Downloaded 75 times













![pySpark Shared Variables
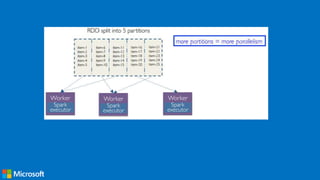
• Broadcast Variables
» Efficiently send large, read-only value to all workers
» Saved at workers for use in one or more Spark operations
» Like sending a large, read-only lookup table to all the nodes
At the driver: broadcastVar = sc.broadcast([1, 2, 3])
At a worker: broadcastVar.value](https://image.slidesharecdn.com/programminginsparkusingpyspark-public-170217010224/85/Programming-in-Spark-using-PySpark-16-320.jpg)
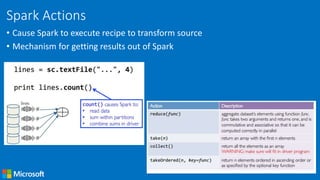
![• Accumulators
» Aggregate values from workers back to driver
» Only driver can access value of accumulator
» For tasks, accumulators are write-only
» Use to count errors seen in RDD across workers
>>> accum = sc.accumulator(0)
>>> rdd = sc.parallelize([1, 2, 3, 4])
>>> def f(x):
>>> global accum
>>> accum += x
>>> rdd.foreach(f)
>>> accum.value
Value: 10](https://image.slidesharecdn.com/programminginsparkusingpyspark-public-170217010224/85/Programming-in-Spark-using-PySpark-17-320.jpg)

















![pySpark Shared Variables
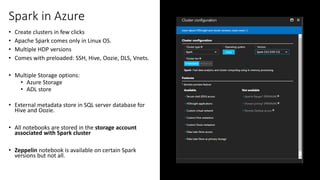
• Broadcast Variables
» Efficiently send large, read-only value to all workers
» Saved at workers for use in one or more Spark operations
» Like sending a large, read-only lookup table to all the nodes
At the driver: broadcastVar = sc.broadcast([1, 2, 3])
At a worker: broadcastVar.value](https://image.slidesharecdn.com/programminginsparkusingpyspark-public-170217010224/75/Programming-in-Spark-using-PySpark-16-2048.jpg)
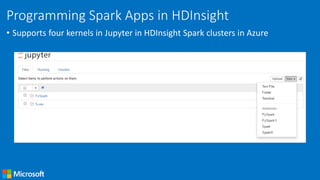
![• Accumulators
» Aggregate values from workers back to driver
» Only driver can access value of accumulator
» For tasks, accumulators are write-only
» Use to count errors seen in RDD across workers
>>> accum = sc.accumulator(0)
>>> rdd = sc.parallelize([1, 2, 3, 4])
>>> def f(x):
>>> global accum
>>> accum += x
>>> rdd.foreach(f)
>>> accum.value
Value: 10](https://image.slidesharecdn.com/programminginsparkusingpyspark-public-170217010224/75/Programming-in-Spark-using-PySpark-17-2048.jpg)








The document outlines the fundamentals of programming with Apache Spark using PySpark, covering session objectives, RDDs, transformations and actions, and visualizing big data. It details the structure of Spark programs which include driver and worker nodes, the creation and manipulation of RDDs, and the usage of shared variables like broadcast and accumulators. Additionally, it discusses the deployment of Spark in cloud environments like Azure and provides resources for further learning.
Overview of programming in Spark with a focus on PySpark, introduced by Mostafa Elzoghbi.
Key objectives include programming with Spark, structural elements, RDDs, transformations, visualizing big data and cloud integration.
Introduction of PySpark as a Python interface to Spark, simplifying parallel operations on large datasets.
