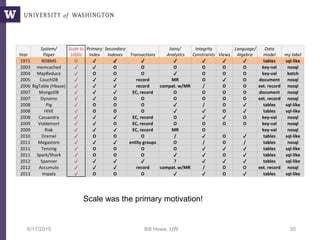
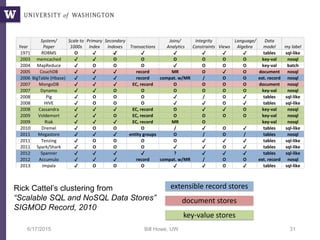
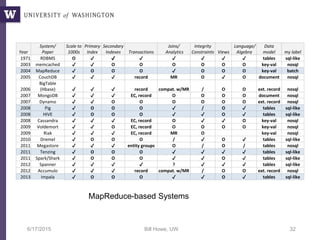
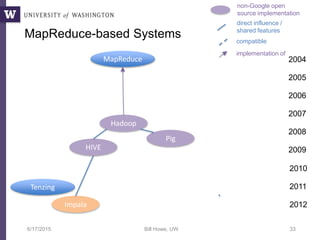
Downloaded 66 times


![6/17/2015 Bill Howe, UW 5
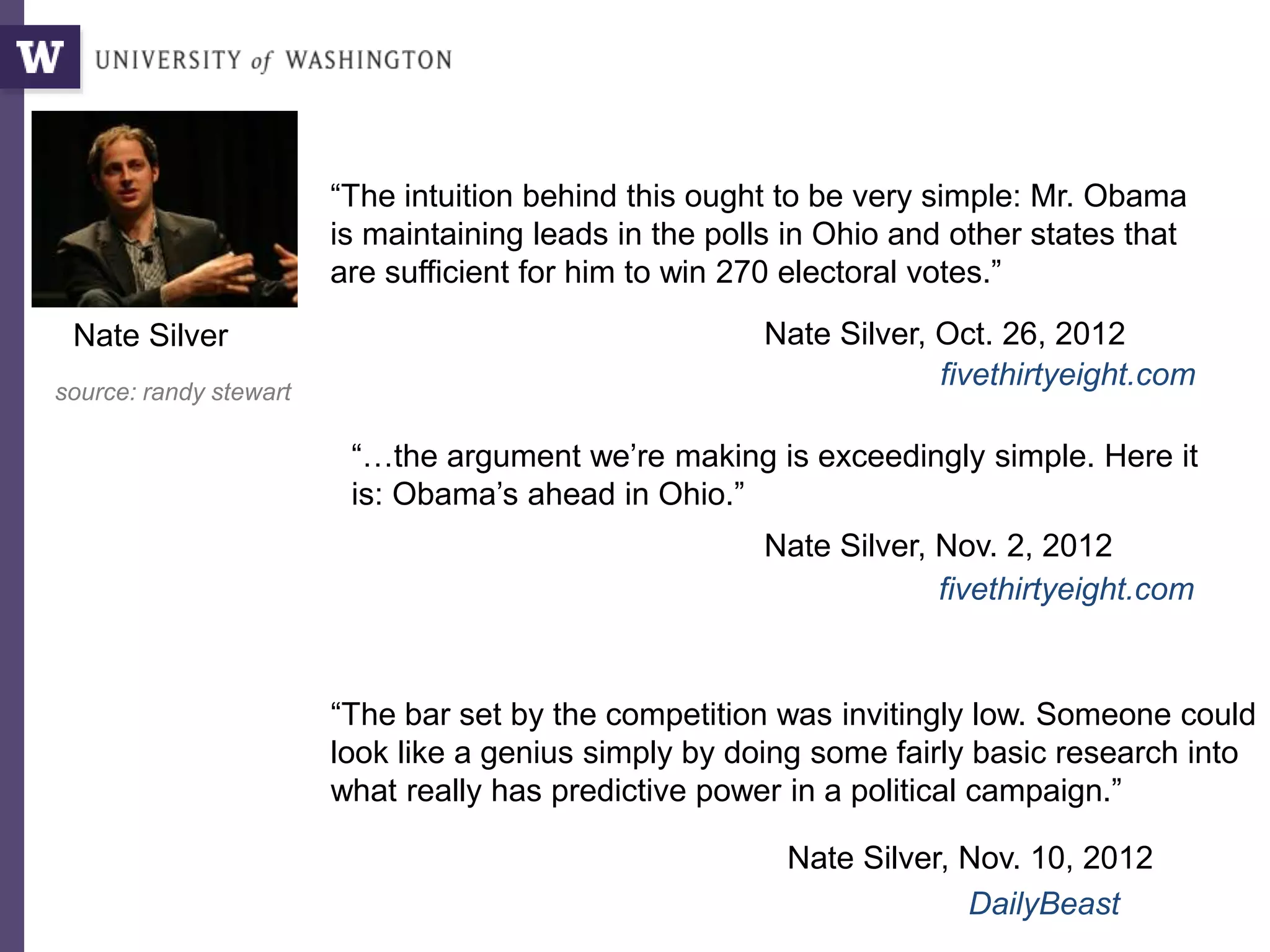
“…the biggest win came from good old SQL on a Vertica data
warehouse and from providing access to data to dozens of
analytics staffers who could follow their own curiosity and
distill and analyze data as they needed.”
Dan Woods
Jan 13 2013, CITO Research
“The decision was made to have Hadoop do the aggregate generations
and anything not real-time, but then have Vertica to answer sort of
‘speed-of-thought’ queries about all the data.”
Josh Hendler, CTO of H & K Strategies
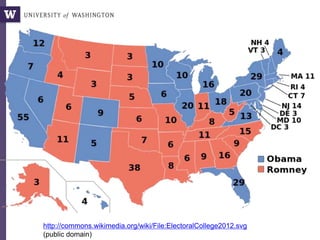
Related: Obama campaign’s data-driven ground game
"In the 21st century, the candidate with [the] best data,
merged with the best messages dictated by that data, wins.”
Andrew Rasiej, Personal Democracy Forum](https://image.slidesharecdn.com/dssgdatasciencejune2015-150617175007-lva1-app6891/85/Intro-to-Data-Science-Concepts-5-320.jpg)
























![6/17/2015 Bill Howe, UW 5
“…the biggest win came from good old SQL on a Vertica data
warehouse and from providing access to data to dozens of
analytics staffers who could follow their own curiosity and
distill and analyze data as they needed.”
Dan Woods
Jan 13 2013, CITO Research
“The decision was made to have Hadoop do the aggregate generations
and anything not real-time, but then have Vertica to answer sort of
‘speed-of-thought’ queries about all the data.”
Josh Hendler, CTO of H & K Strategies
Related: Obama campaign’s data-driven ground game
"In the 21st century, the candidate with [the] best data,
merged with the best messages dictated by that data, wins.”
