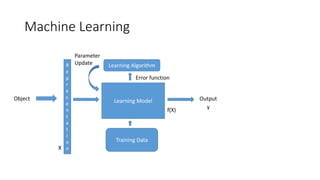
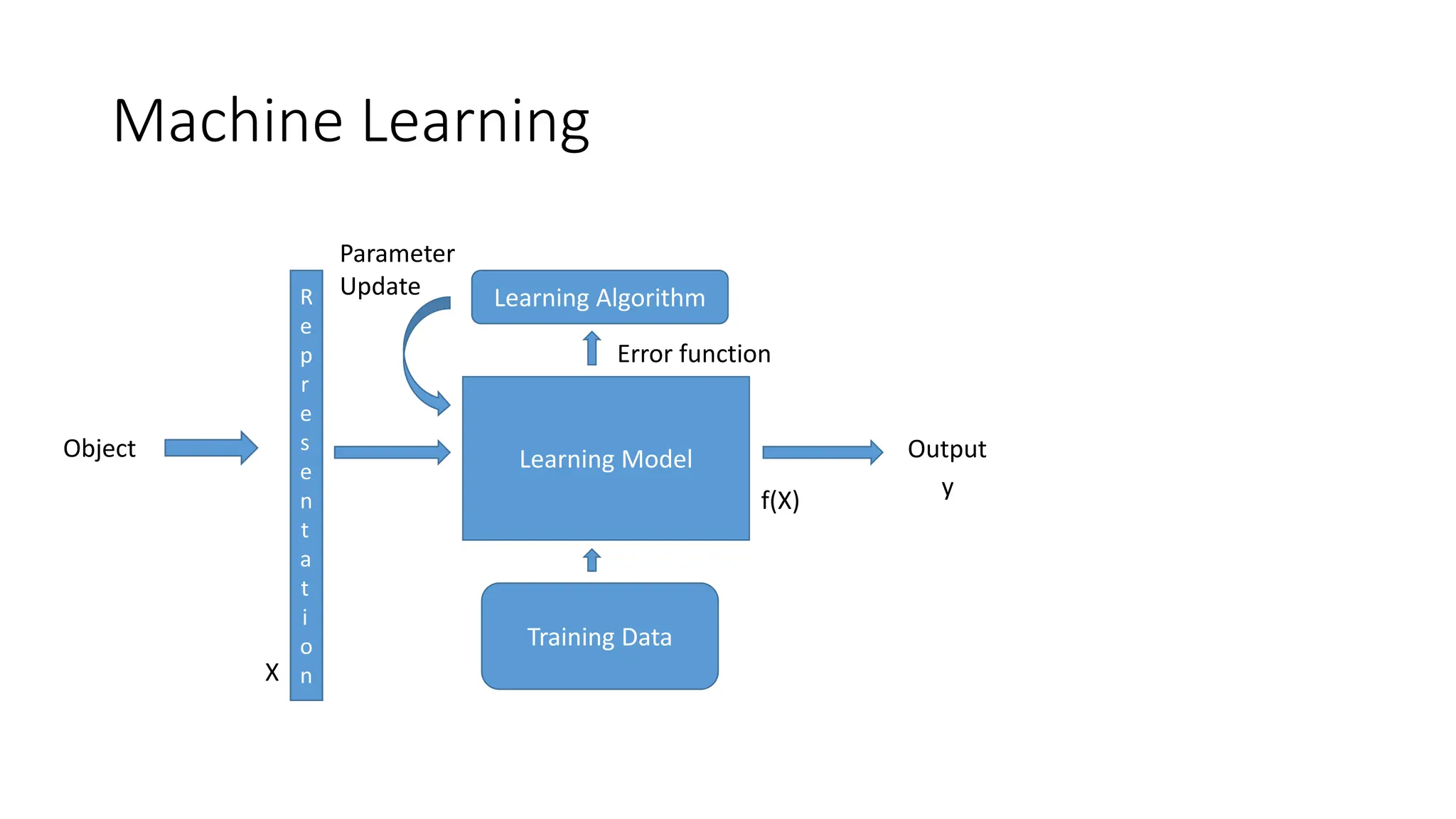
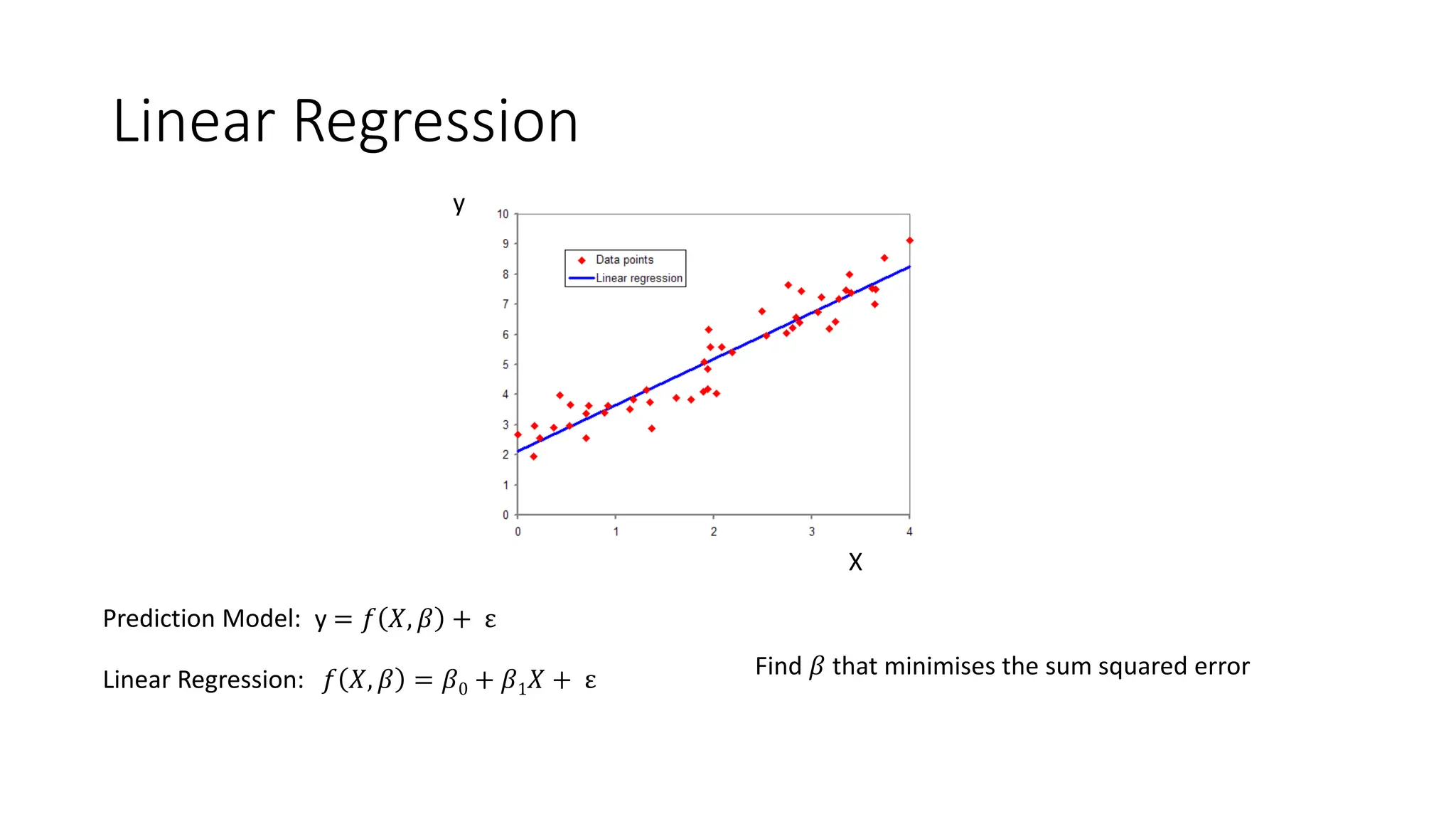
Machine Learning Models
•Classification
• Predicts category of input objects – predefined classes
• Object recognition in images, email spam detection
• Regression
• Predicts real valued output for a given input
• Predicting value of a stock, predicting number of clicks in an advertisement
• Clustering
• Groups objects into homogeneous clusters – clusters not predefined
• Market segmentation, anomaly detection in industrial plants
5.
Learning Algorithms
• Supervised(predictive data analysis)
• For each input in the training data the desired output is known
• Previous history, ground truth, annotations, labels
• Unsupervised (explorative data analysis)
• Output is not specified
• Natural groups are to be determined
• Semi-supervised
• Supervisory output available for few data points
• Output not available for most data points
6.