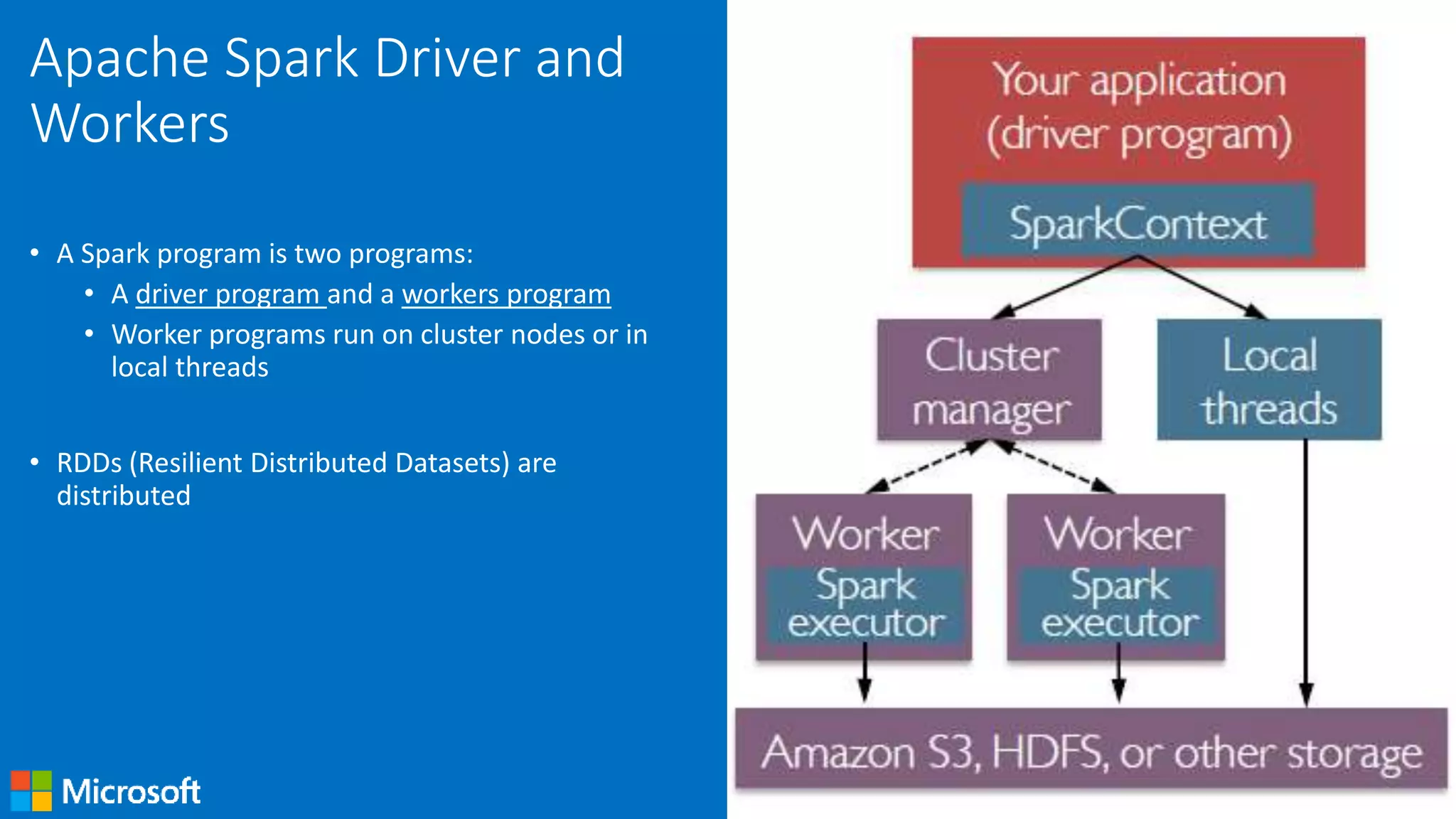
Details on Spark Driver and Worker programs, SparkContext's role in accessing clusters, and essentials for managing them.
