KEMBAR78
Daftar
Login
Distributed data stores in Hadoop ecosystem | PDF
Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
NS
Uploaded by
NTT DATA OSS Professional Services
5,610 views
Distributed data stores in Hadoop ecosystem
2017年10月30日に開催されたNTTデータ テクノロジーカンファレンス2017での講演資料です。
Technology
◦
Read more
1
Save
Share
Embed
1
/ 52
2
/ 52
3
/ 52
4
/ 52
5
/ 52
6
/ 52
7
/ 52
8
/ 52
9
/ 52
10
/ 52
11
/ 52
12
/ 52
13
/ 52
14
/ 52
15
/ 52
16
/ 52
17
/ 52
18
/ 52
19
/ 52
20
/ 52
21
/ 52
22
/ 52
23
/ 52
24
/ 52
25
/ 52
26
/ 52
27
/ 52
28
/ 52
29
/ 52
30
/ 52
31
/ 52
32
/ 52
33
/ 52
34
/ 52
35
/ 52
36
/ 52
37
/ 52
38
/ 52
39
/ 52
40
/ 52
41
/ 52
42
/ 52
43
/ 52
44
/ 52
45
/ 52
46
/ 52
47
/ 52
48
/ 52
49
/ 52
50
/ 52
51
/ 52
52
/ 52
More Related Content
PDF
Hadoopエコシステムのデータストア振り返り
by
NTT DATA OSS Professional Services
PDF
HDFS basics from API perspective
by
NTT DATA OSS Professional Services
PDF
HDFS Router-based federation
by
NTT DATA OSS Professional Services
PDF
Apache Hadoop and YARN, current development status
by
NTT DATA OSS Professional Services
PDF
Apache Hadoopの新機能Ozoneの現状
by
NTT DATA OSS Professional Services
PDF
Apache Hadoopの未来 3系になって何が変わるのか?
by
NTT DATA OSS Professional Services
PDF
サポートメンバは見た! Hadoopバグワースト10 (adoop / Spark Conference Japan 2016 ライトニングトーク発表資料)
by
NTT DATA OSS Professional Services
PDF
PostgreSQL10を導入!大規模データ分析事例からみるDWHとしてのPostgreSQL活用のポイント
by
NTT DATA OSS Professional Services
Hadoopエコシステムのデータストア振り返り
by
NTT DATA OSS Professional Services
HDFS basics from API perspective
by
NTT DATA OSS Professional Services
HDFS Router-based federation
by
NTT DATA OSS Professional Services
Apache Hadoop and YARN, current development status
by
NTT DATA OSS Professional Services
Apache Hadoopの新機能Ozoneの現状
by
NTT DATA OSS Professional Services
Apache Hadoopの未来 3系になって何が変わるのか?
by
NTT DATA OSS Professional Services
サポートメンバは見た! Hadoopバグワースト10 (adoop / Spark Conference Japan 2016 ライトニングトーク発表資料)
by
NTT DATA OSS Professional Services
PostgreSQL10を導入!大規模データ分析事例からみるDWHとしてのPostgreSQL活用のポイント
by
NTT DATA OSS Professional Services
What's hot
PDF
SIerとオープンソースの美味しい関係 ~コミュニティの力を活かして世界を目指そう~
by
NTT DATA OSS Professional Services
PDF
分散処理基盤Apache Hadoopの現状と、NTTデータのHadoopに対する取り組み
by
NTT DATA OSS Professional Services
PDF
Hadoop 2.6の最新機能(Cloudera World Tokyo 2014 LT講演資料)
by
NTT DATA OSS Professional Services
PDF
HDFS新機能総まとめin 2015 (日本Hadoopユーザー会 ライトニングトーク@Cloudera World Tokyo 2015 講演資料)
by
NTT DATA OSS Professional Services
PDF
データインターフェースとしてのHadoop ~HDFSとクラウドストレージと私~ (NTTデータ テクノロジーカンファレンス 2019 講演資料、2019...
by
NTT DATA Technology & Innovation
PDF
Hadoop2.6の最新機能+
by
NTT DATA OSS Professional Services
PPTX
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発...
by
NTT DATA Technology & Innovation
PDF
20170303 java9 hadoop
by
NTT DATA OSS Professional Services
PDF
Hadoopエコシステムの最新動向とNTTデータの取り組み (OSC 2016 Tokyo/Spring 講演資料)
by
NTT DATA OSS Professional Services
PDF
Apache Hadoopの現在と未来
by
Yahoo!デベロッパーネットワーク
PDF
[db tech showcase Tokyo 2015] B34:データの仮想化を具体化するIBMのロジカルデータウェアハウス by 日本アイ・ビー・エ...
by
Insight Technology, Inc.
PDF
Apache Spark超入門 (Hadoop / Spark Conference Japan 2016 講演資料)
by
NTT DATA OSS Professional Services
PPTX
Impala + Kudu を用いたデータウェアハウス構築の勘所 (仮)
by
Cloudera Japan
PDF
並列分散処理基盤Hadoopの紹介と、開発者が語るHadoopの使いどころ (Silicon Valley x 日本 / Tech x Business ...
by
NTT DATA OSS Professional Services
PDF
Apache Hadoop HDFSの最新機能の紹介(2018)#dbts2018
by
Yahoo!デベロッパーネットワーク
PDF
Hadoop ecosystem NTTDATA osc15tk
by
NTT DATA OSS Professional Services
PDF
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
PDF
Oracle Cloudで始める、DBエンジニアのためのHadoop超入門(db tech showcase 2016 Oracle セッション資料)
by
オラクルエンジニア通信
PDF
Apache Spark 1000 nodes NTT DATA
by
NTT DATA OSS Professional Services
PDF
Apache Sparkのご紹介 (後半:技術トピック)
by
NTT DATA OSS Professional Services
SIerとオープンソースの美味しい関係 ~コミュニティの力を活かして世界を目指そう~
by
NTT DATA OSS Professional Services
分散処理基盤Apache Hadoopの現状と、NTTデータのHadoopに対する取り組み
by
NTT DATA OSS Professional Services
Hadoop 2.6の最新機能(Cloudera World Tokyo 2014 LT講演資料)
by
NTT DATA OSS Professional Services
HDFS新機能総まとめin 2015 (日本Hadoopユーザー会 ライトニングトーク@Cloudera World Tokyo 2015 講演資料)
by
NTT DATA OSS Professional Services
データインターフェースとしてのHadoop ~HDFSとクラウドストレージと私~ (NTTデータ テクノロジーカンファレンス 2019 講演資料、2019...
by
NTT DATA Technology & Innovation
Hadoop2.6の最新機能+
by
NTT DATA OSS Professional Services
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発...
by
NTT DATA Technology & Innovation
20170303 java9 hadoop
by
NTT DATA OSS Professional Services
Hadoopエコシステムの最新動向とNTTデータの取り組み (OSC 2016 Tokyo/Spring 講演資料)
by
NTT DATA OSS Professional Services
Apache Hadoopの現在と未来
by
Yahoo!デベロッパーネットワーク
[db tech showcase Tokyo 2015] B34:データの仮想化を具体化するIBMのロジカルデータウェアハウス by 日本アイ・ビー・エ...
by
Insight Technology, Inc.
Apache Spark超入門 (Hadoop / Spark Conference Japan 2016 講演資料)
by
NTT DATA OSS Professional Services
Impala + Kudu を用いたデータウェアハウス構築の勘所 (仮)
by
Cloudera Japan
並列分散処理基盤Hadoopの紹介と、開発者が語るHadoopの使いどころ (Silicon Valley x 日本 / Tech x Business ...
by
NTT DATA OSS Professional Services
Apache Hadoop HDFSの最新機能の紹介(2018)#dbts2018
by
Yahoo!デベロッパーネットワーク
Hadoop ecosystem NTTDATA osc15tk
by
NTT DATA OSS Professional Services
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
Oracle Cloudで始める、DBエンジニアのためのHadoop超入門(db tech showcase 2016 Oracle セッション資料)
by
オラクルエンジニア通信
Apache Spark 1000 nodes NTT DATA
by
NTT DATA OSS Professional Services
Apache Sparkのご紹介 (後半:技術トピック)
by
NTT DATA OSS Professional Services
Similar to Distributed data stores in Hadoop ecosystem
PPTX
Hadoop Compatible File Systems (Azure編) (セミナー「Big Data Developerに贈る第二弾 ‐ Azur...
by
NTT DATA Technology & Innovation
PDF
NTTデータ流 Hadoop活用のすすめ ~インフラ構築・運用の勘所~
by
NTT DATA OSS Professional Services
PDF
Hadoop Compatible File Systems 2019 (db tech showcase 2019 Tokyo講演資料、2019/09/25)
by
NTT DATA Technology & Innovation
PDF
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
PDF
AI・HPC・ビッグデータで利用される分散ファイルシステムを知る
by
日本ヒューレット・パッカード株式会社
PDF
分散処理基盤Apache Hadoop入門とHadoopエコシステムの最新技術動向 (オープンソースカンファレンス 2015 Tokyo/Spring 講...
by
NTT DATA OSS Professional Services
PDF
Hadoop, NoSQL, GlusterFSの概要
by
日本ヒューレット・パッカード株式会社
PDF
マルチテナント Hadoop クラスタのためのモニタリング Best Practice
by
Hadoop / Spark Conference Japan
PDF
【17-E-3】Hadoop:黄色い象使いへの道 ~「Hadoop徹底入門」より~
by
Developers Summit
PDF
Hadoop book-2nd-ch3-update
by
Taisuke Yamada
PDF
Hadoop operation chaper 4
by
Yukinori Suda
PPTX
Tuning maniax 2014 Hadoop編
by
ThinkIT_impress
PPTX
Cloudera大阪セミナー 20130219
by
Cloudera Japan
PDF
分散処理基盤ApacheHadoop入門とHadoopエコシステムの最新技術動向(OSC2015 Kansai発表資料)
by
NTT DATA OSS Professional Services
PDF
ちょっと理解に自信がないな という皆さまに贈るHadoop/Sparkのキホン (IBM Datapalooza Tokyo 2016講演資料)
by
hamaken
PDF
Apache Kuduは何がそんなに「速い」DBなのか? #dbts2017
by
Cloudera Japan
PDF
Red Hat ストレージ製品
by
Takuya Utsunomiya
PDF
HDFS vs. MapR Filesystem
by
日本ヒューレット・パッカード株式会社
PDF
Introduction to Hadoop and Spark (before joining the other talk) and An Overv...
by
DataWorks Summit/Hadoop Summit
PDF
HDFSのスケーラビリティの限界を突破するためのさまざまな取り組み | Hadoop / Spark Conference Japan 2019 #hc...
by
Yahoo!デベロッパーネットワーク
Hadoop Compatible File Systems (Azure編) (セミナー「Big Data Developerに贈る第二弾 ‐ Azur...
