2
Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of Data Mining
What Kind of Data Can Be Mined?
What Kinds of Patterns Can Be Mined?
What Technology Are Used?
What Kind of Applications Are Targeted?
Major Issues in Data Mining
A Brief History of Data Mining and Data Mining Society
Summary
4
Why Data Mining?
The Explosive Growth of Data: from terabytes to petabytes
Data collection and data availability
Automated data collection tools, database systems, Web,
computerized society
Major sources of abundant data
Business: Web, e-commerce, transactions, stocks, …
Science: Remote sensing, The medical and health science
(patient monitoring, and medical imaging), scientific simulation
Society and everyone: news, digital cameras, YouTube
Powerful and versatile tools are badly needed to automatically
uncover valuable information from the tremendous amounts of data
and to transform such data into organized Knowledge.
5.
5
Why Data Mining?
Search Engines: Some patterns found in user search queries can
disclose invaluable knowledge that cannot be obtained by reading
individual data items alone. For example, Google’s Flu Trends uses
specific search terms as indicators of flu activity
Business: large stores, such as Wal-Mart, handle hundreds of
millions of transactions per week at thousands of branches around
the world.
Wal-Mart allows suppliers to access data on their products and
perform analyses using data mining software. This allows
suppliers to identify customer buying patterns at different stores,
control inventory, product placement, and identify new
merchandizing opportunities
6.
6
Evolution of Sciences
Before 1600, empirical science
1600-1950s, theoretical science
Each discipline has grown a theoretical component. Theoretical models often
motivate experiments and generalize our understanding.
1950s-1990s, computational science
Over the last 50 years, most disciplines have grown a third, computational
branch (e.g. empirical, theoretical, and computational ecology, or physics, or
linguistics.)
Computational Science traditionally meant simulation. It grew out of our
inability to find closed-form solutions for complex mathematical models.
1990-now, data science
The flood of data from new scientific instruments and simulations
The ability to economically store and manage petabytes of data online
The Internet and computing Grid that makes all these archives universally
accessible
Scientific info. management, acquisition, organization, query, and visualization
tasks scale almost linearly with data volumes.
7.
7
Evolution of DatabaseTechnology
1960s:
Data collection, database creation, IMS and network DBMS
1970s:
Relational data model, relational DBMS implementation
1980s:
RDBMS, advanced data models (extended-relational, OO, deductive, etc.)
Application-oriented DBMS (spatial, scientific, engineering, etc.)
1990s:
Data mining, data warehousing, multimedia databases, and Web databases
2000s
Stream data management and mining
Data mining and its applications
Web technology (XML, data integration) and global information systems
8.
8
Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of Data Mining
What Kind of Data Can Be Mined?
What Kinds of Patterns Can Be Mined?
What Technology Are Used?
What Kind of Applications Are Targeted?
Major Issues in Data Mining
A Brief History of Data Mining and Data Mining Society
Summary
9.
9
What Is DataMining?
Data mining is the process of discovering interesting patterns
and knowledge from large amounts of data.
Extraction of interesting (non-trivial, previously unknown and
potentially useful) patterns or knowledge from huge amount of
data.
Data mining (knowledge discovery from data)
Many people treat data mining as a synonym for knowledge
discovery from data, or KDD, while others view data mining as
merely an essential step in the process of knowledge discovery
Data mining: a misnomer?
Alternative names
Knowledge discovery (mining) in databases (KDD), knowledge
extraction, data/pattern analysis, data archeology, data
dredging, information harvesting, business intelligence, etc.
10.