Andrew Rasiej, Personal Democracy Forum](https://image.slidesharecdn.com/dssgdatasciencejune2015-150617175007-lva1-app6891/75/Intro-to-Data-Science-Concepts-5-2048.jpg)

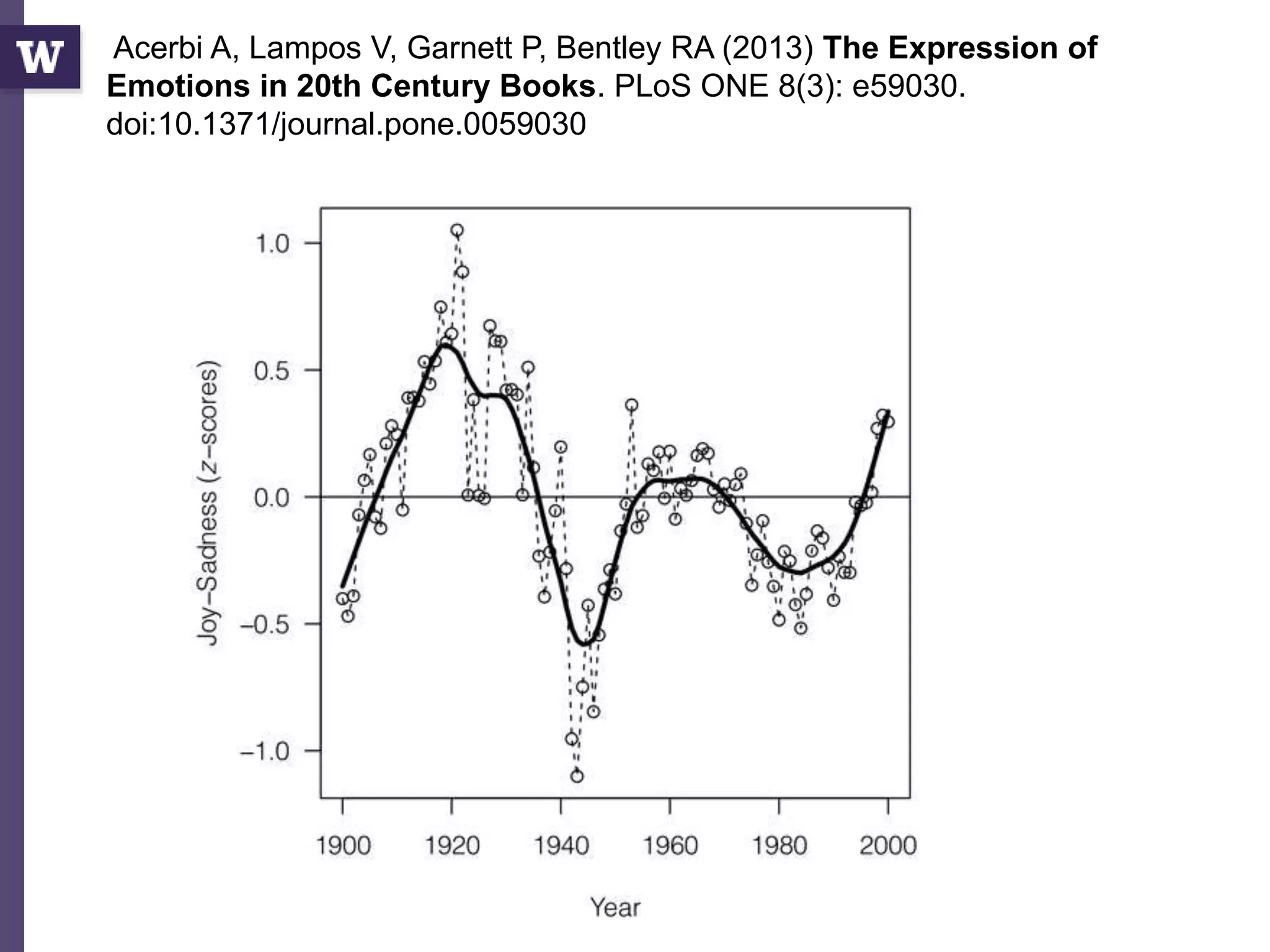
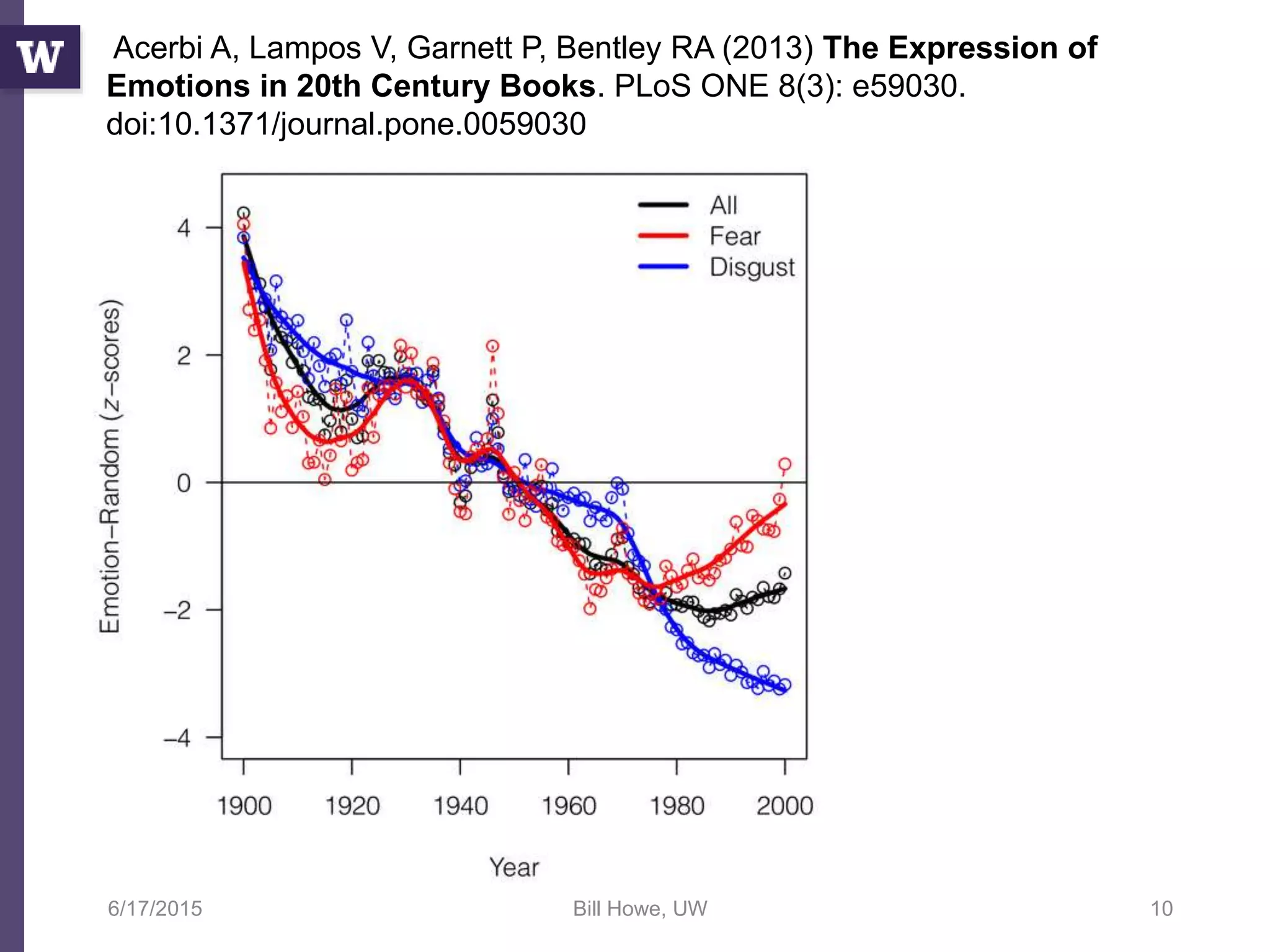


