Downloaded 786 times
















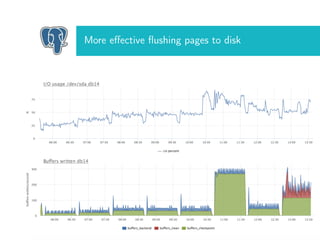











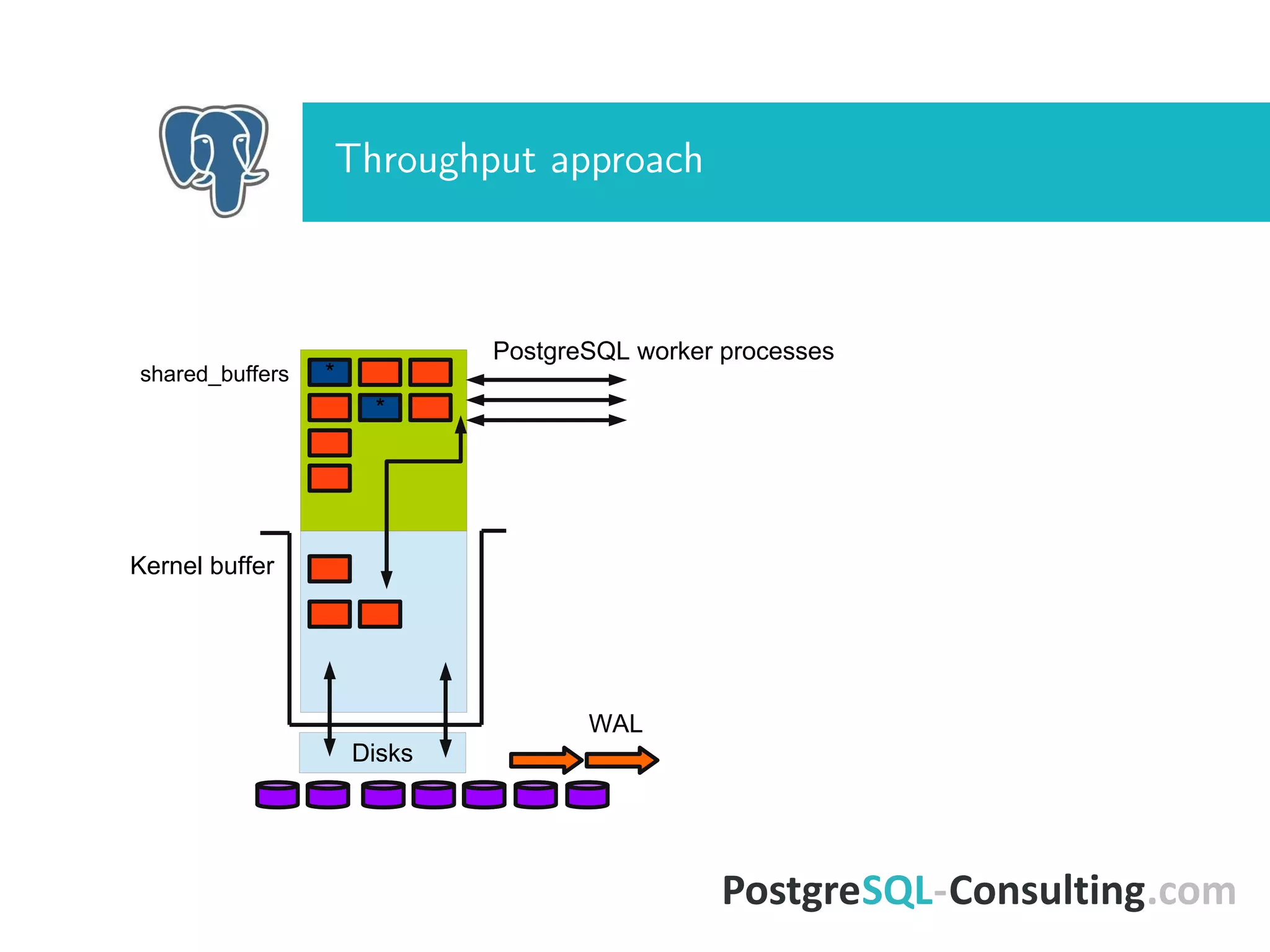












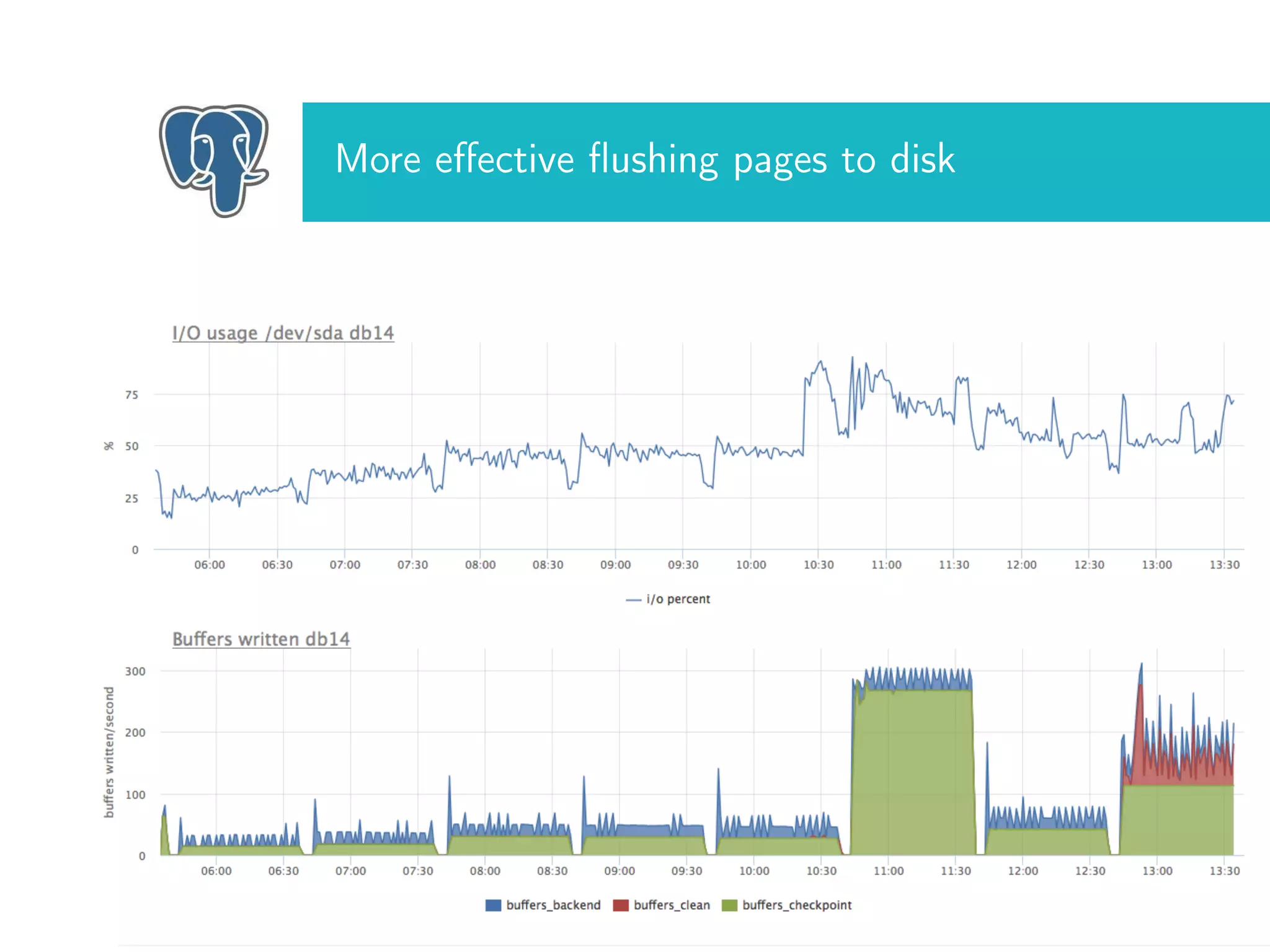








The document discusses tuning Linux settings to enhance PostgreSQL performance by focusing on CPU, memory, and storage configurations. Key areas include optimizing memory usage with huge pages, adjusting swap settings, and fine-tuning flushing processes, as well as scheduler configurations for improved throughput. It emphasizes the need for careful parameter adjustments to fully leverage the efficiency of the modern Linux kernel.






















































































