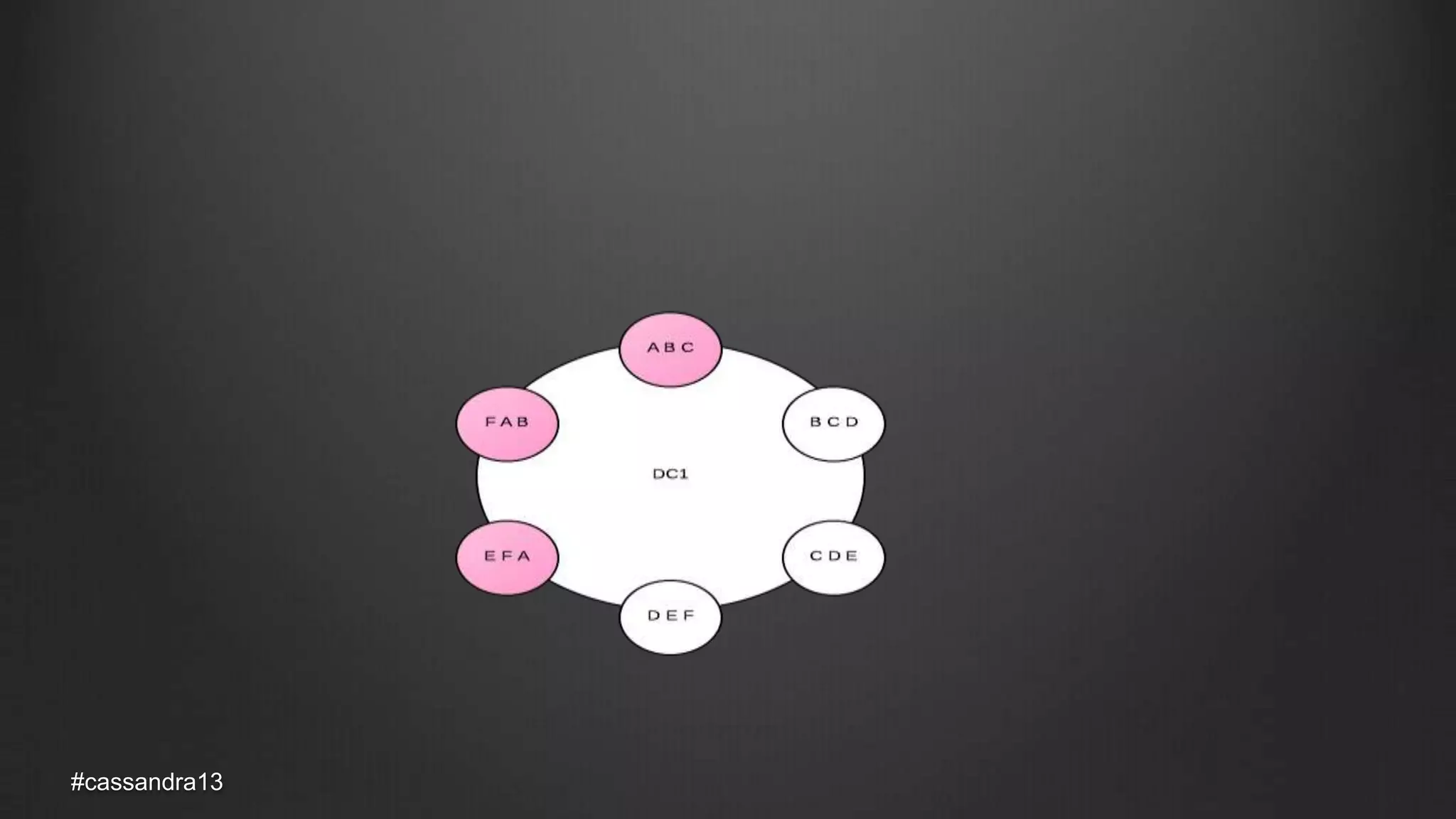
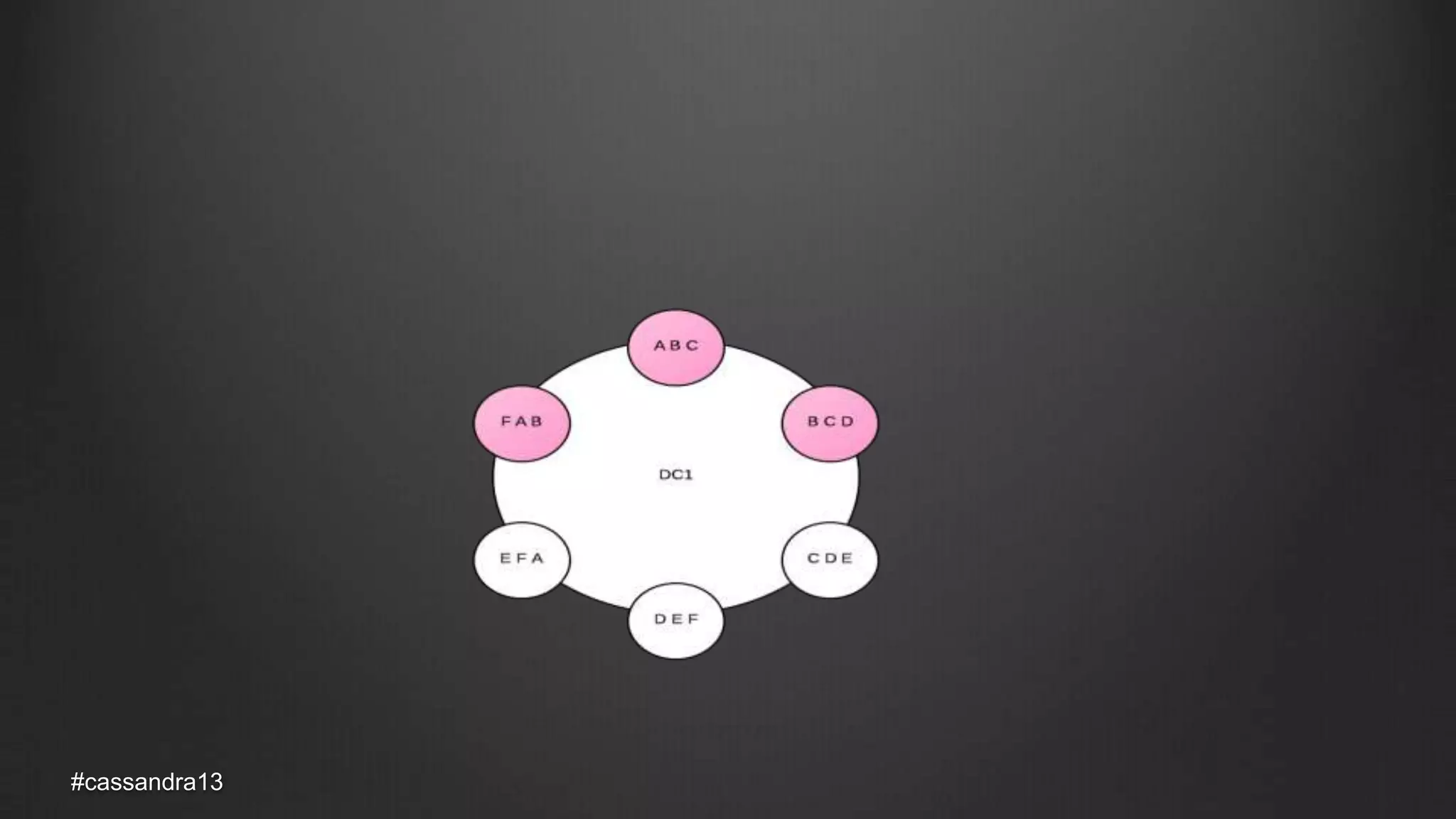
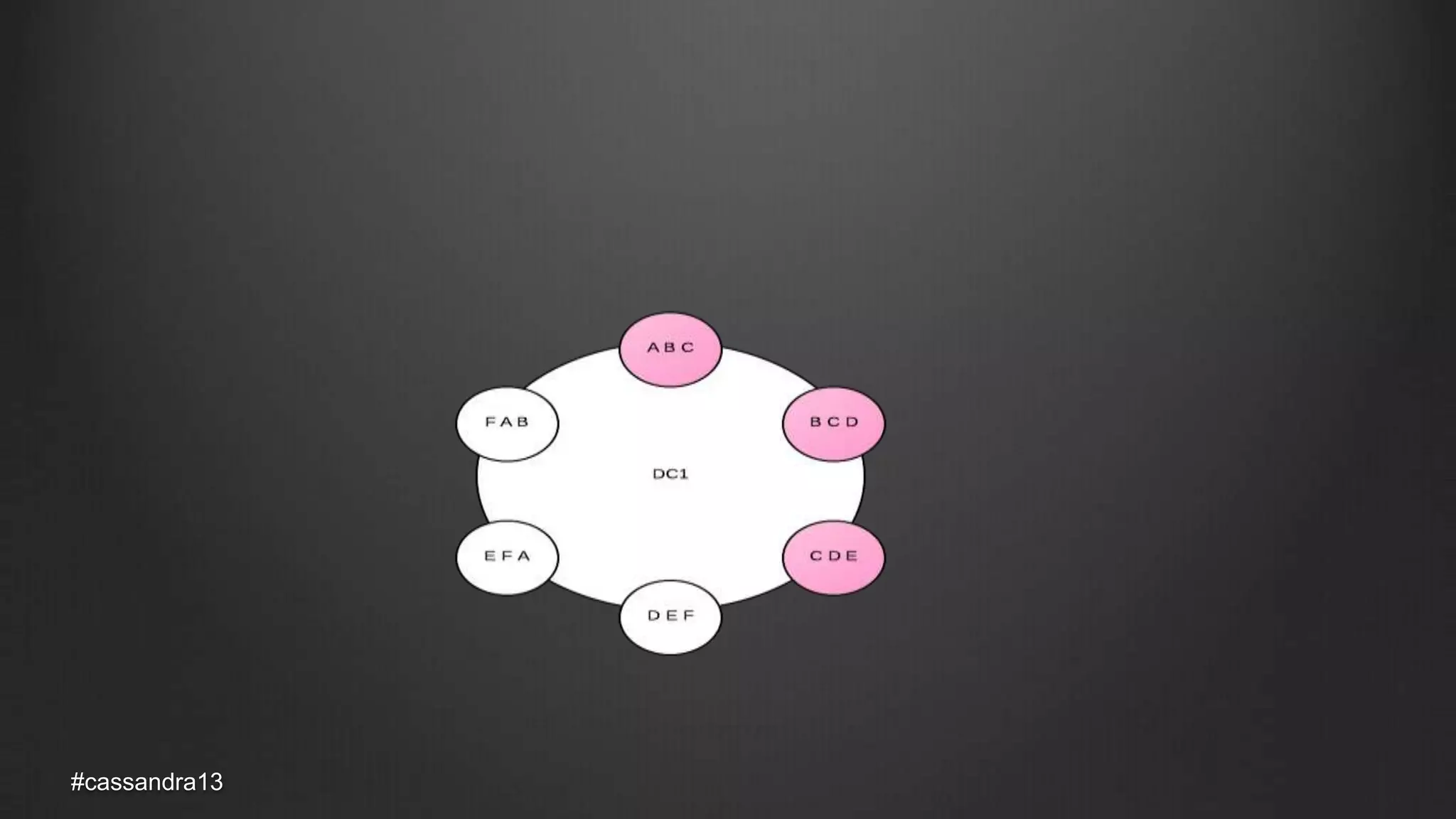
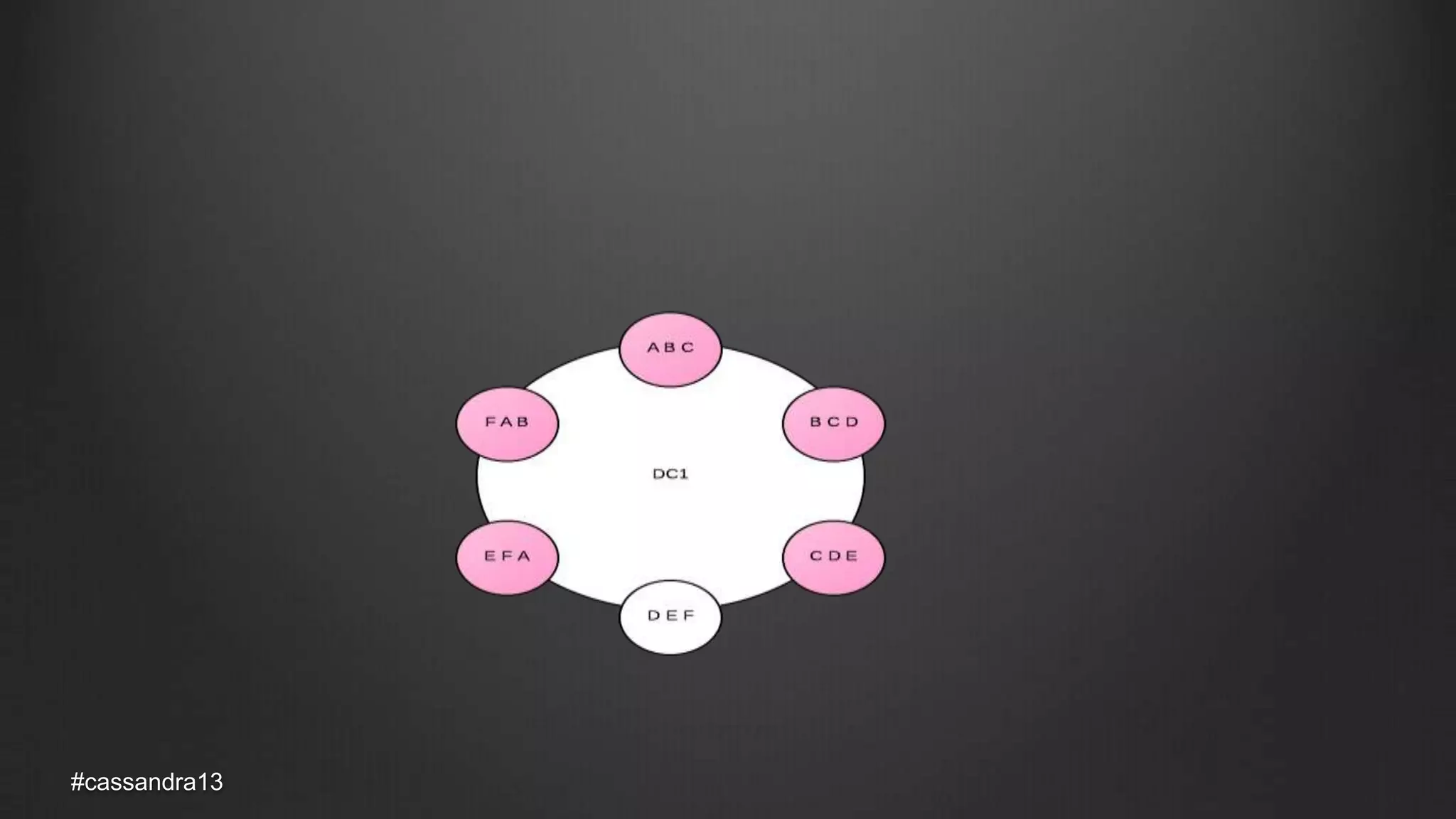



The document discusses anti-entropy in Cassandra, emphasizing the challenges of maintaining consistent data state in distributed systems due to issues like node failures and network partitions. It outlines various methods for achieving consistency, including hinted handoff, atomic batches, and read repairs, while addressing the CAP theorem's implications. The importance of regular node repairs and the need for tunable consistency levels during read and write operations are also highlighted.







































![UiPath Automation Suite Installation (Hands-On) [2/3]](https://cdn.slidesharecdn.com/ss_thumbnails/automationsuitecommunitysession2-251015095633-a6d862f1-thumbnail.jpg?width=600ounds&width=560&fit=bounds)







