Downloaded 947 times













![PROSITE
Families of proteins
Can search using regular expressions
Similar to unix commands using
wildcards, etc.
E.g., [AC]-x-V-x(4)-{ED}
Interpreted as:
[Ala or Cys]-any-Val-any-any-any-
any-{any but Glu or Asp}
Families exhibit these patterns
So we can search over families
http://ca.expasy.org/prosite/ 22](https://image.slidesharecdn.com/primaryandsecondarydatabasespptupdatedfinal1-170929203851/85/Primary-and-secondary-databases-ppt-by-puneet-kulyana-22-320.jpg)





















![PROSITE
Families of proteins
Can search using regular expressions
Similar to unix commands using
wildcards, etc.
E.g., [AC]-x-V-x(4)-{ED}
Interpreted as:
[Ala or Cys]-any-Val-any-any-any-
any-{any but Glu or Asp}
Families exhibit these patterns
So we can search over families
http://ca.expasy.org/prosite/ 22](https://image.slidesharecdn.com/primaryandsecondarydatabasespptupdatedfinal1-170929203851/75/Primary-and-secondary-databases-ppt-by-puneet-kulyana-22-2048.jpg)







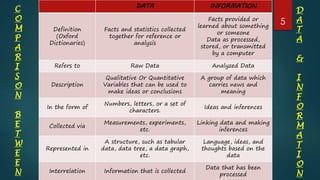
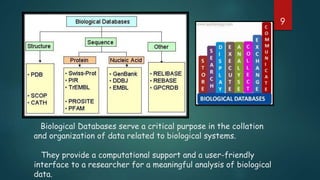