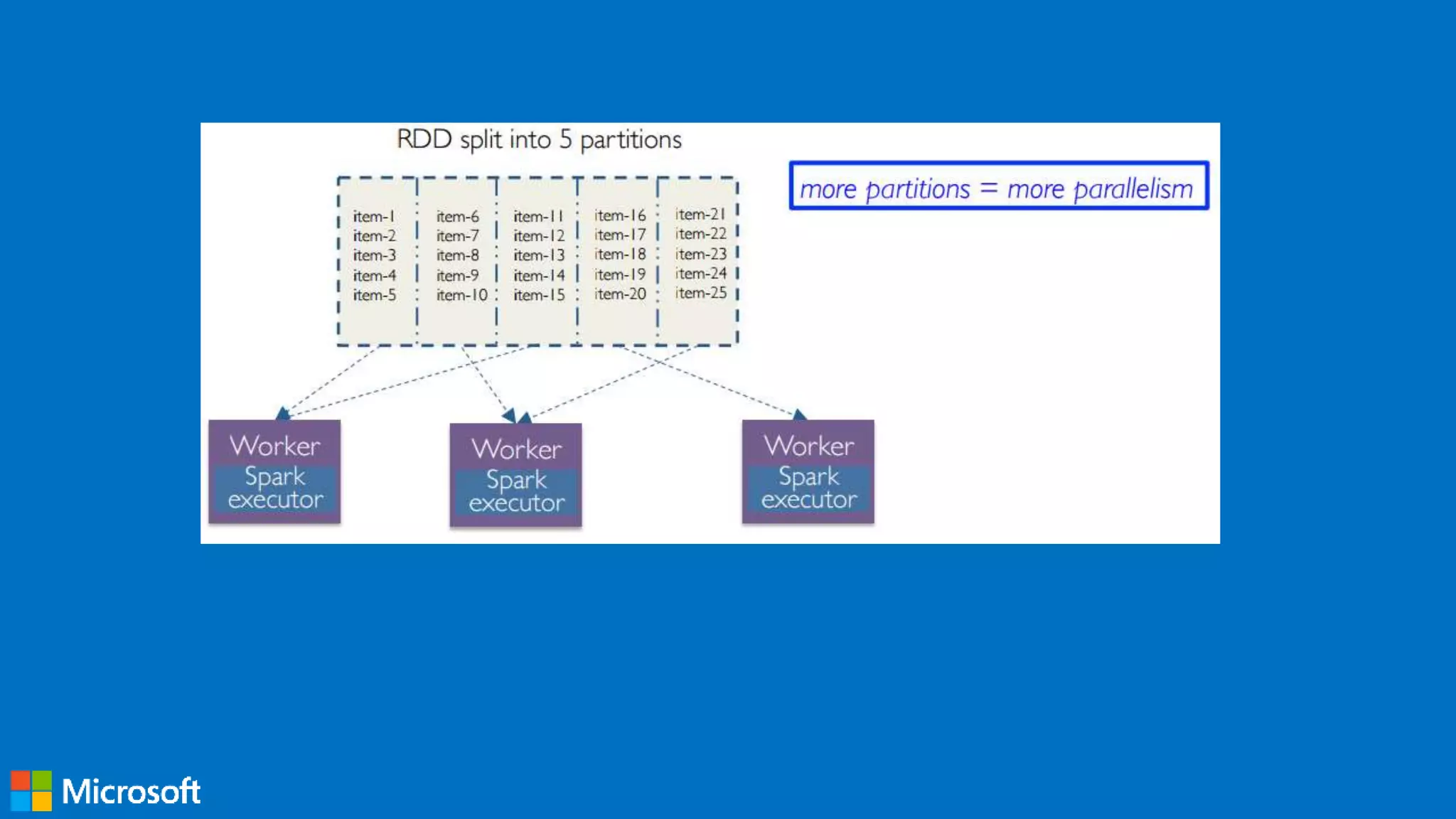
Definition and importance of Resilient Distributed Datasets (RDDs) in Spark, covering transformations and actions.
Methods for creating RDDs from various sources, including Python collections, and applying transformations and actions.
Explanation of lazy evaluation in transformations, optimization, and failure recovery when creating new datasets.
Description of lambda functions in Python that can be used in Spark operations, highlighting their simplicity and utility.
