Download as PDF, PPTX







![Docker – Popular Container engine
• Installation
# sudo tee /etc/yum.repos.d/docker.repo <<-'EOF'
[dockerrepo]
name=Docker Repository
baseurl=https://yum.dockerproject.org/repo/main/centos/7/
enabled=1
gpgcheck=1
gpgkey=https://yum.dockerproject.org/gpg
EOF
# yum install docker-engine
# systemctl enable docker.service
# systemctl start docker.service](https://image.slidesharecdn.com/pgconfsv2016harep-161117043337/85/PostgreSQL-High-Availability-in-a-Containerized-World-8-320.jpg)


















![Consul
• Service Discovery
• Failure Detection
• Multi Data Center
• DNS Query Interface
{
"service": {
"name": ”mypostgresql",
"tags": ["master"],
"address": "127.0.0.1",
"port": 5432,
"enableTagOverride": false,
}
}
nslookup master.mypostgresql.service.domain
nslookup mypostgresql.service.domain](https://image.slidesharecdn.com/pgconfsv2016harep-161117043337/85/PostgreSQL-High-Availability-in-a-Containerized-World-36-320.jpg)










![Docker – Popular Container engine
• Installation
# sudo tee /etc/yum.repos.d/docker.repo <<-'EOF'
[dockerrepo]
name=Docker Repository
baseurl=https://yum.dockerproject.org/repo/main/centos/7/
enabled=1
gpgcheck=1
gpgkey=https://yum.dockerproject.org/gpg
EOF
# yum install docker-engine
# systemctl enable docker.service
# systemctl start docker.service](https://image.slidesharecdn.com/pgconfsv2016harep-161117043337/75/PostgreSQL-High-Availability-in-a-Containerized-World-8-2048.jpg)


















![Consul
• Service Discovery
• Failure Detection
• Multi Data Center
• DNS Query Interface
{
"service": {
"name": ”mypostgresql",
"tags": ["master"],
"address": "127.0.0.1",
"port": 5432,
"enableTagOverride": false,
}
}
nslookup master.mypostgresql.service.domain
nslookup mypostgresql.service.domain](https://image.slidesharecdn.com/pgconfsv2016harep-161117043337/75/PostgreSQL-High-Availability-in-a-Containerized-World-36-2048.jpg)
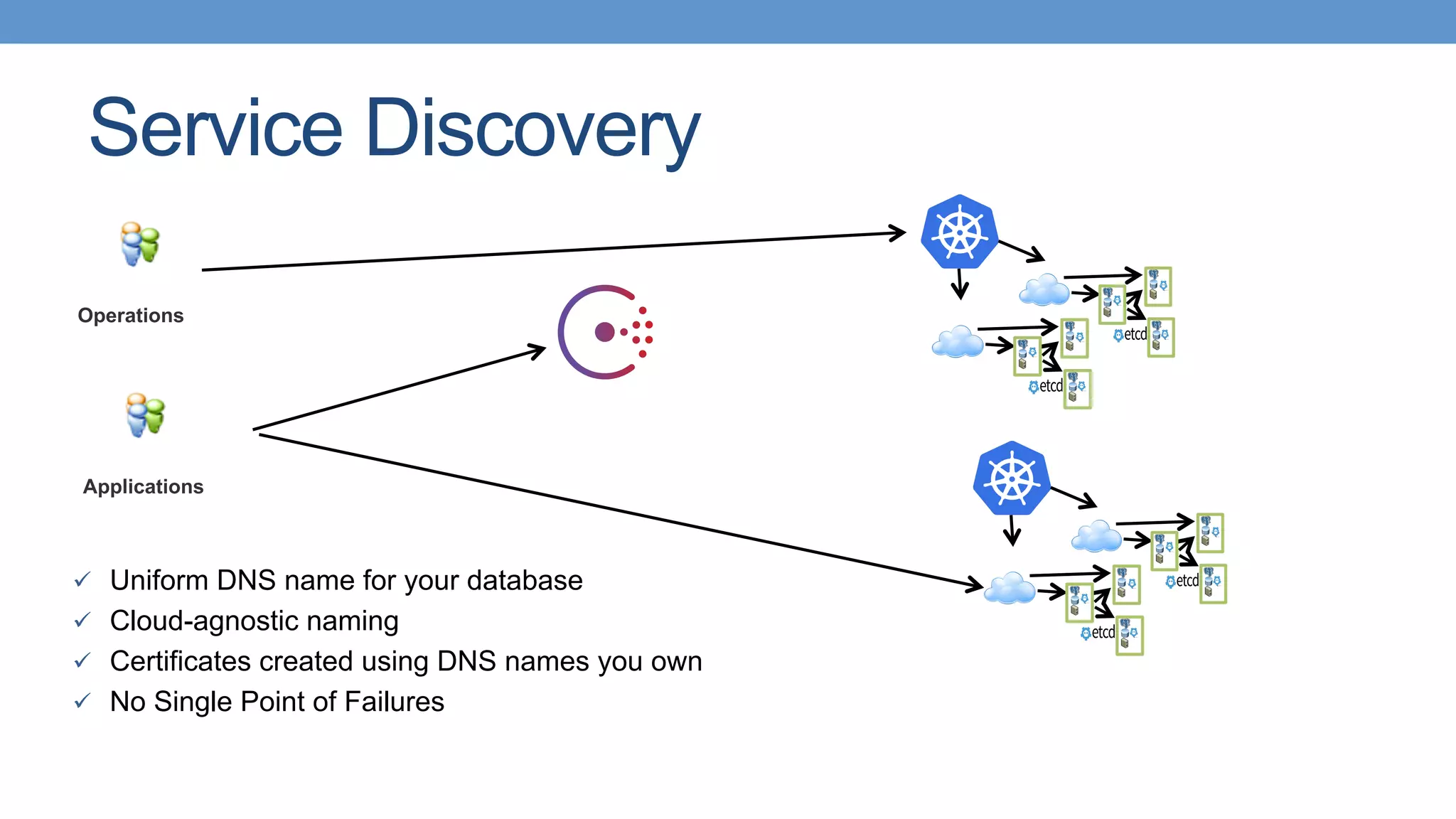





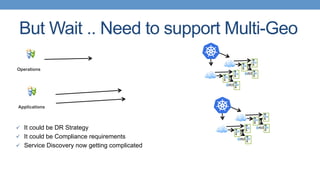
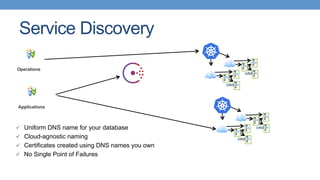
This document discusses PostgreSQL high availability in a containerized environment. It begins with an overview of containers and their advantages like lower footprint and density. It then covers enterprise needs for high availability like recovery time objectives. Common approaches to PostgreSQL high availability are discussed like replication, shared storage, and using projects like Patroni and Stolon. Modern trends with containers are highlighted like separating data and binaries. Kubernetes is presented as a production-grade orchestrator that can provide horizontal scaling and self-healing capabilities. The discussion concludes with challenges of multi-region deployments and how service discovery with Consul can help address those challenges.
