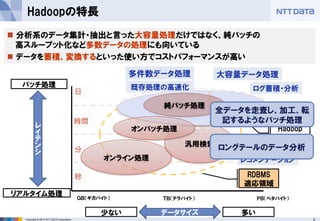
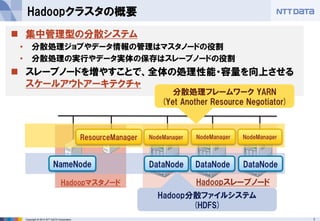
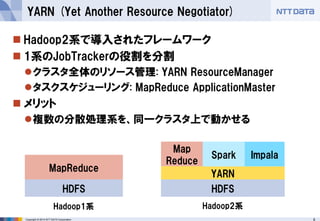
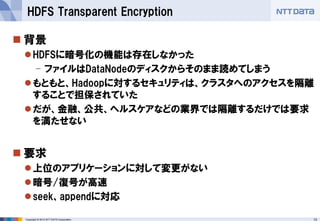
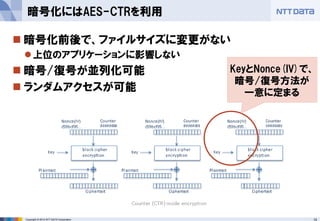
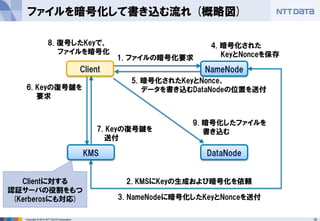