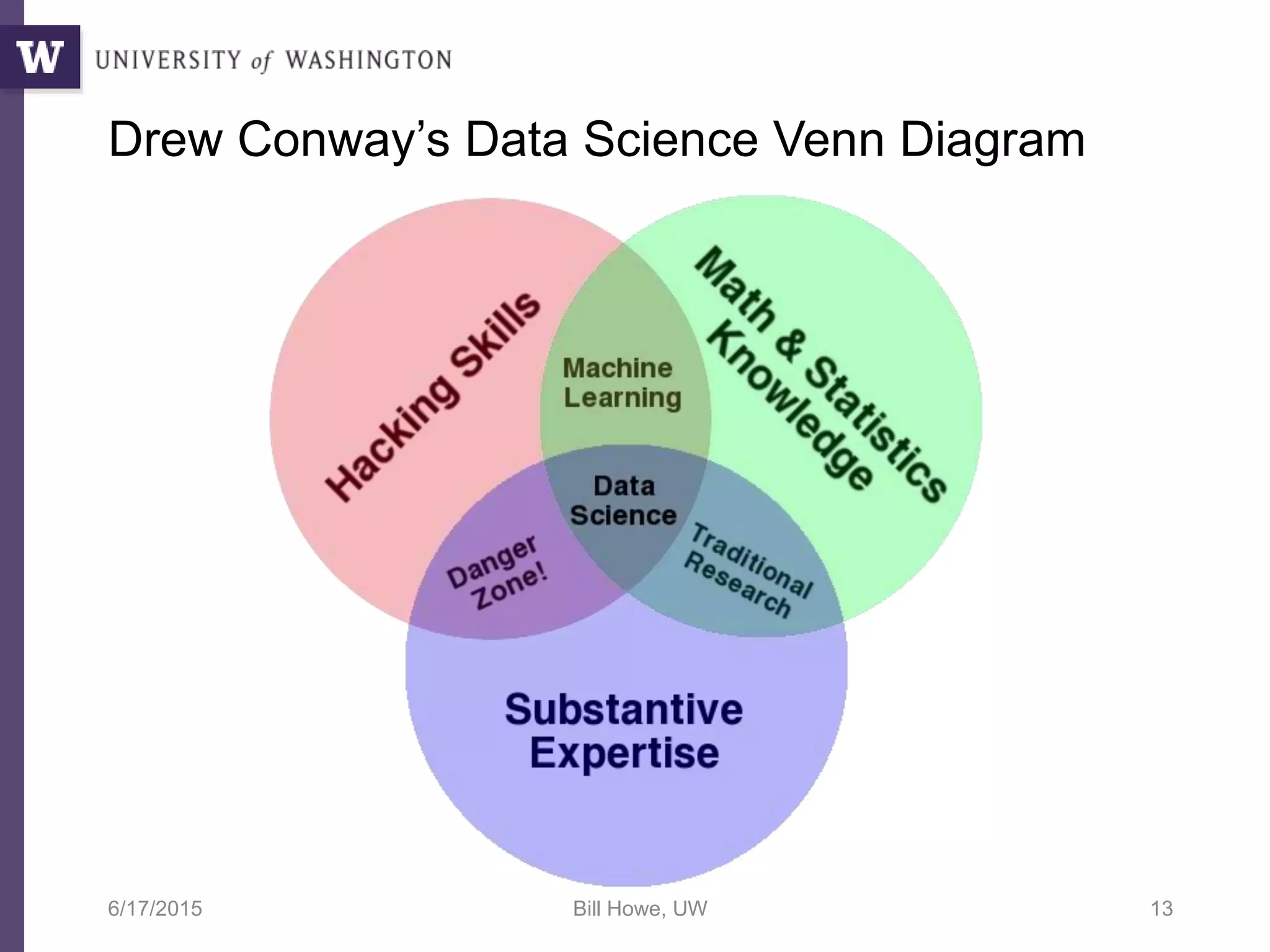










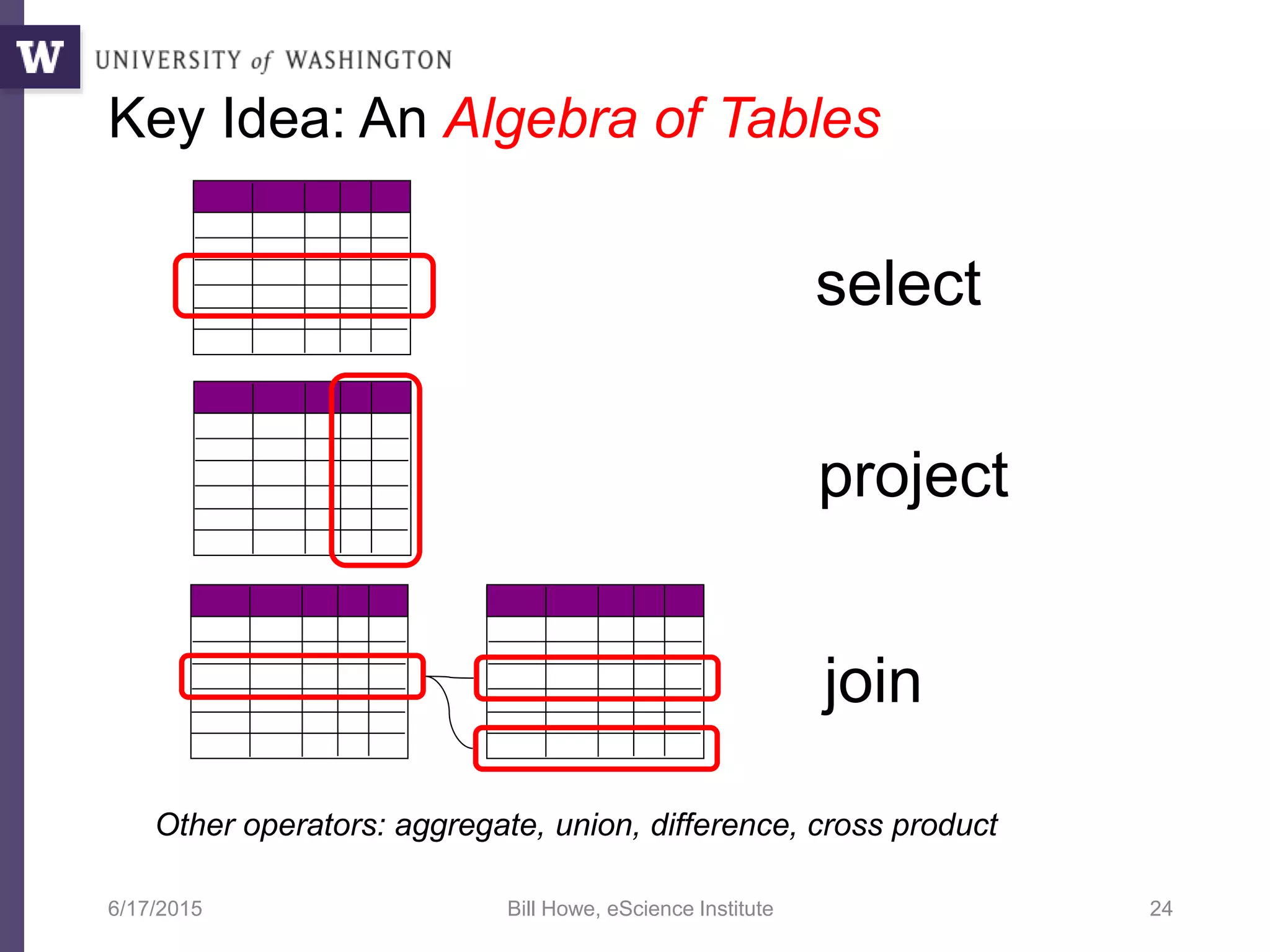




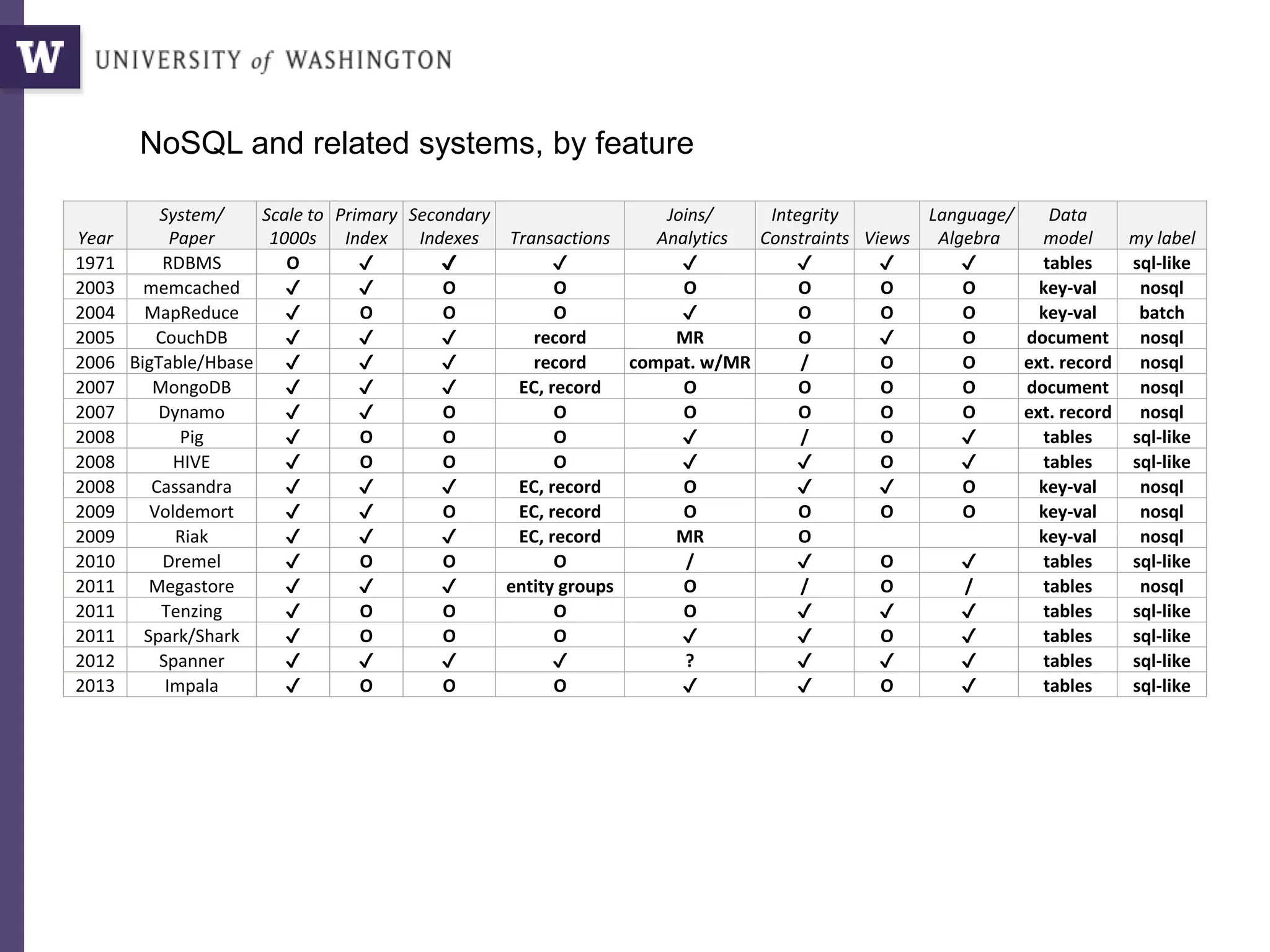

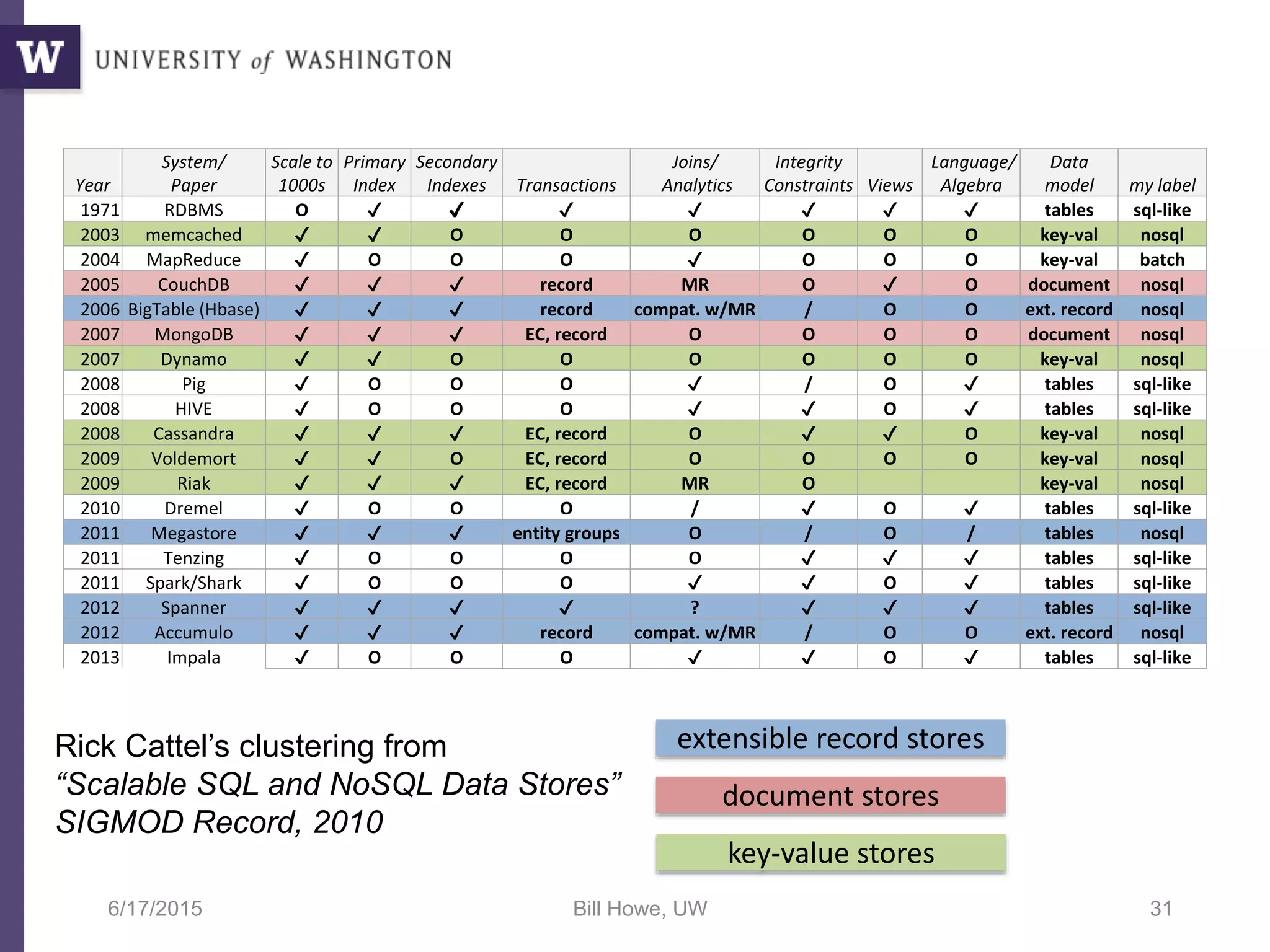
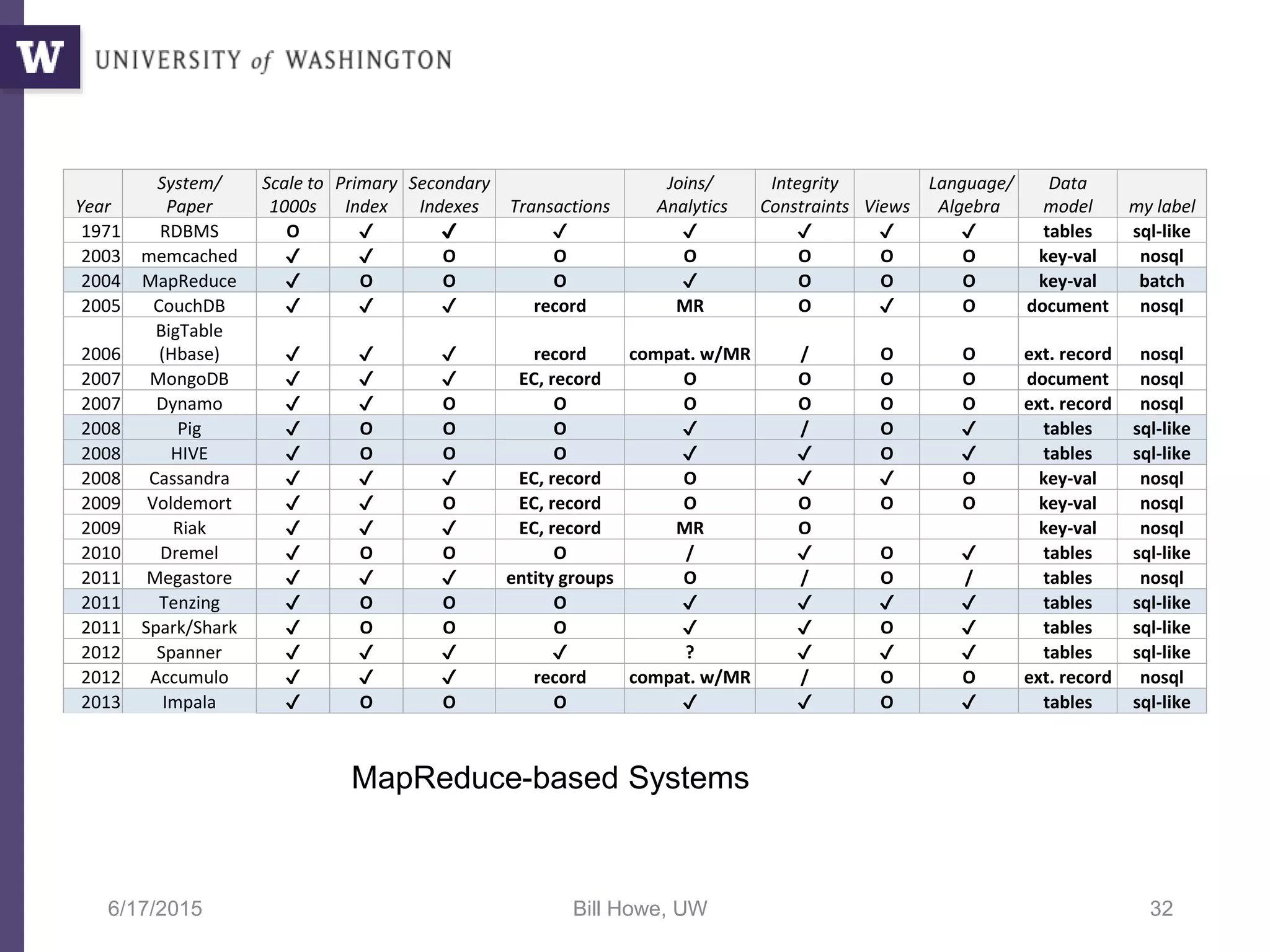