10
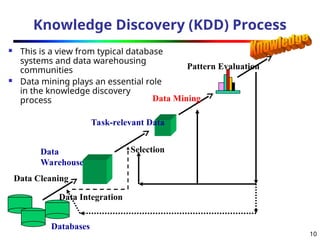
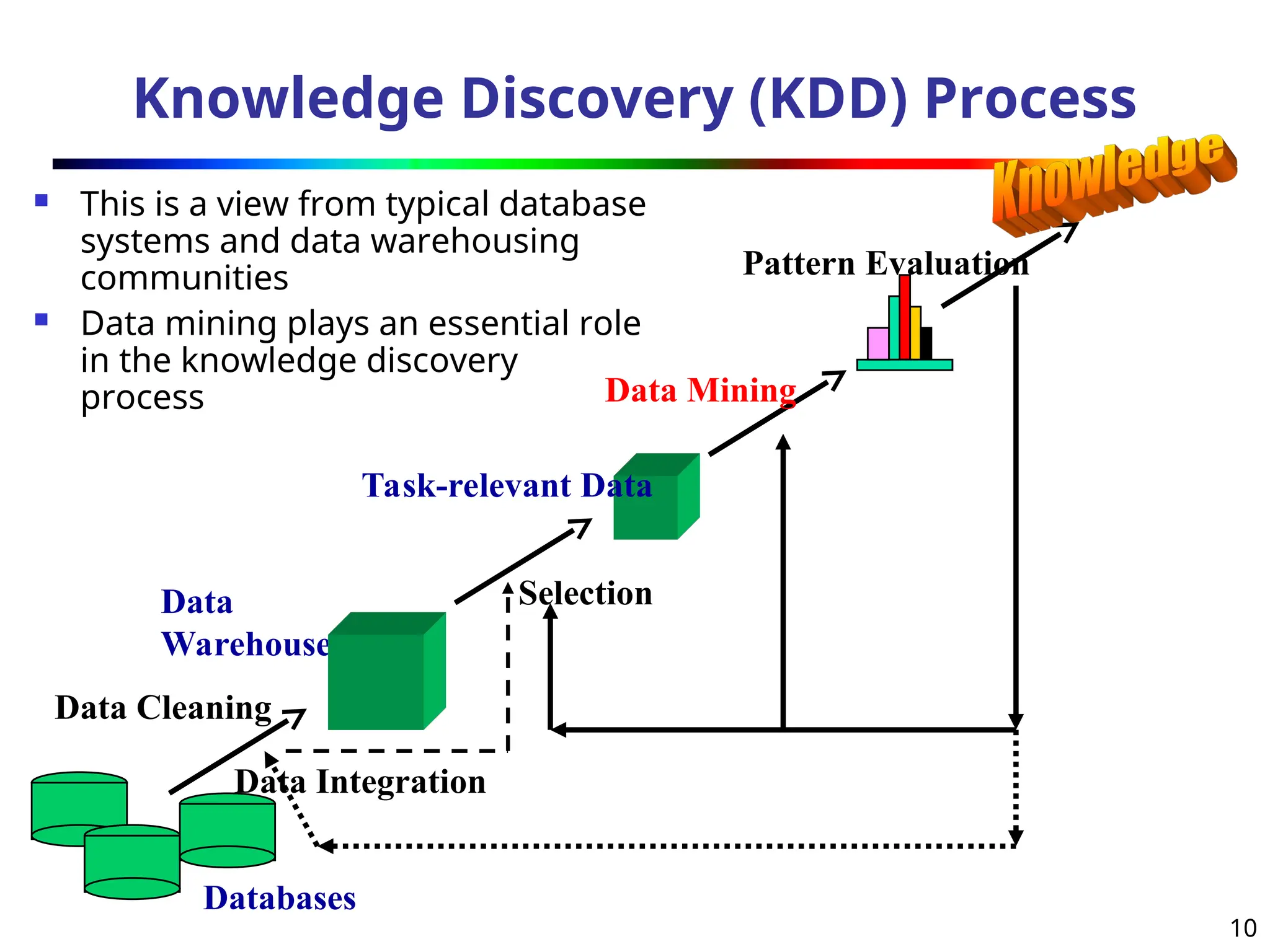
Knowledge Discovery (KDD)Process
This is a view from typical database
systems and data warehousing
communities
Data mining plays an essential role
in the knowledge discovery
process
Data Cleaning
Data Integration
Databases
Data
Warehouse
Task-relevant Data
Selection
Data Mining
Pattern Evaluation
11.
11
Example: A WebMining Framework
Web mining usually involves
Data cleaning
Data integration from multiple sources
Warehousing the data
Data selection for data mining
Data mining
Presentation of the mining results
Patterns and knowledge to be used or stored into
knowledge-base.
12.