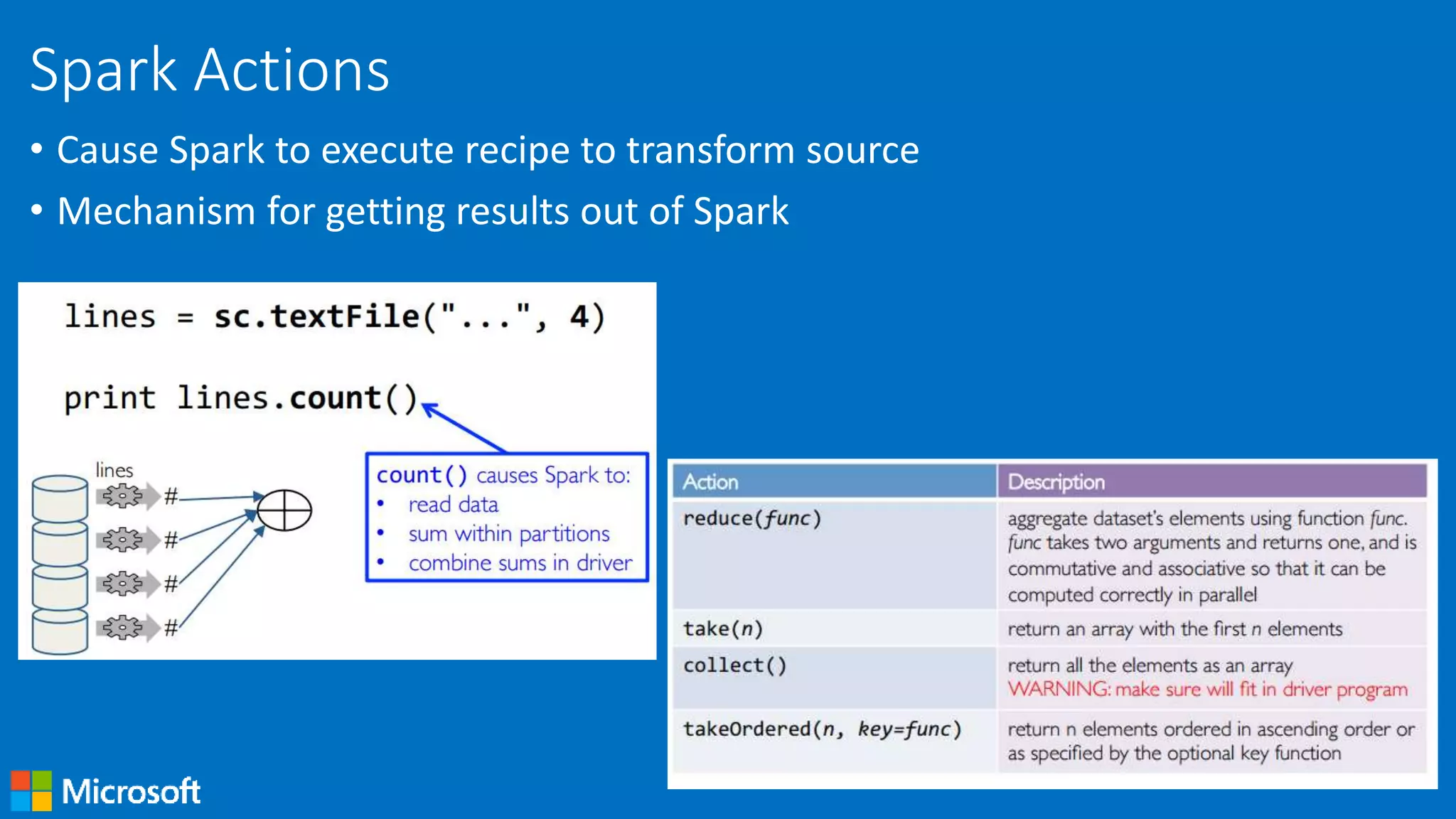
Actions in Spark that trigger computation, allowing results to be collected and returned.
Overview of the lifecycle stages of a Spark program including RDD creation, transformation, caching, and action execution.
Details about broadcast variables for efficient data sharing among workers and accumulators for aggregating values.
Challenges in visualizing big data and methods such as aggregation, sampling, and models to handle large datasets.
Usage of PySpark kernels and supported IPython magic keywords to enhance functionality with Spark in notebooks.