Examples of MachineLearning Models
• Classification and Regression
• Logistic Regression
• Bayesian learning
• K-Nearest neighbor
• Decision Tree
• Support Vector Machine
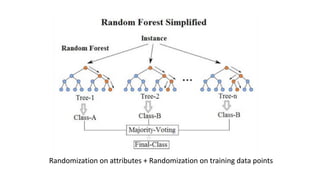
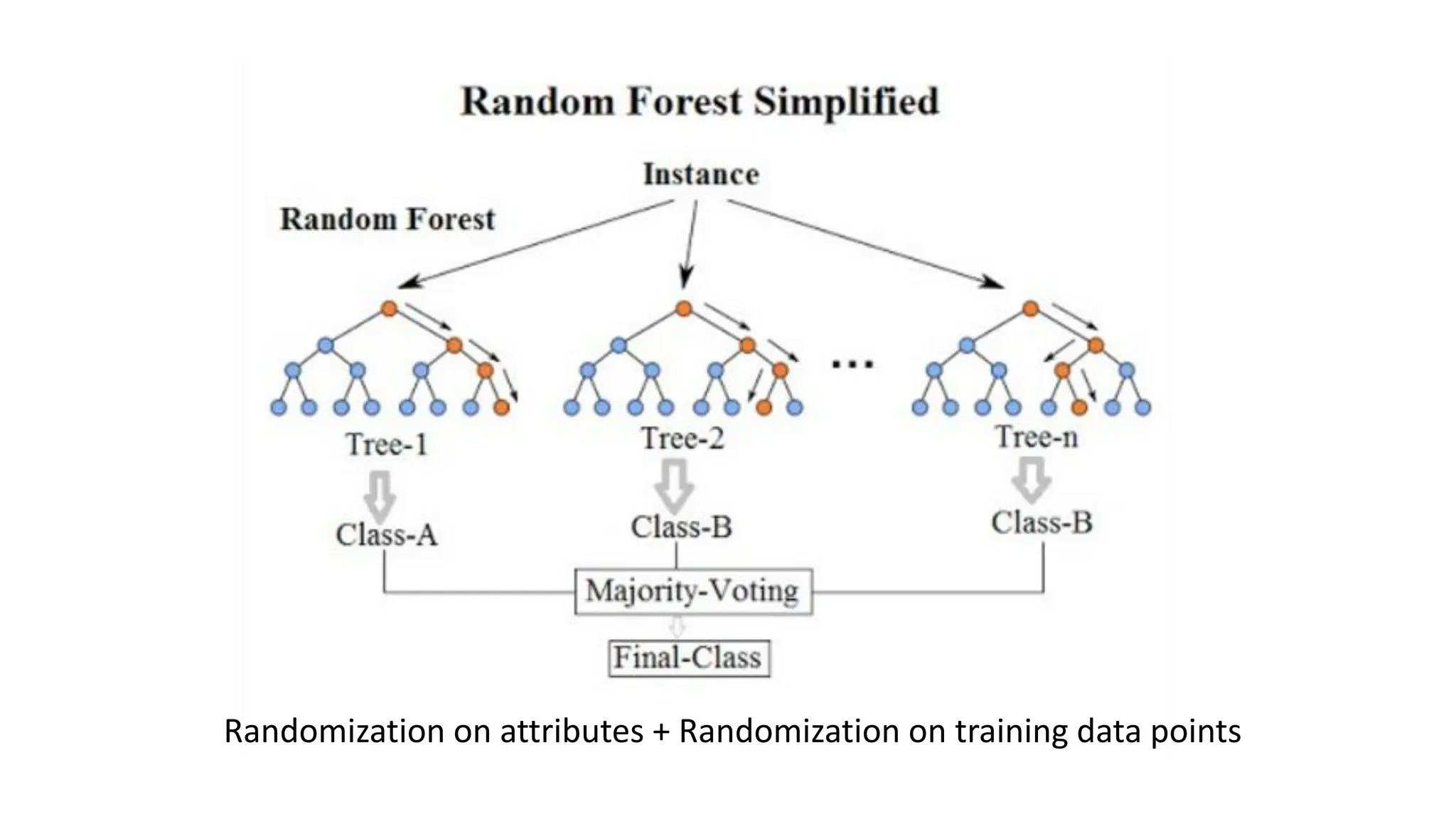
• Boosting – Random Forests, Xgboost
• Neural Networks and Deep Learning
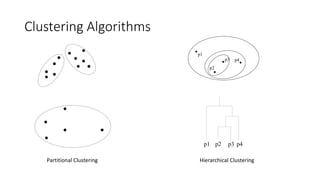
• Clustering
• K-means clustering
• Hierarchical clustering
• DBSCAN
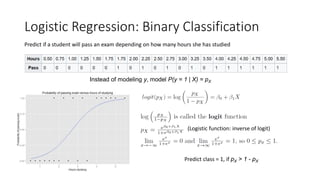
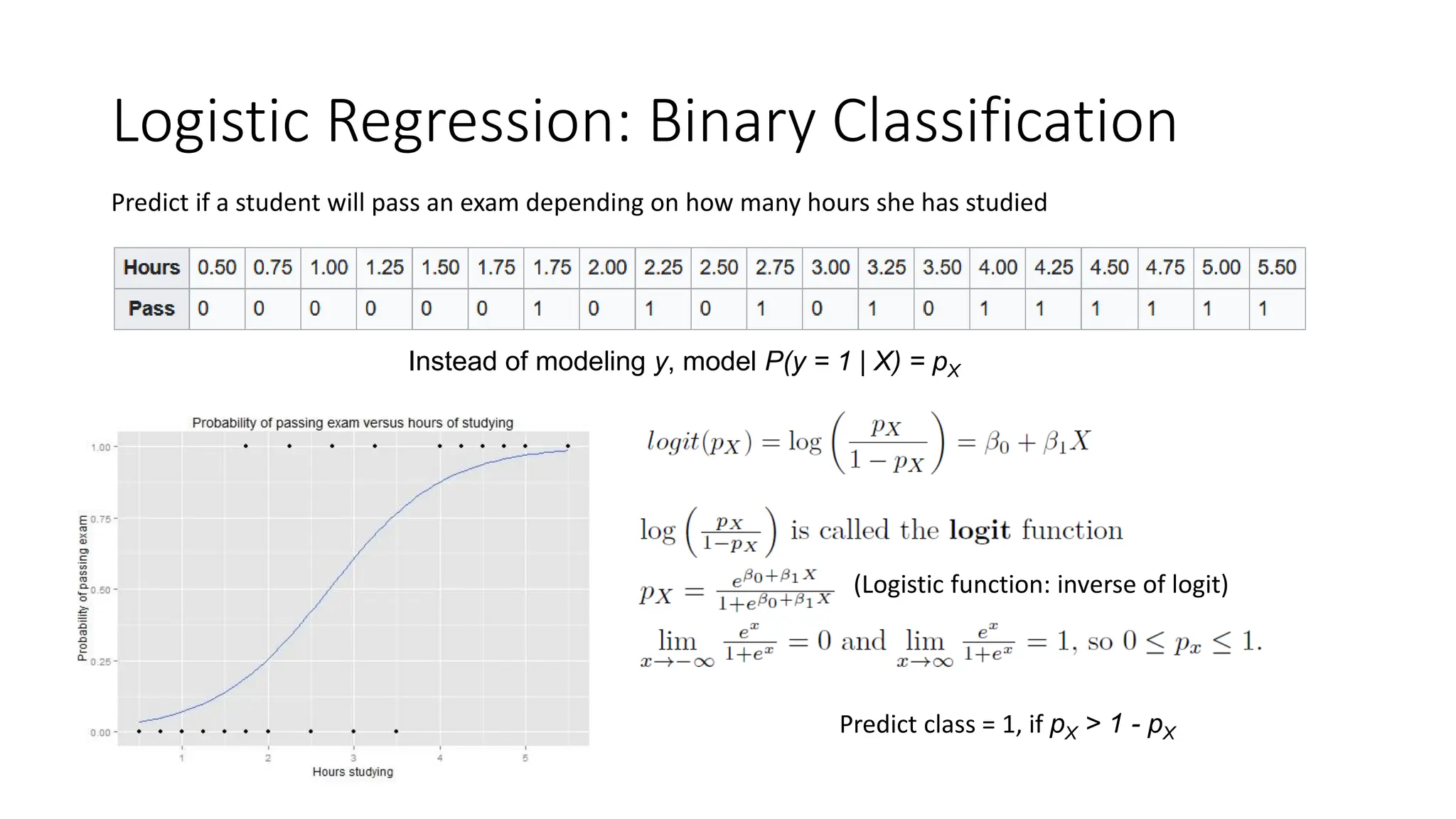
Logistic Regression: BinaryClassification
Predict if a student will pass an exam depending on how many hours she has studied
Instead of modeling y, model P(y = 1 | X) = pX
(Logistic function: inverse of logit)
Predict class = 1, if pX > 1 - pX
9.
