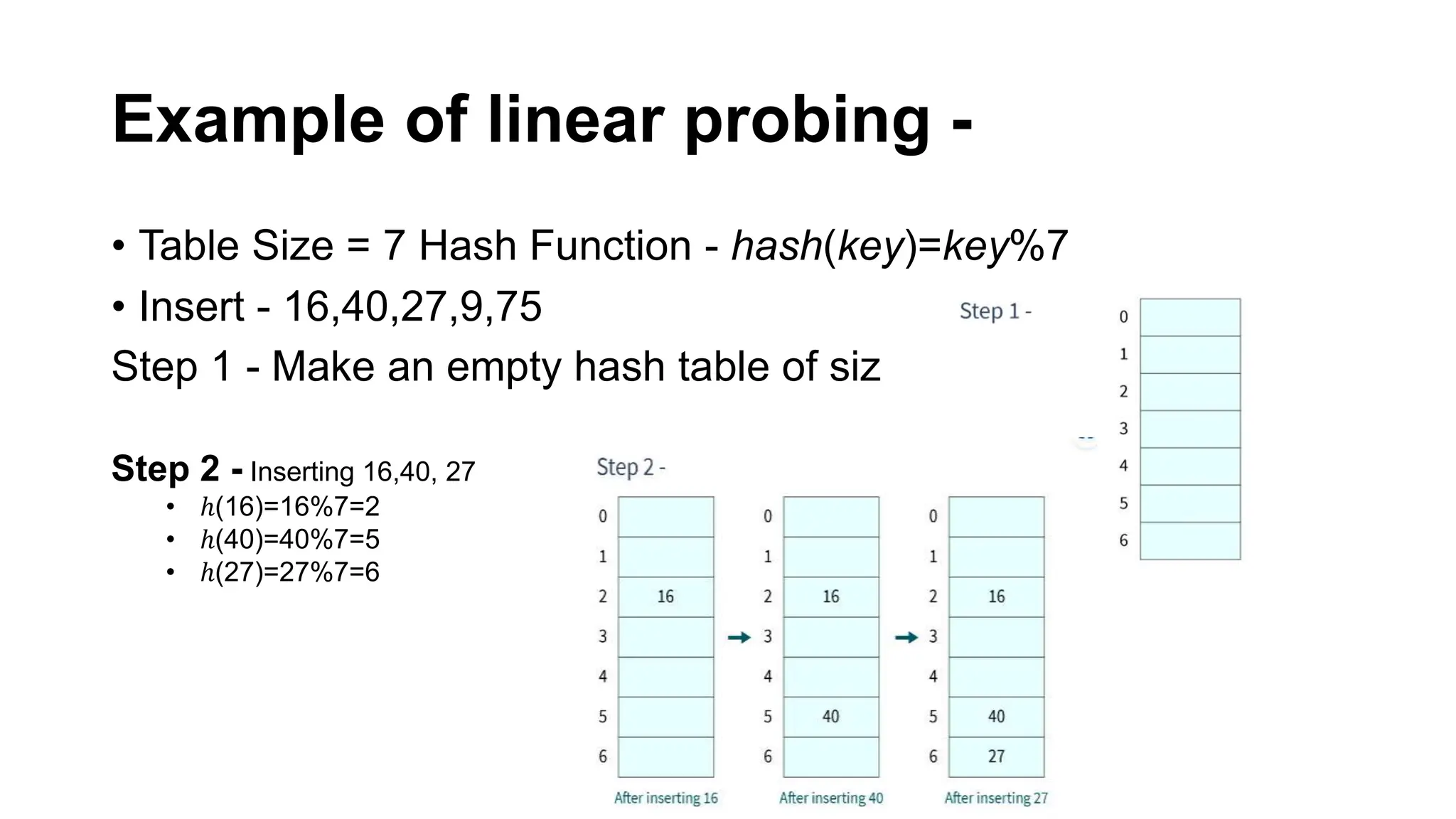
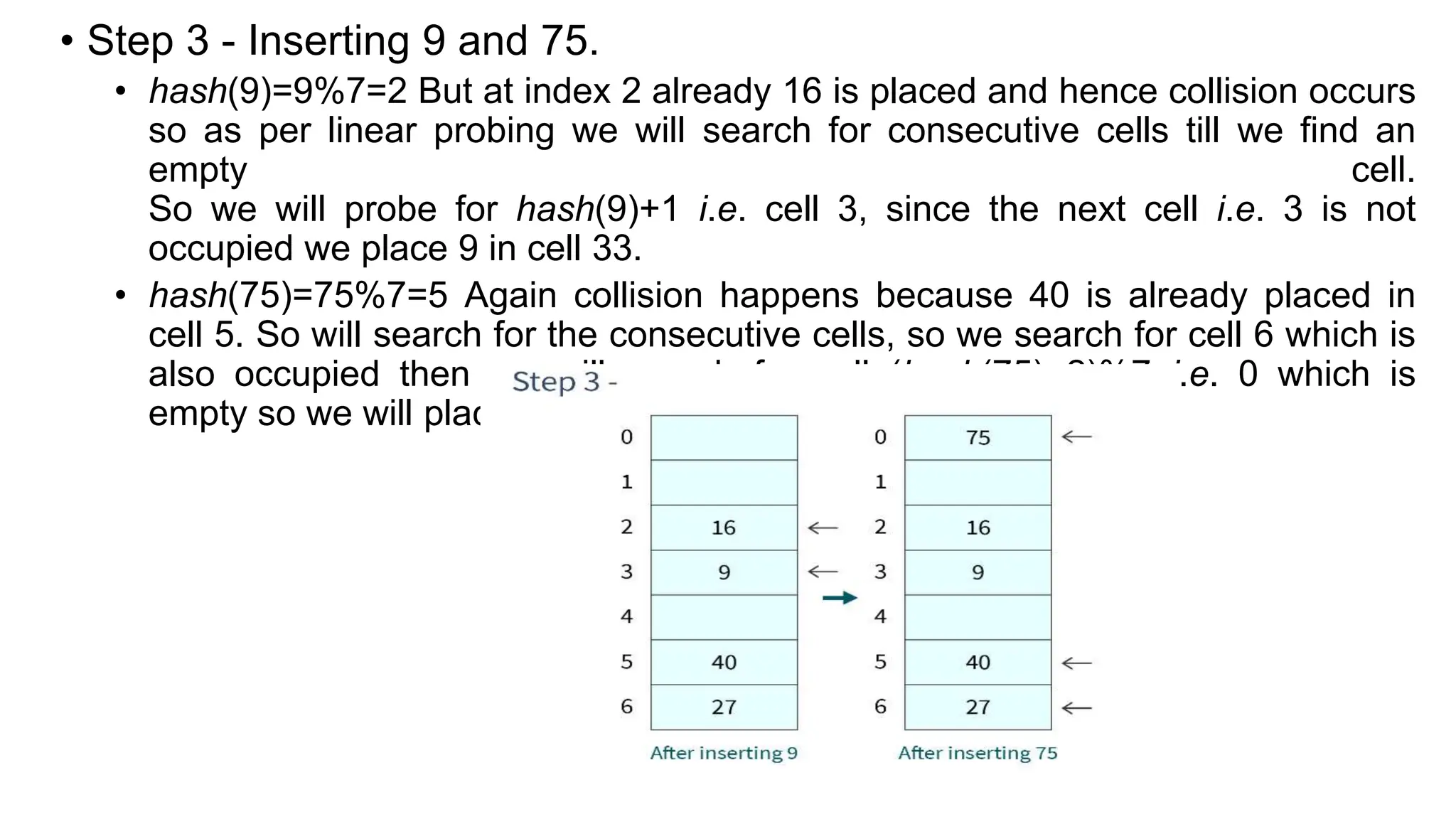
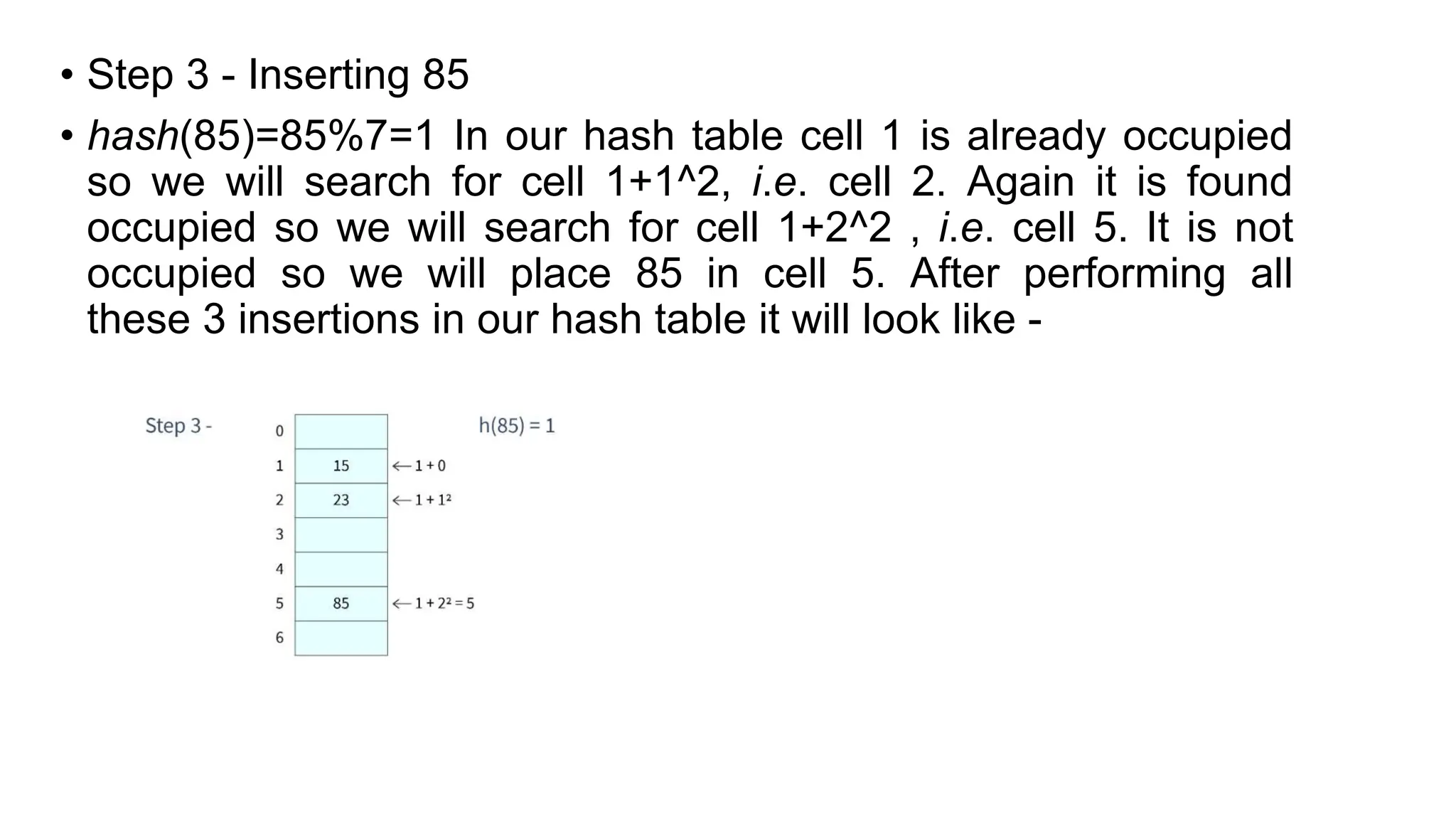