Introduction to PostgreSQL High Availability in containers by Jignesh Shah, focusing on data management expertise.
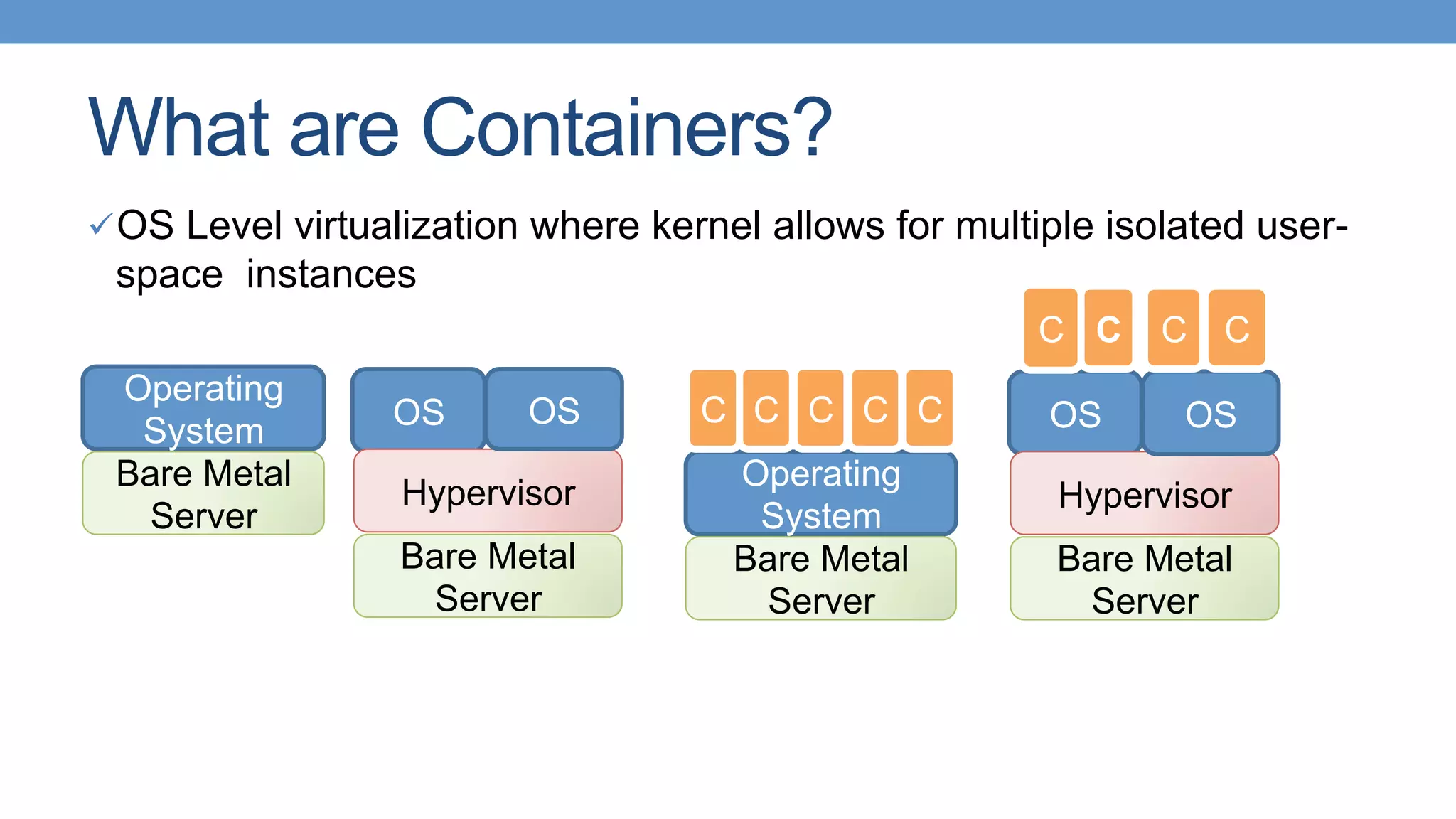
Definitions, advantages, and disadvantages of containers; highlights their role in creating isolated environments.
Guide for utilizing Docker as a container engine, covering installation and volume management in containers.