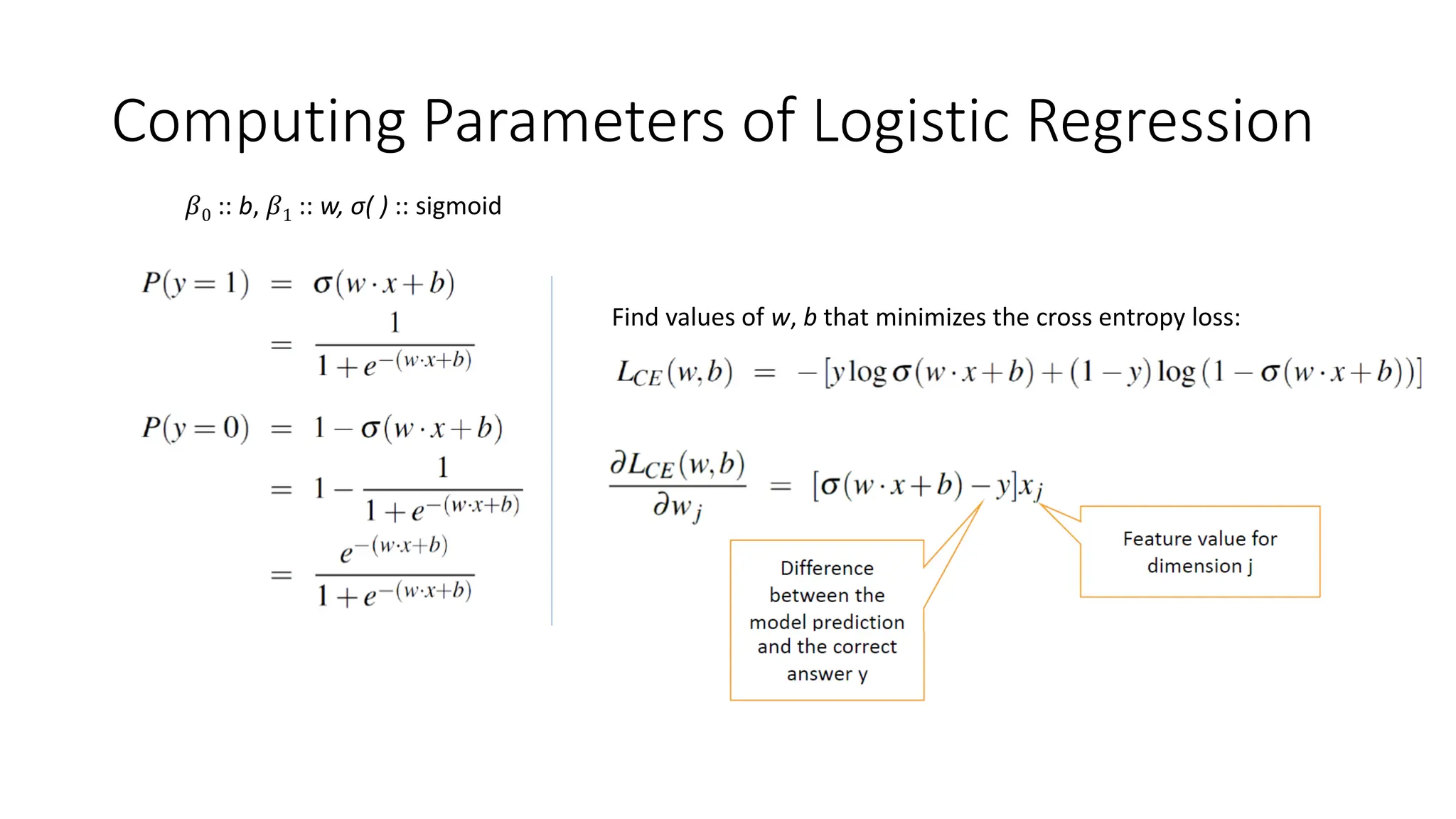
Computing Parameters ofLogistic Regression
𝛽0 :: b, 𝛽1 :: w, σ( ) :: sigmoid
Find values of w, b that minimizes the cross entropy loss:
10.
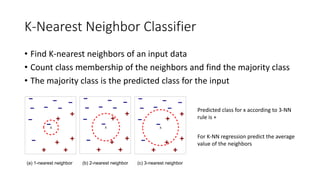
K Nearest Neighbors
XX X
(a) 1-nearest neighbor (b) 2-nearest neighbor (c) 3-nearest neighbor
K-nearest neighbors of an input x are training data points that have the K
smallest distance to x
11.
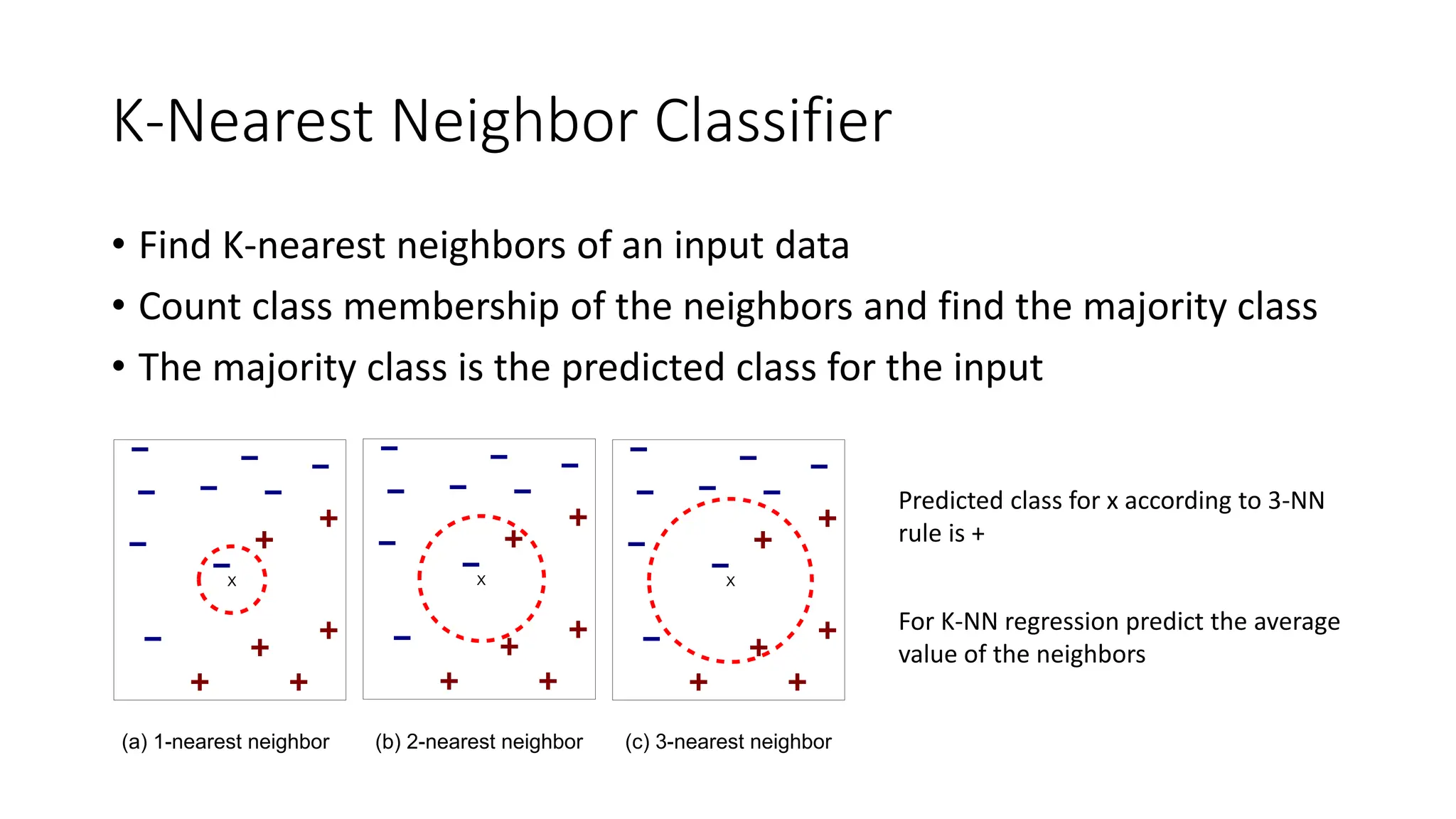
K-Nearest Neighbor Classifier
•Find K-nearest neighbors of an input data
• Count class membership of the neighbors and find the majority class
• The majority class is the predicted class for the input
X X X
(a) 1-nearest neighbor (b) 2-nearest neighbor (c) 3-nearest neighbor
Predicted class for x according to 3-NN
rule is +
For K-NN regression predict the average
value of the neighbors
12.
Nearest-Neighbor Classifiers: DesignChoices
– The value of k, the number of nearest neighbors to retrieve
– Distance Metric to compute distance between data points
13.