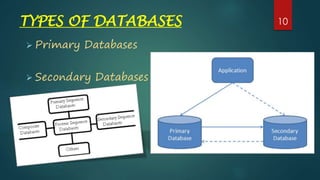
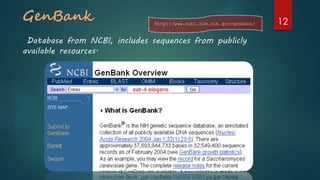
This document provides an introduction to databases used for biological data. It defines key terms like data, information, and databases. It describes different types of biological databases including primary databases that contain original experimental data, and secondary databases that contain derived or analyzed data. Examples of primary databases include GenBank, EMBL, and PDB, while secondary databases include PROSITE, PRINTS, and Pfam that contain conserved protein motifs and families. The document also compares primary and secondary databases.
An opening overview of databases and the presentation's structure, including topics like introduction, data, information, and types of databases.
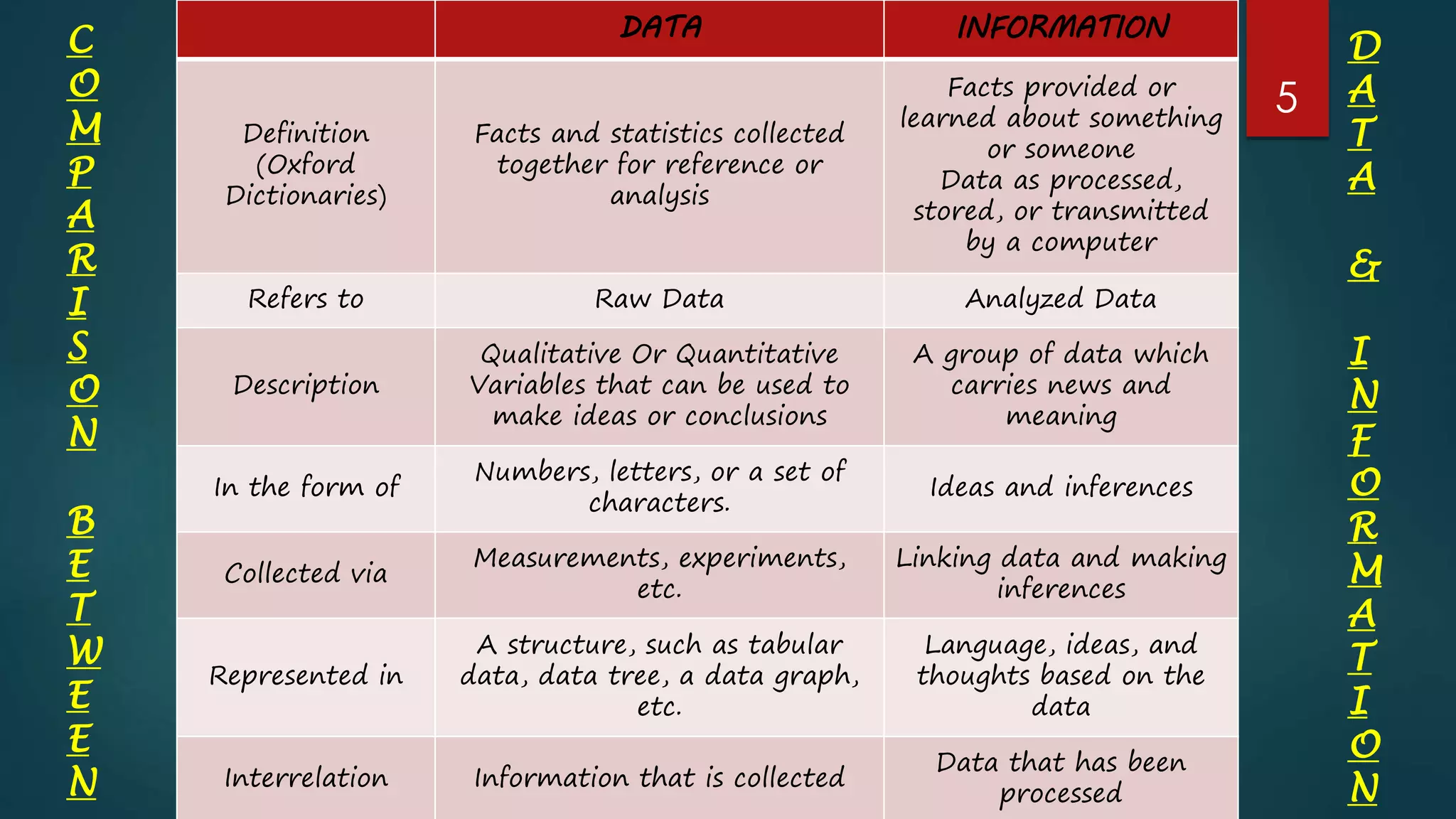
Defines data as raw facts and information as processed data with examples, emphasizing their differences and importance in context.
Categorizes different data types in databases, providing examples like biomolecule sequences and literature databases.