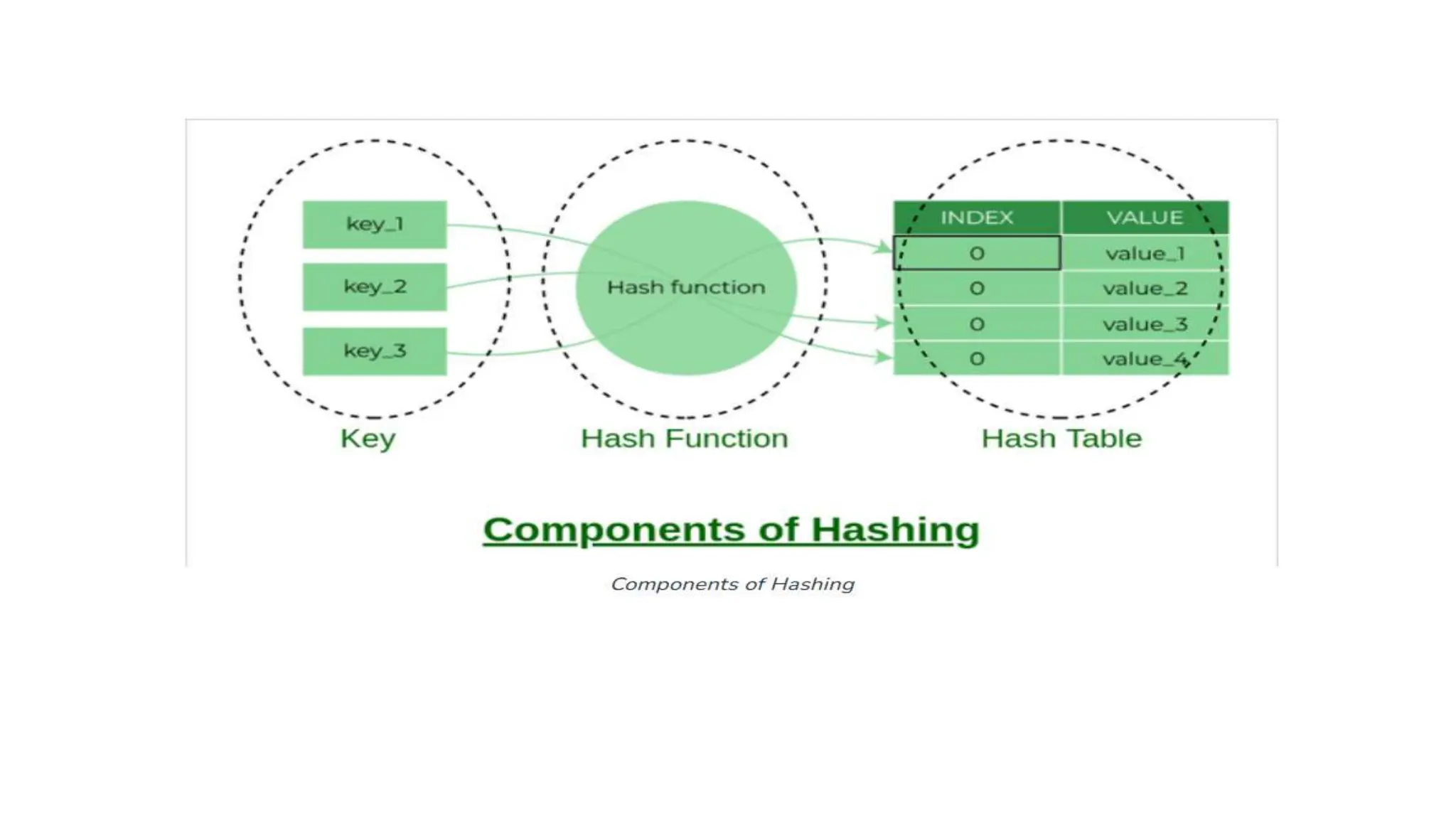
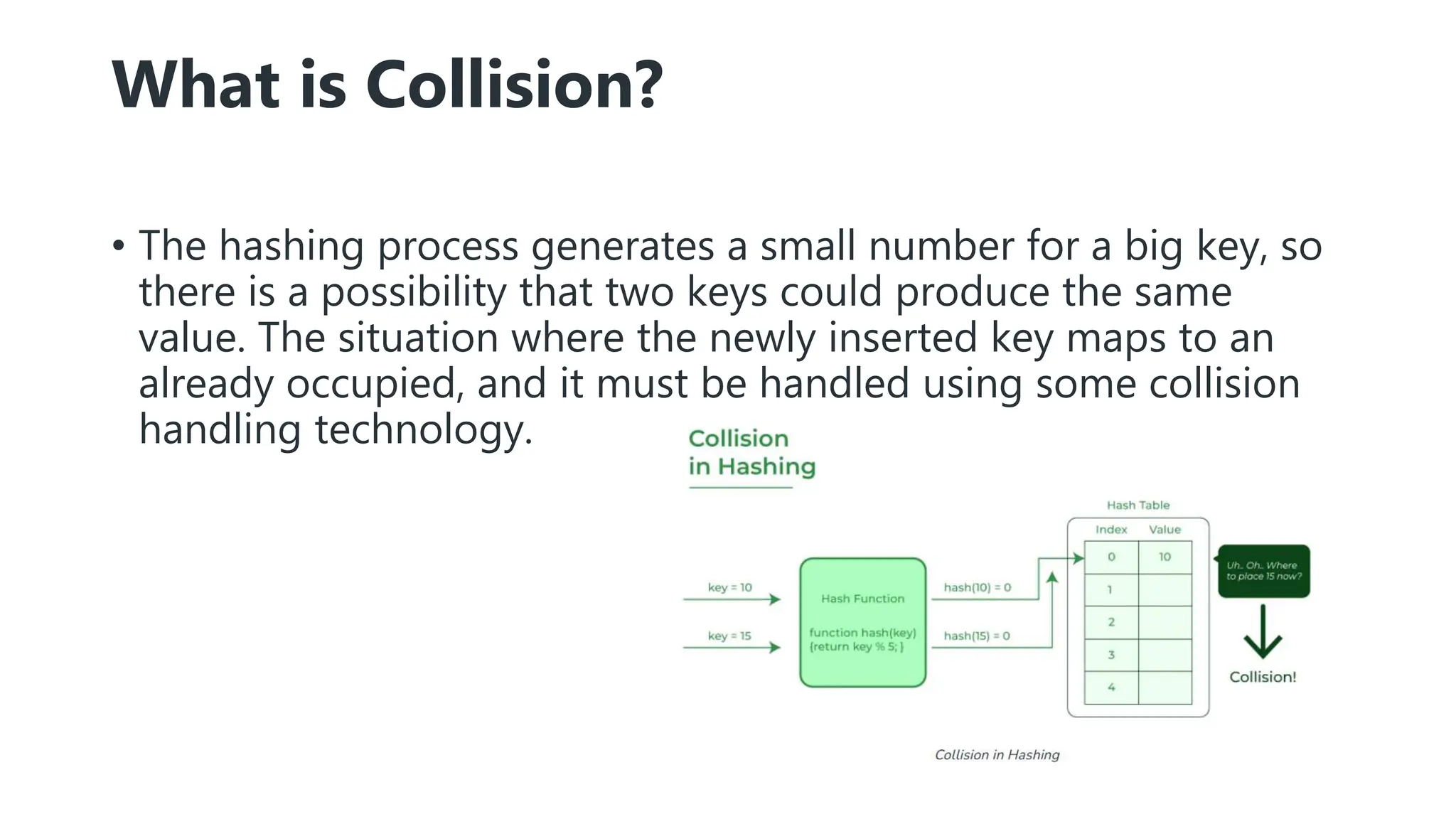
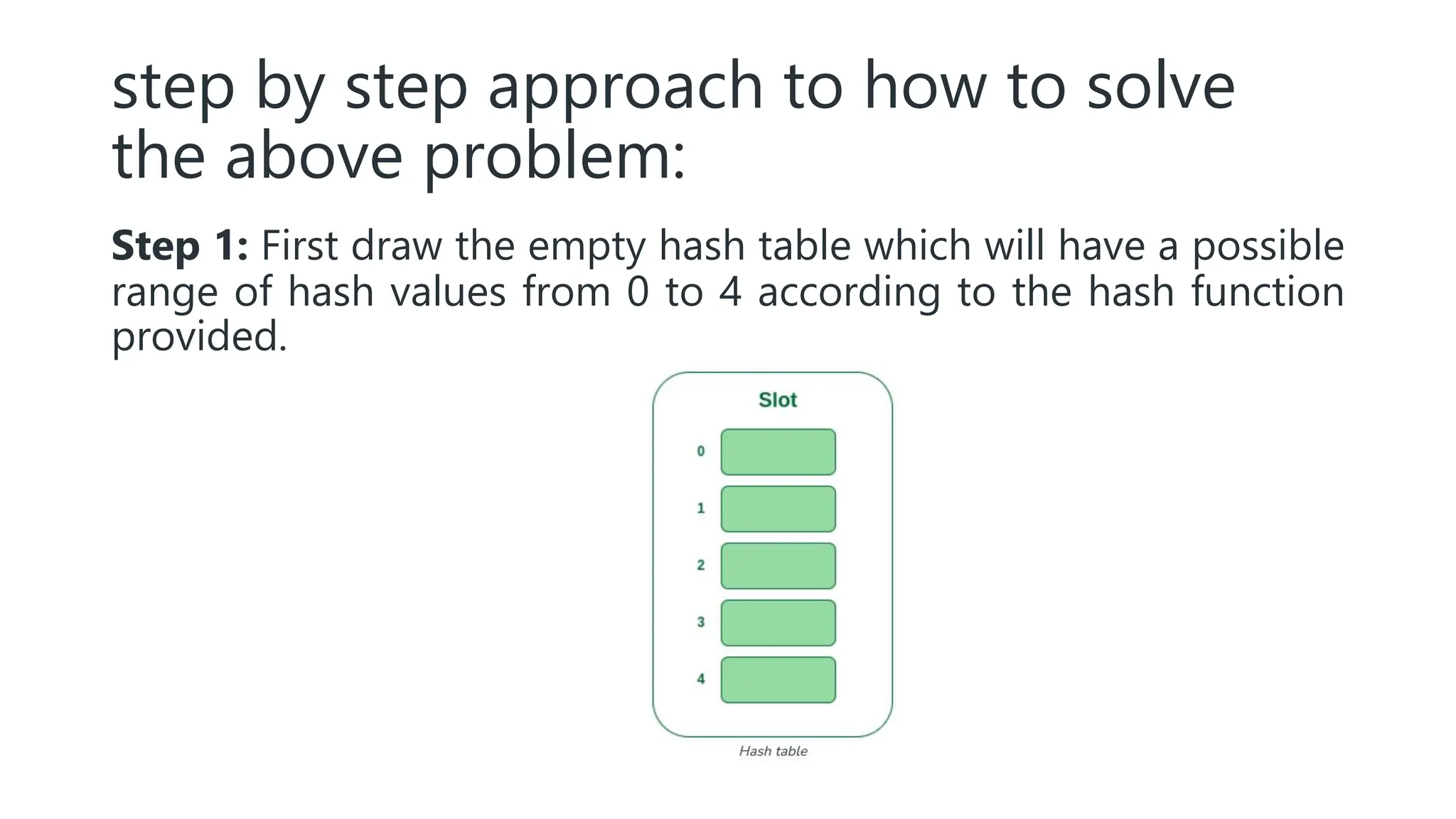