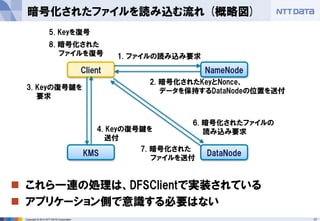
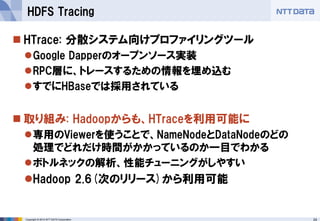
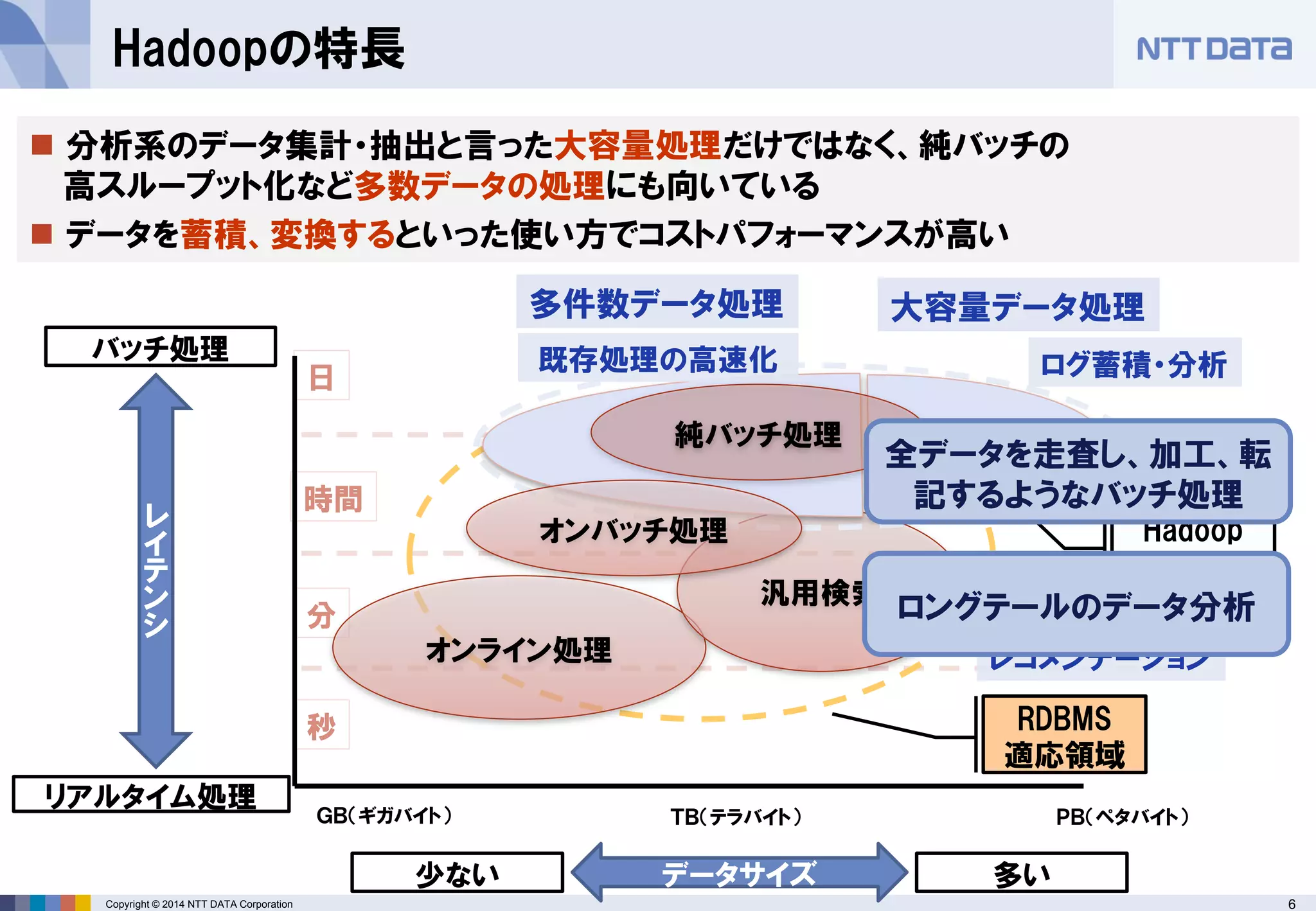