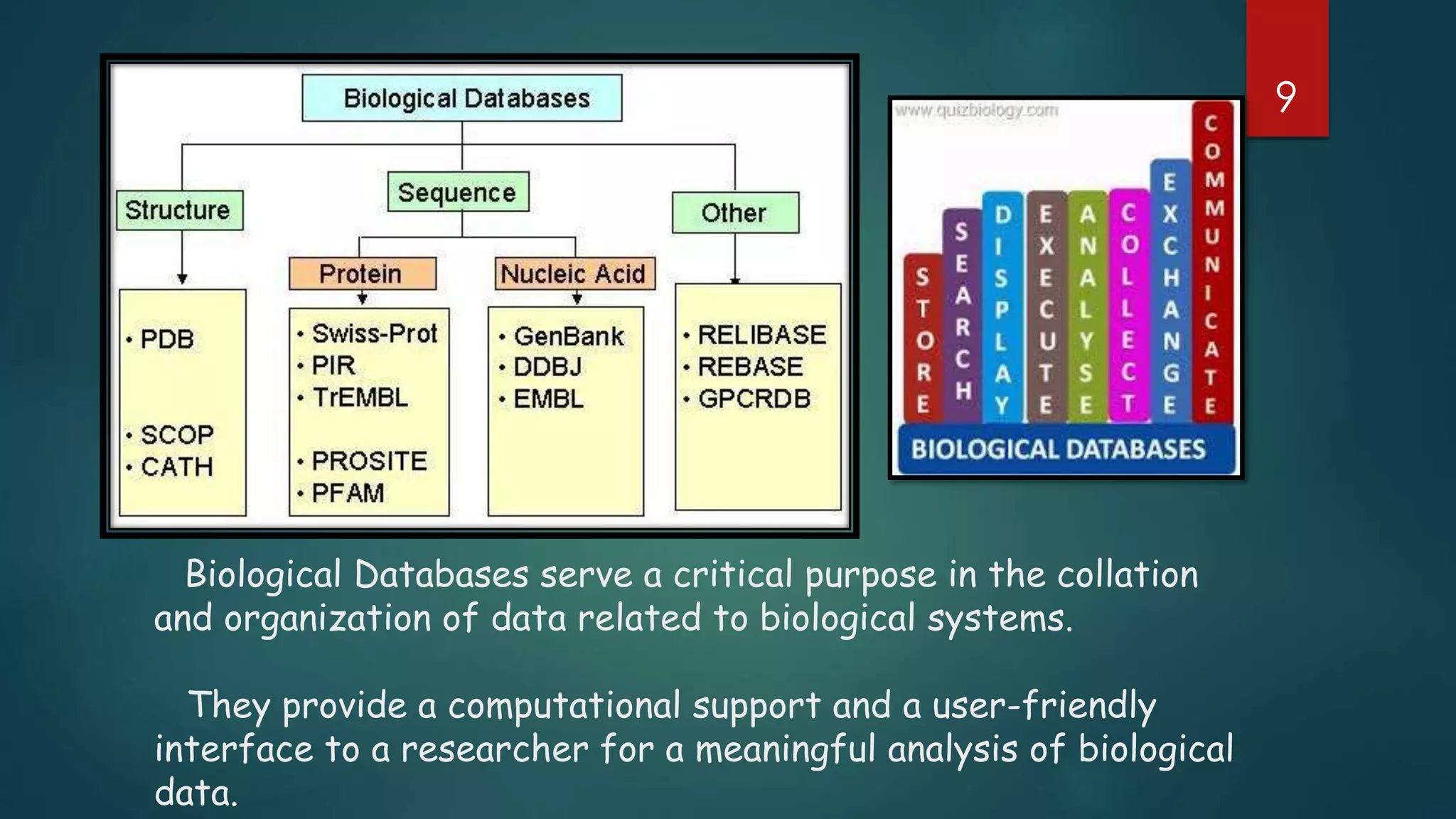
Explains the significance of biological databases in organizing data for meaningful biological analysis.
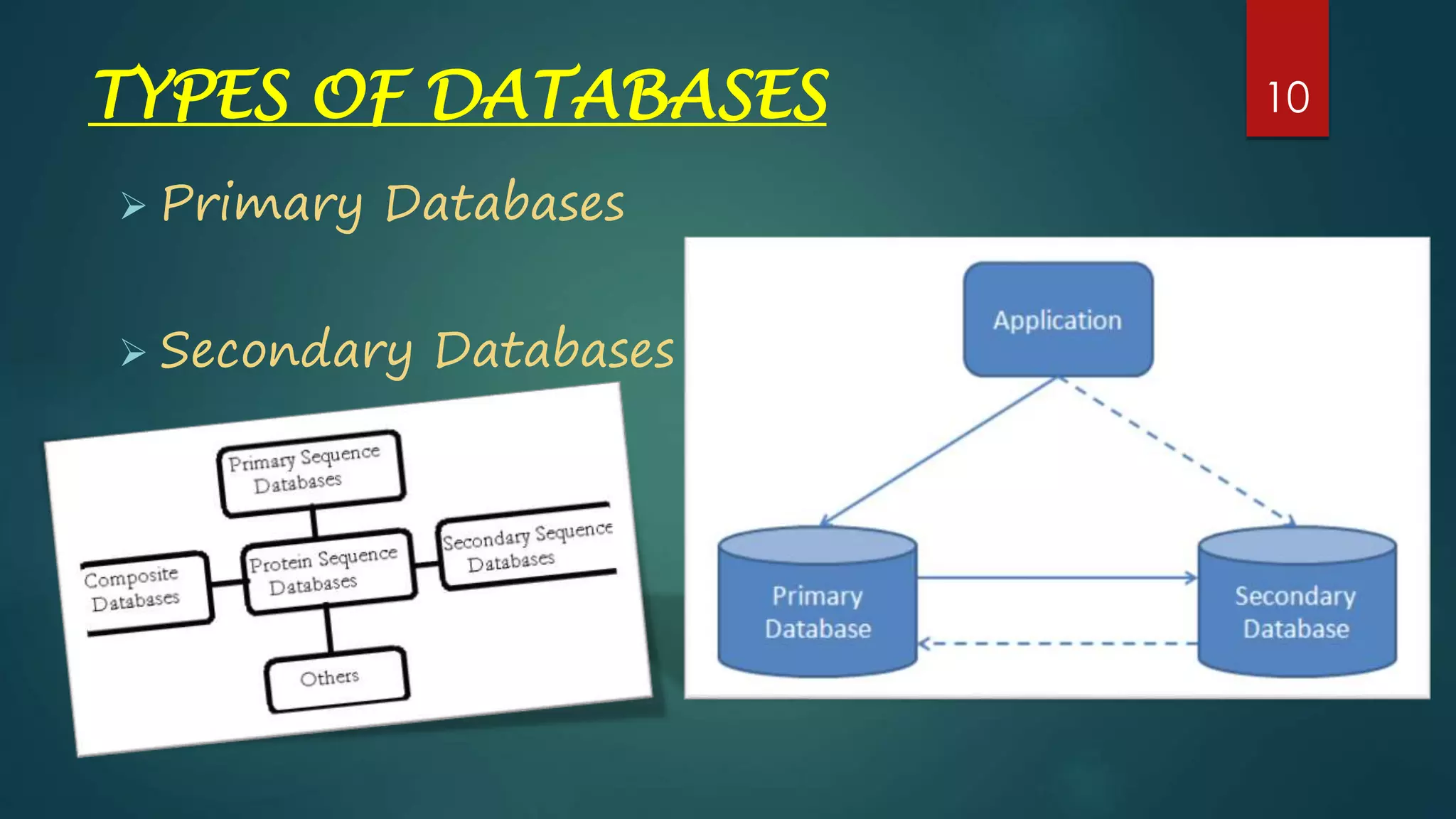
Introduces primary and secondary databases, setting the stage for detailed discussions in upcoming slides.
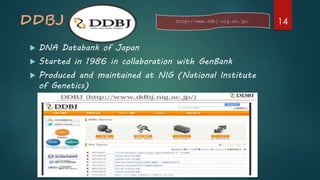
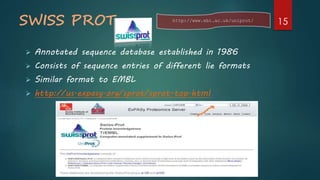
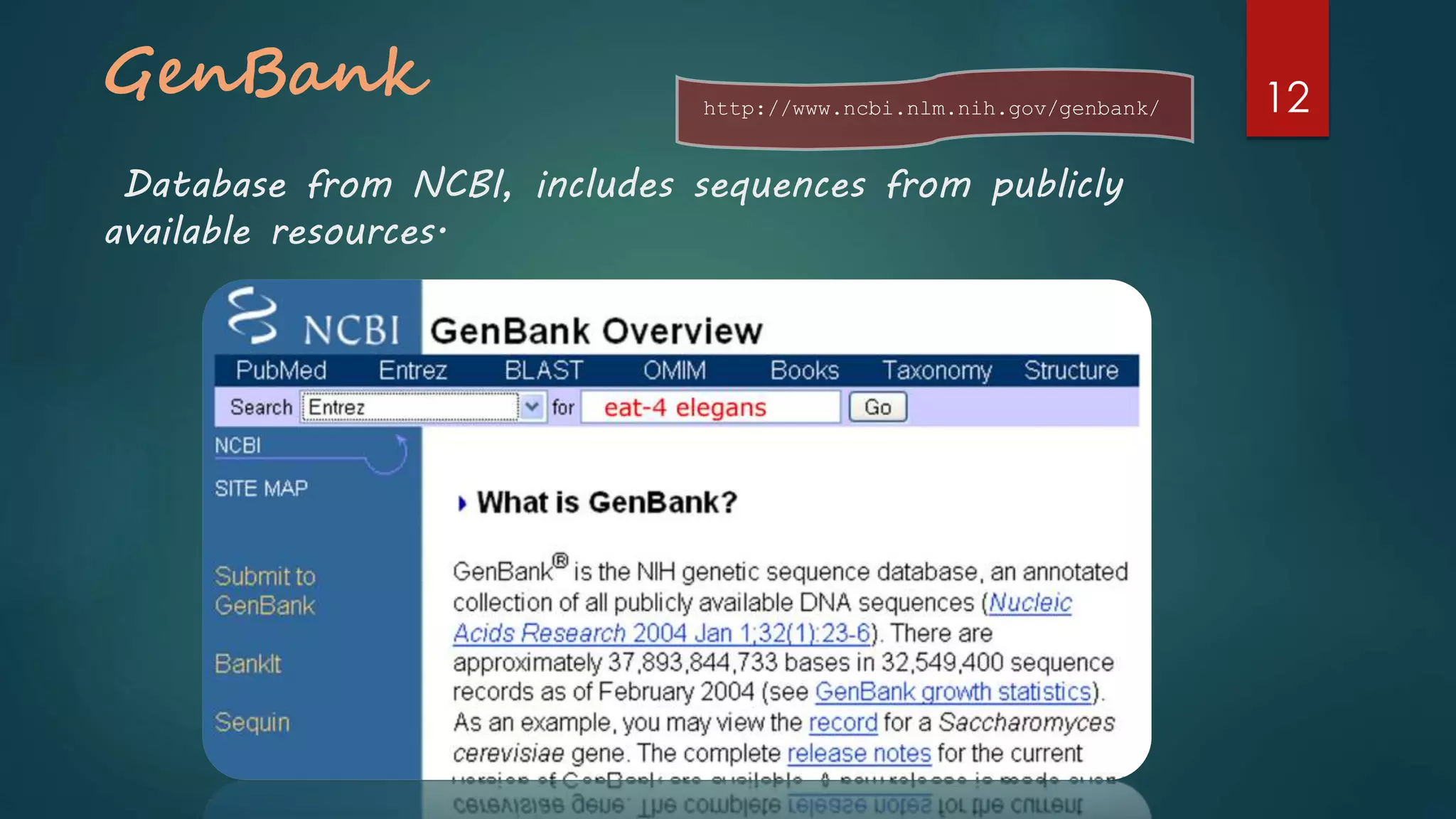
Describes primary databases with examples like GenBank and SWISS-PROT which store original bio-molecular data.