12
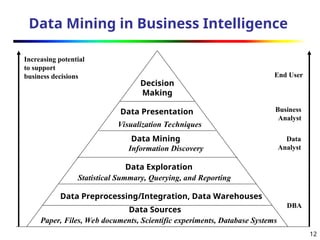
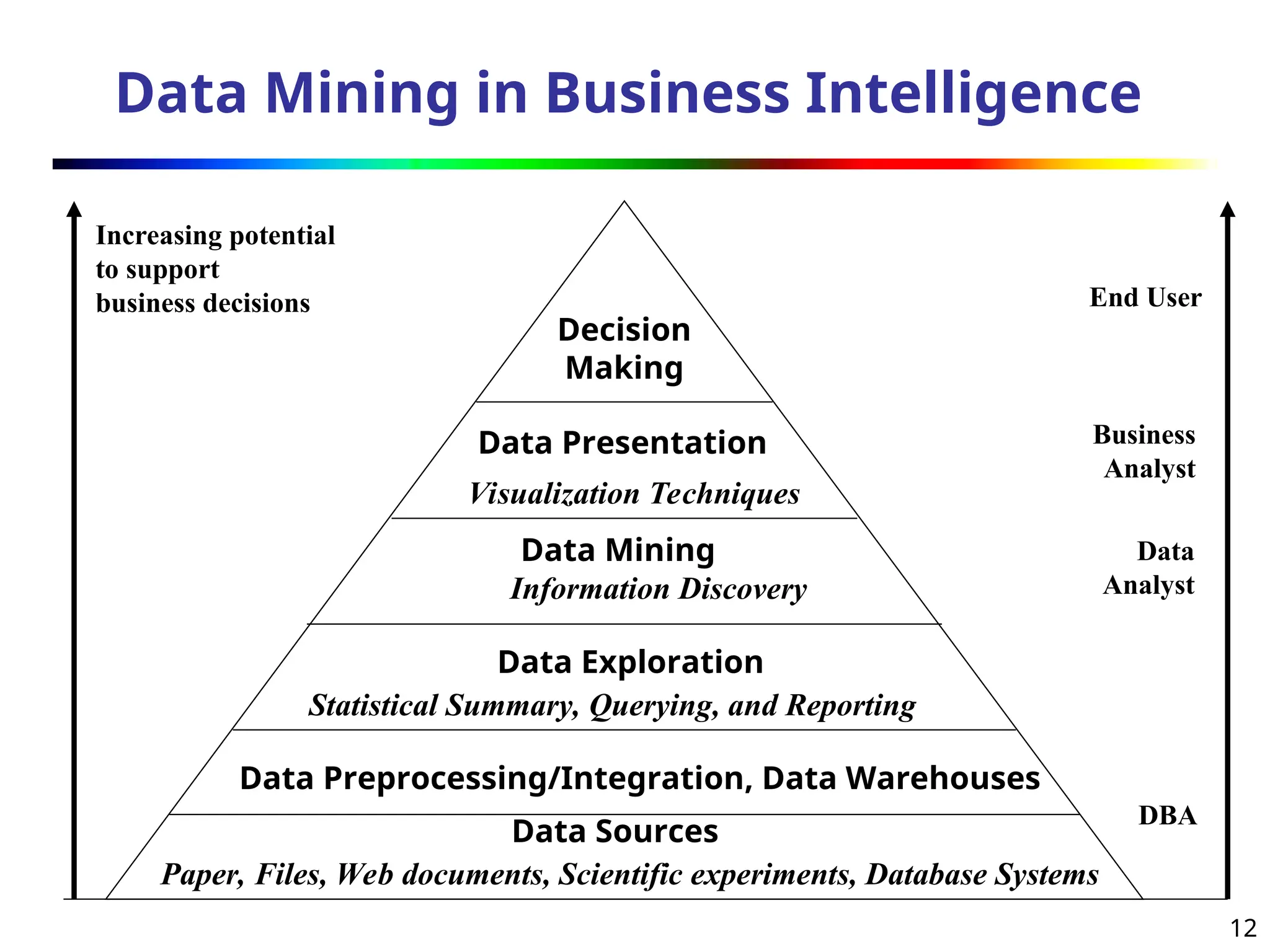
Data Mining inBusiness Intelligence
Increasing potential
to support
business decisions End User
Business
Analyst
Data
Analyst
DBA
Decision
Making
Data Presentation
Visualization Techniques
Data Mining
Information Discovery
Data Exploration
Statistical Summary, Querying, and Reporting
Data Preprocessing/Integration, Data Warehouses
Data Sources
Paper, Files, Web documents, Scientific experiments, Database Systems
13.