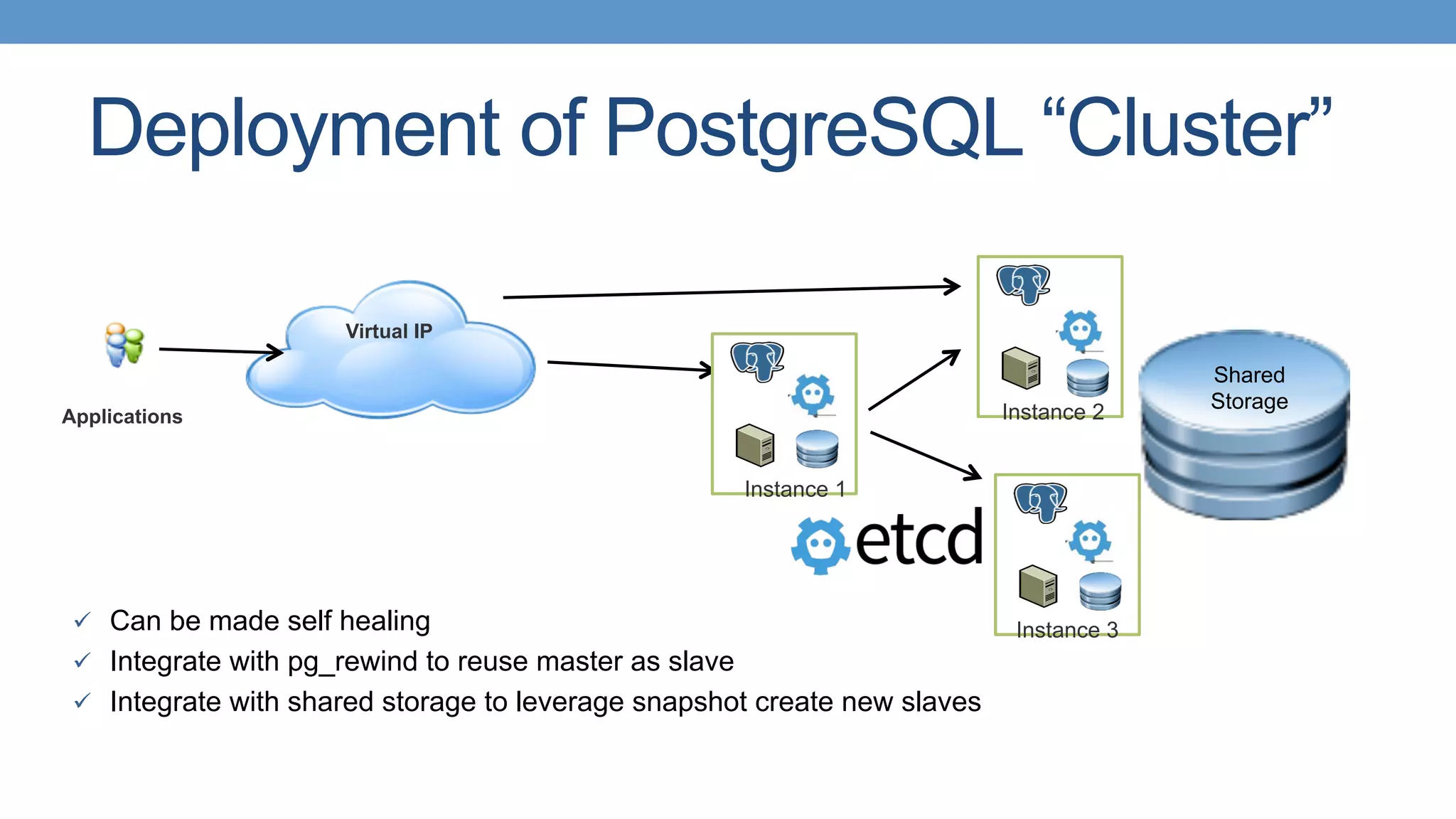
Deploying PostgreSQL in containers, customization for enterprise use, and requirements for a production environment.
Discussion on the importance of high availability in enterprise databases and planning strategies.