by
NTT DATA Technology & Innovation
NTTデータ流 Hadoop活用のすすめ ~インフラ構築・運用の勘所~
by
NTT DATA OSS Professional Services
Hadoop Compatible File Systems 2019 (db tech showcase 2019 Tokyo講演資料、2019/09/25)
by
NTT DATA Technology & Innovation
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
AI・HPC・ビッグデータで利用される分散ファイルシステムを知る
by
日本ヒューレット・パッカード株式会社
分散処理基盤Apache Hadoop入門とHadoopエコシステムの最新技術動向 (オープンソースカンファレンス 2015 Tokyo/Spring 講...
by
NTT DATA OSS Professional Services
Hadoop, NoSQL, GlusterFSの概要
by
日本ヒューレット・パッカード株式会社
マルチテナント Hadoop クラスタのためのモニタリング Best Practice
by
Hadoop / Spark Conference Japan
【17-E-3】Hadoop:黄色い象使いへの道 ~「Hadoop徹底入門」より~
by
Developers Summit
Hadoop book-2nd-ch3-update
by
Taisuke Yamada
Hadoop operation chaper 4
by
Yukinori Suda
Tuning maniax 2014 Hadoop編
by
ThinkIT_impress
Cloudera大阪セミナー 20130219
by
Cloudera Japan
分散処理基盤ApacheHadoop入門とHadoopエコシステムの最新技術動向(OSC2015 Kansai発表資料)
by
NTT DATA OSS Professional Services
ちょっと理解に自信がないな という皆さまに贈るHadoop/Sparkのキホン (IBM Datapalooza Tokyo 2016講演資料)
by
hamaken
Apache Kuduは何がそんなに「速い」DBなのか? #dbts2017
by
Cloudera Japan
Red Hat ストレージ製品
by
Takuya Utsunomiya
HDFS vs. MapR Filesystem
by
日本ヒューレット・パッカード株式会社
Introduction to Hadoop and Spark (before joining the other talk) and An Overv...
by
DataWorks Summit/Hadoop Summit
HDFSのスケーラビリティの限界を突破するためのさまざまな取り組み | Hadoop / Spark Conference Japan 2019 #hc...
by
Yahoo!デベロッパーネットワーク
More from NTT DATA OSS Professional Services
PDF
Global Top 5 を目指す NTT DATA の確かで意外な技術力
by
NTT DATA OSS Professional Services
PDF
Spark SQL - The internal -
by
NTT DATA OSS Professional Services
PDF
Structured Streaming - The Internal -
by
NTT DATA OSS Professional Services
PPTX
ブロックチェーンの仕組みと動向(入門編)
by
NTT DATA OSS Professional Services
PDF
Application of postgre sql to large social infrastructure jp
by
NTT DATA OSS Professional Services
PDF
Application of postgre sql to large social infrastructure
by
NTT DATA OSS Professional Services
PDF
Apache Hadoop 2.8.0 の新機能 (抜粋)
by
NTT DATA OSS Professional Services
PDF
データ活用をもっともっと円滑に! ~データ処理・分析基盤編を少しだけ~
by
NTT DATA OSS Professional Services
PDF
商用ミドルウェアのPuppet化で気を付けたい5つのこと
by
NTT DATA OSS Professional Services
PPTX
今からはじめるPuppet 2016 ~ インフラエンジニアのたしなみ ~
by
NTT DATA OSS Professional Services
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
PDF
PostgreSQLでpg_bigmを使って日本語全文検索 (MySQLとPostgreSQLの日本語全文検索勉強会 発表資料)
by
NTT DATA OSS Professional Services
PDF
本当にあったHadoopの恐い話 Blockはどこへきえた? (Hadoop / Spark Conference Japan 2016 ライトニングトー...
by
NTT DATA OSS Professional Services
PDF
Hadoopのメンテナンスリリースバージョンをリリースしてみた (日本Hadoopユーザー会 ライトニングトーク@Cloudera World Tokyo...
by
NTT DATA OSS Professional Services
PDF
PostgreSQLコミュニティに飛び込もう
by
NTT DATA OSS Professional Services
PDF
SIプロジェクトでのインフラ自動化の事例 (第1回 Puppetユーザ会 発表資料)
by
NTT DATA OSS Professional Services
Global Top 5 を目指す NTT DATA の確かで意外な技術力
by
NTT DATA OSS Professional Services
Spark SQL - The internal -
by
NTT DATA OSS Professional Services
Structured Streaming - The Internal -
by
NTT DATA OSS Professional Services
ブロックチェーンの仕組みと動向(入門編)
by
NTT DATA OSS Professional Services
Application of postgre sql to large social infrastructure jp
by
NTT DATA OSS Professional Services
Application of postgre sql to large social infrastructure
by
NTT DATA OSS Professional Services
Apache Hadoop 2.8.0 の新機能 (抜粋)
by
NTT DATA OSS Professional Services
データ活用をもっともっと円滑に! ~データ処理・分析基盤編を少しだけ~
by
NTT DATA OSS Professional Services
商用ミドルウェアのPuppet化で気を付けたい5つのこと
by
NTT DATA OSS Professional Services
今からはじめるPuppet 2016 ~ インフラエンジニアのたしなみ ~
by
NTT DATA OSS Professional Services
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
PostgreSQLでpg_bigmを使って日本語全文検索 (MySQLとPostgreSQLの日本語全文検索勉強会 発表資料)
by
NTT DATA OSS Professional Services
本当にあったHadoopの恐い話 Blockはどこへきえた? (Hadoop / Spark Conference Japan 2016 ライトニングトー...
by
NTT DATA OSS Professional Services
Hadoopのメンテナンスリリースバージョンをリリースしてみた (日本Hadoopユーザー会 ライトニングトーク@Cloudera World Tokyo...
by
NTT DATA OSS Professional Services
PostgreSQLコミュニティに飛び込もう
by
NTT DATA OSS Professional Services
SIプロジェクトでのインフラ自動化の事例 (第1回 Puppetユーザ会 発表資料)
by
NTT DATA OSS Professional Services
Recently uploaded
PPTX
「Drupal SDCについて紹介」2025/10/17の勉強会で発表されたものです。
by
iPride Co., Ltd.
PDF
技育祭2025秋 サボろうとする生成AIの傾向と対策 登壇資料(フューチャー渋川)
by
Yoshiki Shibukawa
PDF
FOSS4G Hokkaido - QFieldをランナーのために活用した - QField for runners
by
Raymond Lay
PPTX
FOSS4G Japan 2025 - QGISでスムーズに地図を比較 - QMapCompareプラグインの紹介
by
Raymond Lay
PPTX
How to buy a used computer and use it with Windows 11
by
Atomu Hidaka
PDF
「似ているようで微妙に違う言葉」2025/10/17の勉強会で発表されたものです。
by
iPride Co., Ltd.
PDF
FOSS4G Japan 2024 ハザードマップゲームの作り方 Hazard Map Game QGIS Plugin
by
Raymond Lay
PDF
DX人材育成 サービスデザインで実現する「巻き込み力」の育て方 by Graat
by
Graat(グラーツ)
「Drupal SDCについて紹介」2025/10/17の勉強会で発表されたものです。
by
iPride Co., Ltd.
技育祭2025秋 サボろうとする生成AIの傾向と対策 登壇資料(フューチャー渋川)
by
Yoshiki Shibukawa
FOSS4G Hokkaido - QFieldをランナーのために活用した - QField for runners
by
Raymond Lay
FOSS4G Japan 2025 - QGISでスムーズに地図を比較 - QMapCompareプラグインの紹介
by
Raymond Lay
How to buy a used computer and use it with Windows 11
by
Atomu Hidaka
「似ているようで微妙に違う言葉」2025/10/17の勉強会で発表されたものです。
by
iPride Co., Ltd.
FOSS4G Japan 2024 ハザードマップゲームの作り方 Hazard Map Game QGIS Plugin
by
Raymond Lay
DX人材育成 サービスデザインで実現する「巻き込み力」の育て方 by Graat
by
Graat(グラーツ)
Distributed data stores in Hadoop ecosystem
1.
© 2017 NTT
DATA Corporation 10/30/2017 NTT DATA Masatake Iwasaki 分散データストアとそのビルディングブロック
2.
© 2017 NTT
DATA Corporation 2 今回とりあげる分散データストア HDFS HBase Kudu 共通点 ⼤量のデータを格納 多数の(汎⽤)サーバでクラスタを構成 マスタースレーブ 効率的なデータアクセスを提供 データ保全性と可⽤性 分散処理FWから使われることを想定 Hadoopエコシステムの分散データストア
3.
© 2017 NTT
DATA Corporation 3 I. HDFSの概要 II. HBaseの概要 III. Kuduの概要 IV. データフォーマット V. データの冗⻑化 VI. ノード間協調とZooKeeper VII. Javaとネイティブコード VIII. まとめ ToC
4.
© 2017 NTT
DATA Corporation 4 HDFSの概要
5.
© 2017 NTT
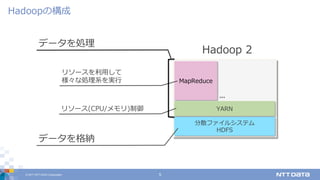
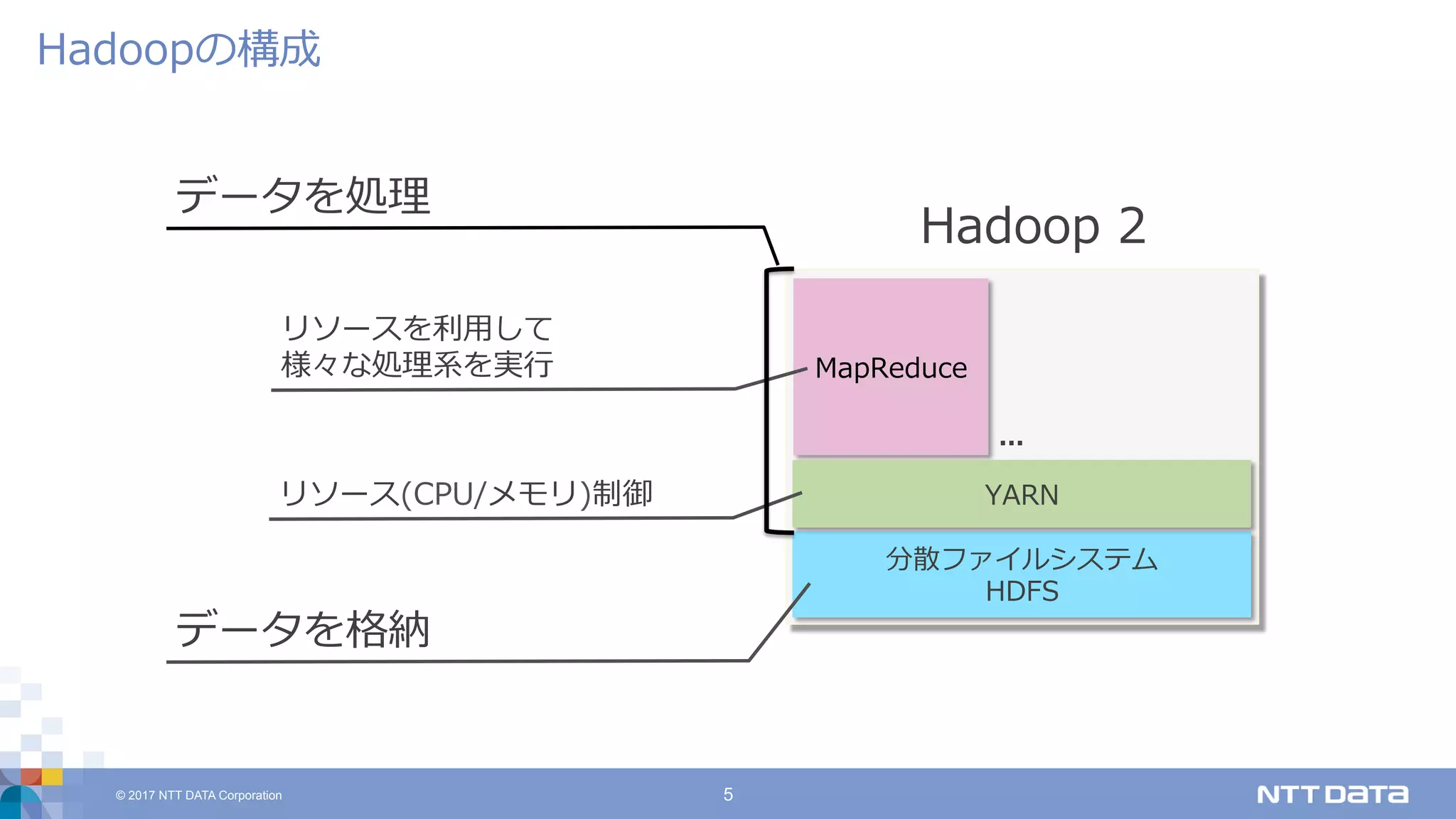
DATA Corporation 5 Hadoopの構成 Hadoop 2 分散ファイルシステム HDFS MapReduce YARN データを格納 リソース(CPU/メモリ)制御 リソースを利⽤して 様々な処理系を実⾏ データを処理 ...