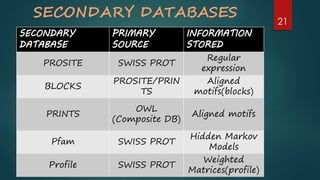
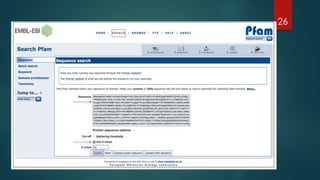
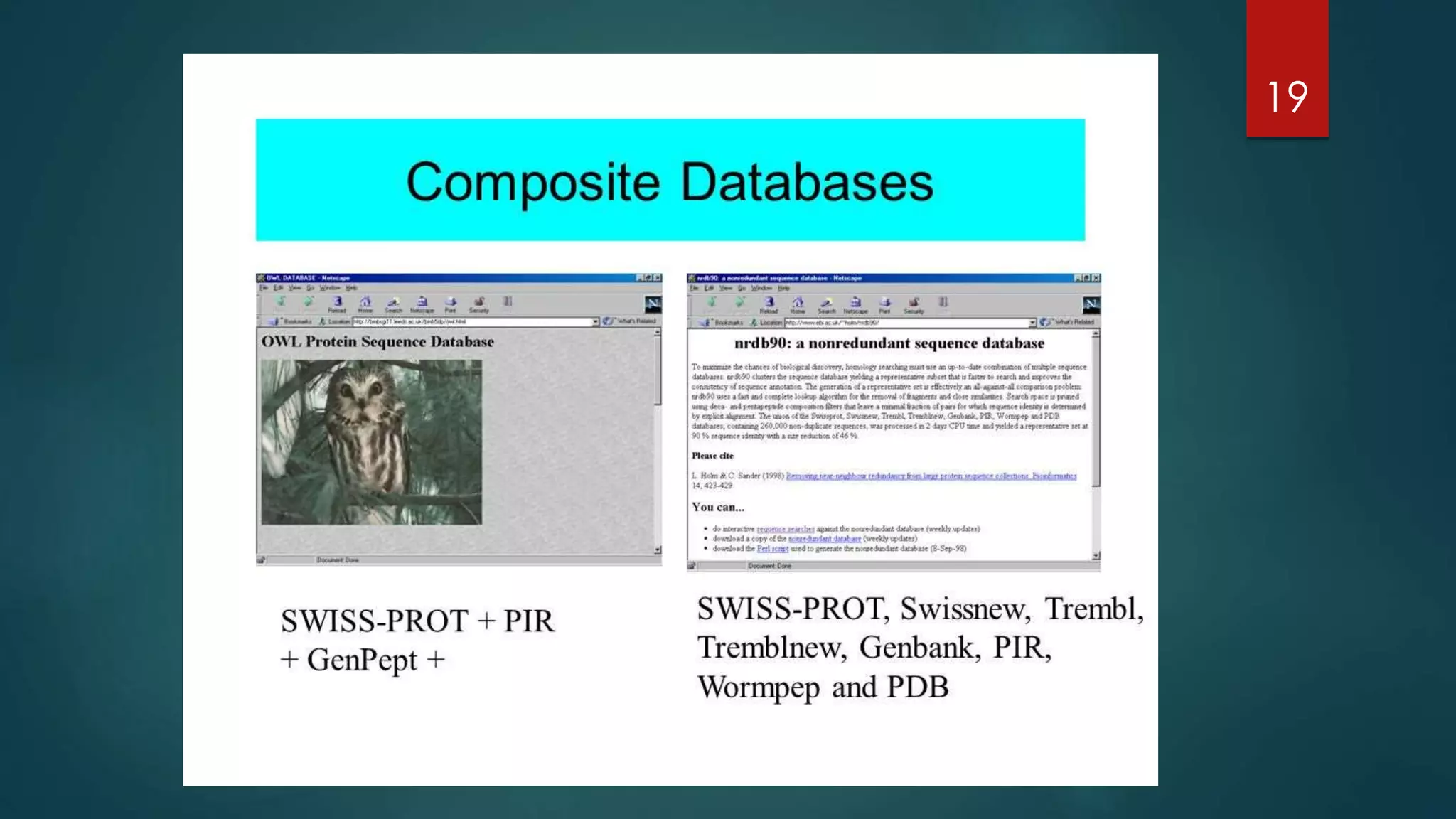
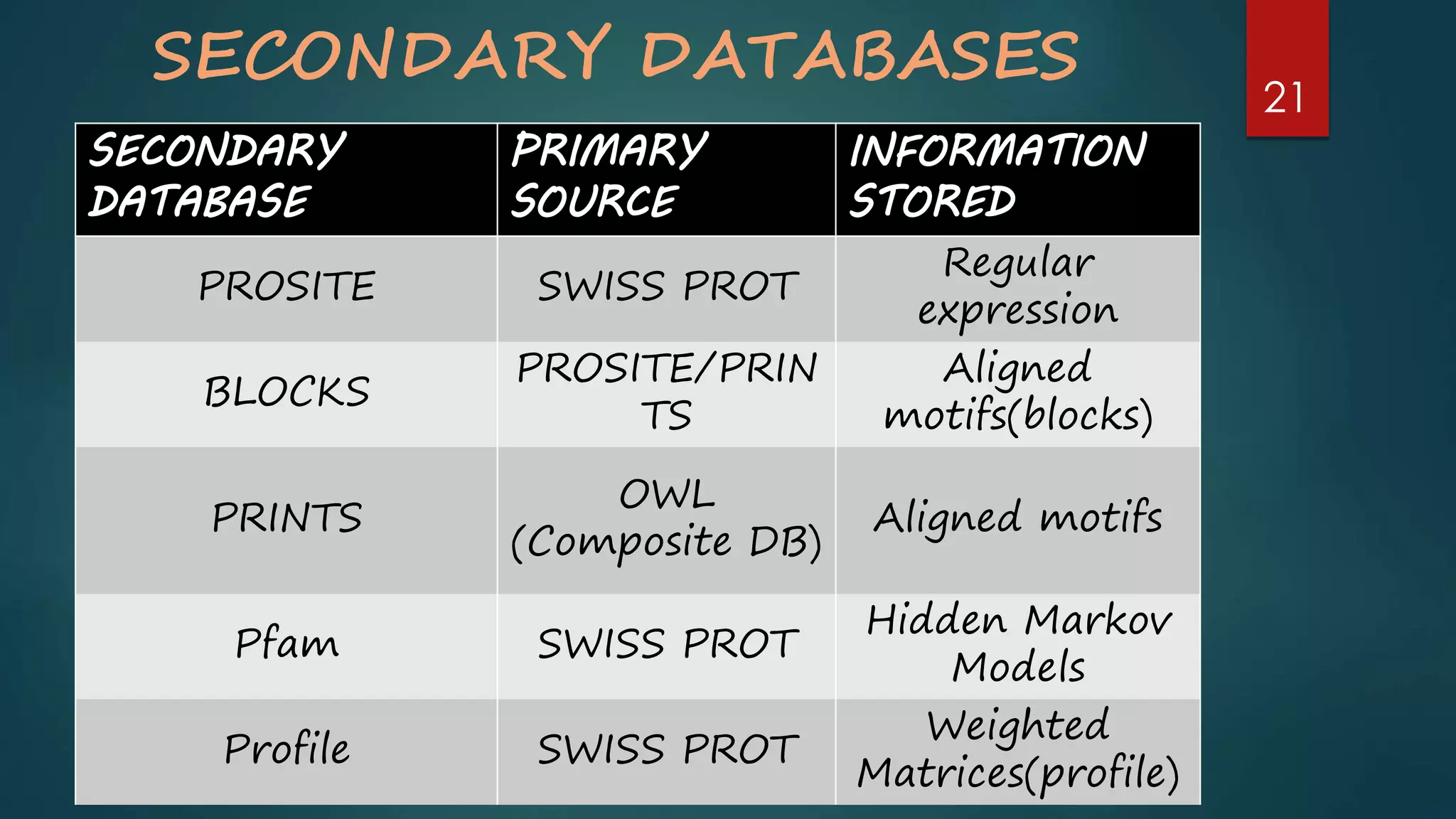
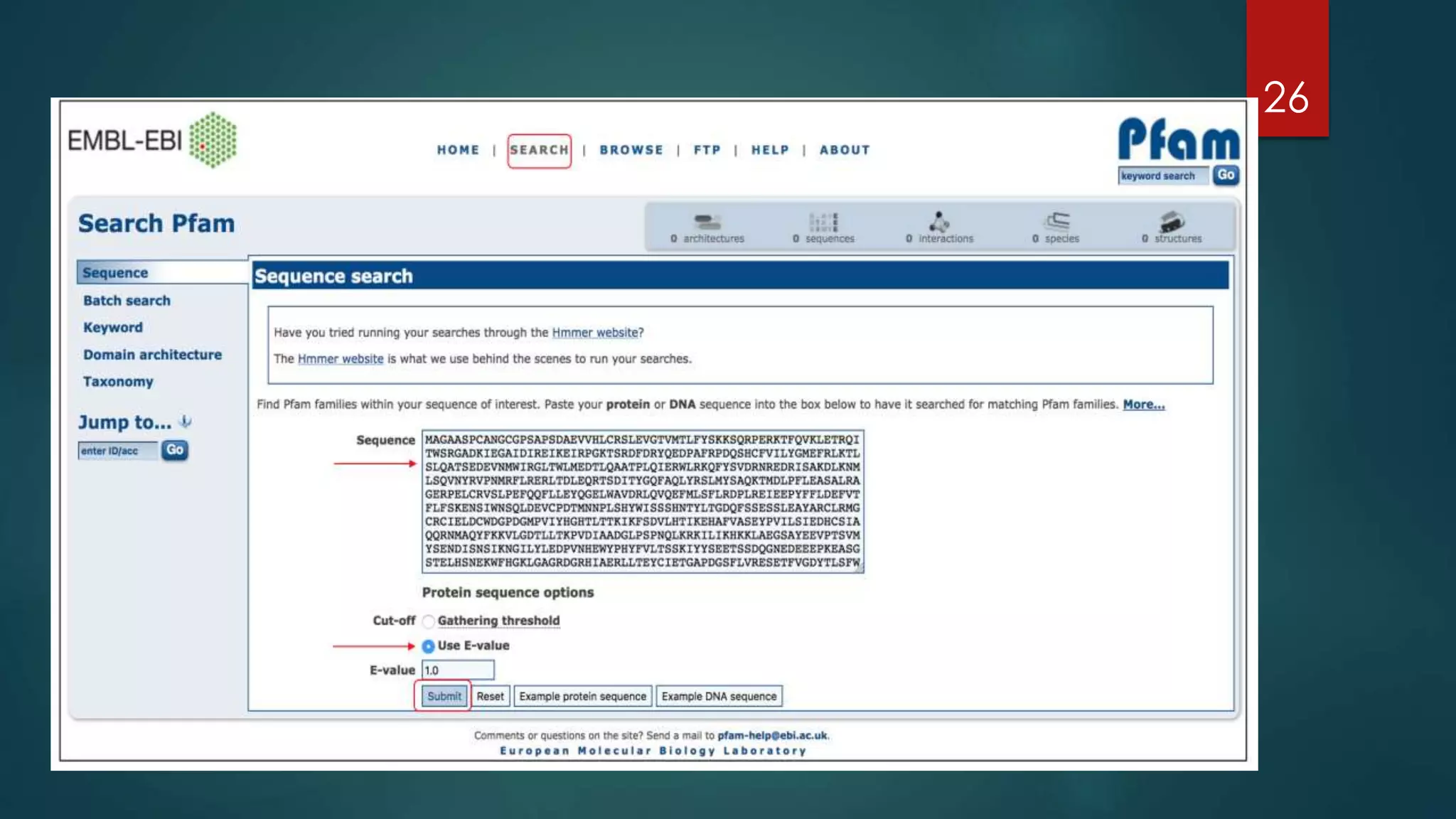
Details secondary databases which contain derived data, with examples like PROSITE and Pfam that facilitate protein family analysis.
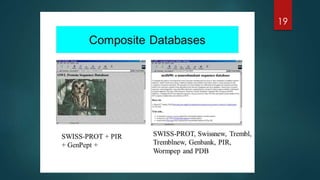
A comparison of primary and secondary databases, highlighting their roles within biological data management.
List of references that supported the presentation, including course materials and online resources.



































































