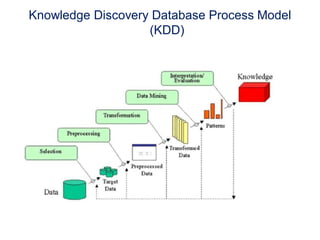
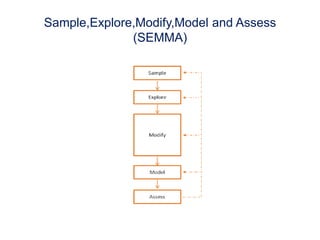
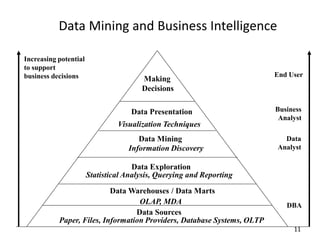
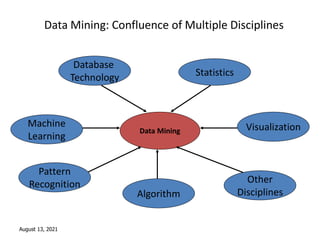
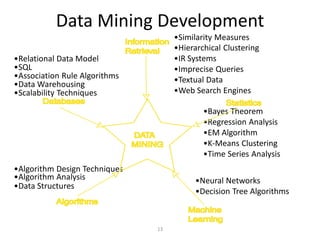
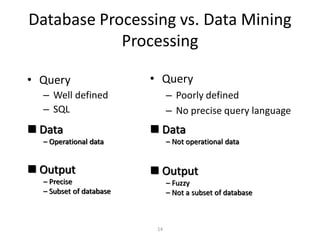
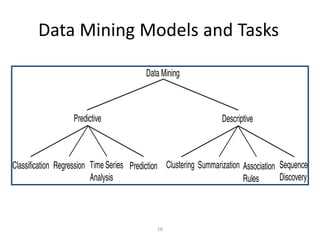
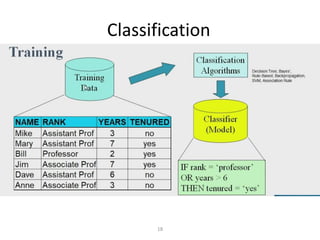
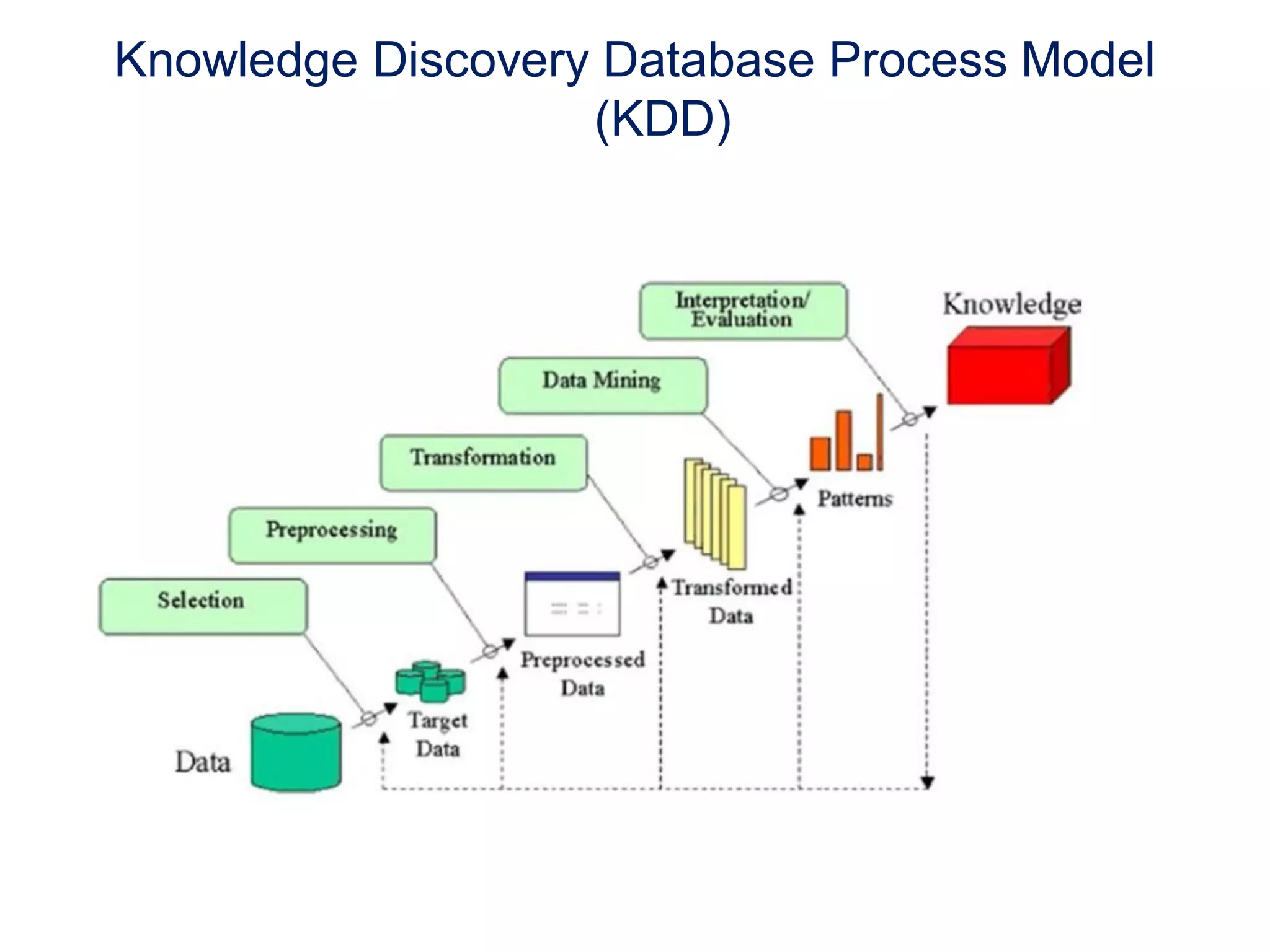
This document provides an introduction to data mining techniques. It discusses how data mining emerged due to the problem of data explosion and the need to extract knowledge from large datasets. It describes data mining as an interdisciplinary field that involves methods from artificial intelligence, machine learning, statistics, and databases. It also summarizes some common data mining frameworks and processes like KDD, CRISP-DM and SEMMA.















![August 13, 2021
Data Mining Functionalities
• Multidimensional concept description: Characterization and discrimination
– Generalize, summarize, and contrast data characteristics, e.g., dry vs.
wet regions
• Frequent patterns, association, correlation vs. causality
– Diaper Beer [0.5%, 75%] (Correlation or causality?)
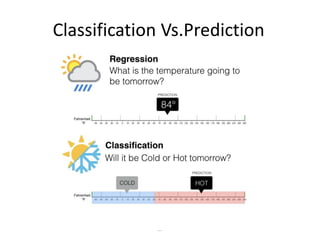
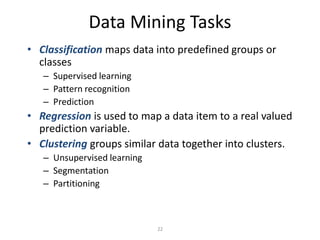
• Classification and prediction
– Construct models (functions) that describe and distinguish classes or
concepts for future prediction
• E.g., classify countries based on (climate), or classify cars based on
(gas mileage)
– Predict some unknown or missing numerical values](https://image.slidesharecdn.com/2introductoryslides-211213052722/85/2-introductory-slides-27-320.jpg)



























![August 13, 2021
Data Mining Functionalities
• Multidimensional concept description: Characterization and discrimination
– Generalize, summarize, and contrast data characteristics, e.g., dry vs.
wet regions
• Frequent patterns, association, correlation vs. causality
– Diaper Beer [0.5%, 75%] (Correlation or causality?)
• Classification and prediction
– Construct models (functions) that describe and distinguish classes or
concepts for future prediction
• E.g., classify countries based on (climate), or classify cars based on
(gas mileage)
– Predict some unknown or missing numerical values](https://image.slidesharecdn.com/2introductoryslides-211213052722/75/2-introductory-slides-27-2048.jpg)











































