6.
© 2017 NTT
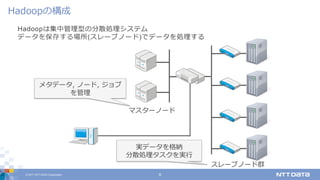
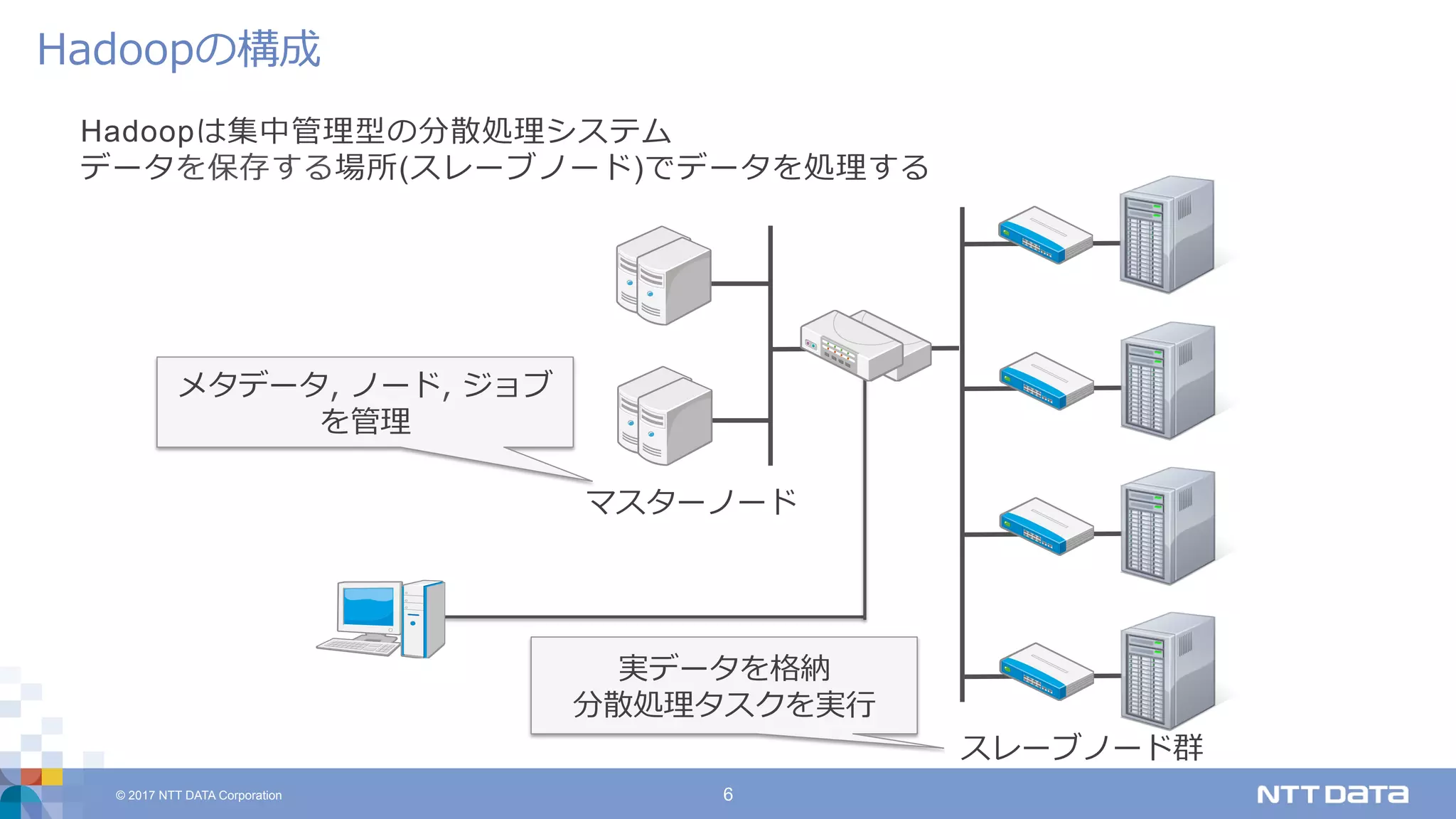
DATA Corporation 6 Hadoopは集中管理型の分散処理システム データを保存する場所(スレーブノード)でデータを処理する Hadoopの構成 マスターノード スレーブノード群 実データを格納 分散処理タスクを実⾏ メタデータ, ノード, ジョブ を管理
7.
© 2017 NTT
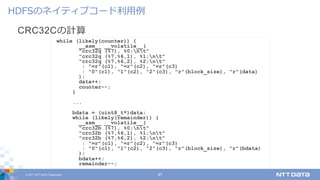
DATA Corporation 7 Hadoop Distributed File System ファイルシステムな機能/APIを提供 階層的な名前空間(mkdir, ls) ファイルの読み書き(open, read, write) パーミッション等によるアクセス制御 quota # シンボリックリンクは未サポート ⼀度追加されたが⾊々問題がありdisabledに ネイティブFS(ext4, xfs, ...)の上に実装 ⼤きなファイル(100+MB)の格納に最適化 ファイルを128MBのブロックに分けて管理 HDFSとは何か
8.
© 2017 NTT
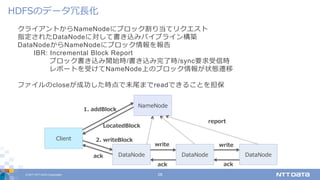
DATA Corporation 8 NameNode: メタデータを管理するマスター どのファイルどのブロックから成るか どのブロックをどのDataNodeが持つか DataNode: データブロック(レプリカ)を保持するスレーブ NameNodeに対して定期/不定期でレポート送信 クライアント: まずNameNodeにリクエスト送信 指定されたDataNodeに接続して読み書き HDFSのアーキテクチャ
9.
© 2017 NTT
DATA Corporation 9 データ保全性 データは書き込み時に冗⻑化 ノード故障で冗⻑度が下がったら⾃動回復 ラックを跨ぐようなデータの配置戦略 可⽤性 スレーブ故障は別ノードを使ってリトライ マスターはactive/standbyなHA構成をサポート ⼀貫性 メタデータを1箇所(NameNode)で管理するため NameNodeがスケーラビリティのボトルネック とはいえスレーブ数千台くらいはいける データローカリティ データを持ってるノードに処理させる HDFSの特徴
10.
© 2017 NTT
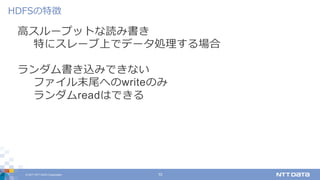
DATA Corporation 10 ⾼スループットな読み書き 特にスレーブ上でデータ処理する場合 ランダム書き込みできない ファイル末尾へのwriteのみ ランダムreadはできる HDFSの特徴
11.
© 2017 NTT
DATA Corporation 11 HBaseの概要
12.
© 2017 NTT
DATA Corporation 12 分散KVS テーブルを⽔平分割してserve プリミティブなAPI(put, get, scan)を提供 HDFS上に実装 データファイルとWALをHDFSに置く Log-Structured Mergeな仕組みで更新に対応 writeはWALとメモリ上(MemStore)にまず反映 溜まったらデータファイル(HFile)に書き出し readはMemStoreとHFileの両⽅を⾒てmerge ファイルはときどきcompactionで整理 HBaseとはなにか
13.
© 2017 NTT
DATA Corporation 13 Master: Regionの割り当てを管理する Region: テーブルを⽔平分割したもの 割り当てはmeta regionに格納 RegionServer: Regionに対する読み書きを処理 クライアント: ZooKeeper(後述)からmasterのアドレス取得 MasterからRegionの割り当て情報を取得 必要なRegionServerに接続して読み書き HBaseのアーキテクチャ
14.
© 2017 NTT
DATA Corporation 14 ランダムwrite/readが得意 HDFSの機能を補完 ⼀貫性重視 あるregionを担当するRSは(基本的には)1台だけ 落ちたらfailover完了までアクセス不可 サーバサイドの処理フック(coprocessor)が多様 ワークロードに合わせて魔改造可能 運⽤にHadoopのツールセットを使える 例: snapshotをMRジョブで別の場所にコピー HBaseの特徴
15.
© 2017 NTT
DATA Corporation 15 Kuduの概要
16.