Key aspects of planning high availability, including Recovery Time and Point Objectives; causes of downtime.
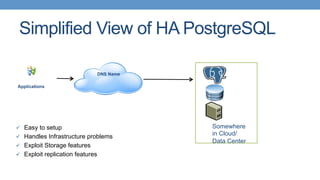
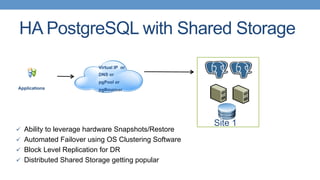
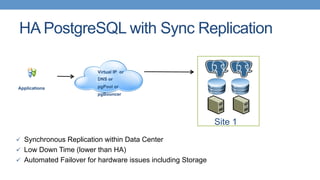
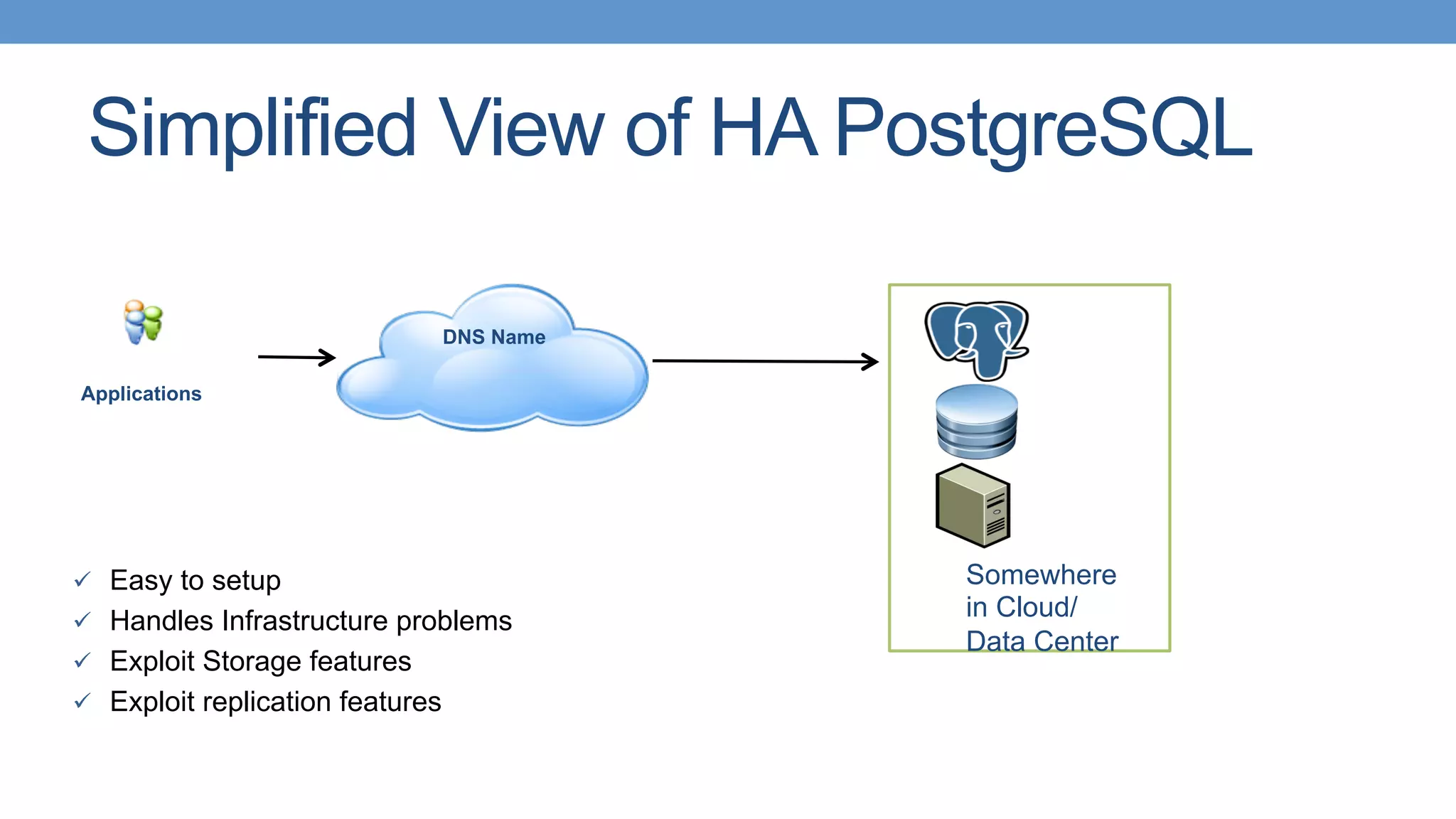