13
Example: Mining vs.Data Exploration
Business intelligence view
Warehouse, data cube, reporting but not much
mining
Business objects vs. data mining tools
Supply chain example: tools
Data presentation
Exploration
14.
14
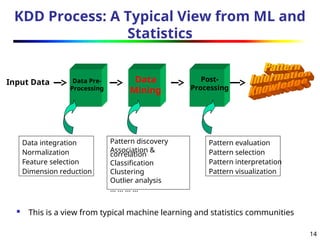
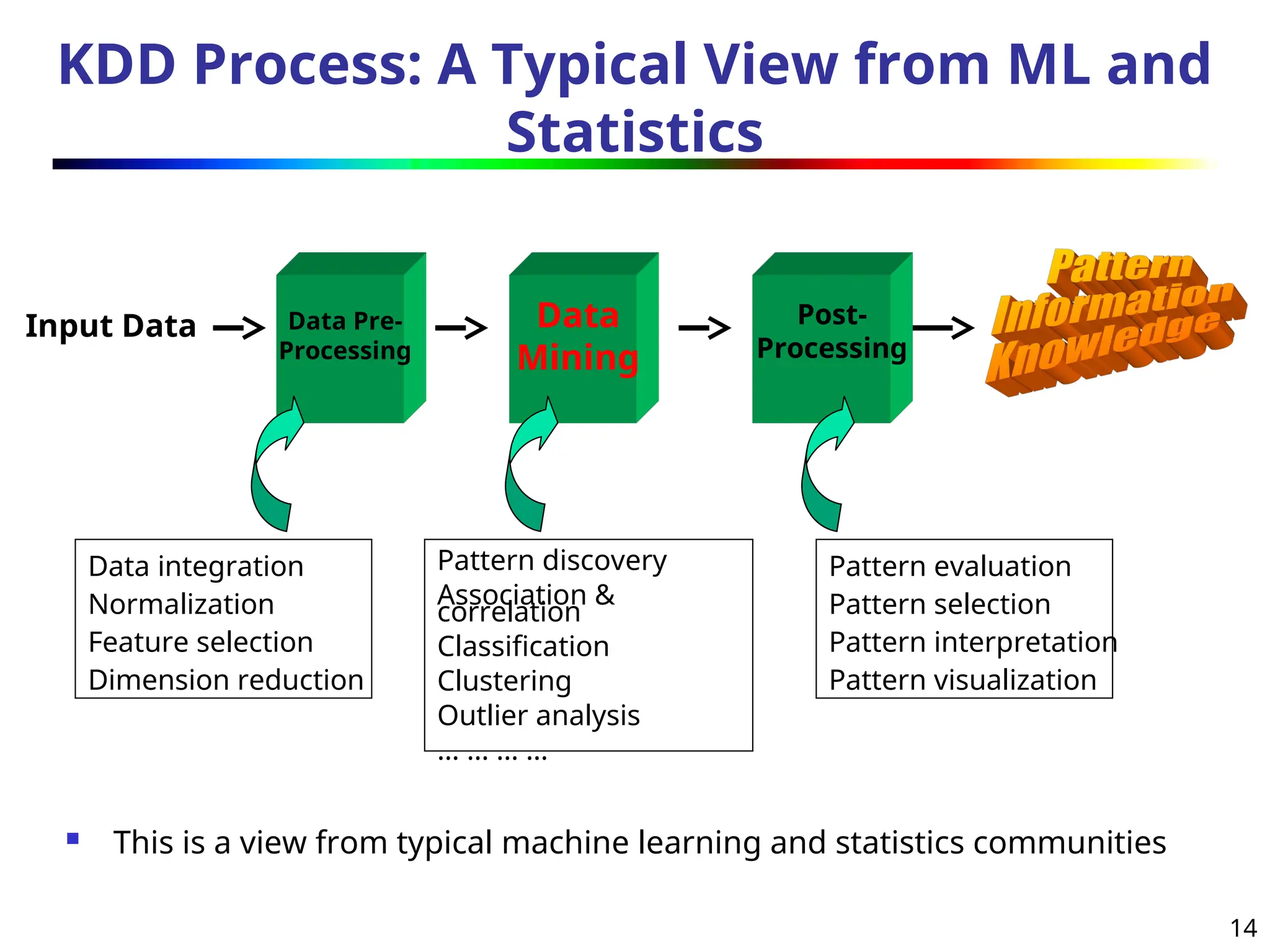
KDD Process: ATypical View from ML and
Statistics
Input Data Data
Mining
Data Pre-
Processing
Post-
Processing
This is a view from typical machine learning and statistics communities
Data integration
Normalization
Feature selection
Dimension reduction
Pattern discovery
Association &
correlation
Classification
Clustering
Outlier analysis
… … … …
Pattern evaluation
Pattern selection
Pattern interpretation
Pattern visualization
15.