© 2017 NTT
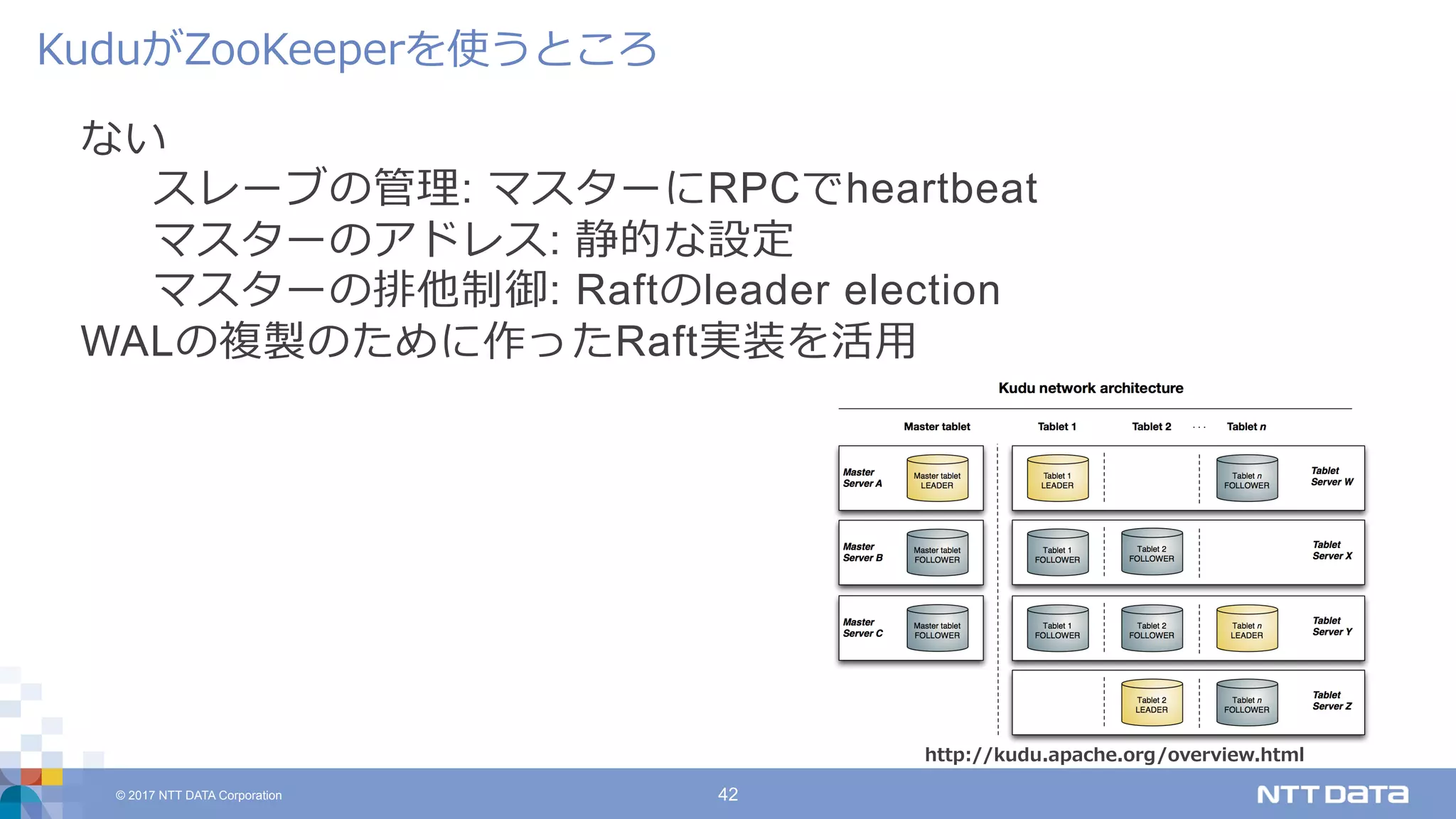
DATA Corporation 16 分散データストア テーブルを⽔平分割してserve プリミティブなAPI(insert, update, scan)を提供 データ型の概念あり: schema on write Kuduとはなにか http://kudu.apache.org/overview.htmlhttp://kudu.apache.org/overview.html
17.
© 2017 NTT
DATA Corporation 17 Master server: Tabletの割り当てを管理する Tablet: テーブルを⽔平分割したもの 割り当てはmaster tabletに格納 Masterがmaster tabletをserve Tablet server: Tabletに対する読み書きを処理 Kuduのアーキテクチャ
18.
© 2017 NTT
DATA Corporation 18 OLAPなワークロードに最適化 Columnarフォーマット(後述)による効率的なIO Log-Structured Mergeな仕組みで更新をサポート writeはWALとメモリ上(MemRowSet)に反映 溜まったらデータファイル(DiskRowSet)に書く readはMemRowSetとDiskRowSetの両⽅をみる ファイルはときどきcompactionで整理 Kuduの特徴
19.
© 2017 NTT
DATA Corporation 19 SQLエンジンは提供しない Impala(等)と組みあわえて使う想定 HDFSやZooKeeperに⾮依存 データは(Raftを使って)⾃前で冗⻑化 (Javaではなく)C++で実装 Linux前提 JavaのクライアントAPIはある HDFS: GFS、HBase: Bigtable Kudu: Spanner(のデータストア部分) Kuduの特徴
20.
© 2017 NTT
DATA Corporation 20 データフォーマット
21.
© 2017 NTT
DATA Corporation 21 フォーマットはない ブロックファイルの集まりとして管理 チェックサムを⼀緒に(.metaに)保存 512バイト毎にCRC32を計算 HDFSのファイルのチェックサム= .metaのMD5をまとめたもののMD5 HDFSのデータファイル $ ls -l data/current/BP-.../current/finalized/subdir0/subdir1 total 254752 -rw-r--r-- 1 test test 134217728 Aug 20 09:35 blk_1073742171 -rw-r--r-- 1 test test 1048583 Aug 20 09:35 blk_1073742171_1347.meta -rw-r--r-- 1 test test 124620800 Aug 20 09:35 blk_1073742172 -rw-r--r-- 1 test test 973607 Aug 20 09:35 blk_1073742172_1348.meta
22.
© 2017 NTT
DATA Corporation 22 データ型の概念なし(Keyもvalueもバイト列) データはKey順にソートして格納 同じRowを持つ複数のKeyValueをatomicに処理可能 KeyValueのKey: Row + ColumnFamily + Quolifier +α Rowが同じなら同じregion MVCC 更新はTimeStampが⼤きいKeyValueの追加 削除はKeyTypeがDELETEなKeyValueの追加 ときどきCompactionで整理 HBaseのKeyValue http://hbase.apache.org/book.html
23.
© 2017 NTT
DATA Corporation 23 ソートされたKeyValue アクセスを効率化する機能 Index:どのキーがどの辺あるか Bloom filter: ある値がその領域に含まれるか HBaseのデータファイル(HFile) http://hbase.apache.org/book.html
24.
© 2017 NTT
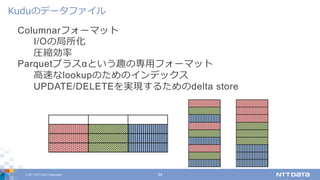
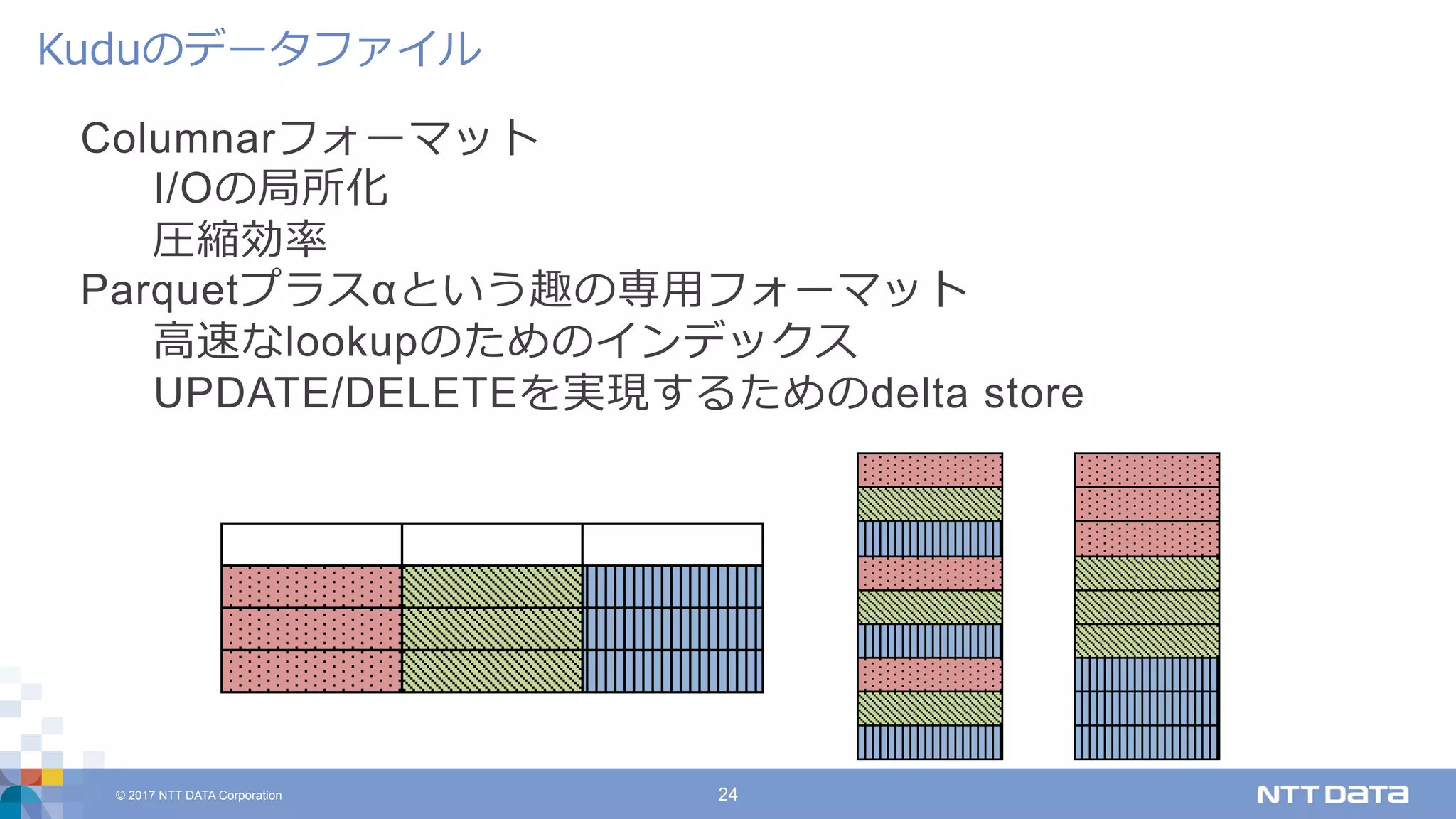
DATA Corporation 24 Columnarフォーマット I/Oの局所化 圧縮効率 Parquetプラスαという趣の専⽤フォーマット ⾼速なlookupのためのインデックス UPDATE/DELETEを実現するためのdelta store Kuduのデータファイル
25.
© 2017 NTT
DATA Corporation 25 OSSのColumnarフォーマット Hadoopエコシステム向けのツール群を提供 利⽤例: MapReduceでファイルを作ってHiveで読む ただし更新するためにはファイルの作り直しが必要 Kuduはそこを補完 Apache Parquet https://github.com/apache/parquet-format
26.