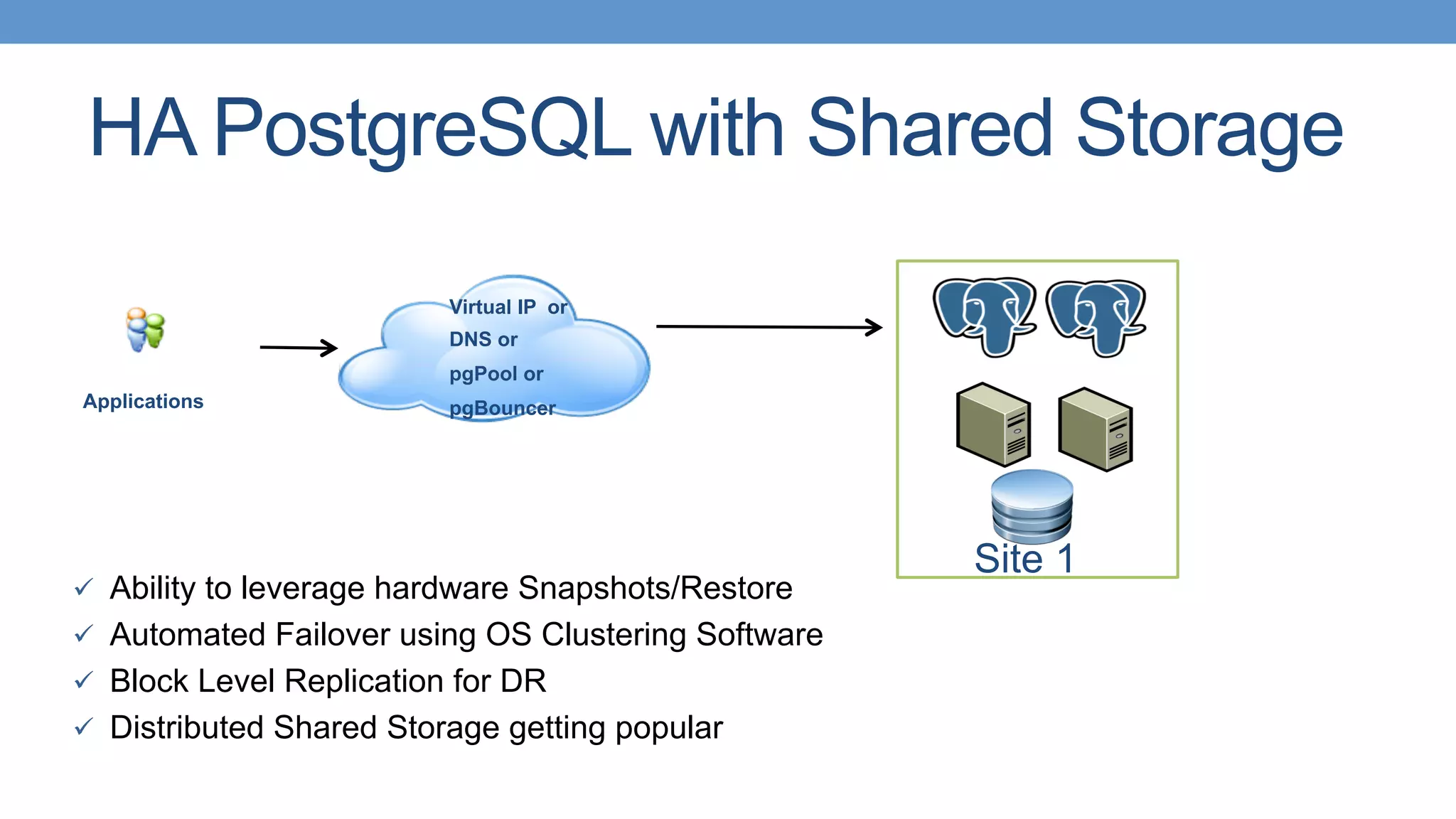
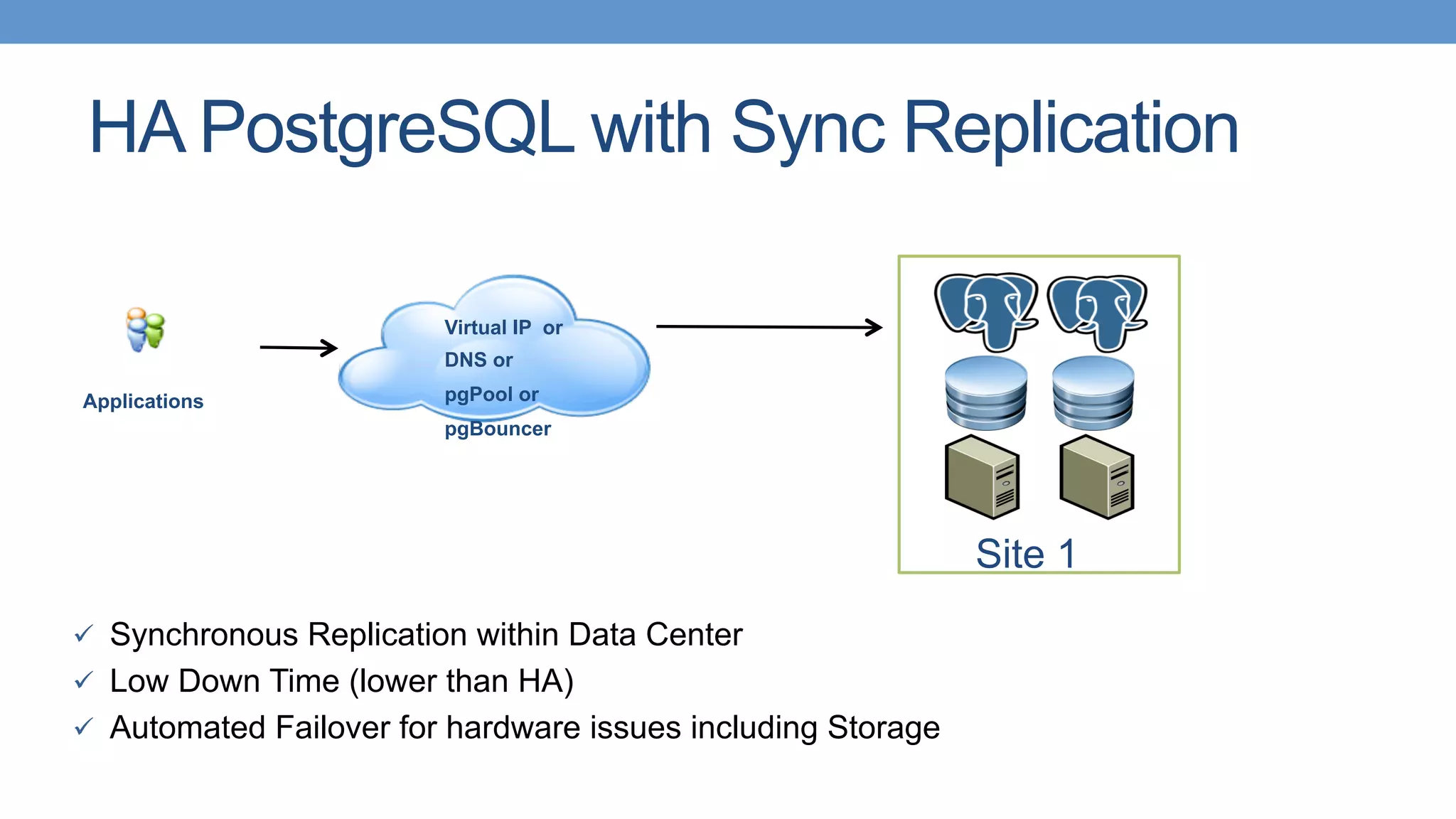
Strategies for HA with PostgreSQL using shared storage and replication, focusing on automated failover. Different types of replication available in PostgreSQL, including