15
Example: Medical DataMining
Health care & medical data mining – often
adopted such a view in statistics and machine
learning
Preprocessing of the data (including feature
extraction and dimension reduction)
Classification or/and clustering processes
Post-processing for presentation
16.
16
Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of Data Mining
What Kind of Data Can Be Mined?
What Kinds of Patterns Can Be Mined?
What Technology Are Used?
What Kind of Applications Are Targeted?
Major Issues in Data Mining
A Brief History of Data Mining and Data Mining Society
Summary
17.
17
Multi-Dimensional View ofData Mining
Data to be mined
Database data (extended-relational, object-oriented,
heterogeneous, legacy), data warehouse, transactional data,
stream, spatiotemporal, time-series, sequence, text and web,
multi-media, graphs & social and information networks
Knowledge to be mined (or: Data mining functions)
Characterization, discrimination, association, classification,
clustering, trend/deviation, outlier analysis, etc.
Descriptive vs. predictive data mining
Multiple/integrated functions and mining at multiple levels
Techniques utilized
Data-intensive, data warehouse (OLAP), machine learning,
statistics, pattern recognition, visualization, high-performance, etc.
Applications adapted
Retail, telecommunication, banking, fraud analysis, bio-data
mining, stock market analysis, text mining, Web mining, etc.
18.
18
Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of Data Mining
What Kind of Data Can Be Mined?
What Kinds of Patterns Can Be Mined?
What Technology Are Used?
What Kind of Applications Are Targeted?
Major Issues in Data Mining
A Brief History of Data Mining and Data Mining Society
Summary
19.
19
Data Mining: OnWhat Kinds of Data?
Database-oriented data sets and applications
Relational database, data warehouse, transactional database
Advanced data sets and advanced applications
Data streams and sensor data
Time-series data, temporal data, sequence data (incl. bio-sequences)
Structure data, graphs, social networks and multi-linked data
Object-relational databases
Heterogeneous databases and legacy databases
Spatial data and spatiotemporal data
Multimedia database
Text databases
The World-Wide Web
20.
20
Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of Data Mining
What Kind of Data Can Be Mined?
What Kinds of Patterns Can Be Mined?
What Technology Are Used?
What Kind of Applications Are Targeted?
Major Issues in Data Mining
A Brief History of Data Mining and Data Mining Society
Summary
21.
21
Data Mining Function:(1) Generalization
Information integration and data warehouse
construction
Data cleaning, transformation, integration, and
multidimensional data model
Data cube technology
Scalable methods for computing (i.e., materializing)
multidimensional aggregates
OLAP (online analytical processing)
Multidimensional concept description: Characterization
and discrimination
Generalize, summarize, and contrast data
characteristics, e.g., dry vs. wet region
22.
22
Data Mining Function:(2) Association and
Correlation Analysis
Frequent patterns (or frequent itemsets)
What items are frequently purchased together in your
Walmart?
Association, correlation vs. causality
A typical association rule
Diaper Beer [0.5%, 75%] (support, confidence)
Are strongly associated items also strongly correlated?
How to mine such patterns and rules efficiently in large
datasets?
How to use such patterns for classification, clustering,
and other applications?
23.