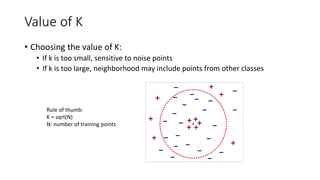
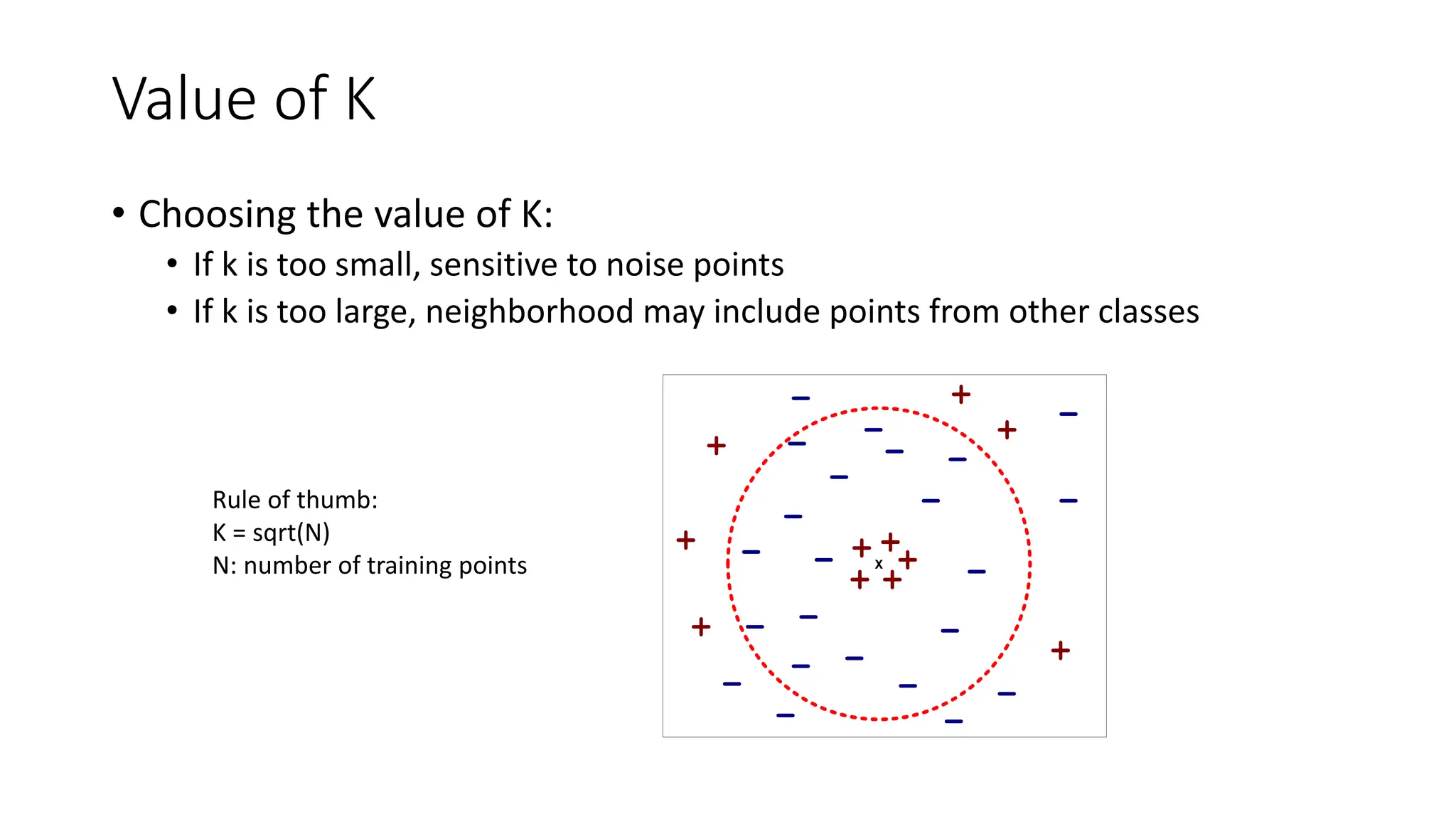
Value of K
•Choosing the value of K:
• If k is too small, sensitive to noise points
• If k is too large, neighborhood may include points from other classes
X
Rule of thumb:
K = sqrt(N)
N: number of training points
Distance Measure: ScaleEffects
• Different features may have different measurement scales
• E.g., patient weight in kg (range [50,200]) vs. blood protein values in ng/L ([-3,3])
• Consequences
• Patient weight will have a greater influence on the distance between samples
• May bias the performance of the classifier
• Transform raw feature values into z-scores
• is the value for the ith sample and jth feature
• is the average of all inputs or feature j
• is the standard deviation of all inputs over all input samples
• Range and scale of z-scores should be similar (providing distributions of raw feature values are alike)
zij =
xij - mj
s j
xij
mj
s j
16.
Nearest Neighbor :Dimensionality
• Problem with Euclidean measure:
• High dimensional data
• curse of dimensionality
• Can produce counter-intuitive results
• Shrinking density – sparsification effect
1 1 1 1 1 1 1 1 1 1 1 0
0 1 1 1 1 1 1 1 1 1 1 1
1 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 1
vs
d = 1.4142 d = 1.4142
17.
Nearest Neighbour :Computational Complexity
• Expensive
• To determine the nearest neighbour of a query point q, must compute the distance to all N