single master and various strategies.
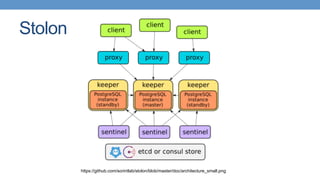
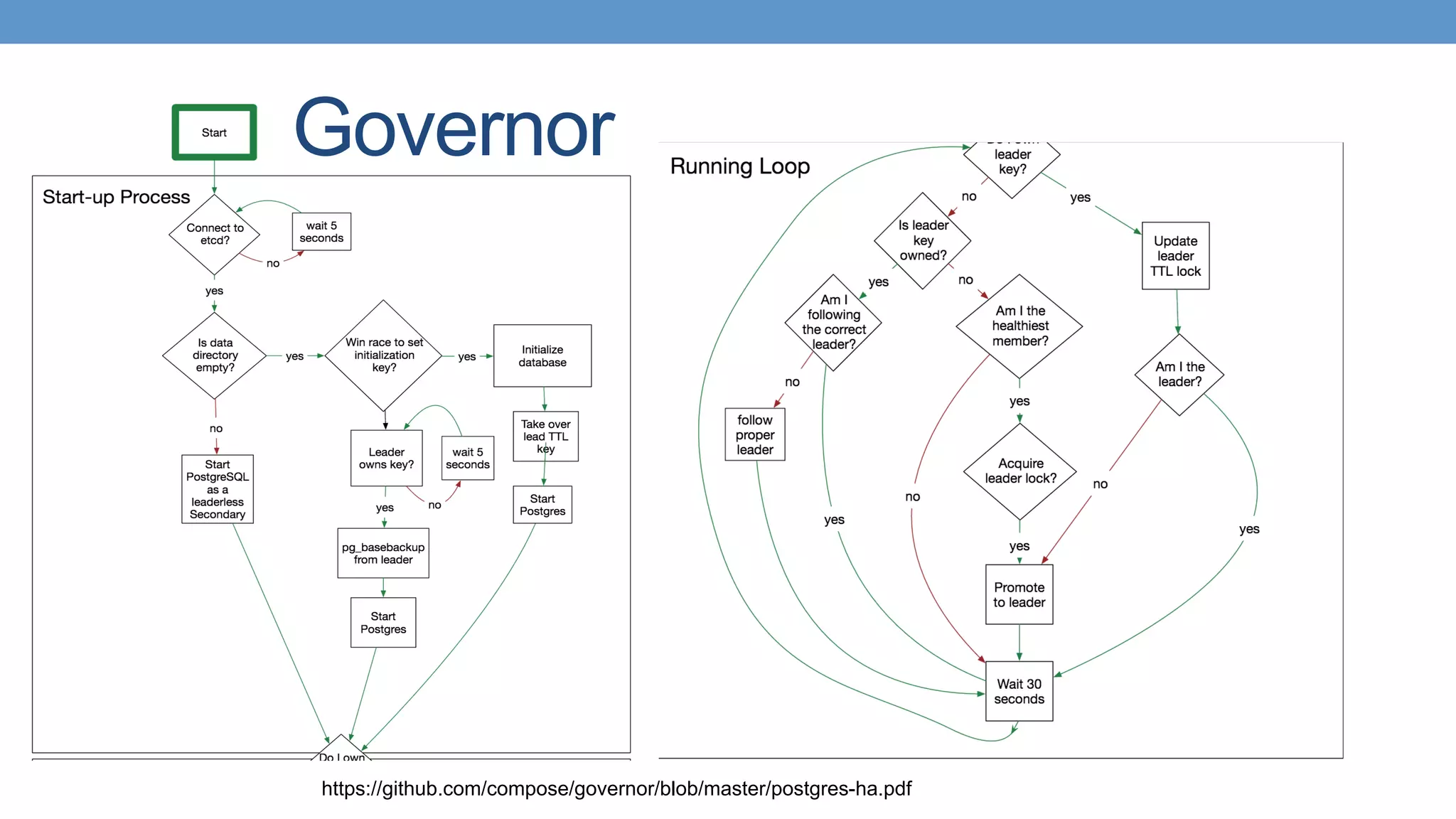
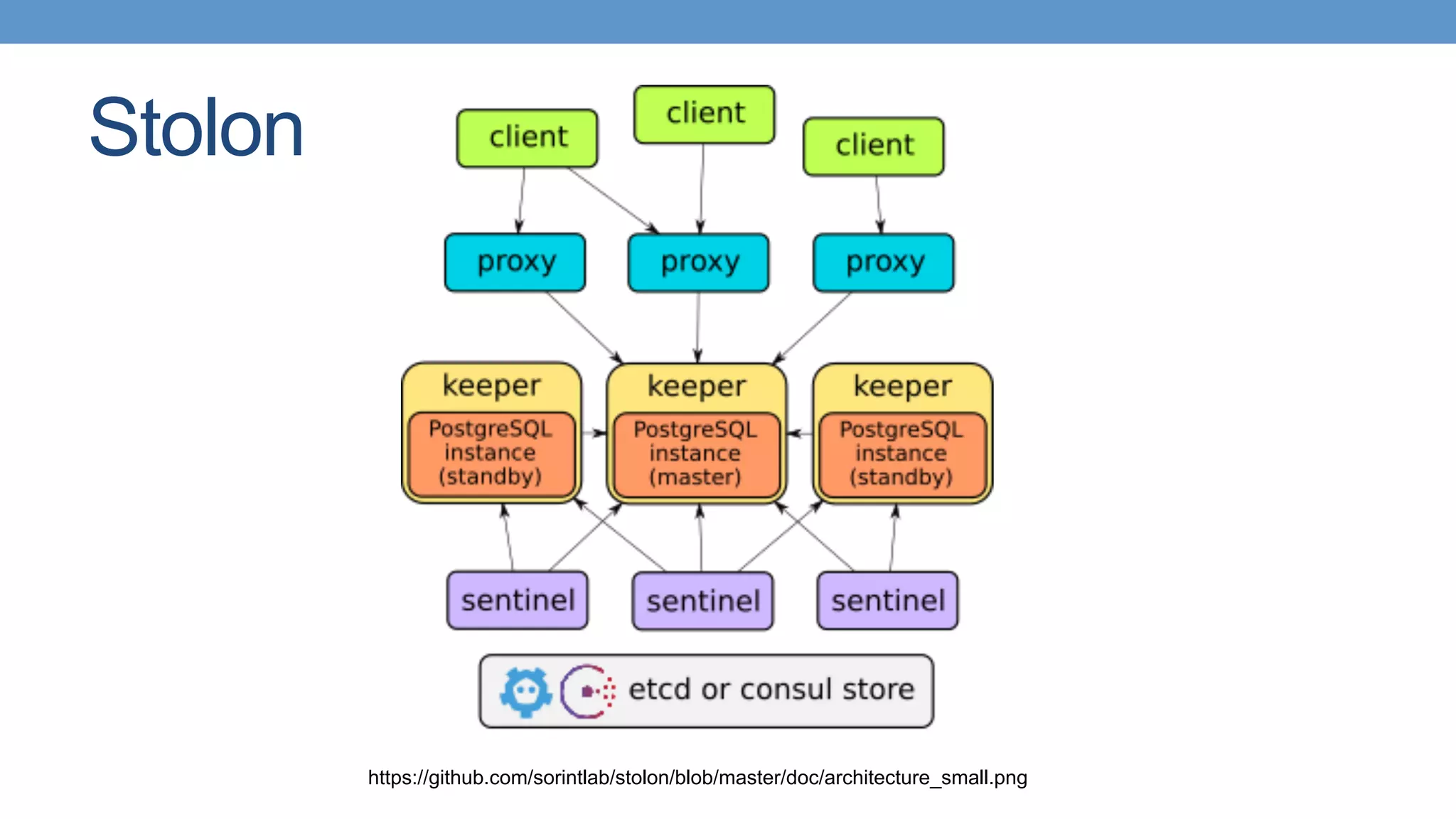
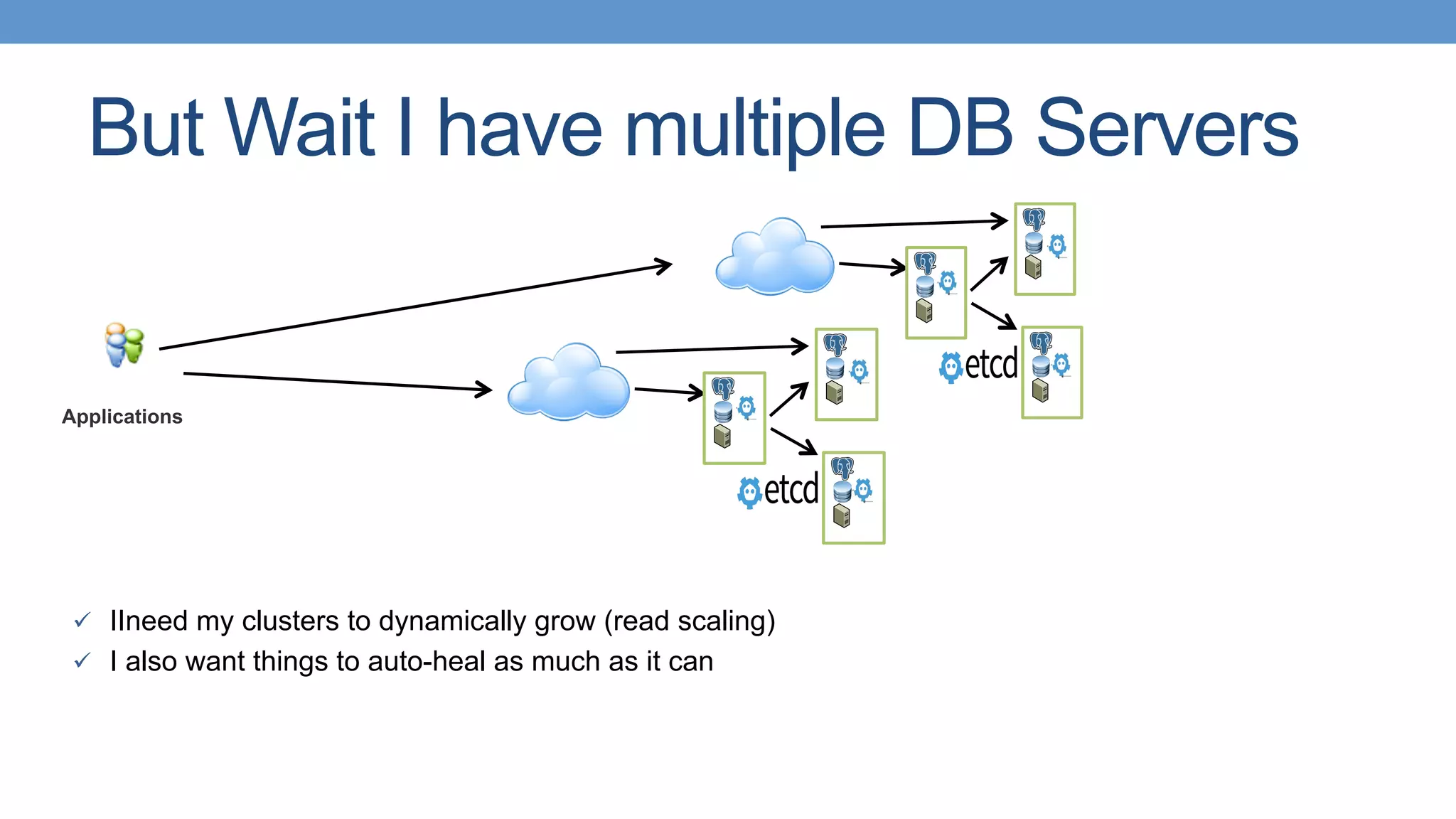
Trend towards using modern tools like Patroni and