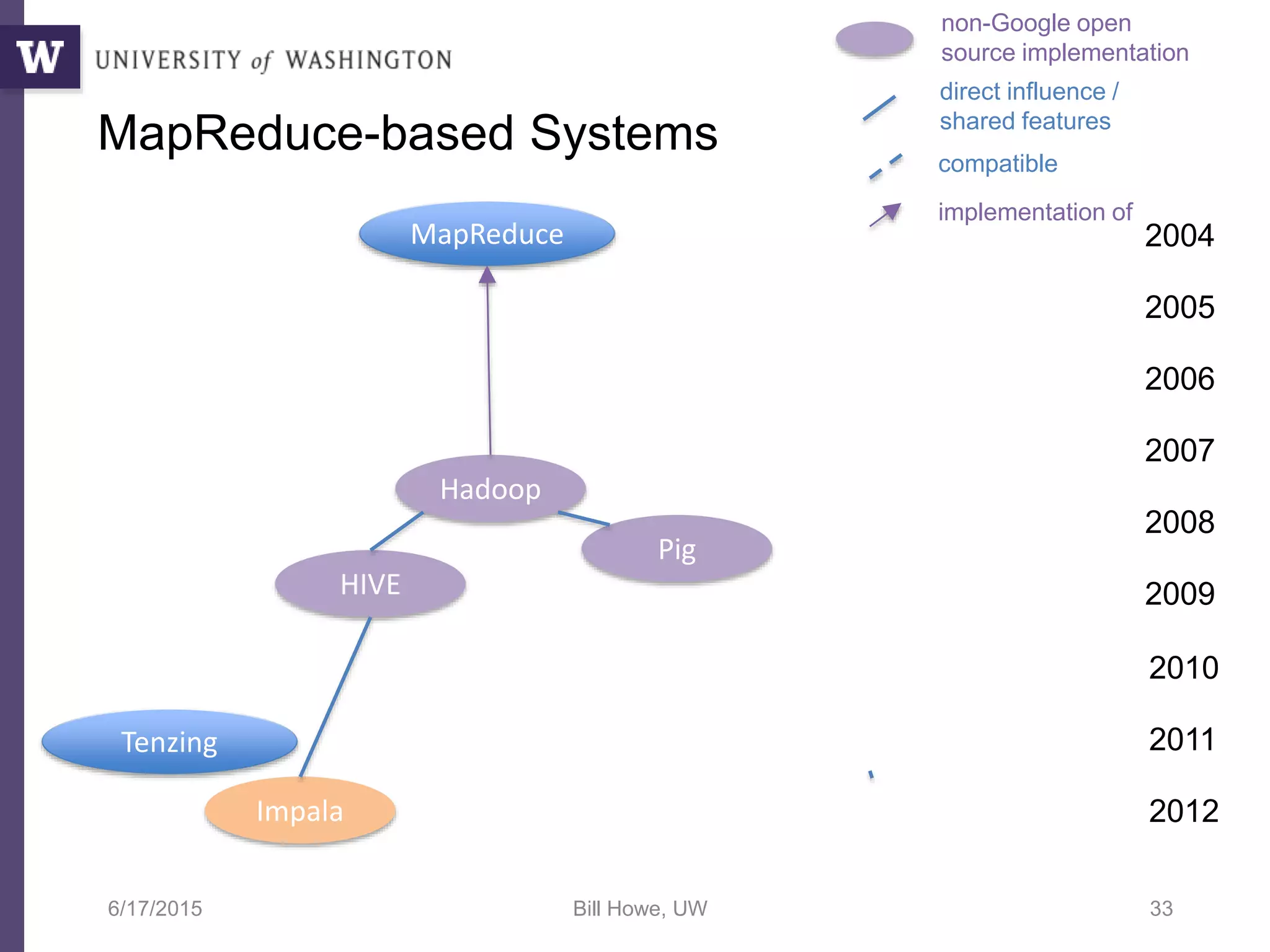
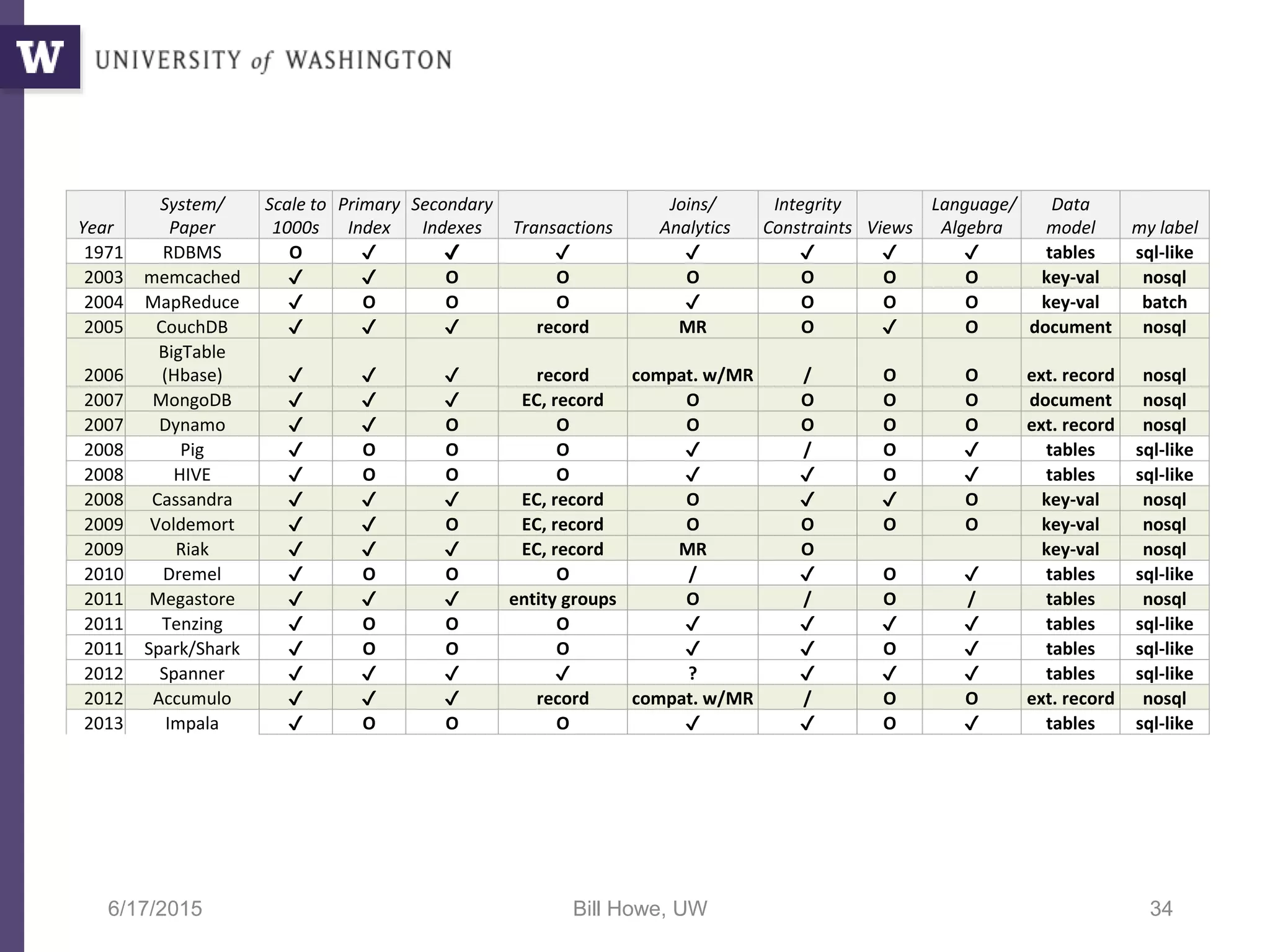
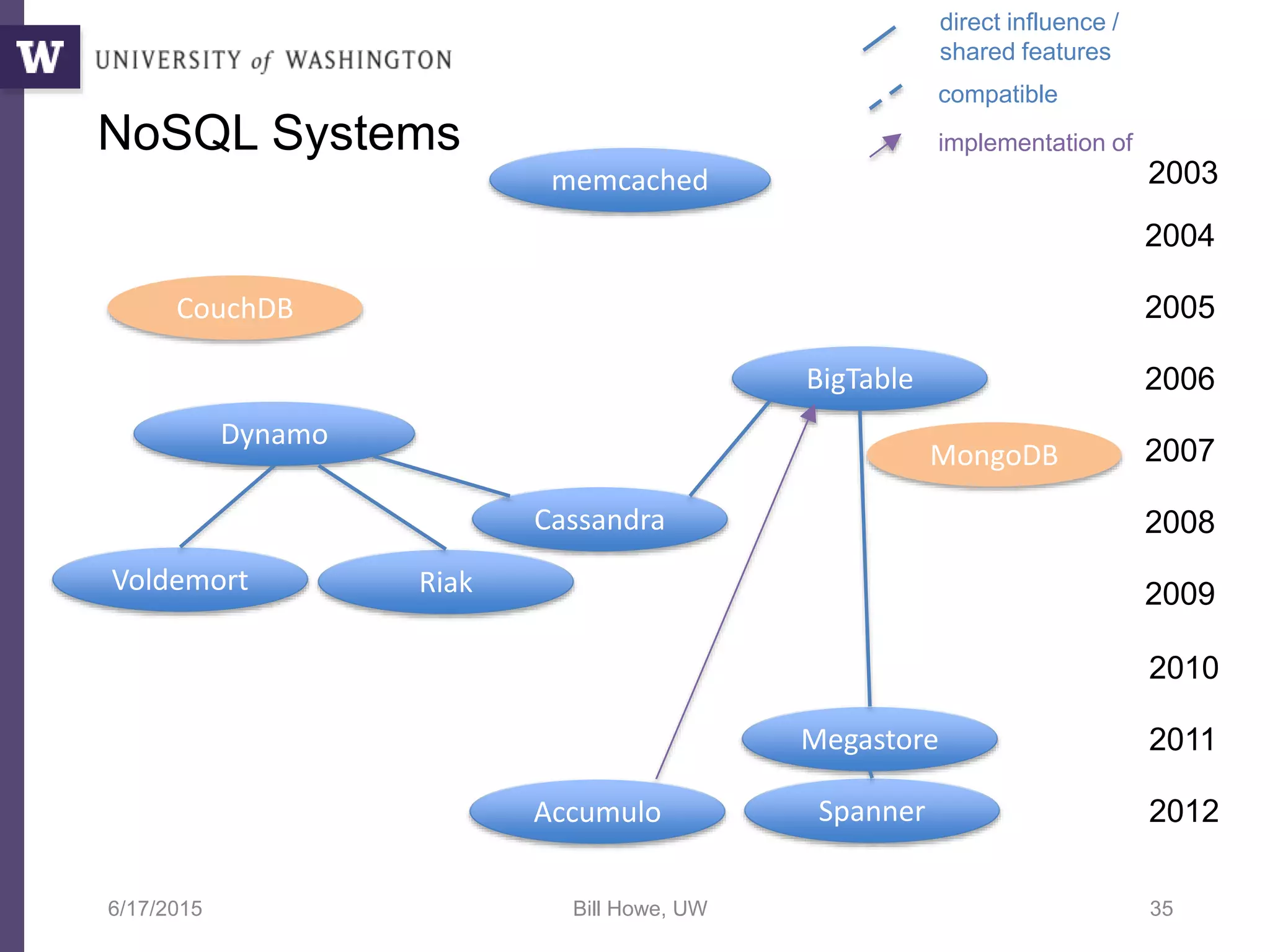
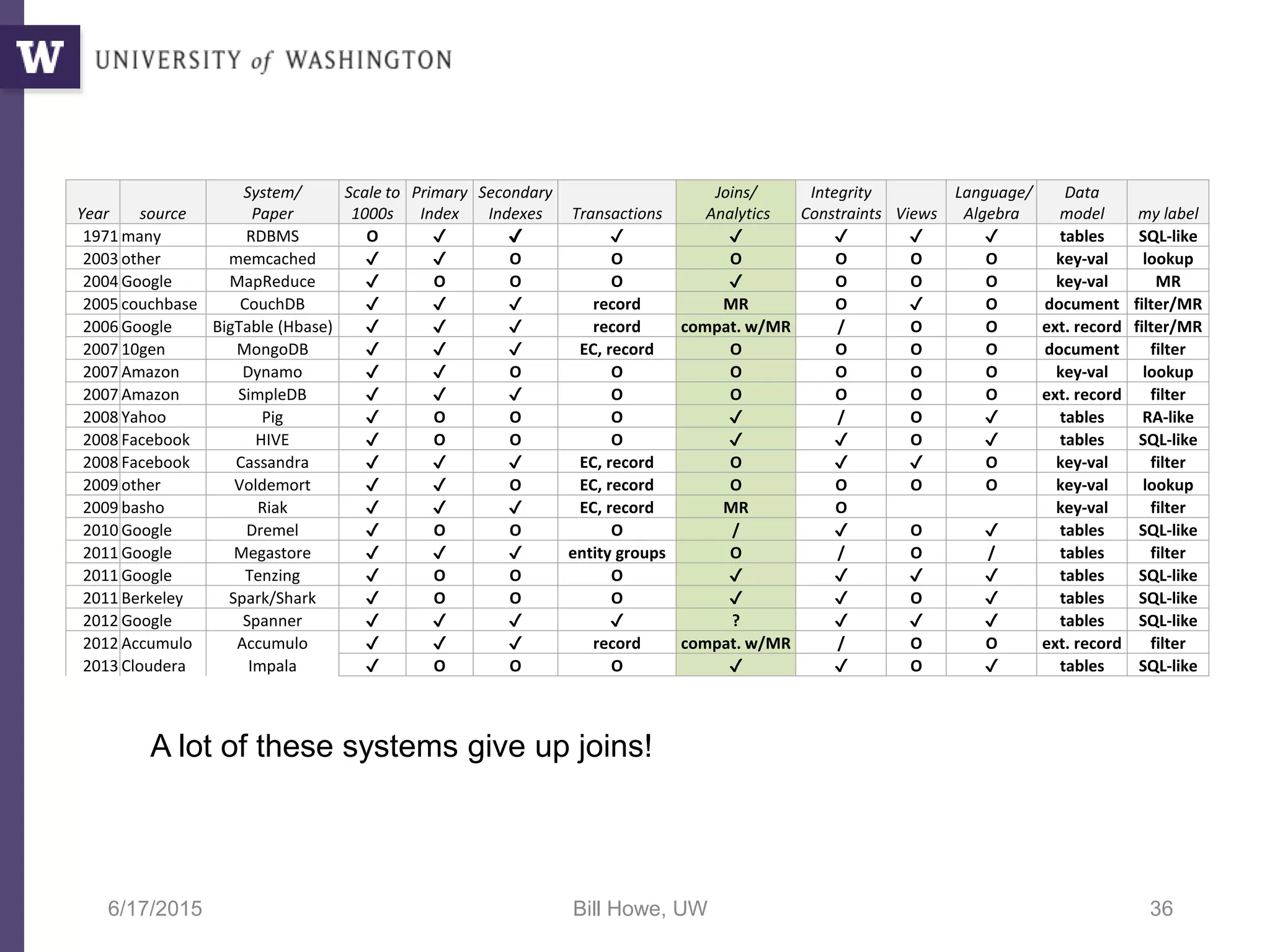

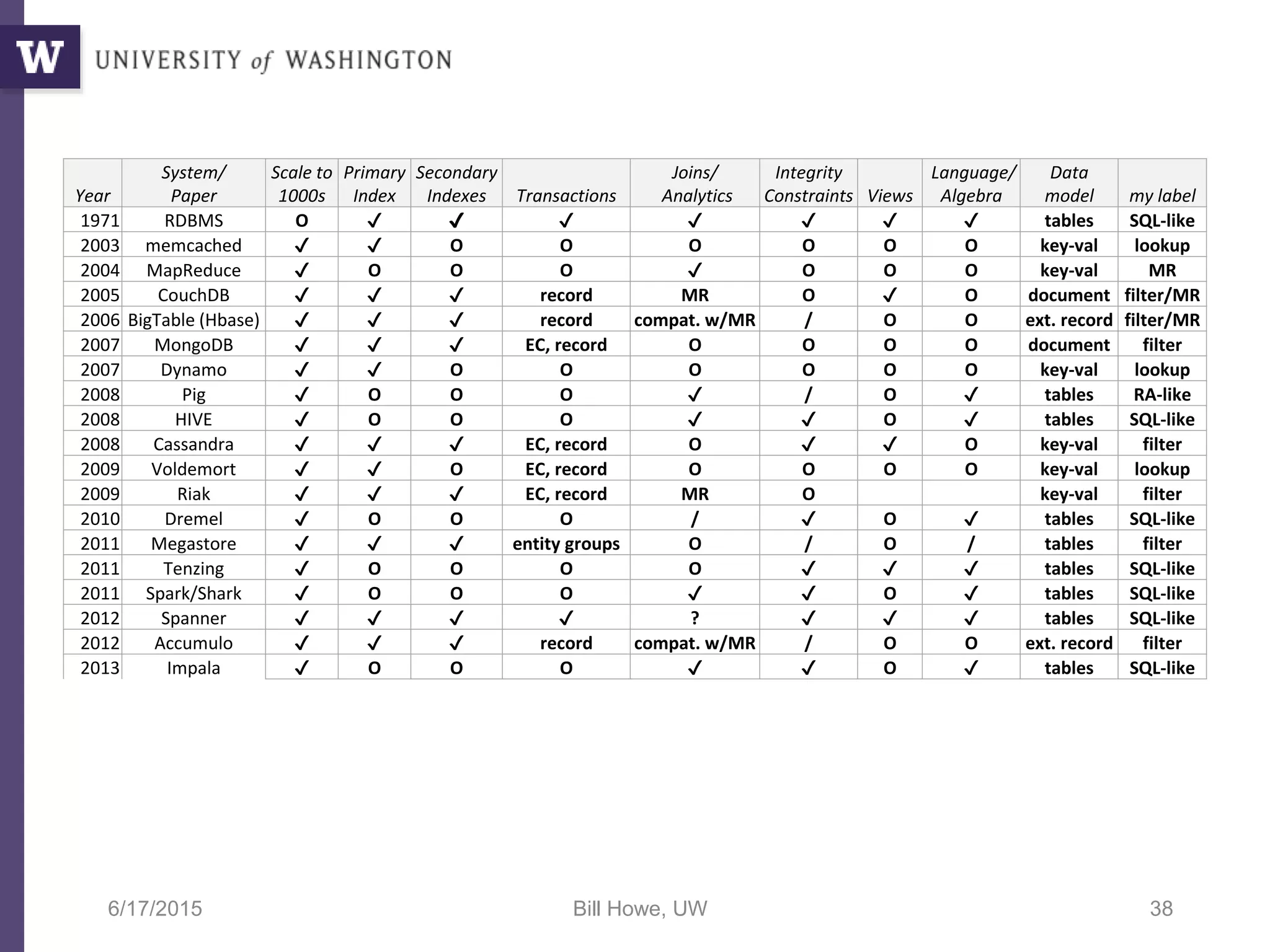




The document discusses data science, defining it as an area concerned with the collection, analysis, visualization, and management of large datasets, emphasizing the importance of understanding and processing data effectively. It examines the role of data scientists and the methodologies they employ, including relational algebra and various data management systems. Key figures in the field highlight the need for data-driven apps and products that empower users to analyze data independently.














![Big Data [sorry] & Data Science: What Does a Data Scientist Do?](https://cdn.slidesharecdn.com/ss_thumbnails/dslatcloudmsevent20130125-130126065651-phpapp01-thumbnail.jpg?width=600ounds&width=560&fit=bounds)








































































![Agentic Systems and Compliance - A brief intro [1.2]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticsystemsandcompliace-1-251018025303-958a42ec-thumbnail.jpg?width=600ounds&width=560&fit=bounds)


