© 2017 NTT
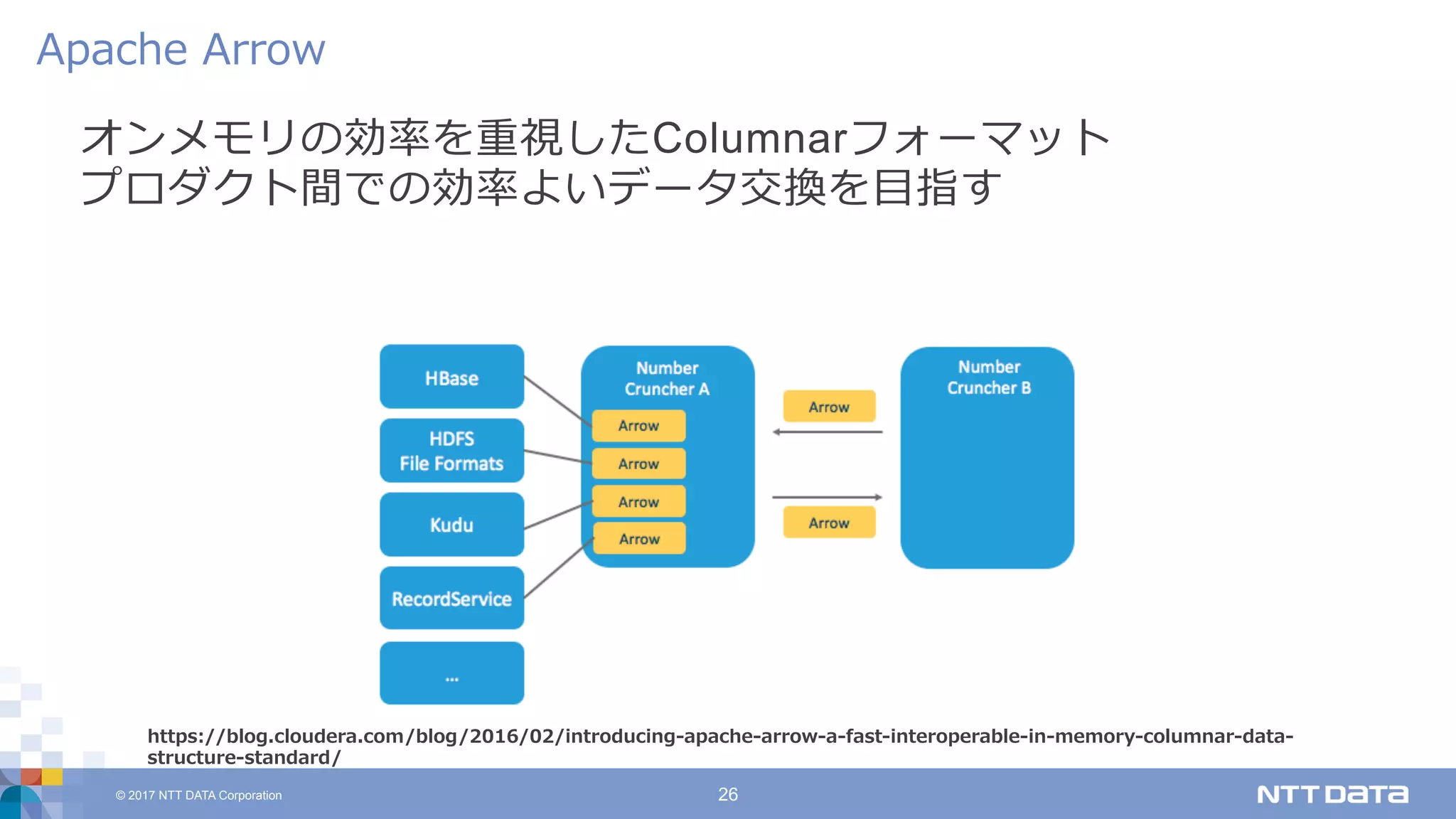
DATA Corporation 26 オンメモリの効率を重視したColumnarフォーマット プロダクト間での効率よいデータ交換を⽬指す Apache Arrow https://blog.cloudera.com/blog/2016/02/introducing-apache-arrow-a-fast-interoperable-in-memory-columnar-data- structure-standard/
27.
© 2017 NTT
DATA Corporation 27 データの冗⻑化
28.
© 2017 NTT
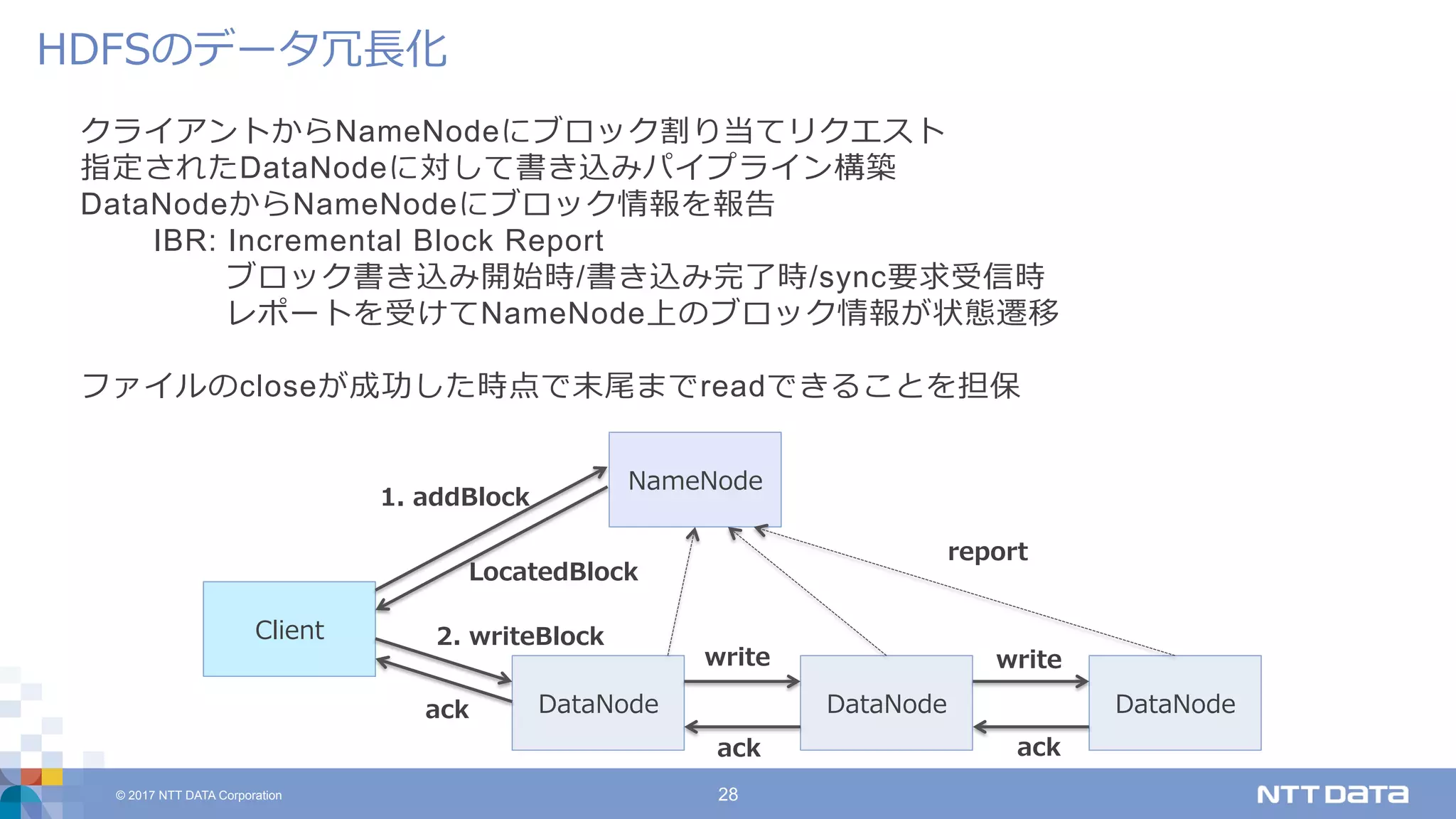
DATA Corporation 28 クライアントからNameNodeにブロック割り当てリクエスト 指定されたDataNodeに対して書き込みパイプライン構築 DataNodeからNameNodeにブロック情報を報告 IBR: Incremental Block Report ブロック書き込み開始時/書き込み完了時/sync要求受信時 レポートを受けてNameNode上のブロック情報が状態遷移 ファイルのcloseが成功した時点で末尾までreadできることを担保 HDFSのデータ冗⻑化 DataNode NameNode DataNode Client DataNode write ack write report 1. addBlock LocatedBlock 2. writeBlock ack ack
29.
© 2017 NTT
DATA Corporation 29 ブロックを保存するスレーブノードの選び⽅ 1つ⽬: クライアント on スレーブ ならそのノード そうでなければランダム 2つ⽬: 1つ⽬と別のサーバラックにあるノード 3つ⽬ :2つ⽬と同⼀サーバラックにあるノード 4つ⽬以降: ランダム(偏り過ぎないように調整) HDFSのrack awareness
30.