Stolon for high availability in PostgreSQL.
Introduction of self-managing distributed PostgreSQL clusters and peer integration.
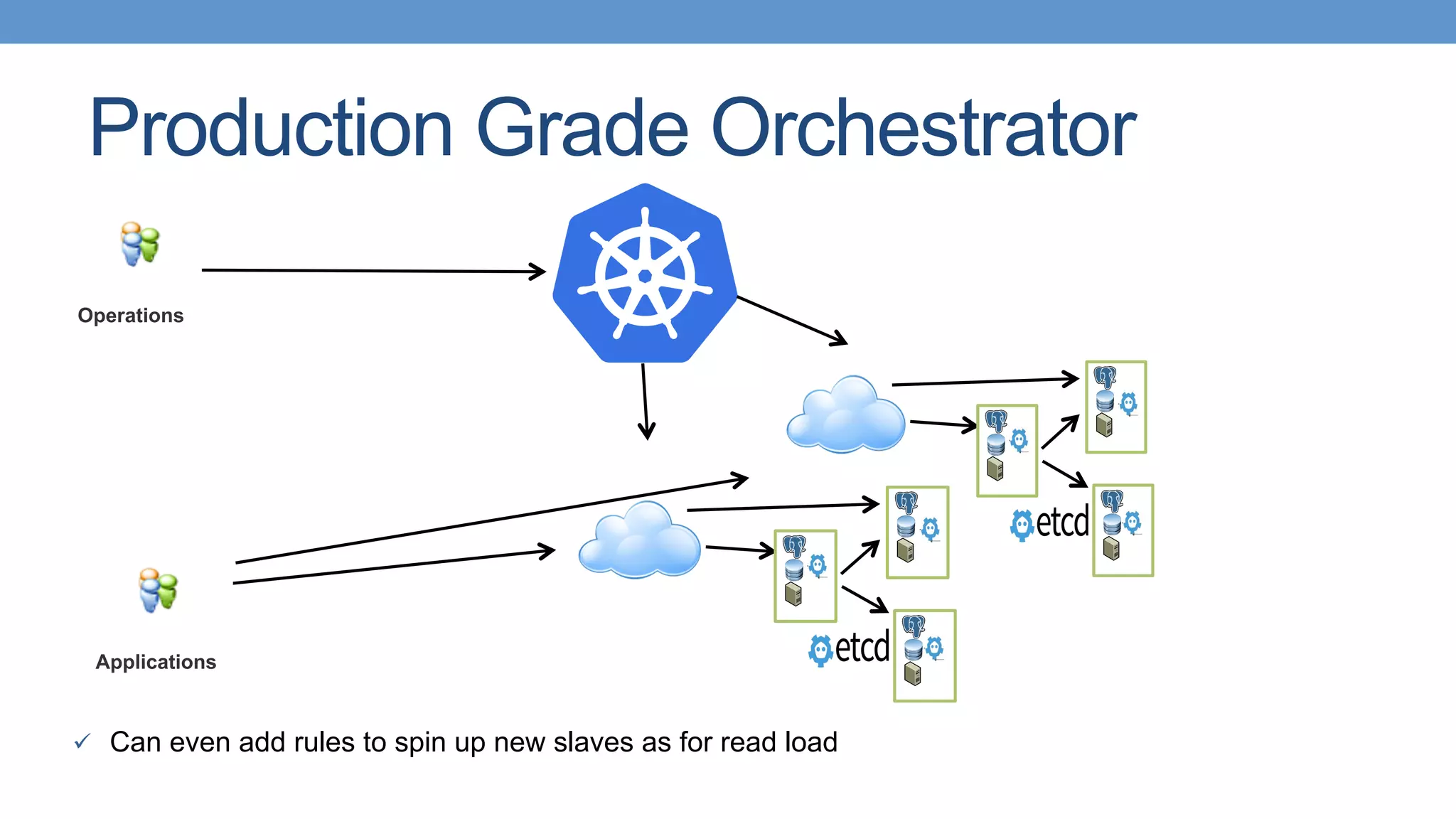
Emerging trends in container management, including microservices and deployment strategies.
