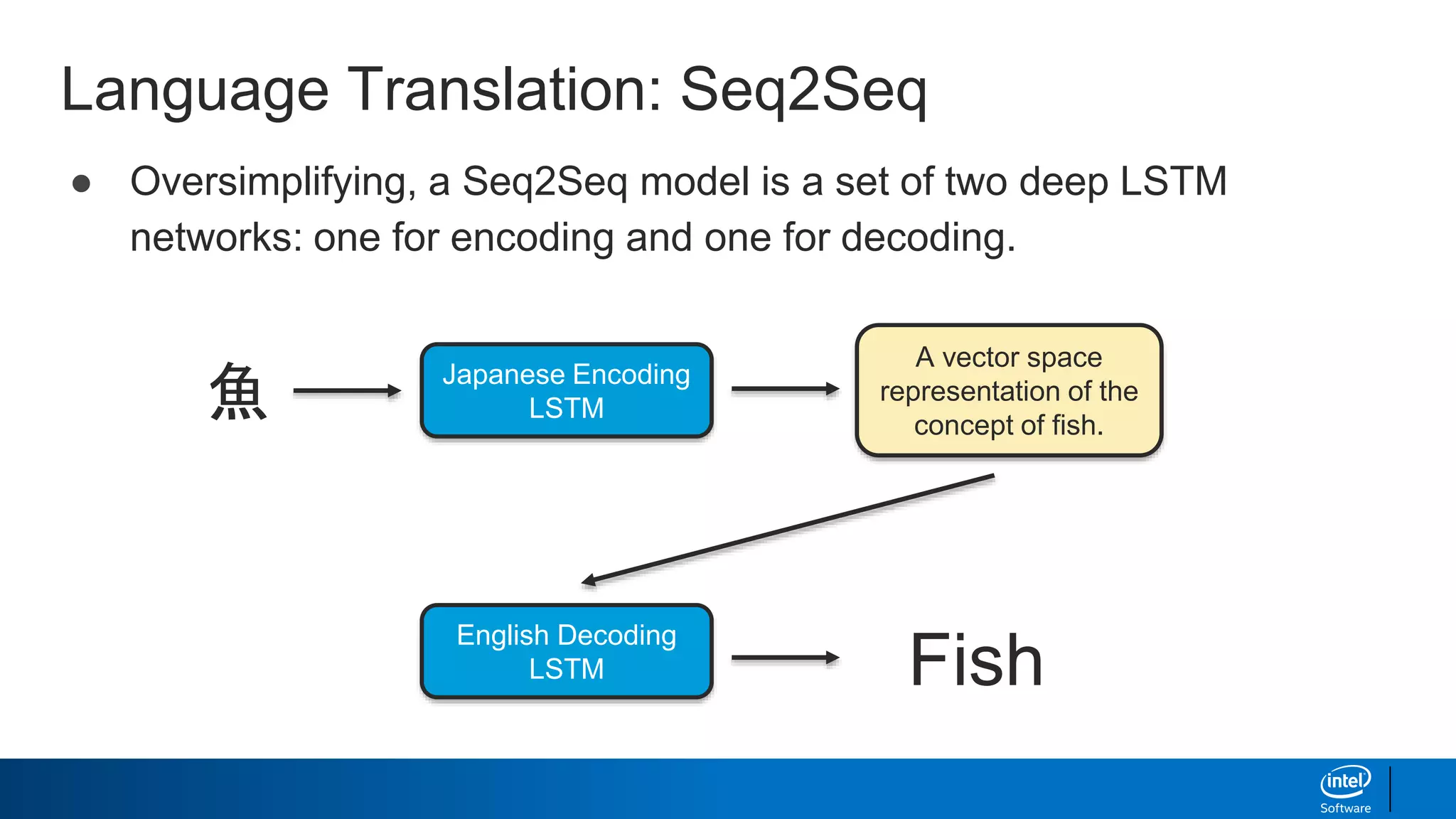
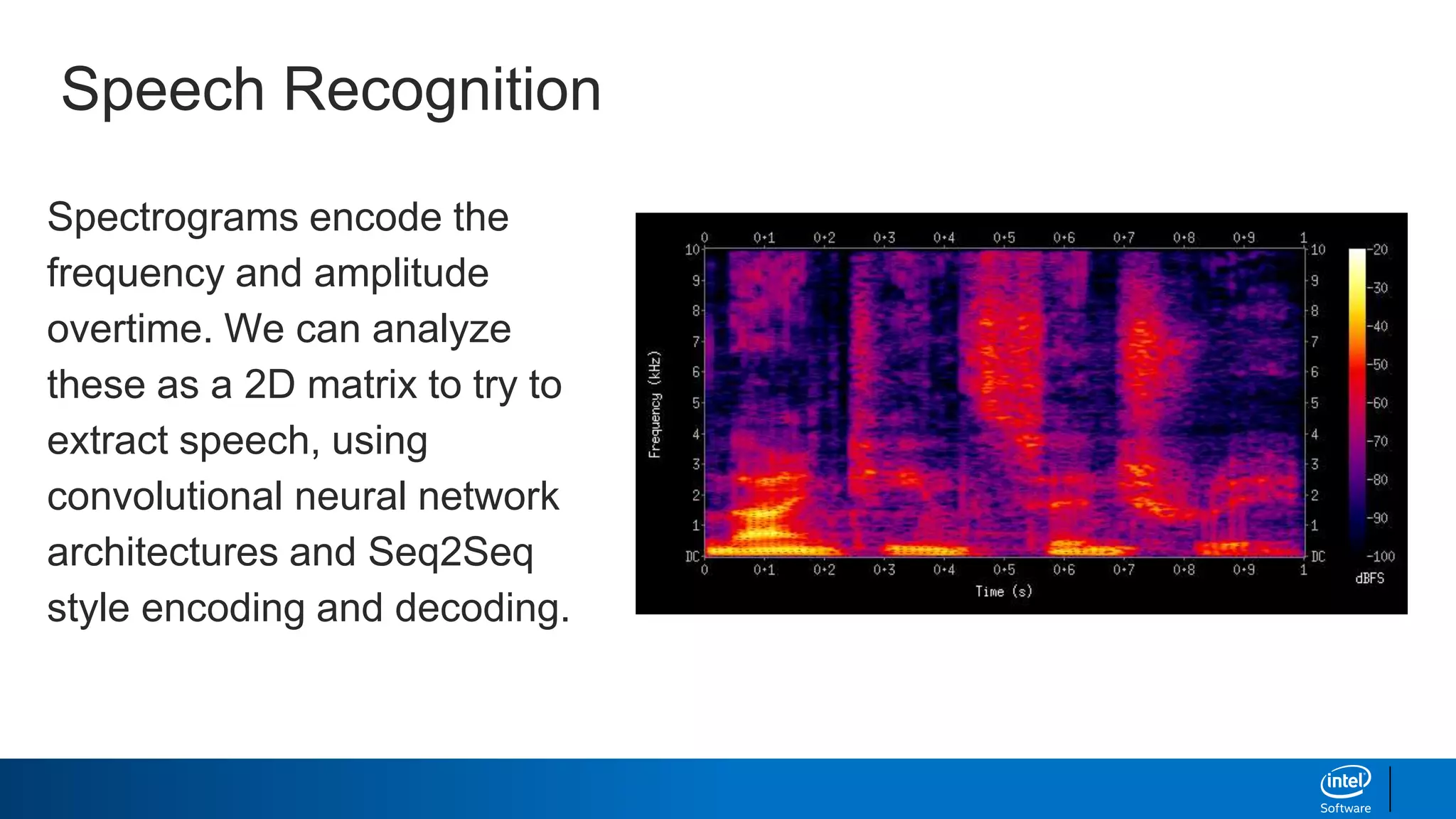
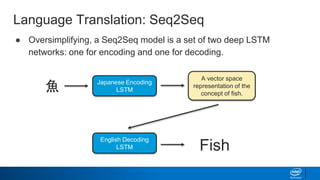