23
Data Mining Function:(3) Classification
Classification and label prediction
Construct models (functions) based on some training examples
Describe and distinguish classes or concepts for future
prediction
E.g., classify countries based on (climate), or classify cars
based on (gas mileage)
Predict some unknown class labels
Typical methods
Decision trees, naïve Bayesian classification, support vector
machines, neural networks, rule-based classification, pattern-
based classification, logistic regression, …
Typical applications:
Credit card fraud detection, direct marketing, classifying stars,
diseases, web-pages, …
24.
24
Data Mining Function:(4) Cluster Analysis
Unsupervised learning (i.e., Class label is unknown)
Group data to form new categories (i.e., clusters), e.g.,
cluster houses to find distribution patterns
Principle: Maximizing intra-class similarity & minimizing
interclass similarity
Many methods and applications
25.
25
Data Mining Function:(5) Outlier Analysis
Outlier analysis
Outlier: A data object that does not comply with the general
behavior of the data
Noise or exception? ― One person’s garbage could be another
person’s treasure
Methods: by product of clustering or regression analysis, …
Useful in fraud detection, rare events analysis
26.
26
Time and Ordering:Sequential Pattern,
Trend and Evolution Analysis
Sequence, trend and evolution analysis
Trend, time-series, and deviation analysis: e.g.,
regression and value prediction
Sequential pattern mining
e.g., first buy digital camera, then buy large SD
memory cards
Periodicity analysis
Motifs and biological sequence analysis
Approximate and consecutive motifs
Similarity-based analysis
Mining data streams
Ordered, time-varying, potentially infinite, data streams
27.
27
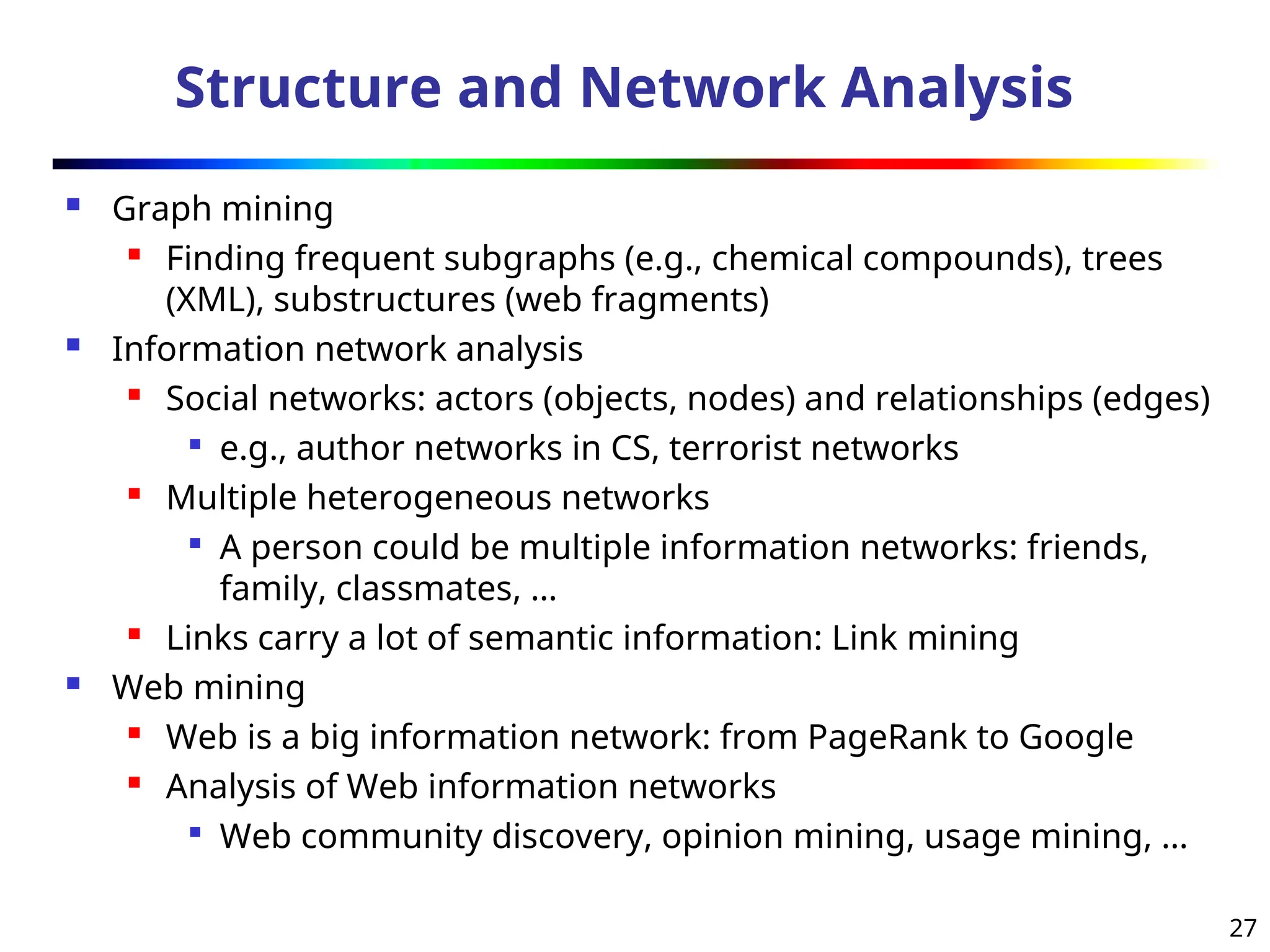
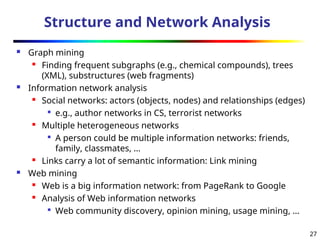
Structure and NetworkAnalysis
Graph mining
Finding frequent subgraphs (e.g., chemical compounds), trees
(XML), substructures (web fragments)
Information network analysis
Social networks: actors (objects, nodes) and relationships (edges)
e.g., author networks in CS, terrorist networks