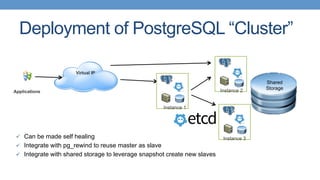
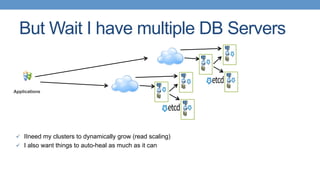
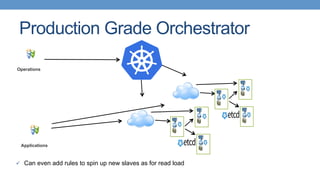
Strategies for deploying scalable PostgreSQL clusters using Kubernetes and persistent storage solutions.
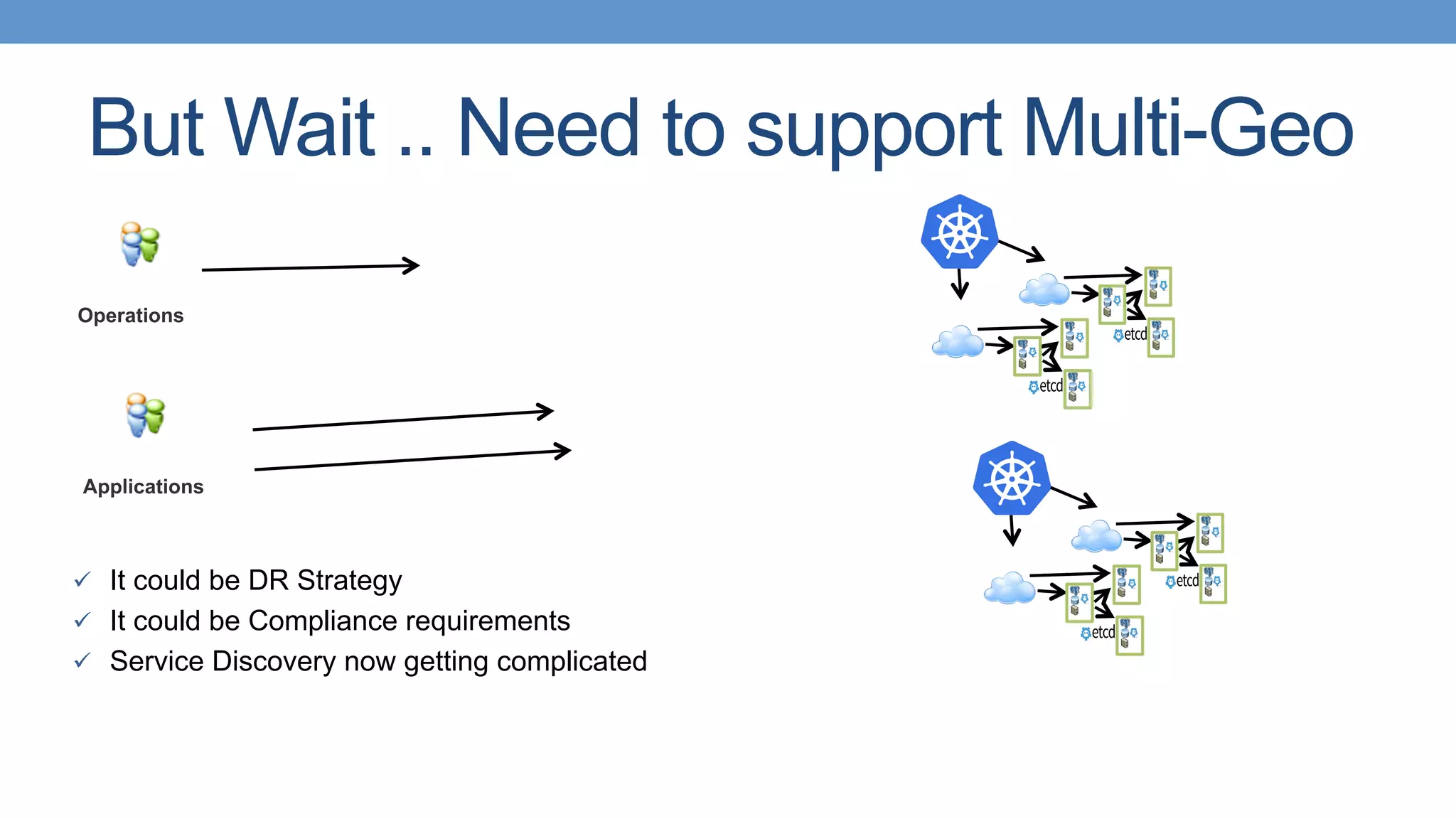
Importance of service discovery for PostgreSQL in multi-geo environments with DNS and SRV record improvements.
Summary of PostgreSQL deployment strategies and request for user feedback along with contact information.
























![[2018] MySQL 이중화 진화기](https://cdn.slidesharecdn.com/ss_thumbnails/cloudinfra03-190131073325-thumbnail.jpg?width=600ounds&width=560&fit=bounds)























