The document provides an overview of using Markov chains and recurrent neural networks (RNNs) for text generation. It discusses:
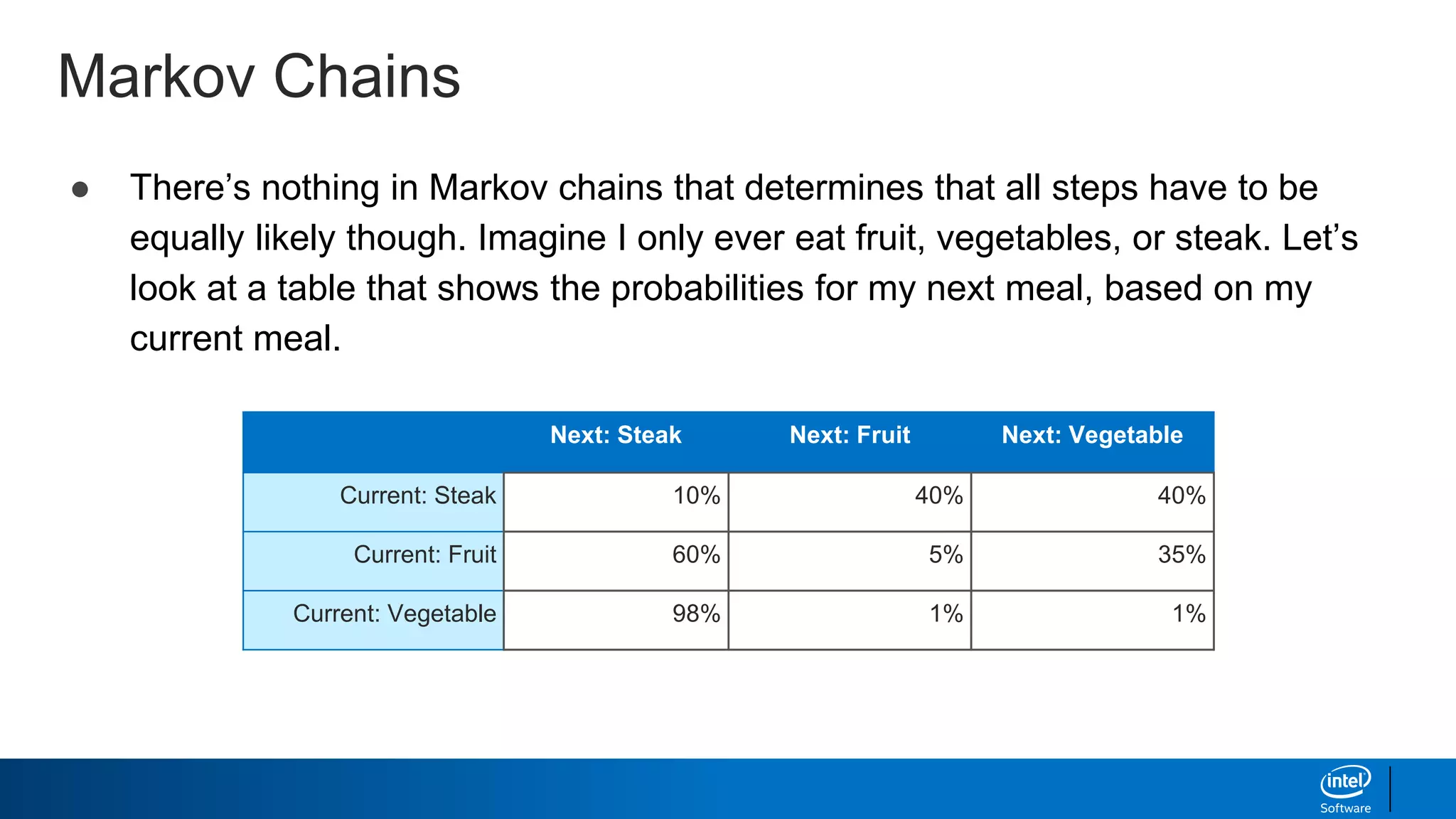
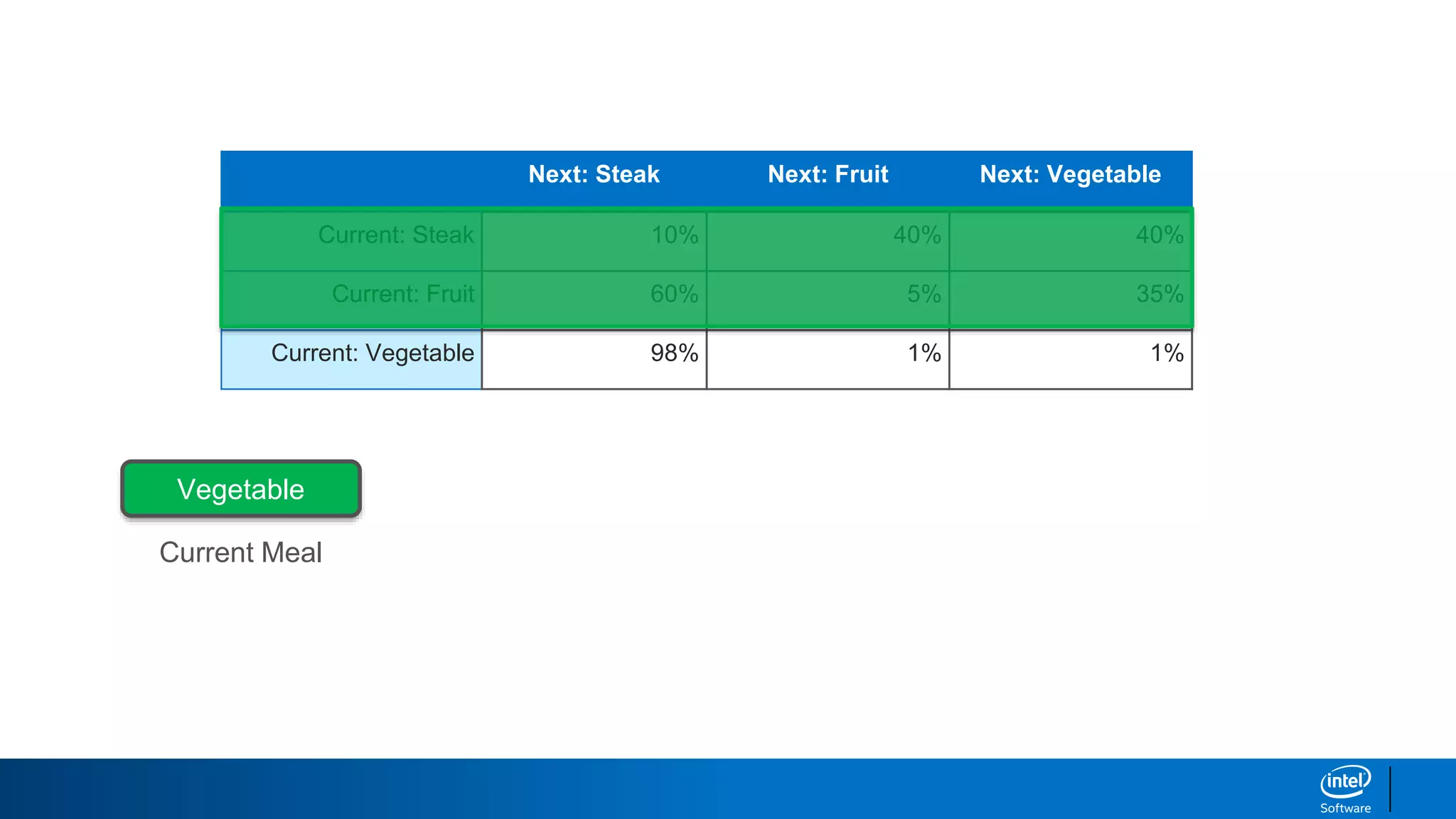
- How Markov chains can model text by treating sequences of words as "states" and predicting the next word based on conditional probabilities.