training examples
+ Pre-sort training examples into fast data structures (kd-trees)
+ Compute only an approximate distance (LSH)
+ Remove redundant data (condensing)
• Storage Requirements
• Must store all training data P
+ Remove redundant data (condensing)
- Pre-sorting often increases the storage requirements
• High Dimensional Data
• “Curse of Dimensionality”
• Required amount of training data increases exponentially with dimension
• Computational cost also increases dramatically
• Partitioning techniques degrade to linear search in high dimension
18.
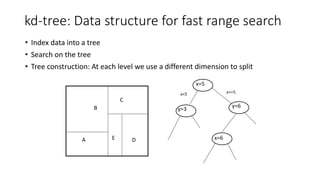
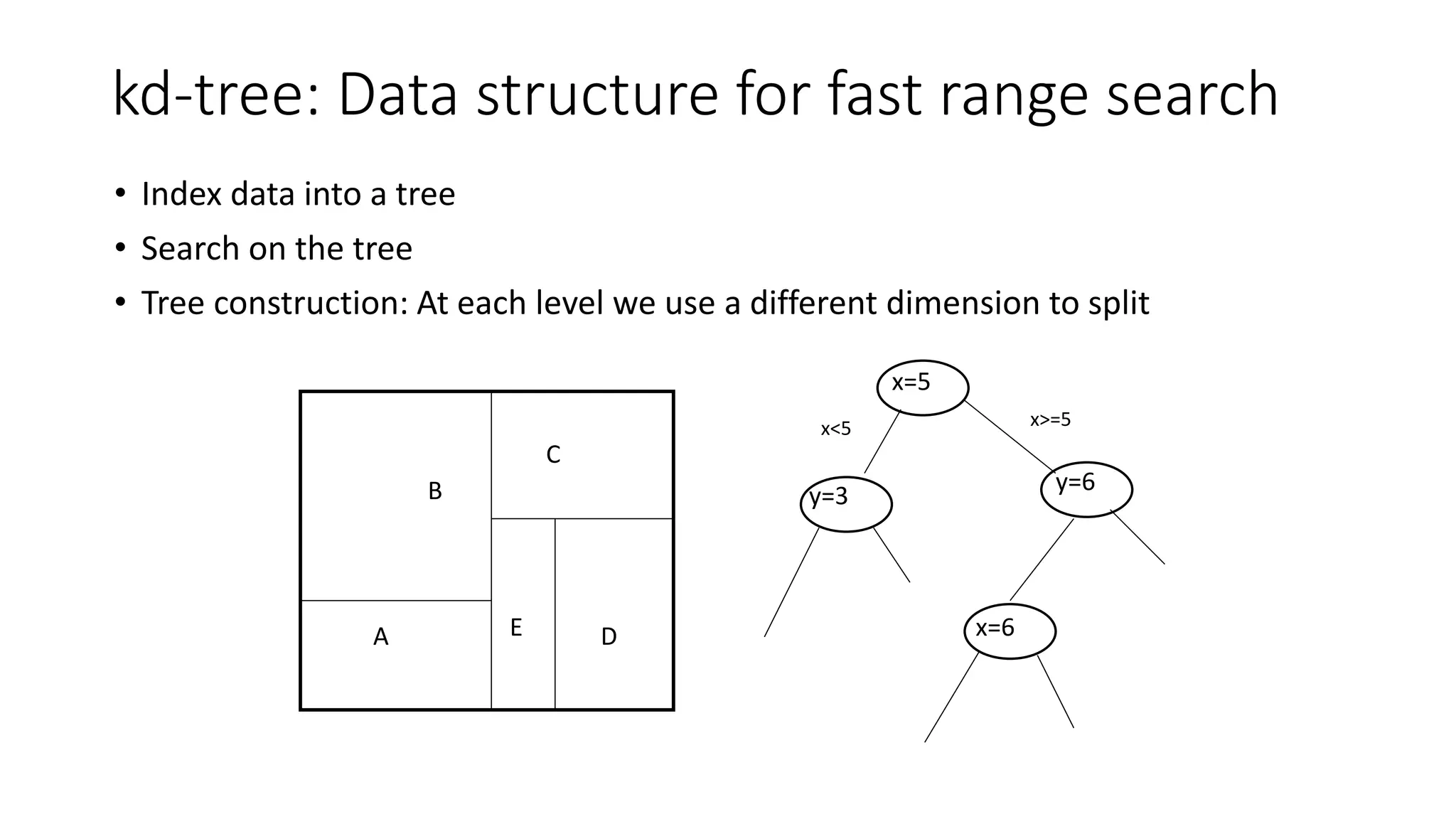
kd-tree: Data structurefor fast range search
• Index data into a tree
• Search on the tree
• Tree construction: At each level we use a different dimension to split
x=5
y=3
y=6
x=6
A
B
C
D
E
x<5 x>=5
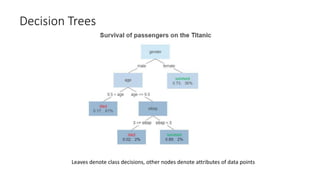
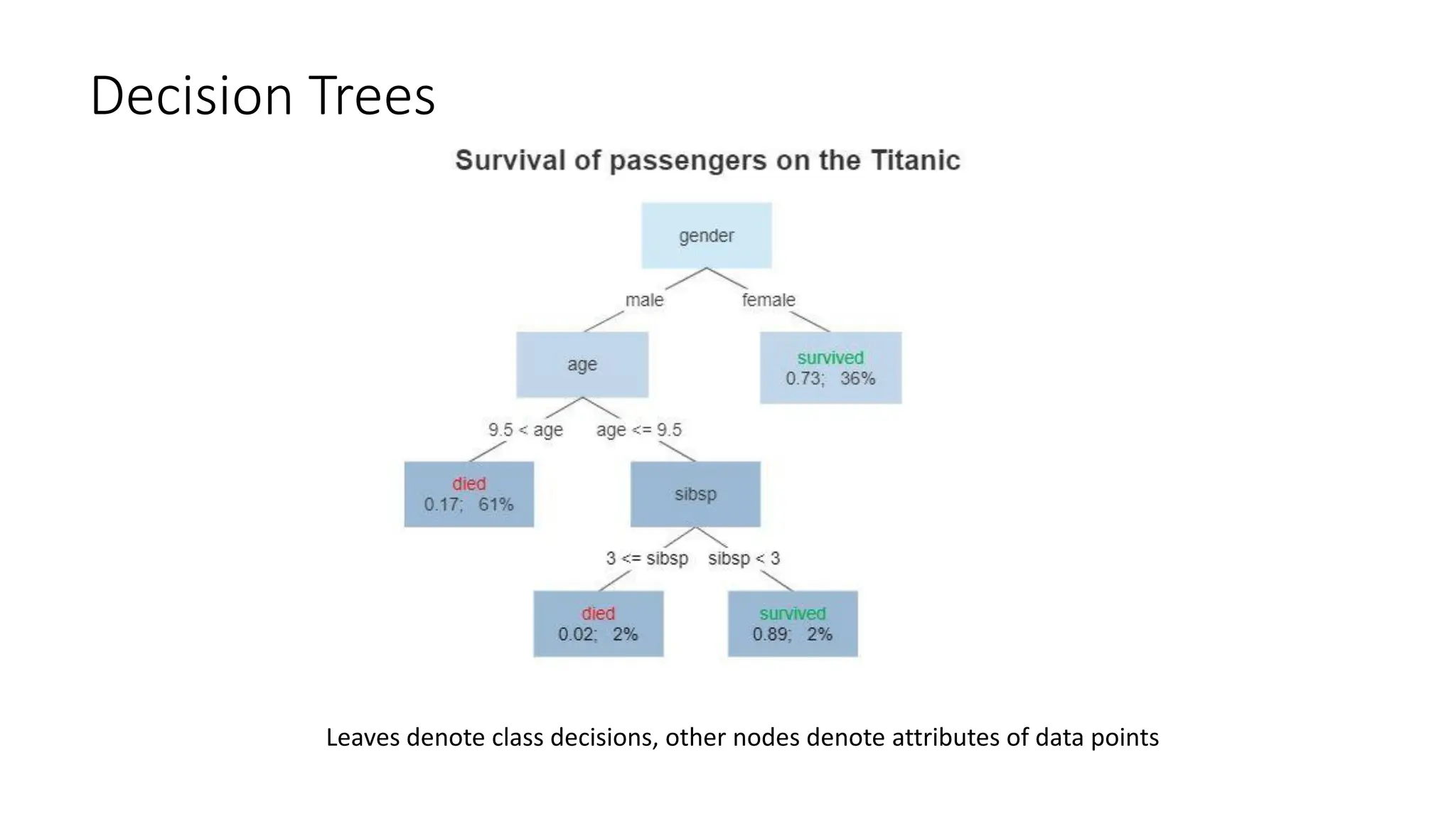
Decision Tree Construction
Repeat:
1.Split the “best” decision attribute (A) for next node
2. For each value of A, create new descendant of node
4. Sort training examples to leaf nodes
5. If training examples perfectly classified, STOP,
Else iterate over new leaf nodes
Grow tree just deep enough for perfect classification
–If possible (or can approximate at chosen depth)
Which attribute is best? (Information Gain Maximization)
• Simplified tree construction: At each level use only a small random
