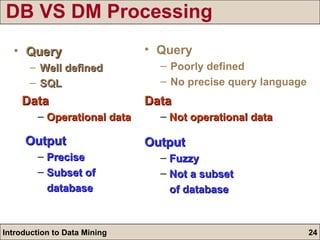
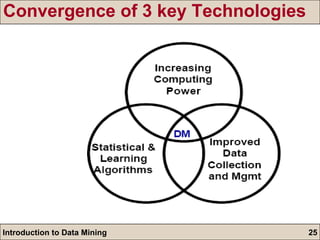
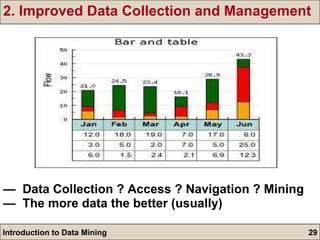
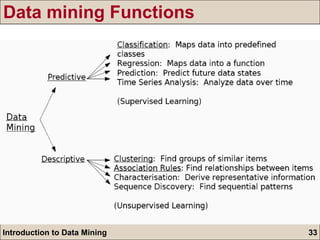
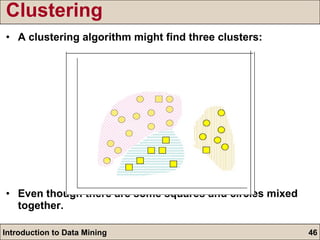
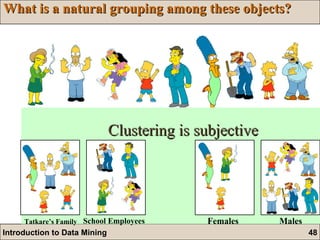
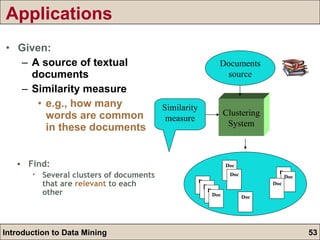
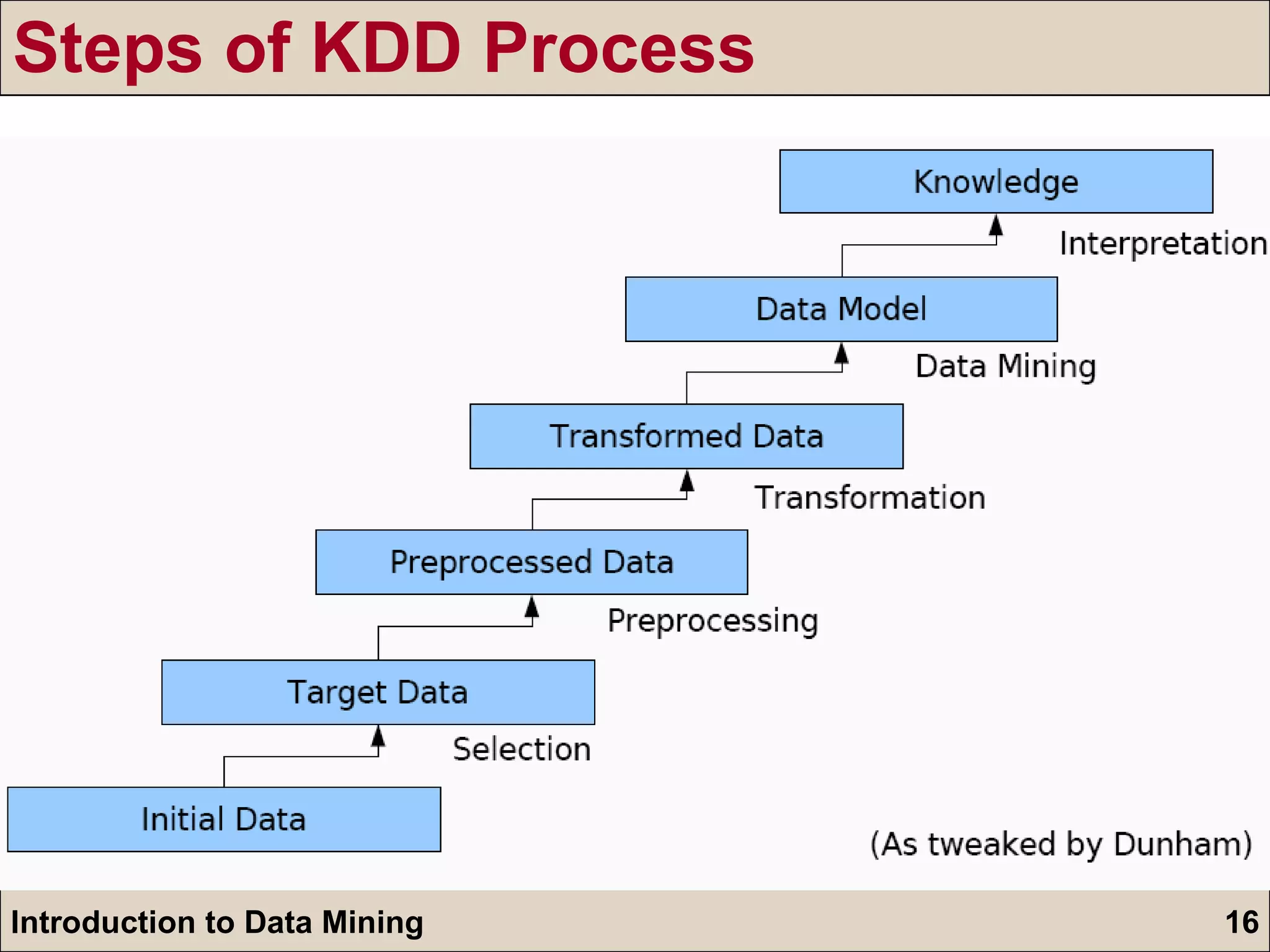
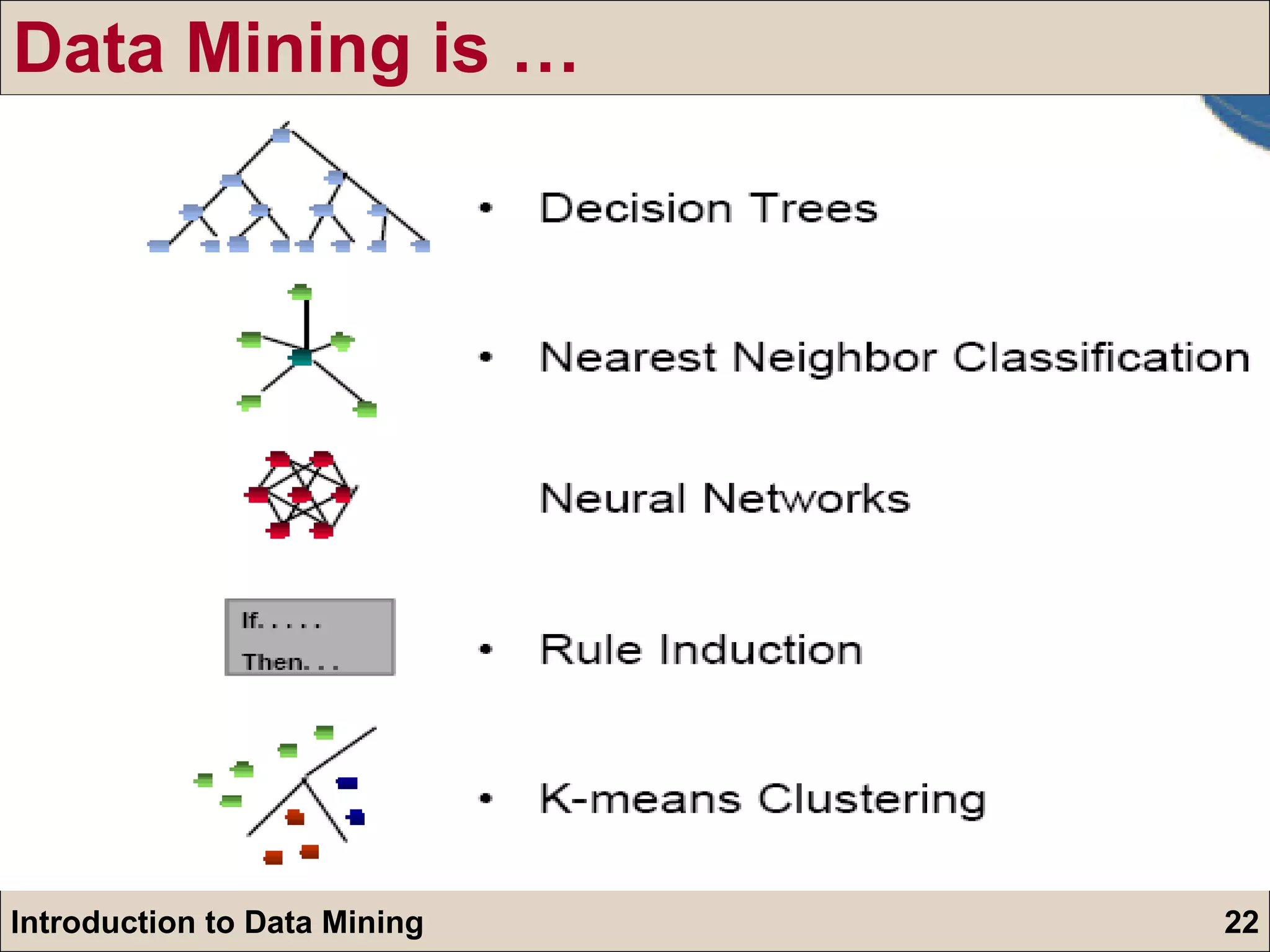
The document is an introduction to data mining, detailing its goals, processes, and functions, with a focus on the importance of databases. It describes data mining as a method for extracting useful information and patterns through the KDD (knowledge discovery in databases) process, including data selection, preprocessing, transformation, mining, and evaluation. The document further distinguishes between different types of data