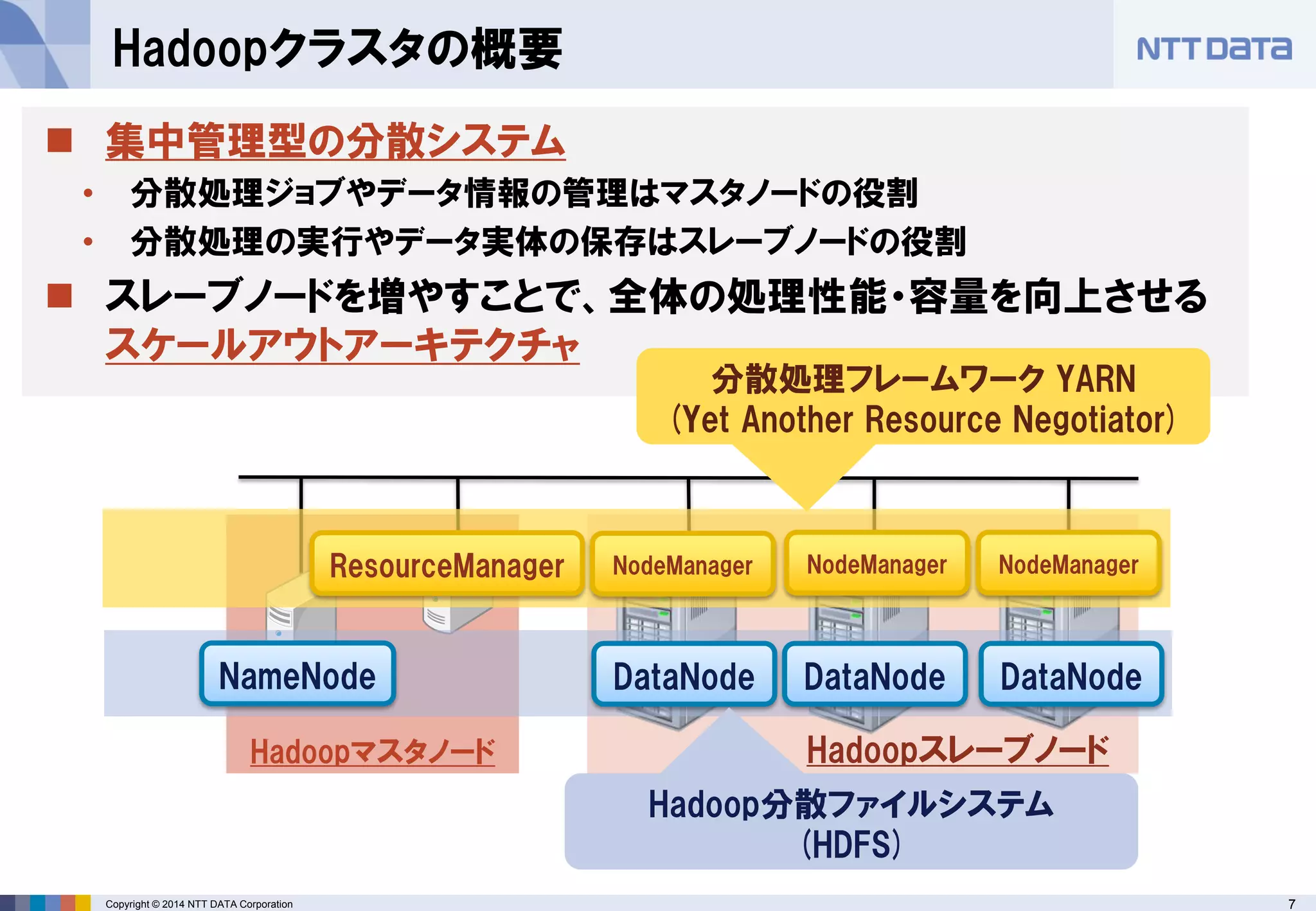
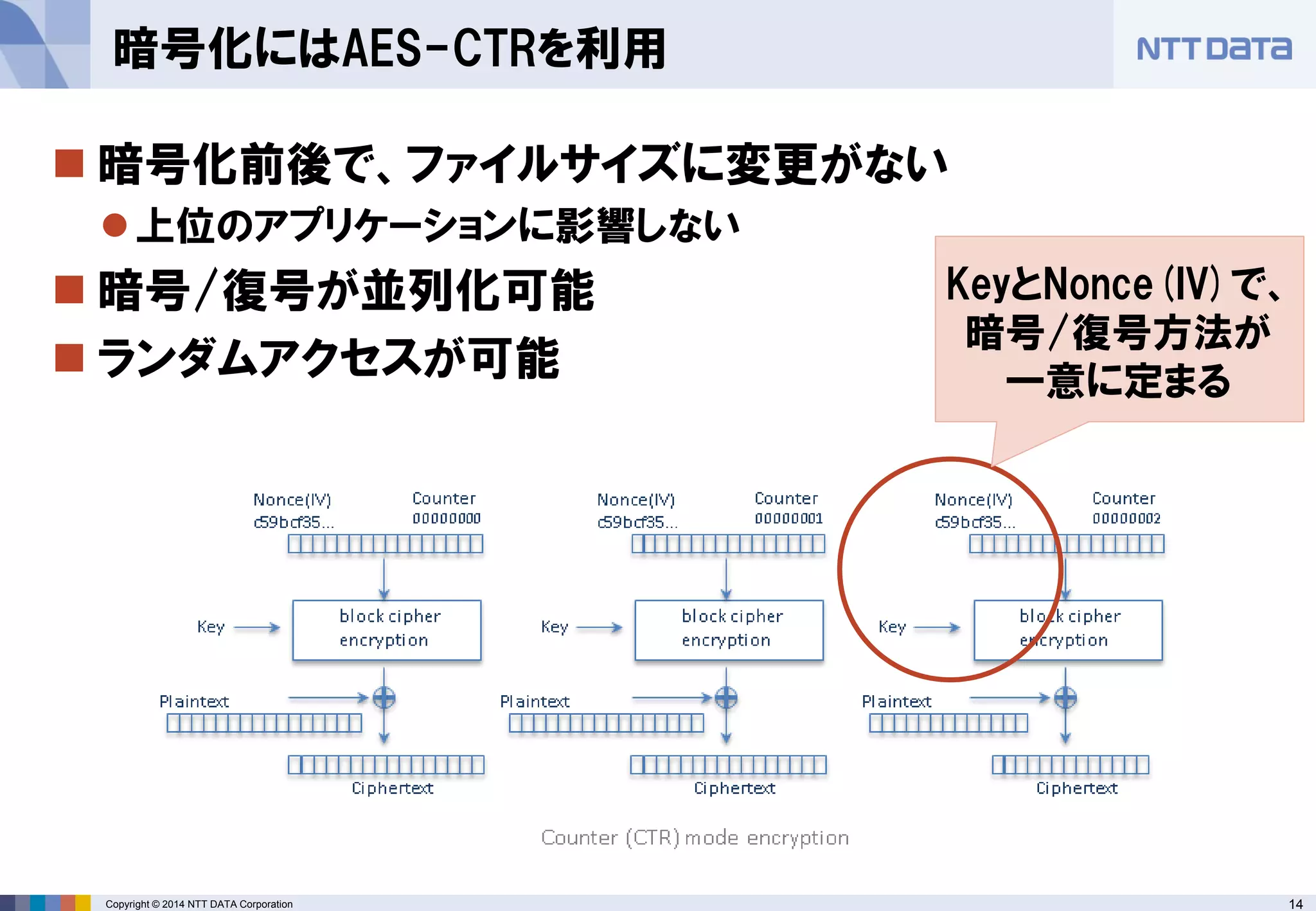