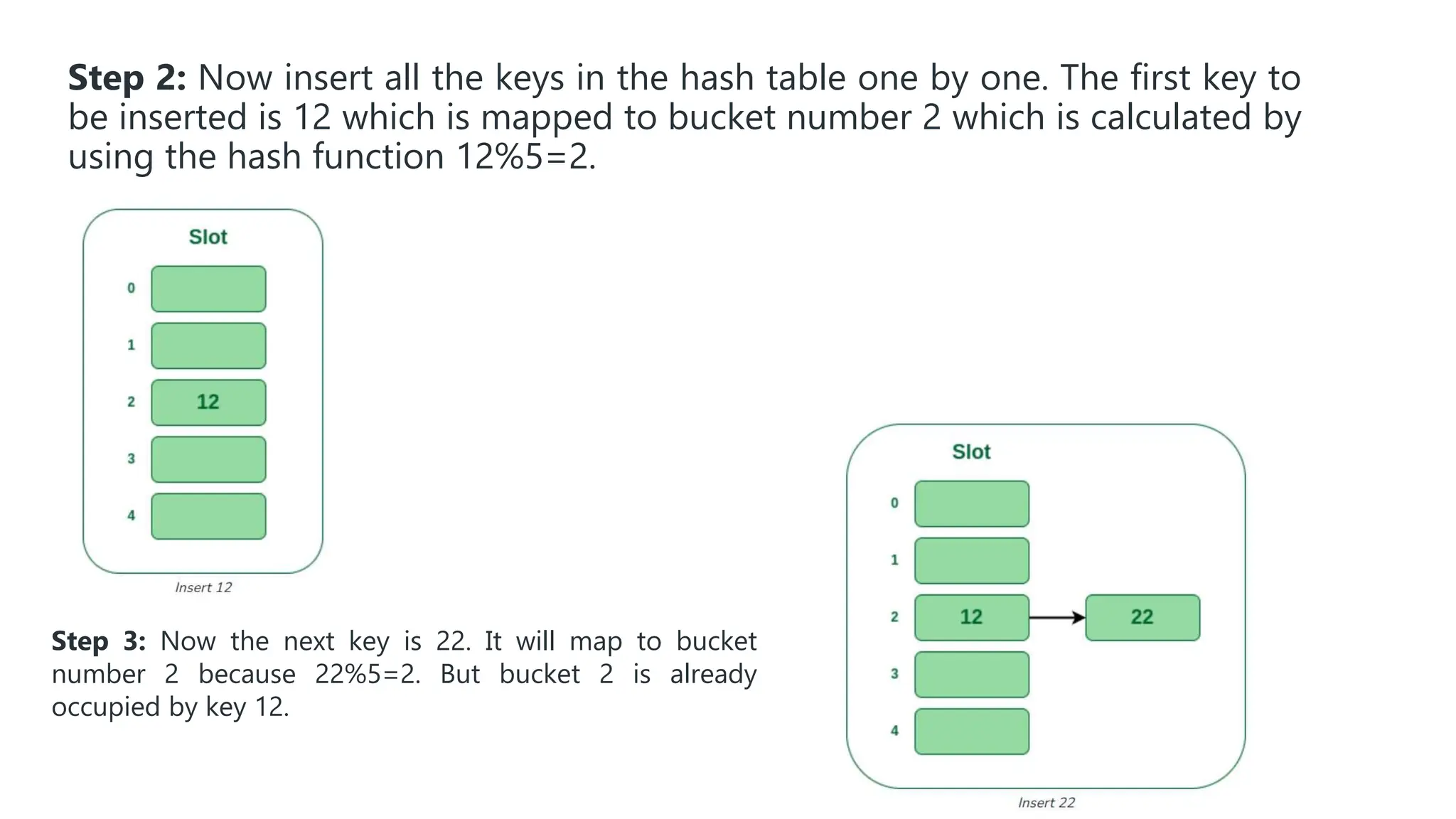
Hashing is a technique that maps values to a fixed-size key to uniquely identify elements, facilitating efficient data storage and retrieval. It utilizes hash functions to produce a hash code which acts as an index in a hash table for quick operations like insertion, deletion, and searching, ideally in constant time O(1). However, issues like collisions, where different keys generate the same hash value, require resolution strategies such as separate chaining and open addressing methods.