mining problems, such as classification, clustering, and association rules, underscoring the significance of data mining in real-world applications.













![Why Data Mining? That all sounds ... complicated. Why should I learn about Data Mining? What's wrong with just a relational database? Why would I want to go through these extra [complicated] steps? Isn't it expensive? It sounds like it takes a lot of skill, programming, computational time and storage space. Where's the benefit? Data Mining isn't just a cute academic exercise, it has very profitable real world uses. Practically all large companies and many governments perform data mining as part of their planning and analysis.](https://image.slidesharecdn.com/intrdmsndt-110903113957-phpapp01/85/Introduction-to-Data-Mining-20-320.jpg)

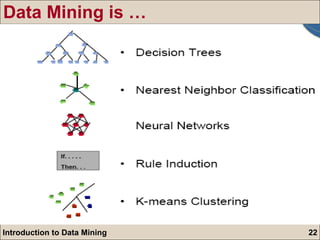





















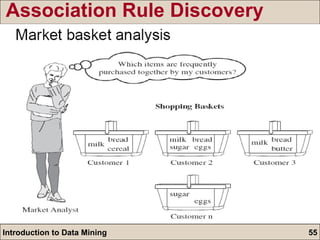

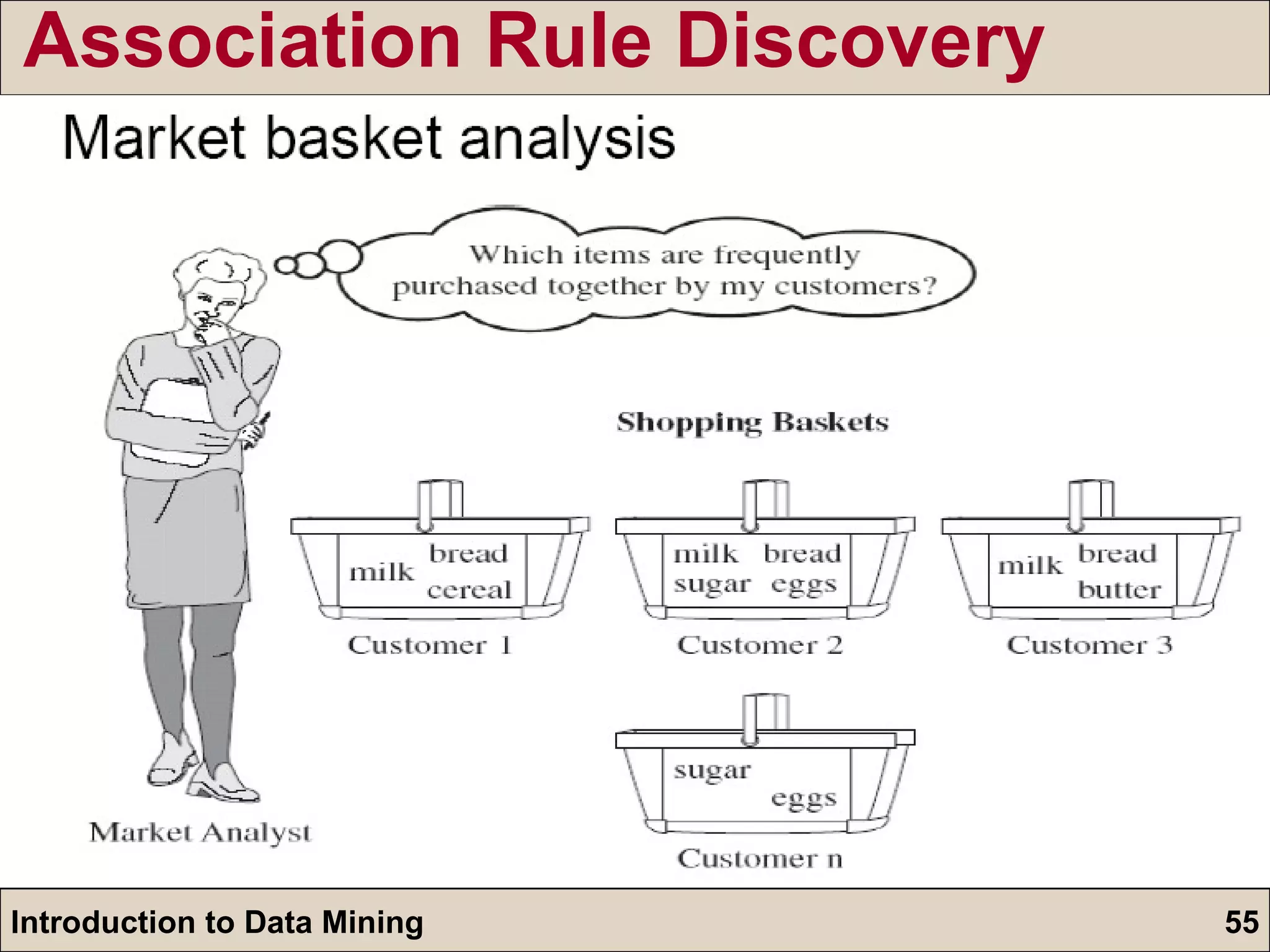
![Market basket: Rule form: “ Body ead [support, confidence] ” . buys(X, `beer') buys(X, “snacks') [1%, 60%] (a) If a customer X purchased `beer', 60% of them purchased `snacks' (b) 1% of all transactions contain the items `beer' and `snacks‘ together Association Rule Discovery](https://image.slidesharecdn.com/intrdmsndt-110903113957-phpapp01/85/Introduction-to-Data-Mining-57-320.jpg)

















![Why Data Mining? That all sounds ... complicated. Why should I learn about Data Mining? What's wrong with just a relational database? Why would I want to go through these extra [complicated] steps? Isn't it expensive? It sounds like it takes a lot of skill, programming, computational time and storage space. Where's the benefit? Data Mining isn't just a cute academic exercise, it has very profitable real world uses. Practically all large companies and many governments perform data mining as part of their planning and analysis.](https://image.slidesharecdn.com/intrdmsndt-110903113957-phpapp01/75/Introduction-to-Data-Mining-20-2048.jpg)






















![Market basket: Rule form: “ Body ead [support, confidence] ” . buys(X, `beer') buys(X, “snacks') [1%, 60%] (a) If a customer X purchased `beer', 60% of them purchased `snacks' (b) 1% of all transactions contain the items `beer' and `snacks‘ together Association Rule Discovery](https://image.slidesharecdn.com/intrdmsndt-110903113957-phpapp01/75/Introduction-to-Data-Mining-57-2048.jpg)