Multiple heterogeneous networks
A person could be multiple information networks: friends,
family, classmates, …
Links carry a lot of semantic information: Link mining
Web mining
Web is a big information network: from PageRank to Google
Analysis of Web information networks
Web community discovery, opinion mining, usage mining, …
28.
28
Evaluation of Knowledge
Are all mined knowledge interesting?
One can mine tremendous amount of “patterns” and knowledge
Some may fit only certain dimension space (time, location, …)
Some may not be representative, may be transient, …
Evaluation of mined knowledge → directly mine only
interesting knowledge?
Descriptive vs. predictive
Coverage
Typicality vs. novelty
Accuracy
Timeliness
…
29.
29
Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of Data Mining
What Kind of Data Can Be Mined?
What Kinds of Patterns Can Be Mined?
What Technology Are Used?
What Kind of Applications Are Targeted?
Major Issues in Data Mining
A Brief History of Data Mining and Data Mining Society
Summary
30.
30
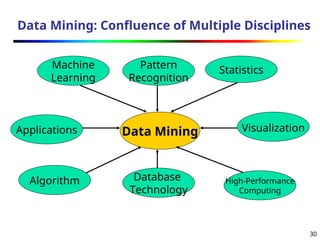
Data Mining: Confluenceof Multiple Disciplines
Data Mining
Machine
Learning
Statistics
Applications
Algorithm
Pattern
Recognition
High-Performance
Computing
Visualization
Database
Technology
31.
31
Why Confluence ofMultiple Disciplines?
Tremendous amount of data
Algorithms must be highly scalable to handle such as tera-bytes
of data
High-dimensionality of data
Micro-array may have tens of thousands of dimensions
High complexity of data
Data streams and sensor data
Time-series data, temporal data, sequence data
Structure data, graphs, social networks and multi-linked data
Heterogeneous databases and legacy databases
Spatial, spatiotemporal, multimedia, text and Web data
Software programs, scientific simulations
New and sophisticated applications
32.
32
Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of Data Mining
What Kind of Data Can Be Mined?
What Kinds of Patterns Can Be Mined?
What Technology Are Used?
What Kind of Applications Are Targeted?
Major Issues in Data Mining
A Brief History of Data Mining and Data Mining Society
Summary
33.