subset of attributes to create descendants
23.
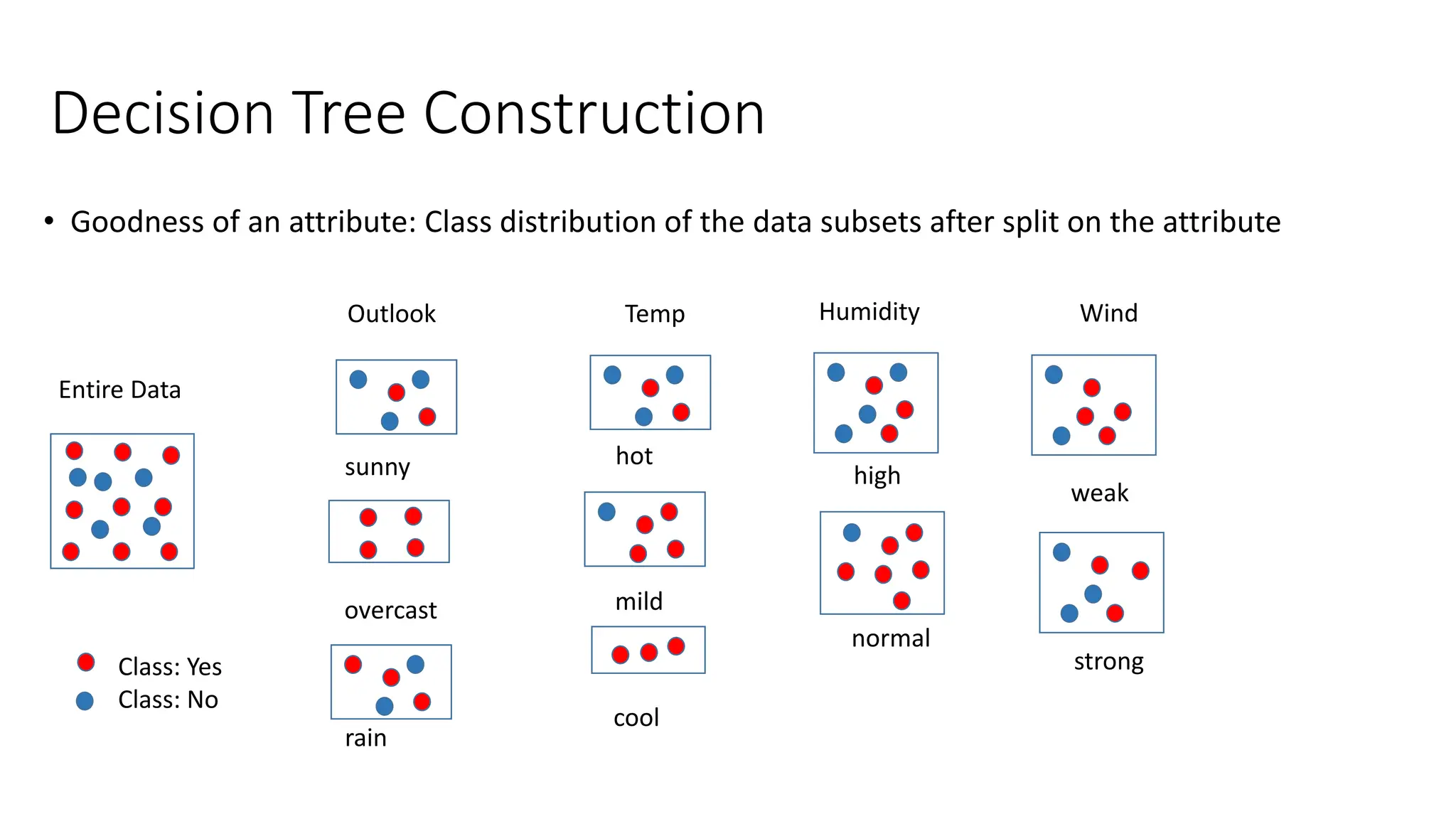
Decision Tree Construction
•Goodness of an attribute: Class distribution of the data subsets after split on the attribute
Class: Yes
Class: No
Entire Data
Outlook Temp Humidity Wind
sunny
overcast
rain
hot
mild
cool
high
normal
weak
strong
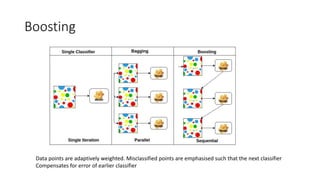
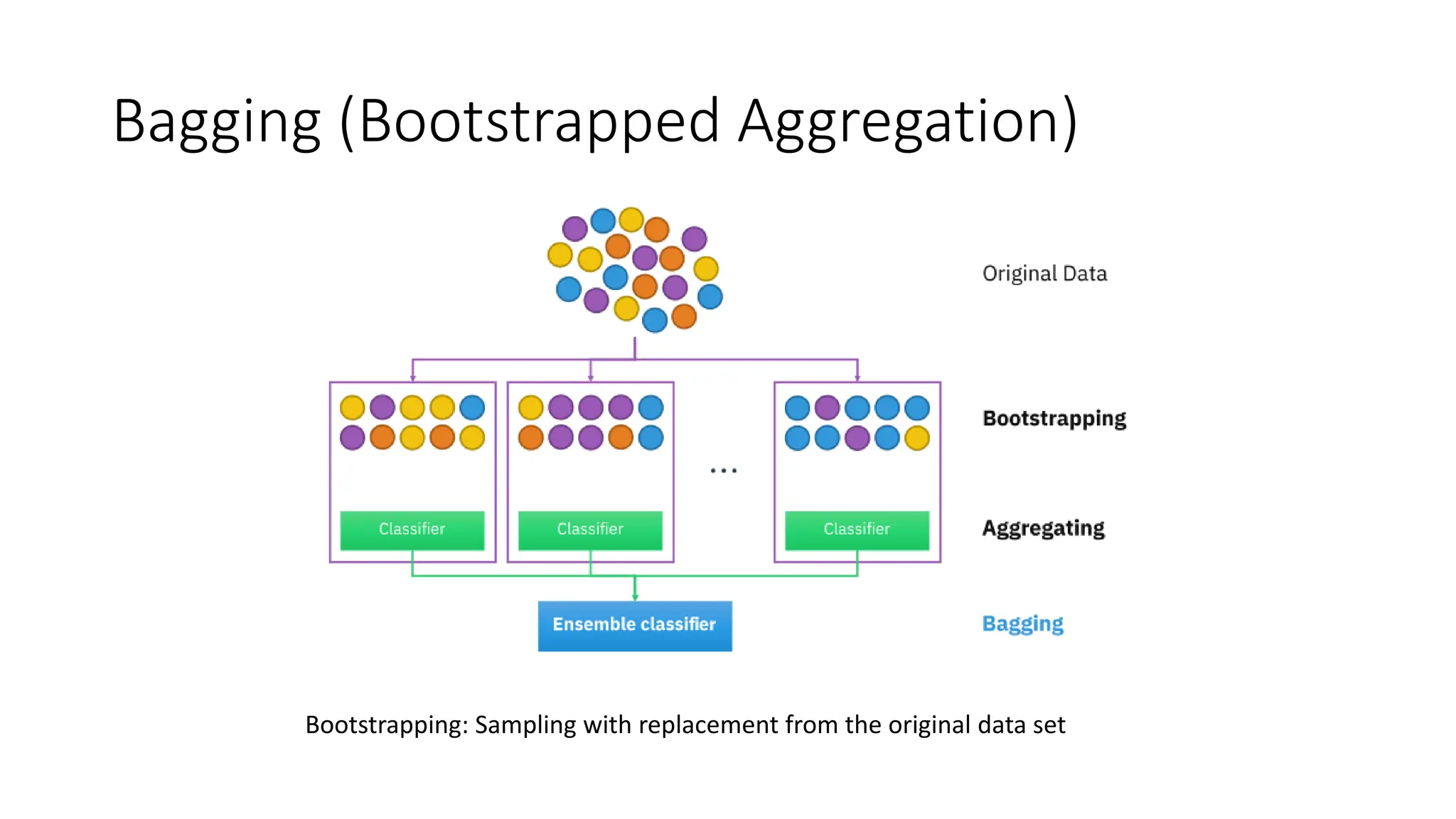
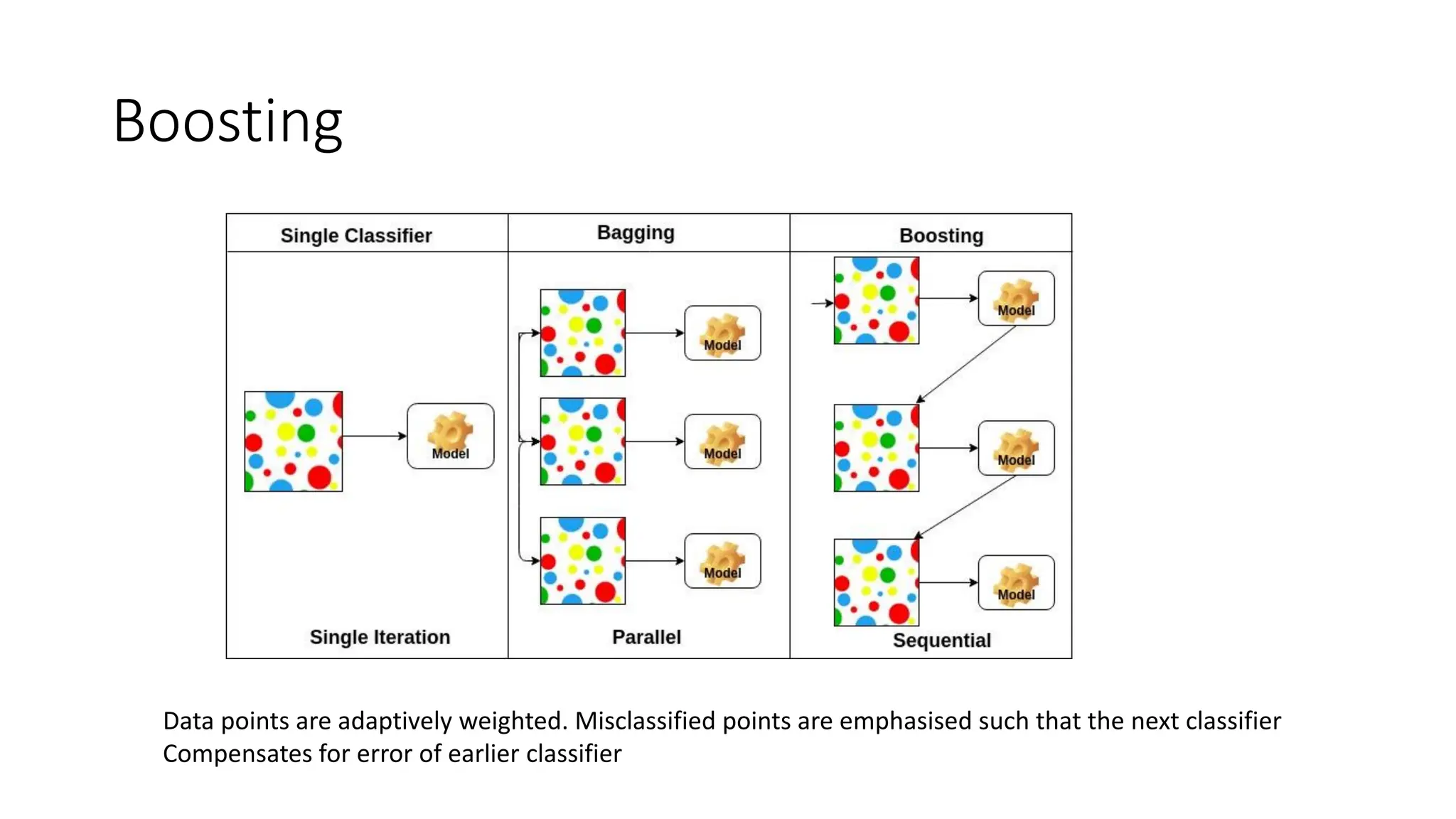
Boosting
Data points areadaptively weighted. Misclassified points are emphasised such that the next classifier
Compensates for error of earlier classifier
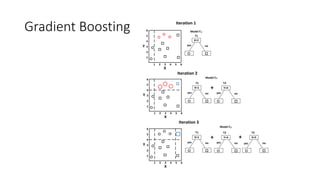
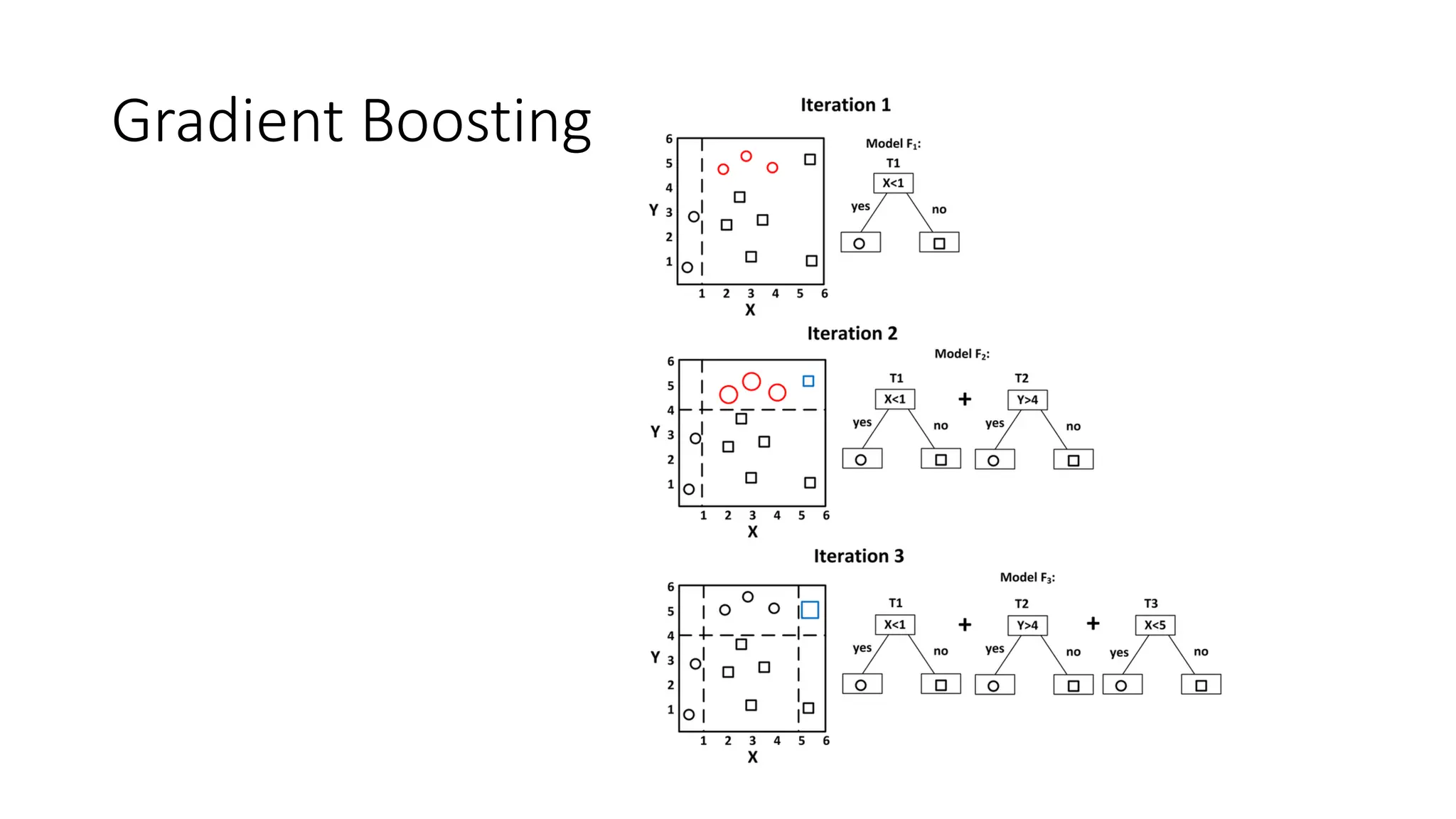
Gradient Boosting
• GradientDescent + Boosting
Error term indicate inadequacy of the model
Residual
Model residual with another classifier M2. And append it to M1.
Continue over iterations
M1 additively compensates inadequacy of M1
Residual = negative gradient
Iterative process a gradient descent
Gradient Boosting forRegression
• We have a set of variables vectors x1 , x2 and x3. You need to predict
y which is a continuous variable.
• Steps of Gradient Boost algorithm
Step 1 : Assume mean is the prediction of all variables.
Step 2 : Calculate errors of each observation from the mean (latest prediction).
Step 3 : Find the variable that can split the errors perfectly and find the value