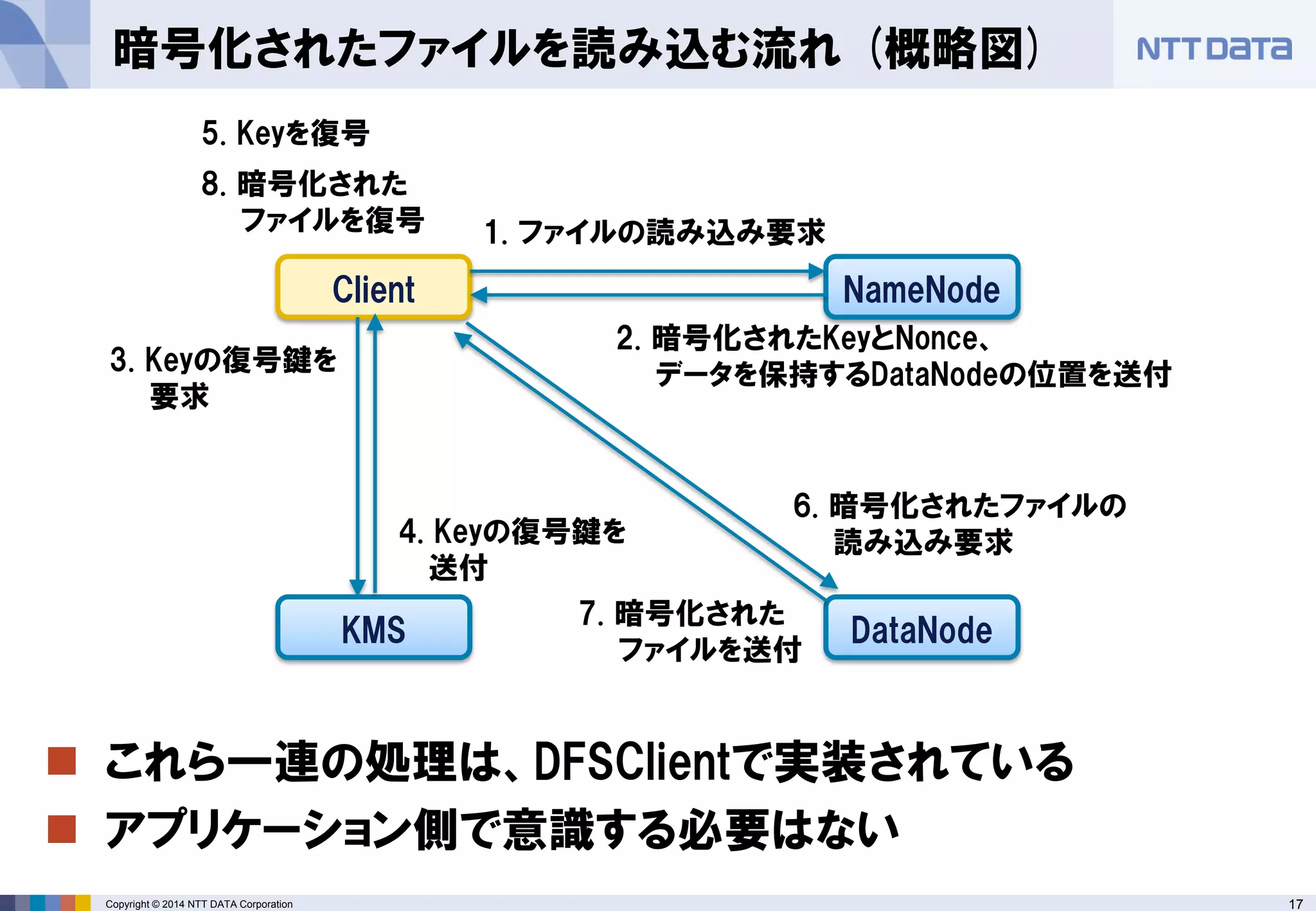
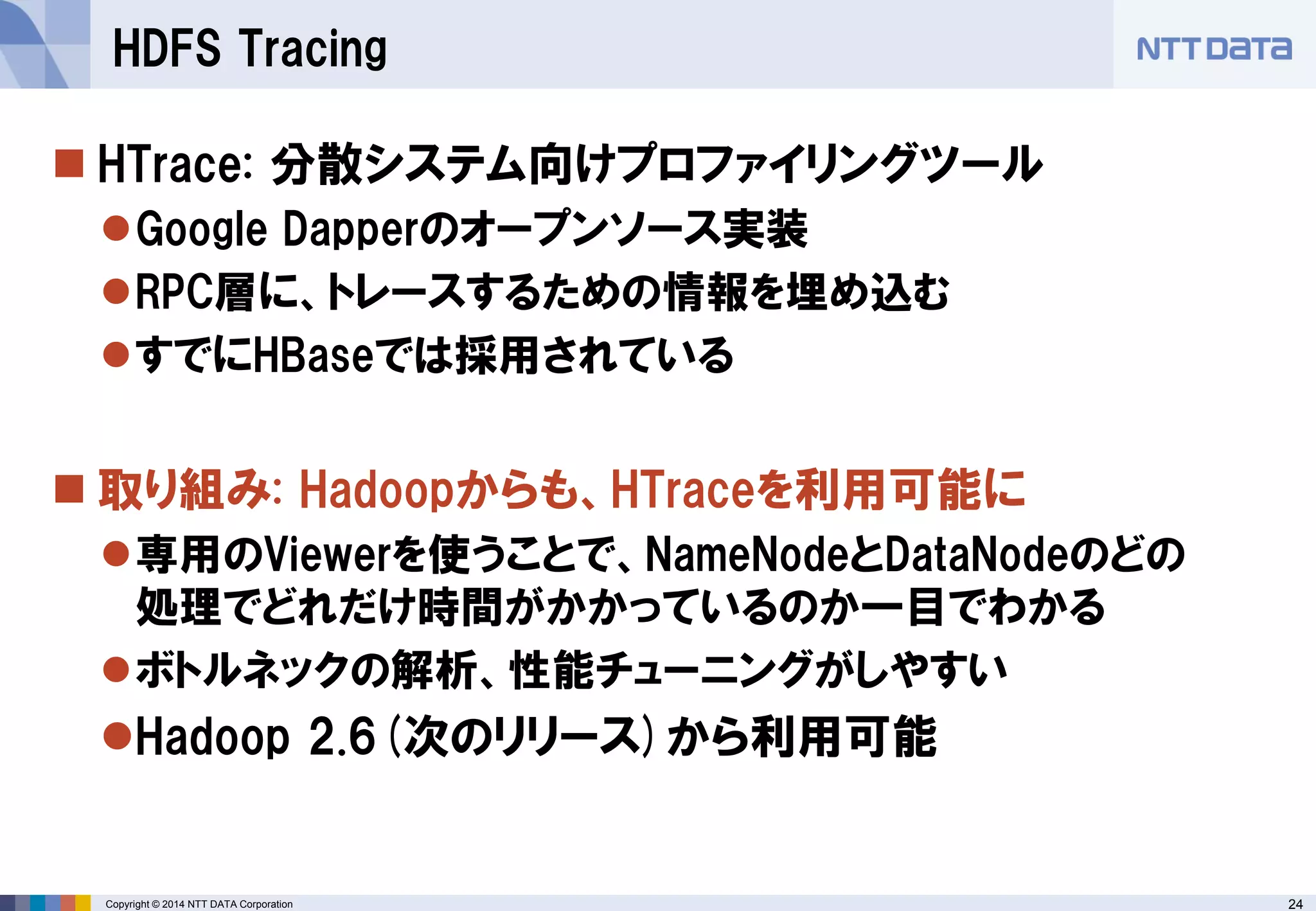
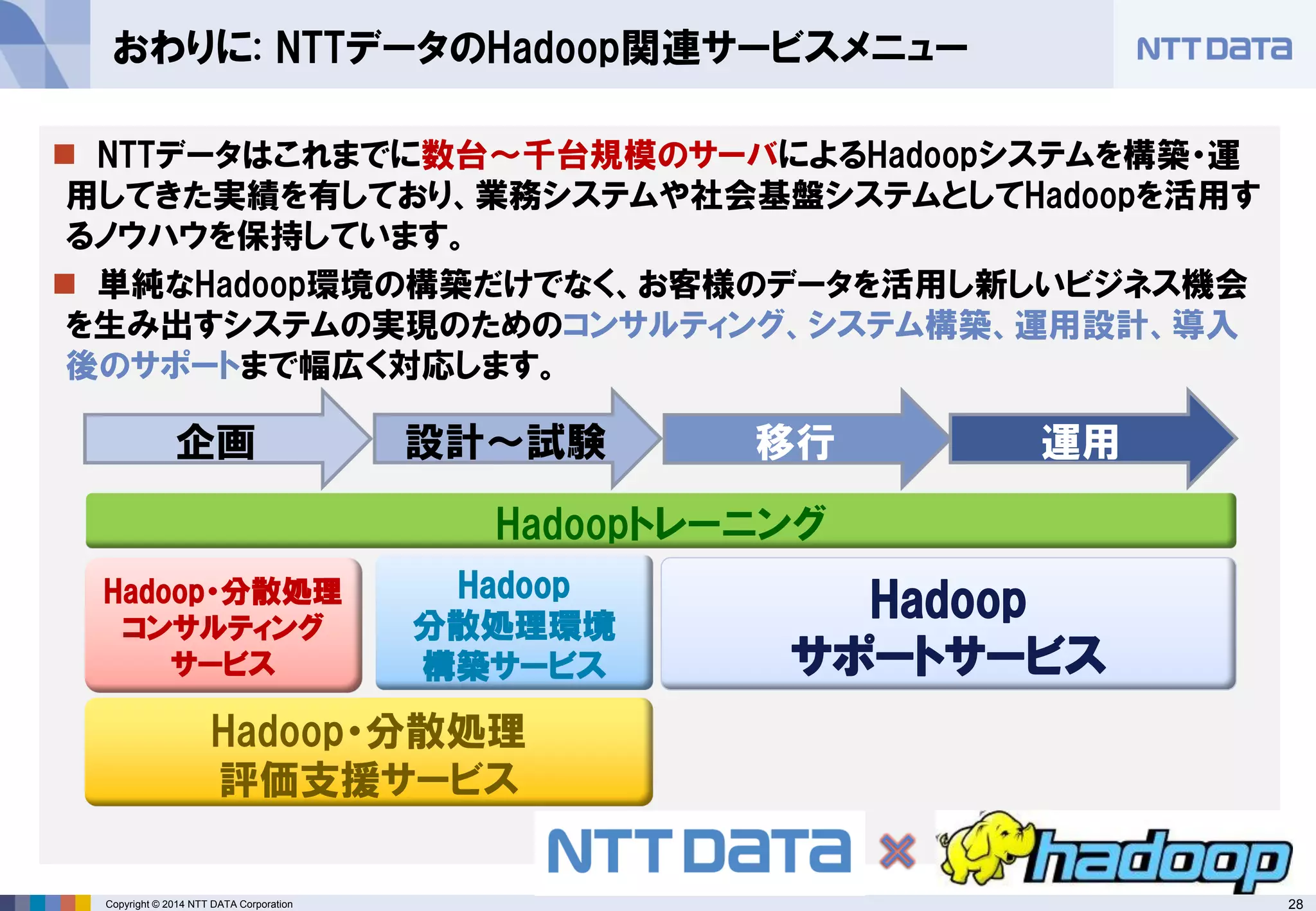
■オープンソースカンファレンス 2014 Tokyo/Fall 講演資料 (2014/10/18) 『分散処理基盤Apache Hadoopの現状と、NTTデータのHadoopに対する取り組み』 NTTデータ 基盤システム事業本部 方式システム技術事業部)鯵坂 明