© 2017 NTT
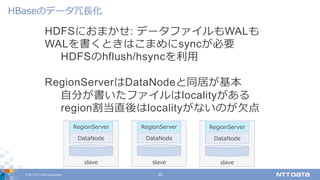
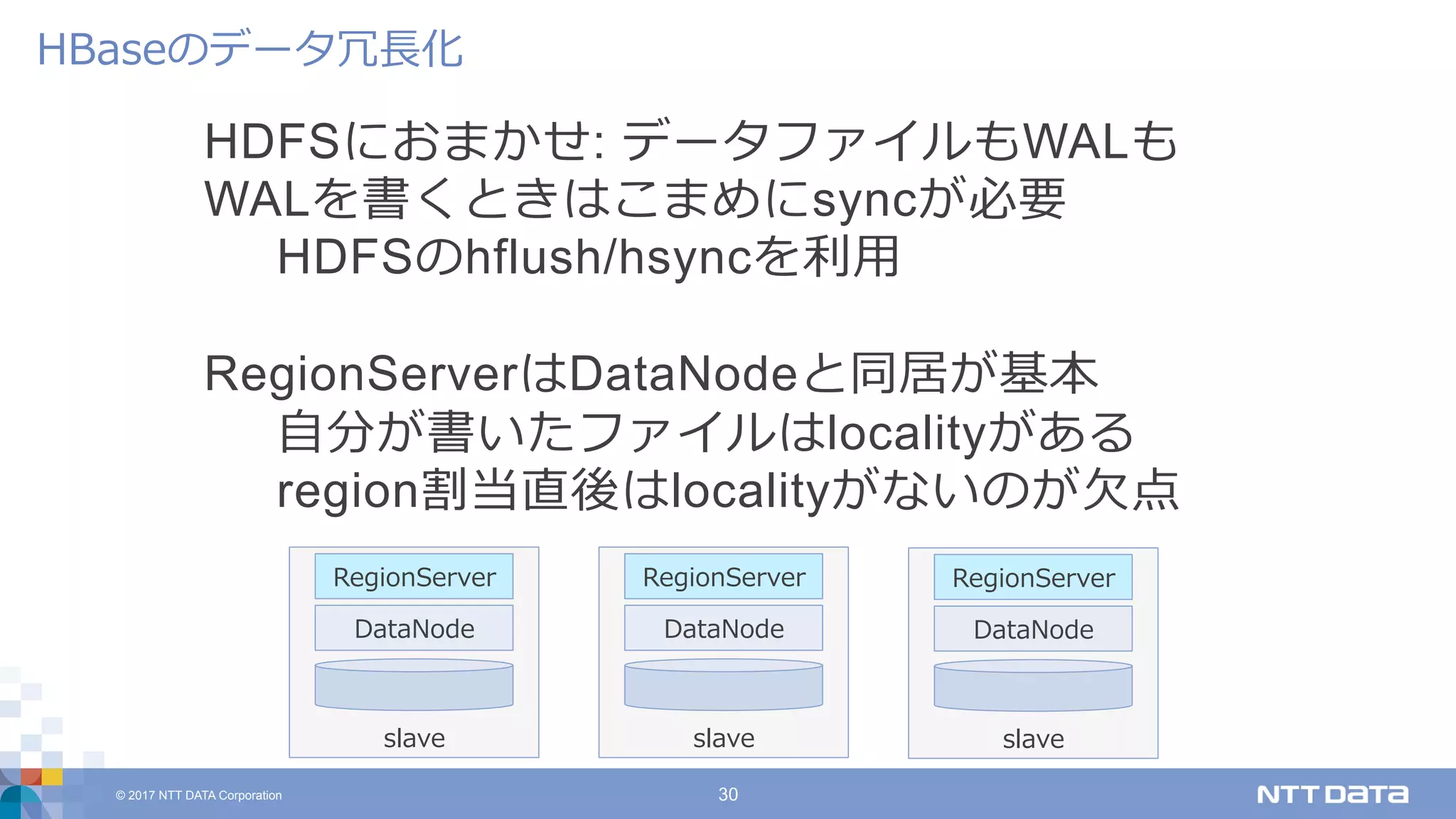
DATA Corporation 30 HDFSにおまかせ: データファイルもWALも WALを書くときはこまめにsyncが必要 HDFSのhflush/hsyncを利⽤ RegionServerはDataNodeと同居が基本 ⾃分が書いたファイルはlocalityがある region割当直後はlocalityがないのが⽋点 HBaseのデータ冗⻑化 slave RegionServer DataNode slave RegionServer DataNode slave RegionServer DataNode
31.
© 2017 NTT
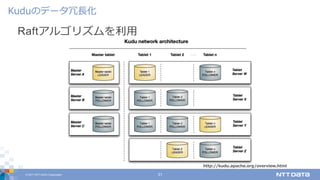
DATA Corporation 31 Raftアルゴリズムを利⽤ Kuduのデータ冗⻑化 http://kudu.apache.org/overview.html
32.
© 2017 NTT
DATA Corporation 32 ノード間協調とZooKeeper
33.
© 2017 NTT
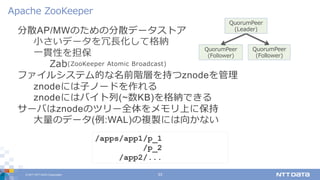
DATA Corporation 33 分散AP/MWのための分散データストア ⼩さいデータを冗⻑化して格納 ⼀貫性を担保 Zab(ZooKeeper Atomic Broadcast) ファイルシステム的な名前階層を持つznodeを管理 znodeには⼦ノードを作れる znodeにはバイト列(~数KB)を格納できる サーバはznodeのツリー全体をメモリ上に保持 ⼤量のデータ(例:WAL)の複製には向かない Apache ZooKeeper QuorumPeer (Follower) QuorumPeer (Follower) QuorumPeer (Leader) /apps/app1/p_1 /p_2 /app2/...
34.
© 2017 NTT
DATA Corporation 34 クライアントはTCPでつなぎっぱなし znodeをwatch: 変化があったらcallbackしてもらう ephemeralノード: 作者のコネクション切断で消えるznode どのサーバにつなぎにいくかはランダム エラーなら別ノードにリトライ 同じイベントが同じ順番で発⽣ ZooKeeperのクライアントとAPI
35.
© 2017 NTT
DATA Corporation 35 設定/状態の格納 ロック カウンタ シーケンス 待ち合わせ リーダー選出 メンバー管理 ZooKeeperでできること
36.
© 2017 NTT
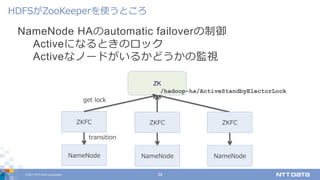
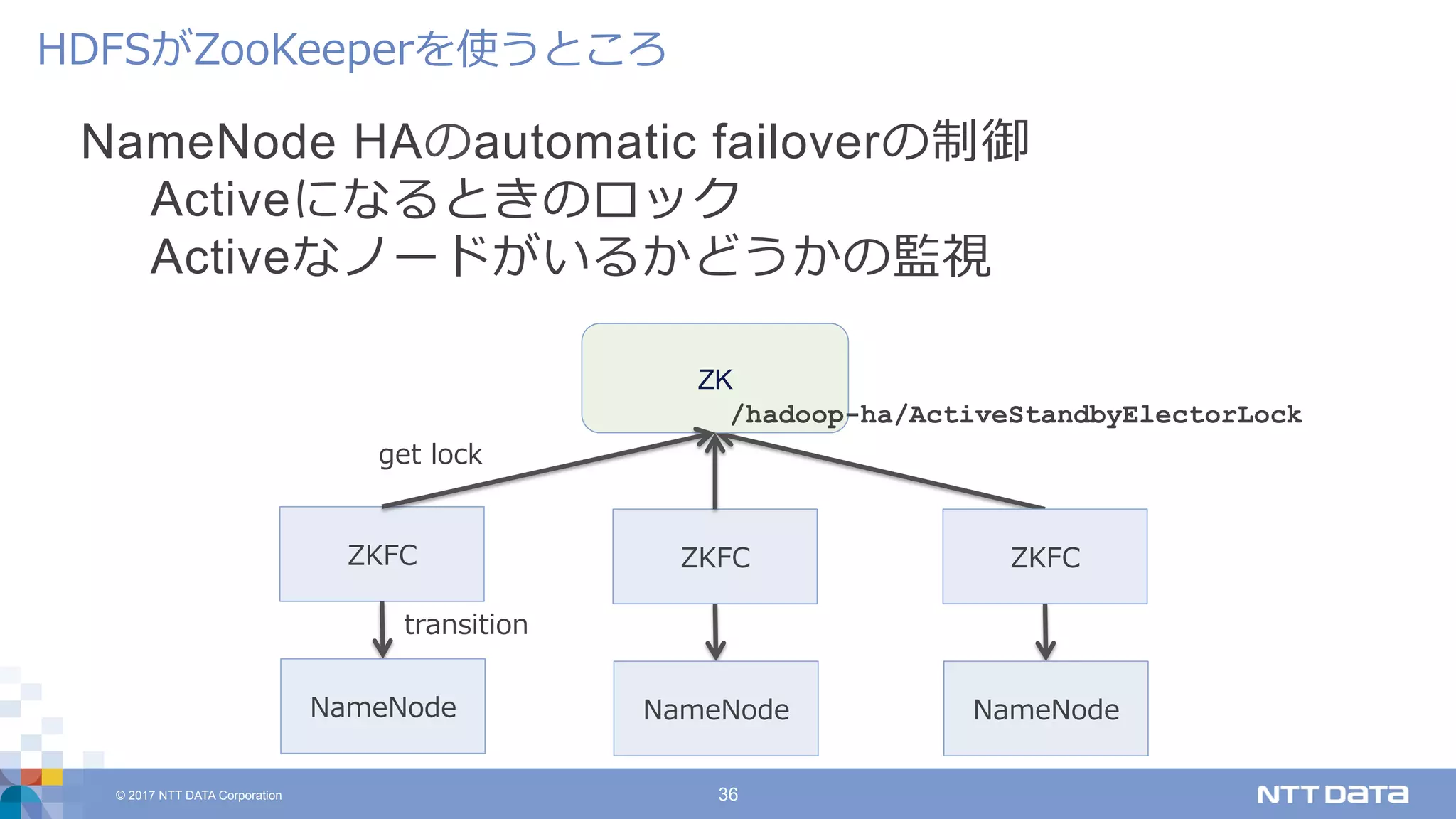
DATA Corporation 36 NameNode HAのautomatic failoverの制御 Activeになるときのロック Activeなノードがいるかどうかの監視 HDFSがZooKeeperを使うところ ZKFC ZK NameNode transition get lock /hadoop-ha/ActiveStandbyElectorLock ZKFC NameNode ZKFC NameNode
37.
© 2017 NTT
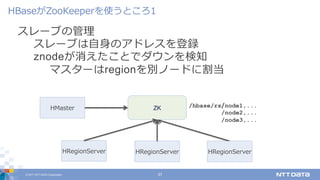
DATA Corporation 37 スレーブの管理 スレーブは⾃⾝のアドレスを登録 znodeが消えたことでダウンを検知 マスターはregionを別ノードに割当 HBaseがZooKeeperを使うところ1 HRegionServer ZK /hbase/rs/node1,... /node2,... /node3,... HRegionServer HRegionServer HMaster
38.