- The limitations of Markov chains for complex text generation.
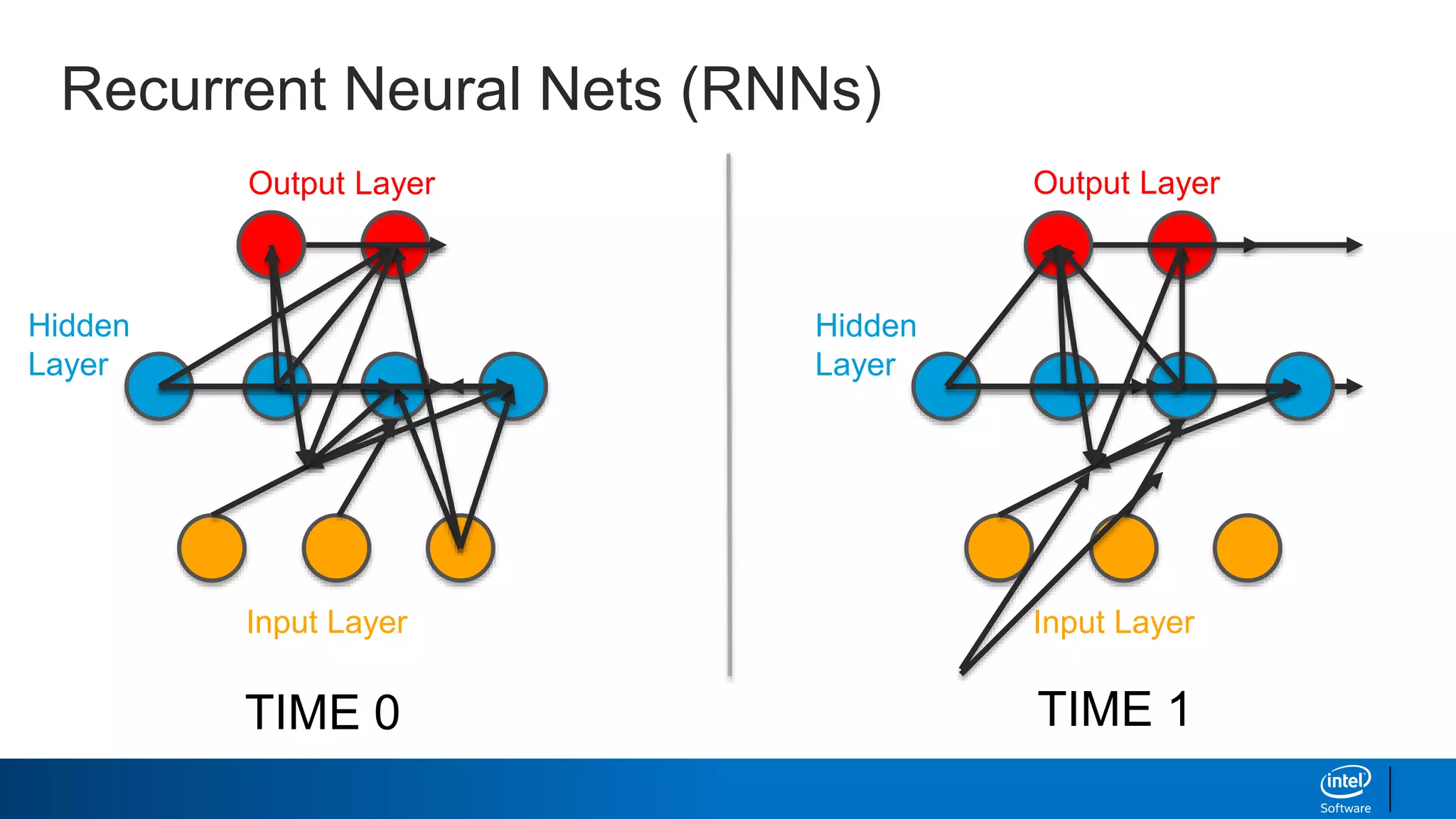