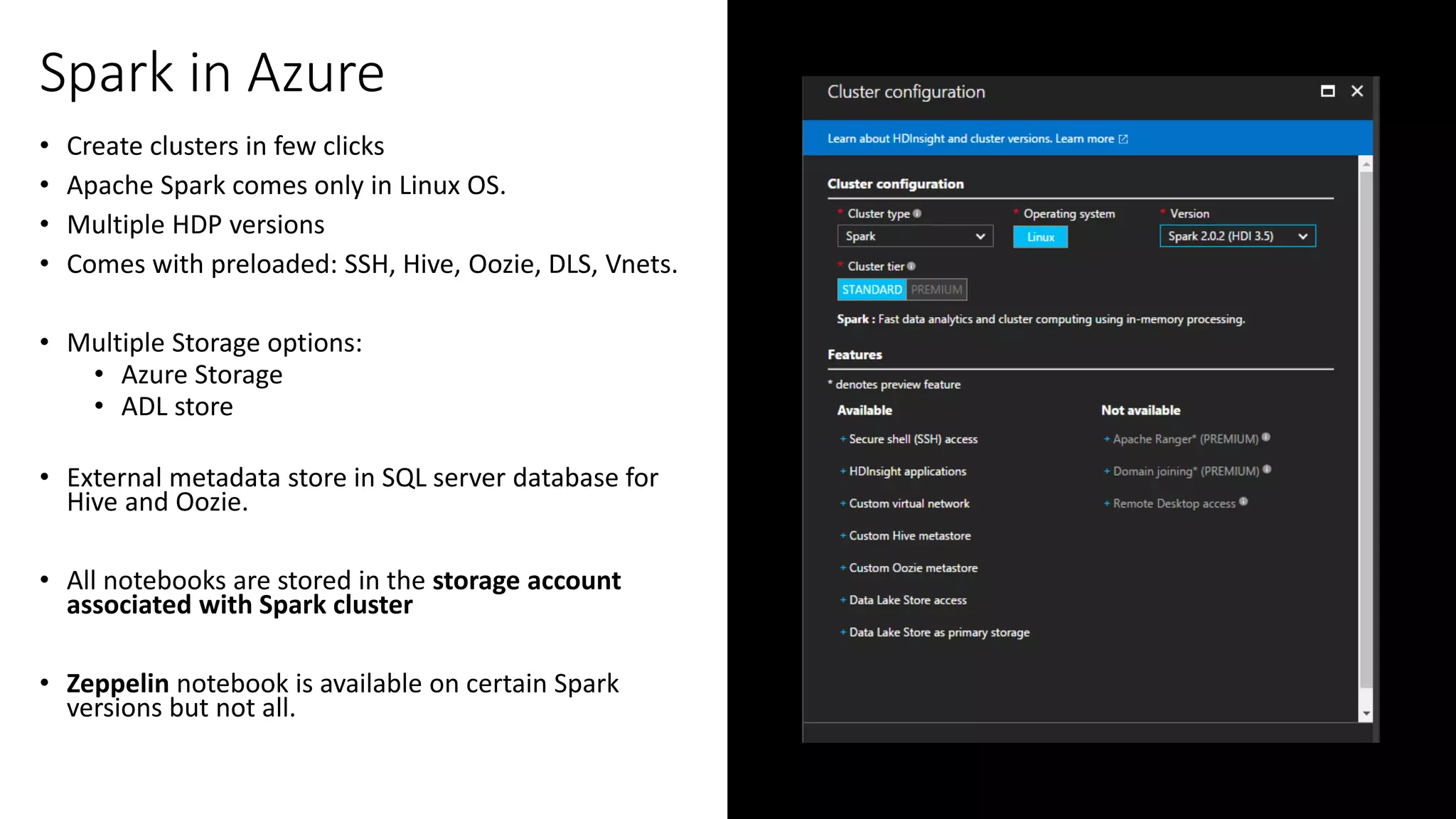
Deployment of Spark in Azure through HDInsight, including cluster setup, storage options, and notebook capabilities.
Live demonstration of building and running Spark applications using Jupyter notebooks within Azure.
A list of references for further reading including the Spark programming guide and additional resources for learning.
Concluding the presentation with contact information, blogging, and invitations for further engagement on cloud solutions.








![[DSC Europe 22] Overview of the Databricks Platform - Petar Zecevic](https://cdn.slidesharecdn.com/ss_thumbnails/petarzecevic-databricksoverview-221130080703-c60d93de-thumbnail.jpg?width=600ounds&width=560&fit=bounds)


































































