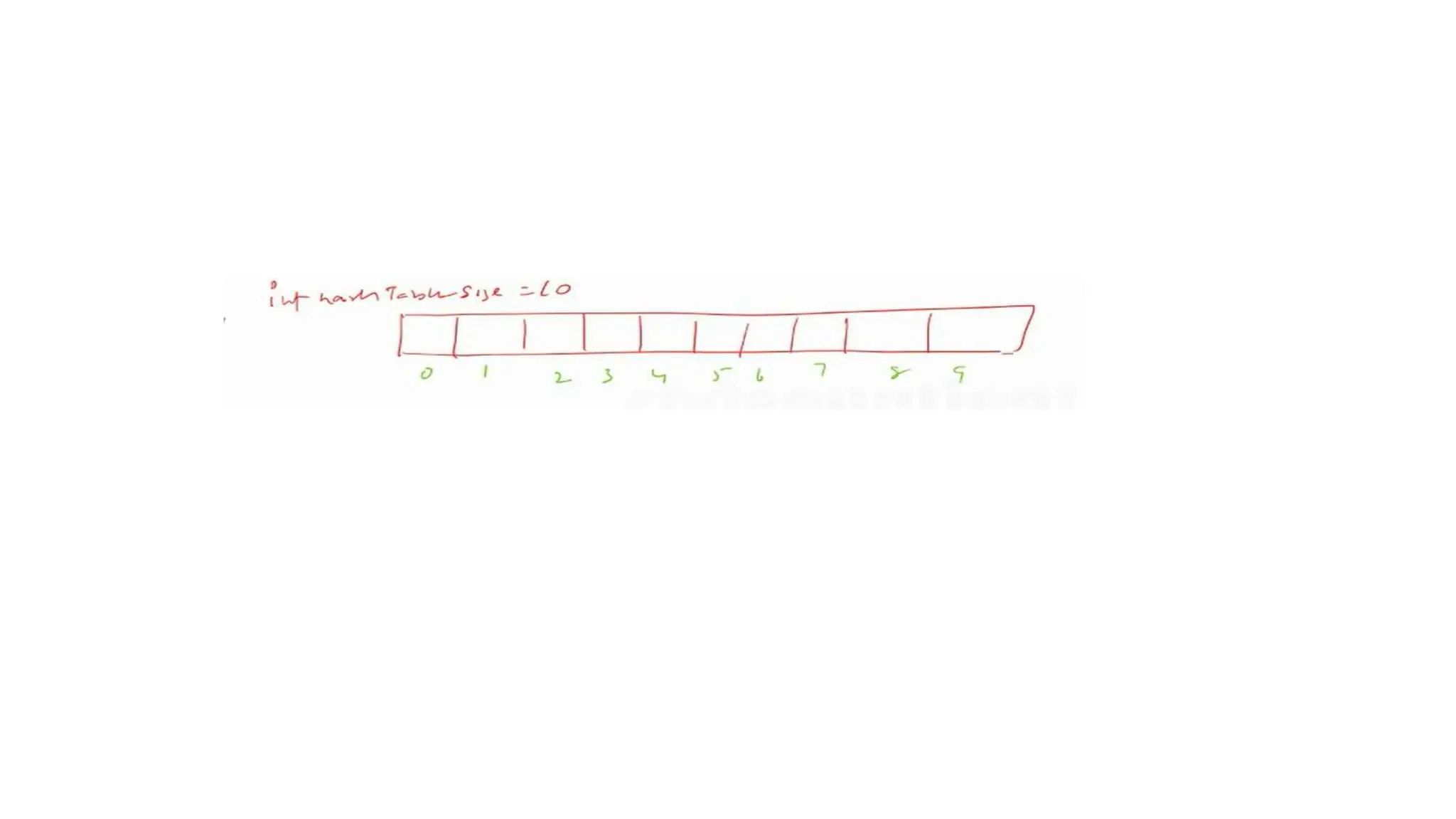
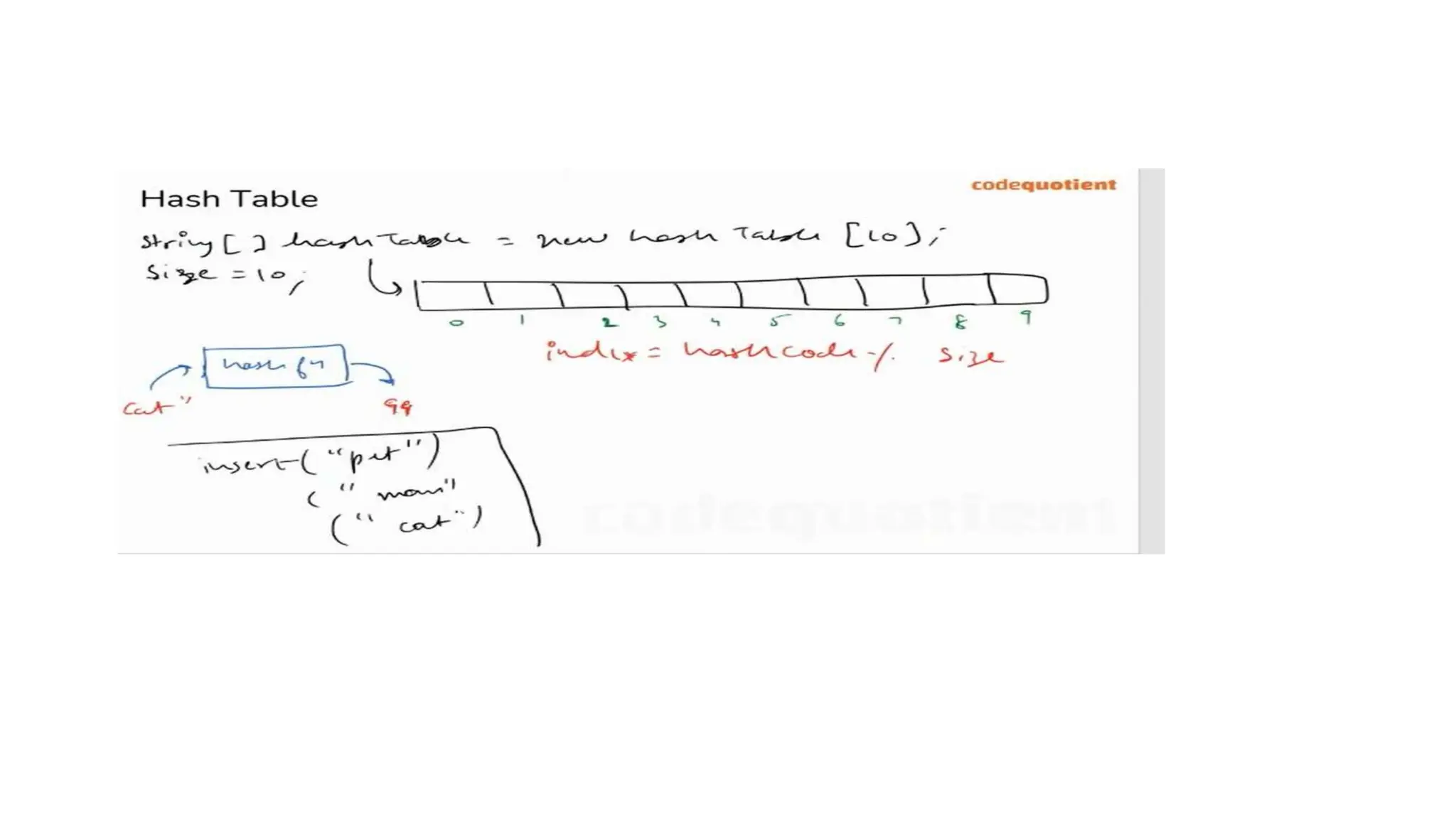
![int hashTable[10];
int hashTableSize = 10;
int hashFunction(int value)
{
return (value);
}
void Insert(int value)
{
//Compute the index using the hash function
int index= hashFunction(value) % hashTablesize;
//insert the value in the hashtable at the computed index
hashTable[index]=value;
}
void search(int value)
{
//Compute the index uing the Hash function
int index=hashFunction(value) % hashTableSize;
//Check the value in the hashTable present the computed index
if (hashTable[index]==value)
printf(“found”);
else printf("not found");
}](https://image.slidesharecdn.com/adihashing-240509043017-ed4e50b3/85/hashing-in-data-strutures-advanced-in-languae-java-13-320.jpg)









![Pseudocode for Linear Probing
class Hashing:
size, table[]
Hash(x):
return x%size
Insert(x):
k=Hash(x)
while(table[k] is not empty):
k=(k+1)%size
table[k]=x
Search(x):
k=Hash(x)
while(table[k] != x):
if(table[k] has never been occupied):
return false
k=(k+1)%size
return table[k]==x
Delete(x):
k=Hash(x)
while(table[k]!=x):
if(table[k] has never been occupied):
return
k=(k+1)%size
if(table[k]==x):
table[k] = -Infinity](https://image.slidesharecdn.com/adihashing-240509043017-ed4e50b3/85/hashing-in-data-strutures-advanced-in-languae-java-27-320.jpg)