© 2017 NTT
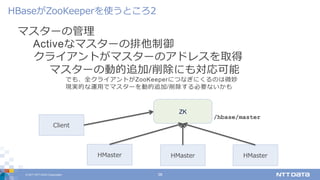
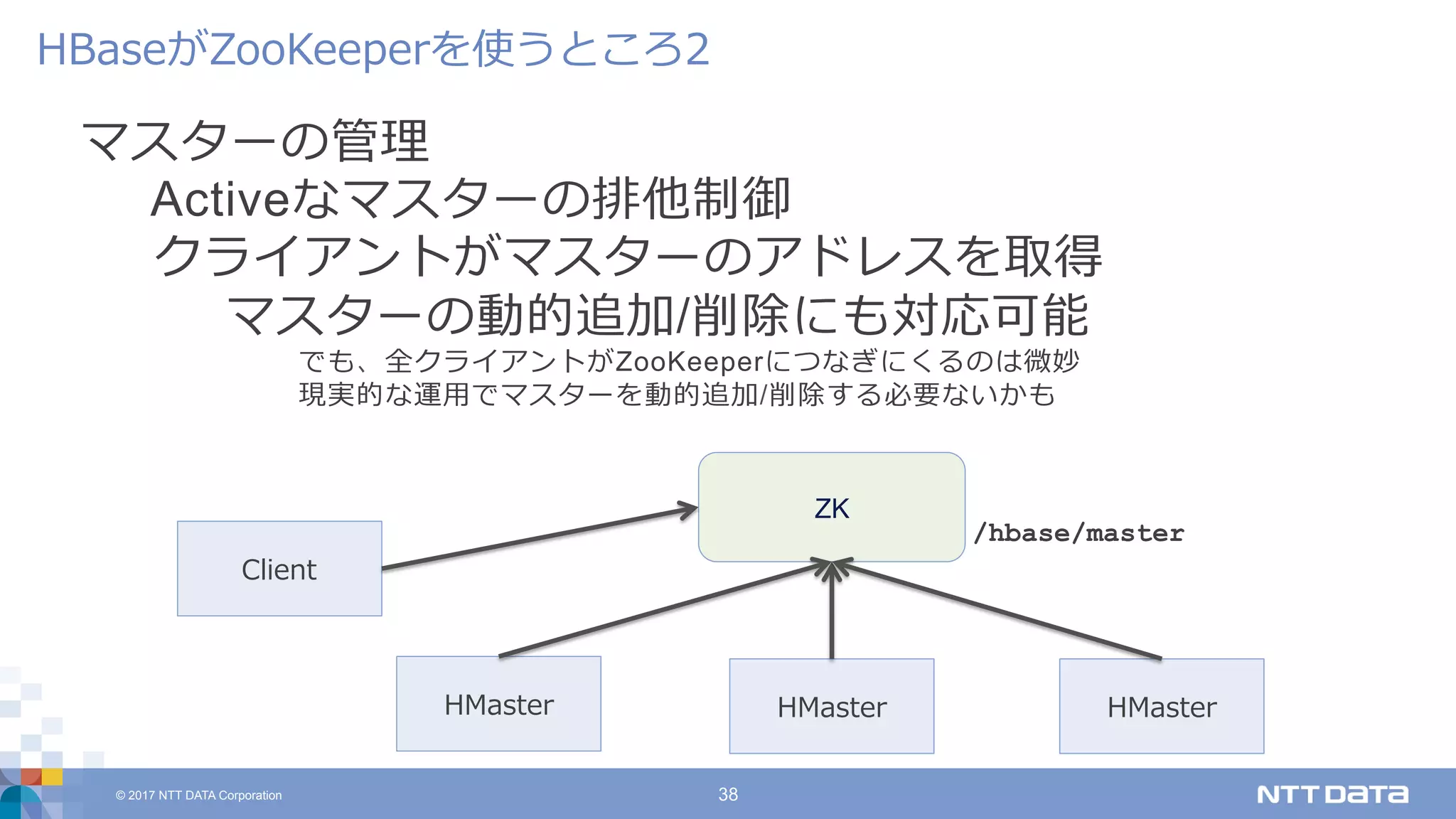
DATA Corporation 38 マスターの管理 Activeなマスターの排他制御 クライアントがマスターのアドレスを取得 マスターの動的追加/削除にも対応可能 でも、全クライアントがZooKeeperにつなぎにくるのは微妙 現実的な運⽤でマスターを動的追加/削除する必要ないかも HBaseがZooKeeperを使うところ2 HMaster ZK /hbase/master HMaster HMaster Client
39.
© 2017 NTT
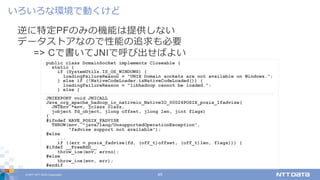
DATA Corporation 39 使い⽅によっては ZooKeeperがボトルネックになる 逆に複雑になる バックアップとリカバリ ZKクラスタダウン => サービスダウン これは意外と問題ではないかも ZooKeeperを使っていたけど、やめた例 Kafkaのサーバアドレス取得とoffset管理 Stormのtask heartbeat HBaseのリージョン割り当て ZooKeeperの落とし⽳
40.
© 2017 NTT
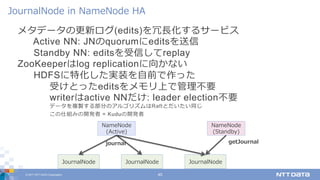
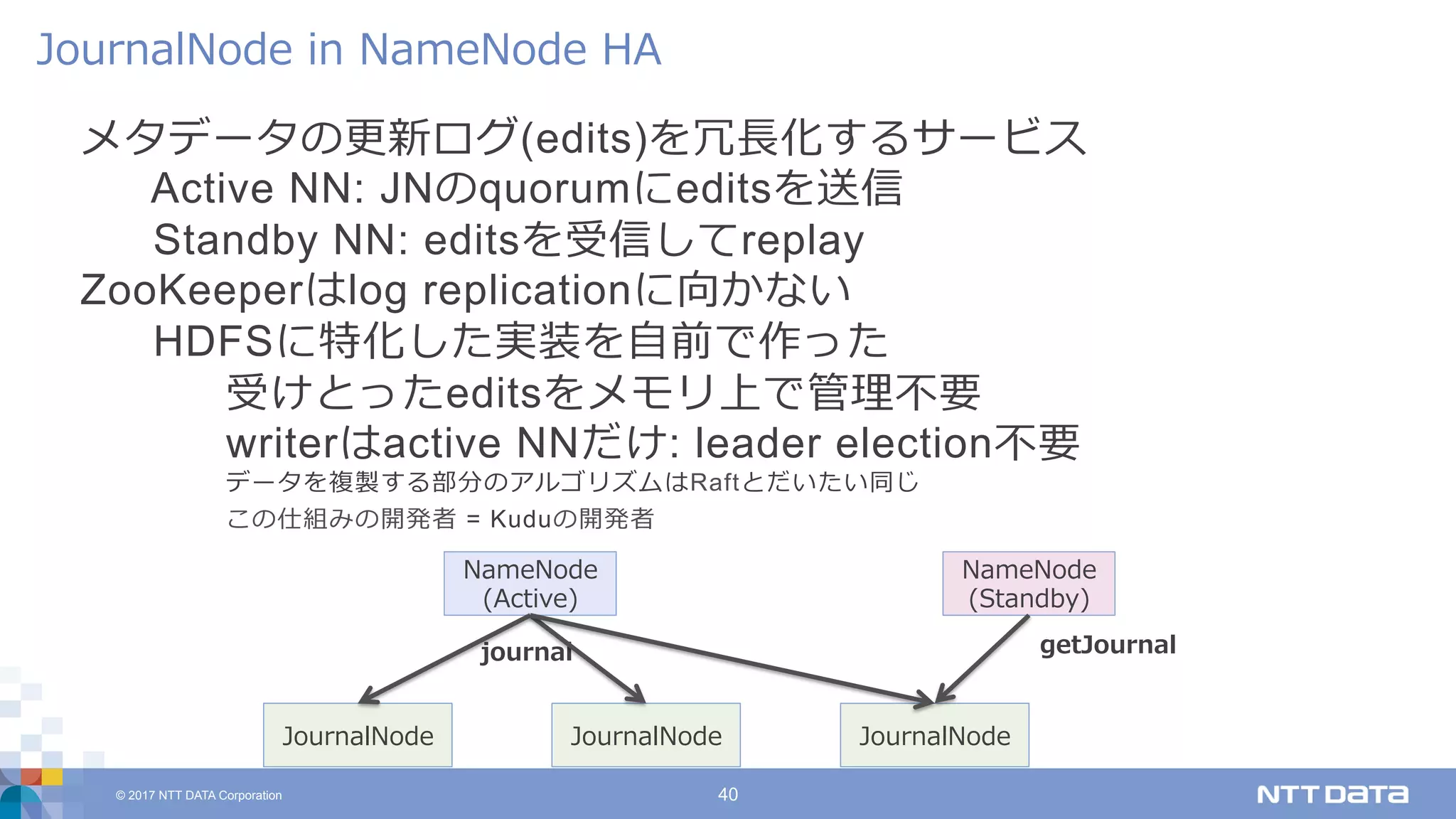
DATA Corporation 40 メタデータの更新ログ(edits)を冗⻑化するサービス Active NN: JNのquorumにeditsを送信 Standby NN: editsを受信してreplay ZooKeeperはlog replicationに向かない HDFSに特化した実装を⾃前で作った 受けとったeditsをメモリ上で管理不要 writerはactive NNだけ: leader election不要 データを複製する部分のアルゴリズムはRaftとだいたい同じ この仕組みの開発者 = Kuduの開発者 JournalNode in NameNode HA JournalNode NameNode (Active) JournalNode NameNode (Standby) JournalNode journal getJournal
41.
© 2017 NTT
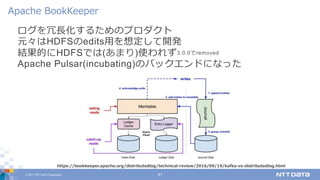
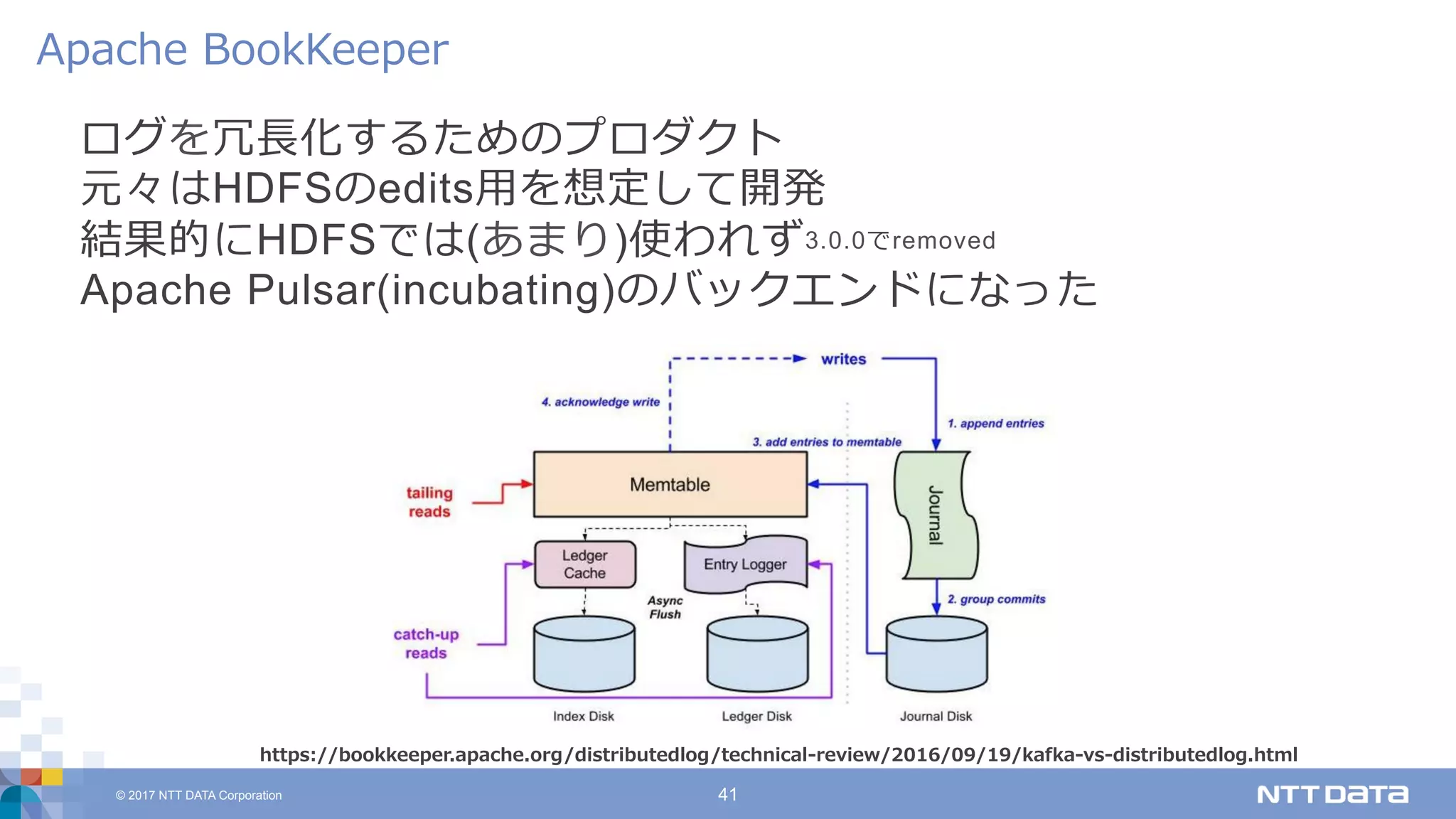
DATA Corporation 41 ログを冗⻑化するためのプロダクト 元々はHDFSのedits⽤を想定して開発 結果的にHDFSでは(あまり)使われず3.0.0でremoved Apache Pulsar(incubating)のバックエンドになった Apache BookKeeper https://bookkeeper.apache.org/distributedlog/technical-review/2016/09/19/kafka-vs-distributedlog.html
42.