for the split. This is assumed to be the latest prediction.
Step 4 : Calculate errors of each observation from the mean of both the sides of
split (latest prediction).
Step 5 : Repeat the step 3 and 4 till the objective function maximizes/minimizes.
Step 6 : Take a weighted mean of all the classifiers to come up with the final
model.
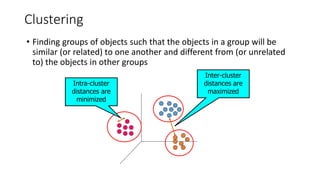
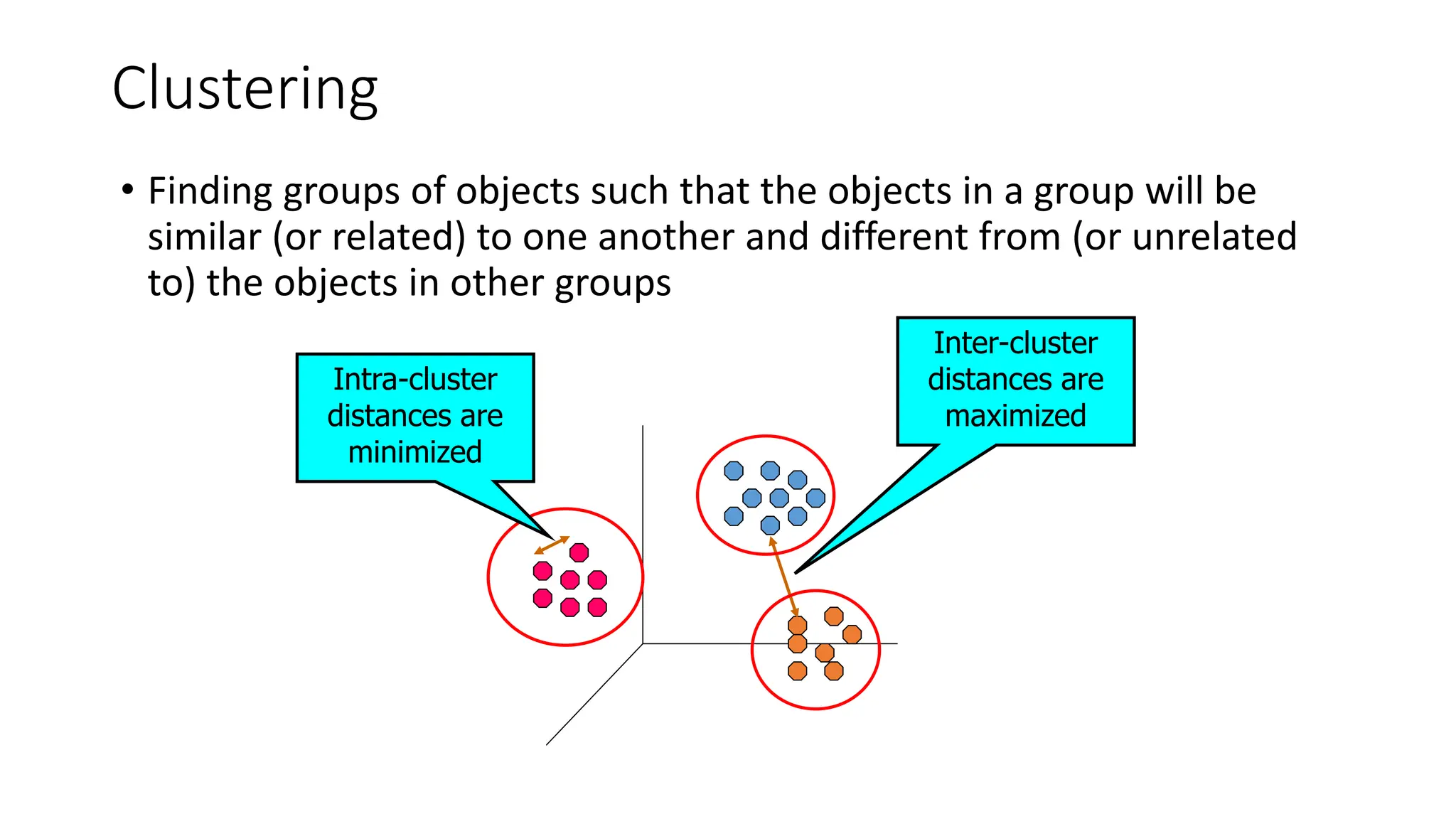
Clustering
• Finding groupsof objects such that the objects in a group will be
similar (or related) to one another and different from (or unrelated
to) the objects in other groups
Inter-cluster
distances are
maximized
Intra-cluster
distances are
minimized
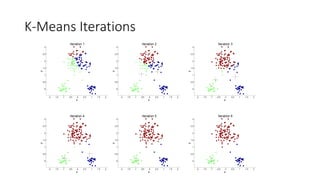
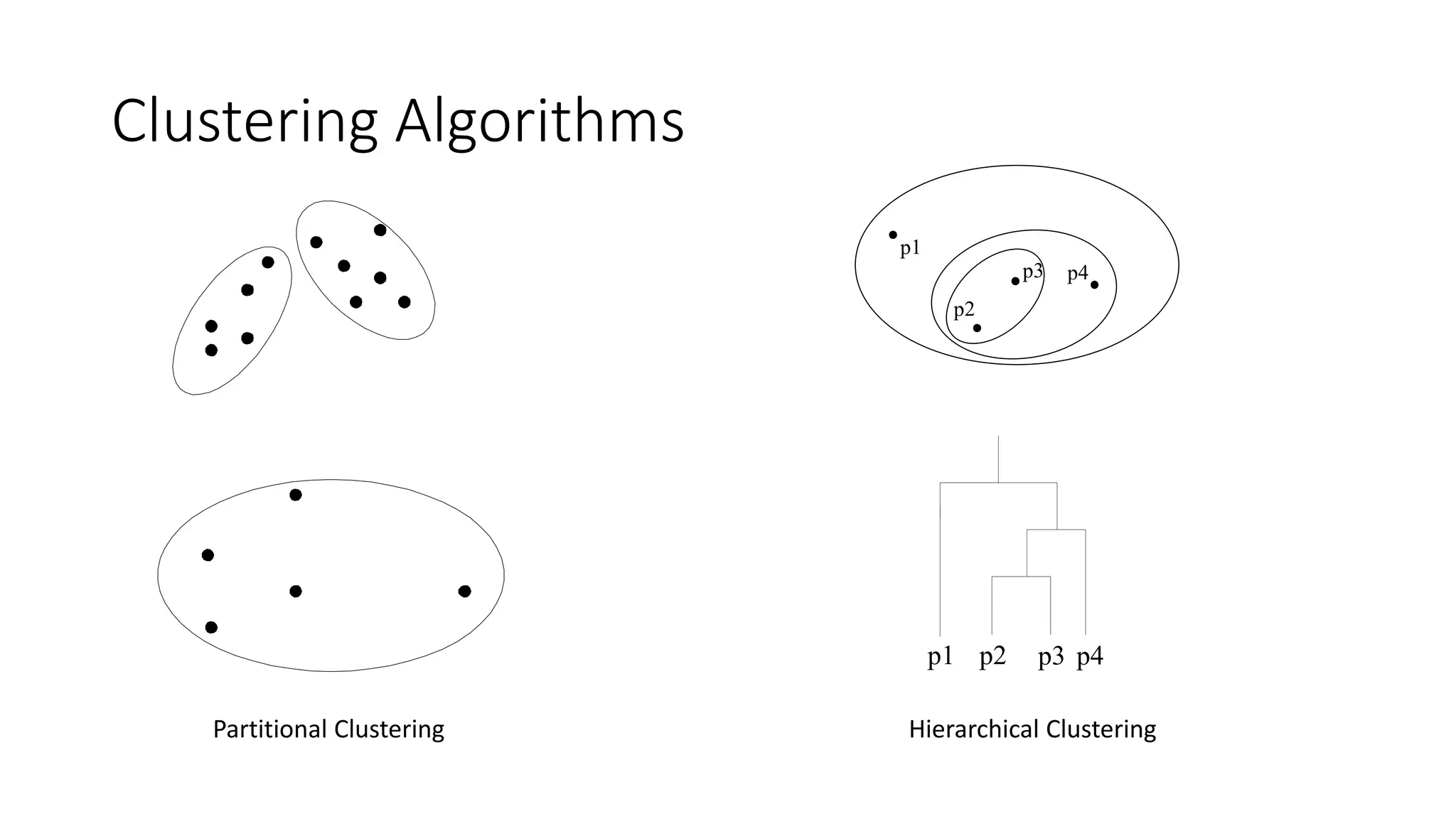
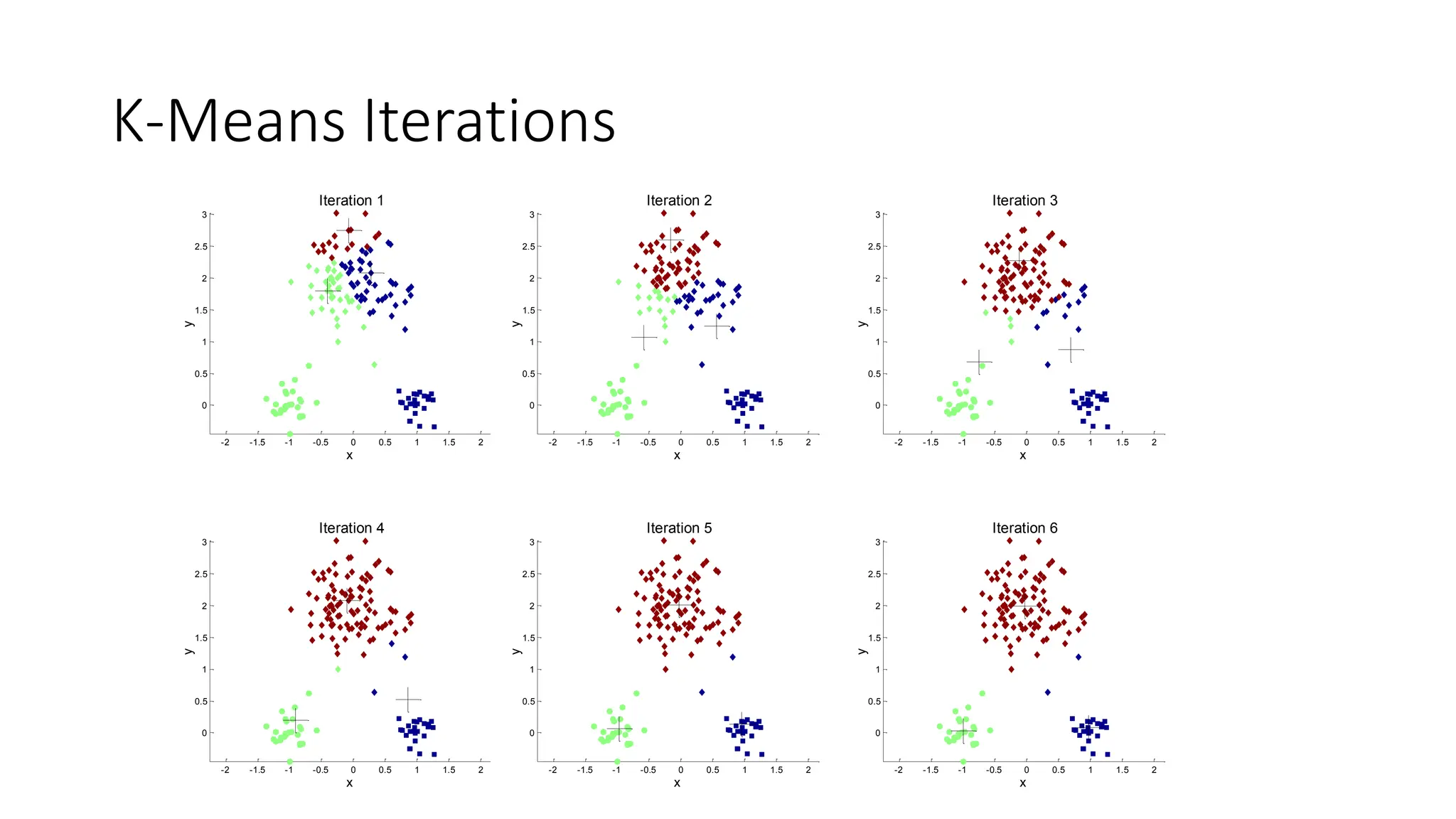
K-Means Clustering
• Partitionalclustering approach
• Each cluster is associated with a centroid (center point)
• Each point is assigned to the cluster with the closest centroid
• Number of clusters, K, must be specified









![Distance Measure: Scale Effects
• Different features may have different measurement scales
• E.g., patient weight in kg (range [50,200]) vs. blood protein values in ng/L ([-3,3])
• Consequences
• Patient weight will have a greater influence on the distance between samples
• May bias the performance of the classifier
• Transform raw feature values into z-scores
• is the value for the ith sample and jth feature
• is the average of all inputs or feature j
• is the standard deviation of all inputs over all input samples
• Range and scale of z-scores should be similar (providing distributions of raw feature values are alike)
zij =
xij - mj
s j
xij
mj
s j](https://image.slidesharecdn.com/machinelearningalgorithms-250622095235-3eb94fcd/85/Machine-Learning-Algorithms-Introduction-pdf-15-320.jpg)



















![Distance Measure: Scale Effects
• Different features may have different measurement scales
• E.g., patient weight in kg (range [50,200]) vs. blood protein values in ng/L ([-3,3])
• Consequences
• Patient weight will have a greater influence on the distance between samples
• May bias the performance of the classifier
• Transform raw feature values into z-scores
• is the value for the ith sample and jth feature
• is the average of all inputs or feature j
• is the standard deviation of all inputs over all input samples
• Range and scale of z-scores should be similar (providing distributions of raw feature values are alike)
zij =
xij - mj
s j
xij
mj
s j](https://image.slidesharecdn.com/machinelearningalgorithms-250622095235-3eb94fcd/75/Machine-Learning-Algorithms-Introduction-pdf-15-2048.jpg)












![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2931-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt3441-thumbnail.jpg?width=600ounds&width=560&fit=bounds)











