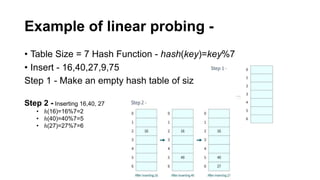













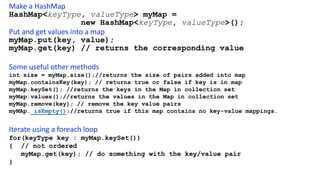















![int hashTable[10];
int hashTableSize = 10;
int hashFunction(int value)
{
return (value);
}
void Insert(int value)
{
//Compute the index using the hash function
int index= hashFunction(value) % hashTablesize;
//insert the value in the hashtable at the computed index
hashTable[index]=value;
}
void search(int value)
{
//Compute the index uing the Hash function
int index=hashFunction(value) % hashTableSize;
//Check the value in the hashTable present the computed index
if (hashTable[index]==value)
printf(“found”);
else printf("not found");
}](https://image.slidesharecdn.com/adihashing-240509043017-ed4e50b3/75/hashing-in-data-strutures-advanced-in-languae-java-13-2048.jpg)








![Pseudocode for Linear Probing
class Hashing:
size, table[]
Hash(x):
return x%size
Insert(x):
k=Hash(x)
while(table[k] is not empty):
k=(k+1)%size
table[k]=x
Search(x):
k=Hash(x)
while(table[k] != x):
if(table[k] has never been occupied):
return false
k=(k+1)%size
return table[k]==x
Delete(x):
k=Hash(x)
while(table[k]!=x):
if(table[k] has never been occupied):
return
k=(k+1)%size
if(table[k]==x):
table[k] = -Infinity](https://image.slidesharecdn.com/adihashing-240509043017-ed4e50b3/75/hashing-in-data-strutures-advanced-in-languae-java-27-2048.jpg)