© 2017 NTT
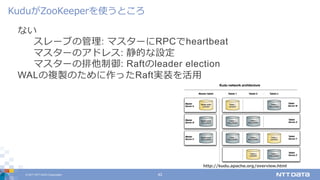
DATA Corporation 42 ない スレーブの管理: マスターにRPCでheartbeat マスターのアドレス: 静的な設定 マスターの排他制御: Raftのleader election WALの複製のために作ったRaft実装を活⽤ KuduがZooKeeperを使うところ http://kudu.apache.org/overview.html
43.
© 2017 NTT
DATA Corporation 43 Javaとネイティブコード
44.
© 2017 NTT
DATA Corporation 44 開発や運⽤のためのツールが豊富 技術者が多い 安定した実⾏環境(JVM) いろいろな環境で動く メモリ管理してくれる Javaのよいところ
45.
© 2017 NTT
DATA Corporation 45 逆に特定PFのみの機能は提供しない データストアなので性能の追求も必要 => Cで書いてJNIで呼び出せばよい いろいろな環境で動くけど public class DomainSocket implements Closeable { static { if (SystemUtils.IS_OS_WINDOWS) { loadingFailureReason = "UNIX Domain sockets are not available on Windows."; } else if (!NativeCodeLoader.isNativeCodeLoaded()) { loadingFailureReason = "libhadoop cannot be loaded."; } else { JNIEXPORT void JNICALL Java_org_apache_hadoop_io_nativeio_NativeIO_00024POSIX_posix_1fadvise( JNIEnv *env, jclass clazz, jobject fd_object, jlong offset, jlong len, jint flags) { #ifndef HAVE_POSIX_FADVISE THROW(env, "java/lang/UnsupportedOperationException", "fadvise support not available"); #else ... if ((err = posix_fadvise(fd, (off_t)offset, (off_t)len, flags))) { #ifdef __FreeBSD__ throw_ioe(env, errno); #else throw_ioe(env, err); #endif
46.
© 2017 NTT
DATA Corporation 46 mmap, munmap, mlock 特定のブロックデータをキャッシュにキープ posix_fadvise キャッシュ上にいなくてよいファイル/領域を指定 もうすぐ必要な領域を先読み sync_file_range こまめなsync: writeレイテンシのスパイクを消す sendmsg, recevmsg clientがDNからopen済みfdをもらって直接read 結局⼀番おすすめなのはLinux 初めからLinux前提でよいという気持ちは分かる HDFSのネイティブコード利⽤例
47.
© 2017 NTT
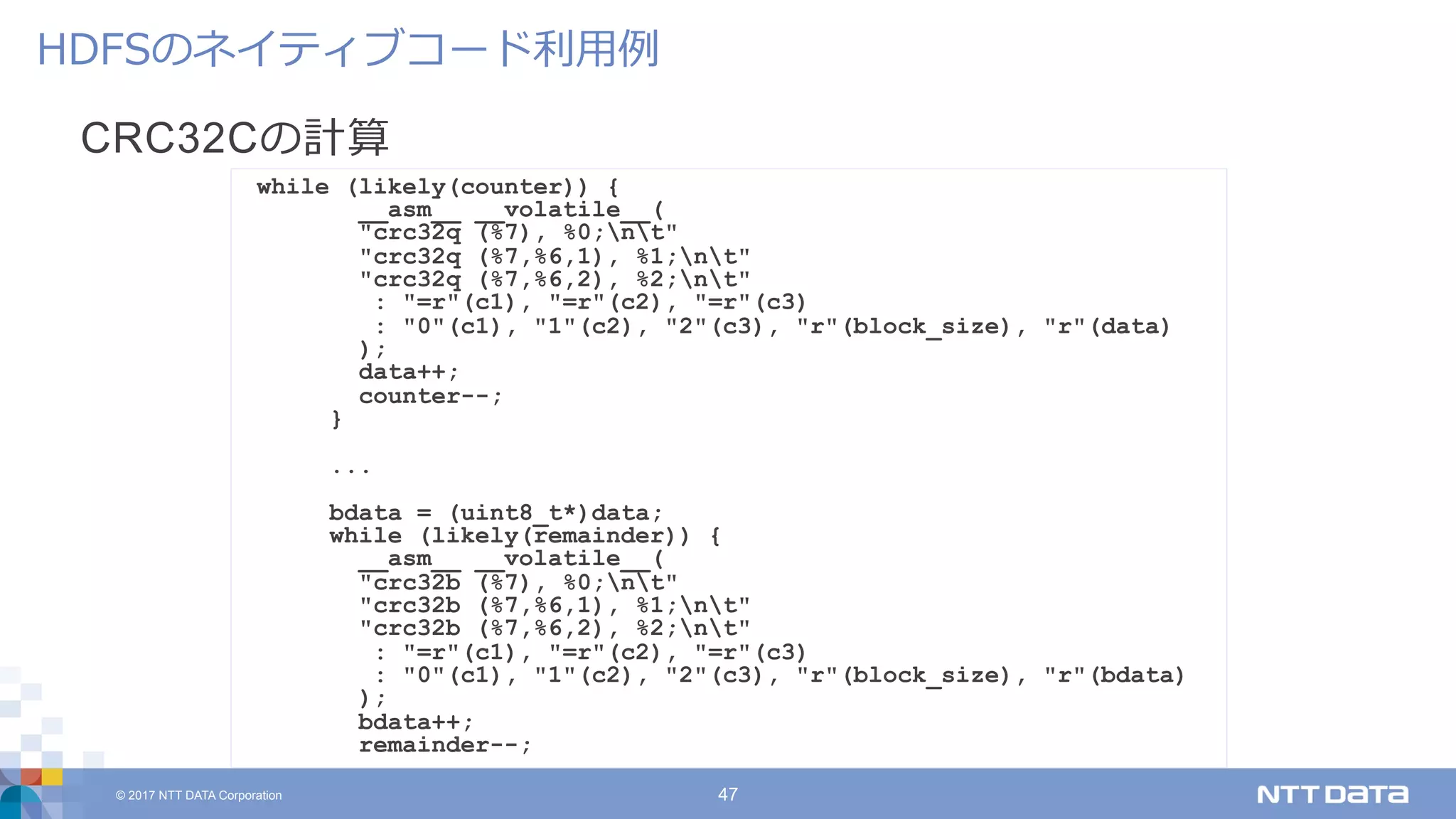
DATA Corporation 47 CRC32Cの計算 HDFSのネイティブコード利⽤例 while (likely(counter)) { __asm__ __volatile__( "crc32q (%7), %0;nt" "crc32q (%7,%6,1), %1;nt" "crc32q (%7,%6,2), %2;nt" : "=r"(c1), "=r"(c2), "=r"(c3) : "0"(c1), "1"(c2), "2"(c3), "r"(block_size), "r"(data) ); data++; counter--; } ... bdata = (uint8_t*)data; while (likely(remainder)) { __asm__ __volatile__( "crc32b (%7), %0;nt" "crc32b (%7,%6,1), %1;nt" "crc32b (%7,%6,2), %2;nt" : "=r"(c1), "=r"(c2), "=r"(c3) : "0"(c1), "1"(c2), "2"(c3), "r"(block_size), "r"(bdata) ); bdata++; remainder--;
48.
© 2017 NTT
DATA Corporation 48 Cで実装している部分はほぼない I/OはHDFSにお任せなため メモリ管理は課題 GCのオーバーヘッド ヒープサイズの上限 オフヒープ: ByteBuffer#allocateDirect ⾃分でメモリ管理するなら初めからC++で書く という気持ちは分かる気がしなくもない HBaseの場合
49.
© 2017 NTT
DATA Corporation 49 まとめ
50.
© 2017 NTT
DATA Corporation 50 APIとRPC ProtocolBuffers タイムアウトとリトライ REST API セキュリティ Kerberos SASL Delegation token 運⽤ツール CLI, shell Web UI, REST API logging, metrics Dependency management 今回とりあげなかった話題
51.
© 2017 NTT
DATA Corporation 51 現実的な運⽤に耐えるソフトウェア 多くのパーツが必要 安定するまで時間がかかる HDFSやHBaseはそれなりの時間をかけてきた Kuduもそこで得た知⾒を活かしている HDFS, HBase, Kudu 異なるワークロードに最適化 GFS, Bigtable, Spanner NoSQLの勃興とSQLへの回帰 アーキテクチャの試⾏錯誤 OSSで中が⾒えるとうれしい まとめ
52.
© 2017 NTT
DATA Corporation




























































































![[db tech showcase Tokyo 2015] B34:データの仮想化を具体化するIBMのロジカルデータウェアハウス by 日本アイ・ビー・エ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b34hadoopibm-150629025630-lva1-app6891-thumbnail.jpg?width=600ounds&width=560&fit=bounds)




















