33
Applications of DataMining
Web page analysis: from web page classification, clustering to
PageRank & HITS algorithms
Collaborative analysis & recommender systems
Basket data analysis to targeted marketing
Biological and medical data analysis: classification, cluster analysis
(microarray data analysis), biological sequence analysis,
biological network analysis
Data mining and software engineering (e.g., IEEE Computer, Aug.
2009 issue)
From major dedicated data mining systems/tools (e.g., SAS, MS
SQL-Server Analysis Manager, Oracle Data Mining Tools) to
invisible data mining
34.
34
Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of Data Mining
What Kind of Data Can Be Mined?
What Kinds of Patterns Can Be Mined?
What Technology Are Used?
What Kind of Applications Are Targeted?
Major Issues in Data Mining
A Brief History of Data Mining and Data Mining Society
Summary
35.
35
Major Issues inData Mining (1)
Mining Methodology
Mining various and new kinds of knowledge
Mining knowledge in multi-dimensional space
Data mining: An interdisciplinary effort
Boosting the power of discovery in a networked environment
Handling noise, uncertainty, and incompleteness of data
Pattern evaluation and pattern- or constraint-guided mining
User Interaction
Interactive mining
Incorporation of background knowledge
Presentation and visualization of data mining results
36.
36
Major Issues inData Mining (2)
Efficiency and Scalability
Efficiency and scalability of data mining algorithms
Parallel, distributed, stream, and incremental mining methods
Diversity of data types
Handling complex types of data
Mining dynamic, networked, and global data repositories
Data mining and society
Social impacts of data mining
Privacy-preserving data mining
Invisible data mining
37.
37
Chapter 1. Introduction
Why Data Mining?
What Is Data Mining?
A Multi-Dimensional View of Data Mining
What Kind of Data Can Be Mined?
What Kinds of Patterns Can Be Mined?
What Technology Are Used?
What Kind of Applications Are Targeted?
Major Issues in Data Mining
A Brief History of Data Mining and Data Mining Society
Summary
38.
38
Summary
Data mining:Discovering interesting patterns and knowledge from
massive amount of data
A natural evolution of database technology, in great demand, with
wide applications
A KDD process includes data cleaning, data integration, data
selection, transformation, data mining, pattern evaluation, and
knowledge presentation
Mining can be performed in a variety of data
Data mining functionalities: characterization, discrimination,
association, classification, clustering, outlier and trend analysis, etc.
Data mining technologies and applications
Major issues in data mining
Editor's Notes
#7 Two slides should be added after this one
1. Evolution of machine learning
2. Evolution of statistics methods
#21 I BELIEVE WE MAY NEED TO DO IT IN MORE IN-DEPTH INTRODUCTION, USING SOME EXAMPLES. So it will take one slide for one function, i.e., one chapter we want to cover. Do we need to cover chapter 2: preprocessing and 3. Statistical methods?
#27 This chapter will not be in the new version, will it?
BUT SHOULD WESTILL INTRODCE THEM SO THAT THEY WILL GET AN OVERALL PICTURE?
#31 Add a definition/description of “traditional data analysis”.


















![22
Data Mining Function: (2) Association and
Correlation Analysis
Frequent patterns (or frequent itemsets)
What items are frequently purchased together in your
Walmart?
Association, correlation vs. causality
A typical association rule
Diaper Beer [0.5%, 75%] (support, confidence)
Are strongly associated items also strongly correlated?
How to mine such patterns and rules efficiently in large
datasets?
How to use such patterns for classification, clustering,
and other applications?](https://image.slidesharecdn.com/01intro1-250305121629-5955a914/85/01Intro-1-ppt-Introduction-In-computer-science-22-320.jpg)
































![22
Data Mining Function: (2) Association and
Correlation Analysis
Frequent patterns (or frequent itemsets)
What items are frequently purchased together in your
Walmart?
Association, correlation vs. causality
A typical association rule
Diaper Beer [0.5%, 75%] (support, confidence)
Are strongly associated items also strongly correlated?
How to mine such patterns and rules efficiently in large
datasets?
How to use such patterns for classification, clustering,
and other applications?](https://image.slidesharecdn.com/01intro1-250305121629-5955a914/75/01Intro-1-ppt-Introduction-In-computer-science-22-2048.jpg)