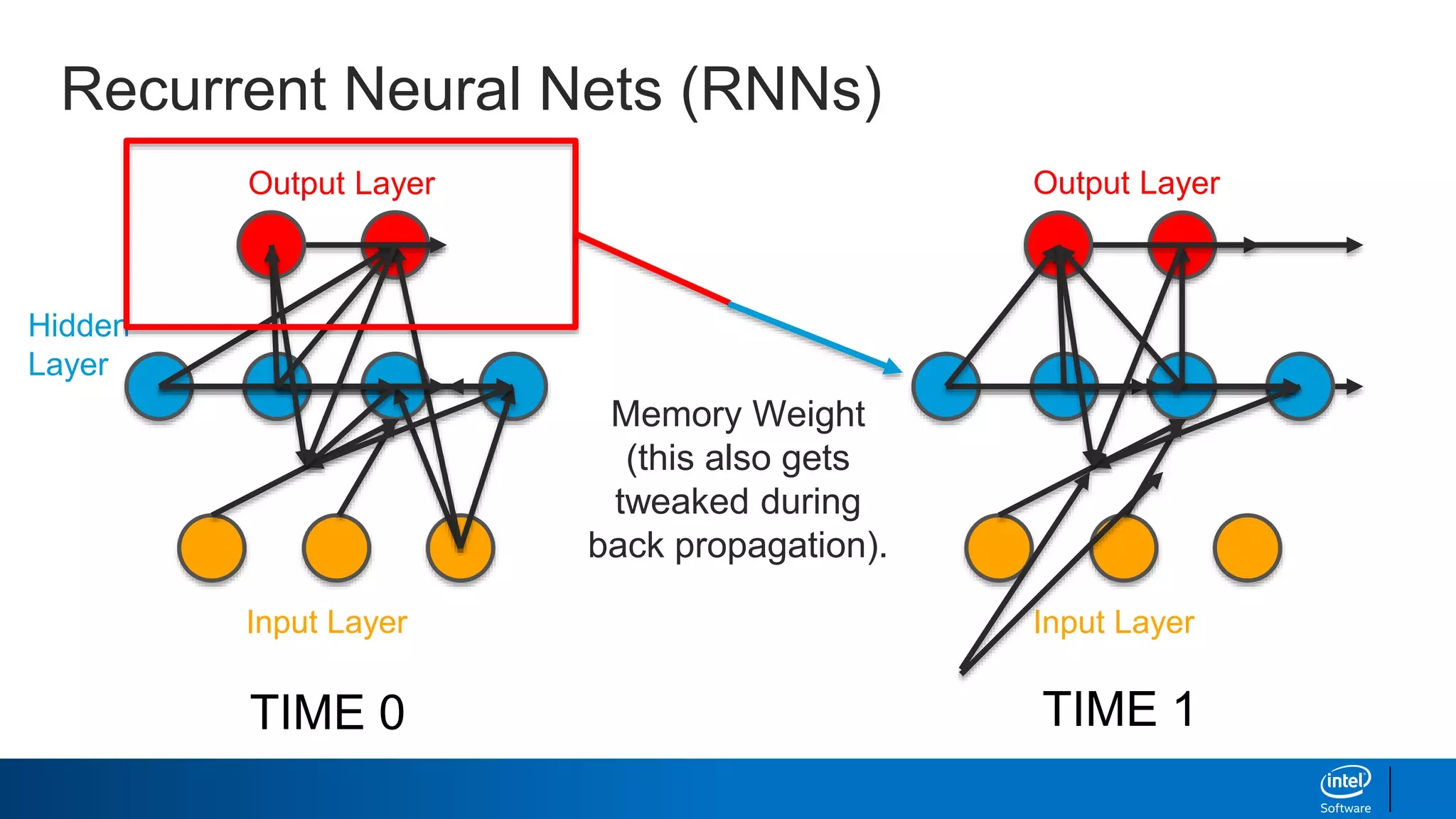
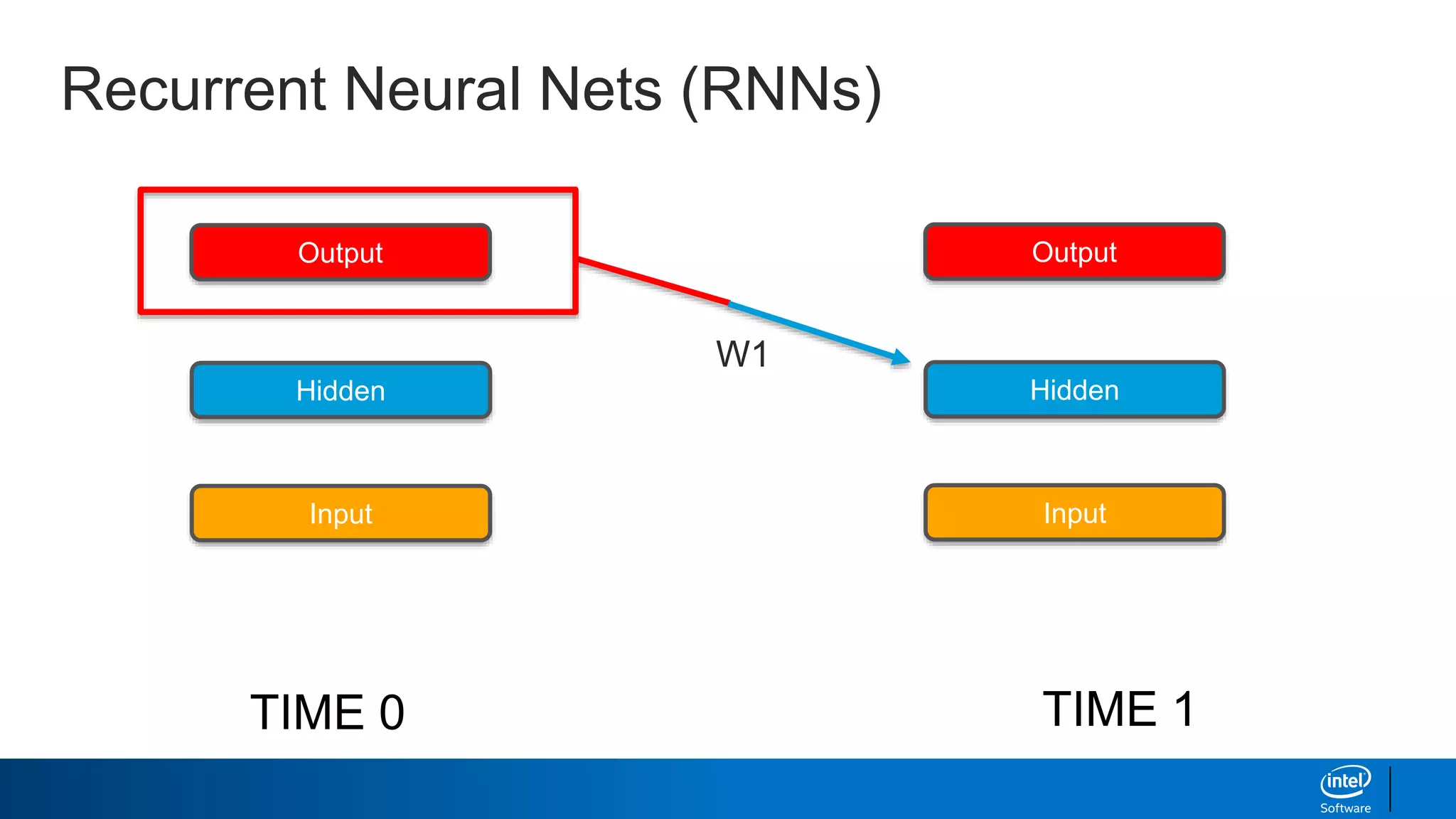
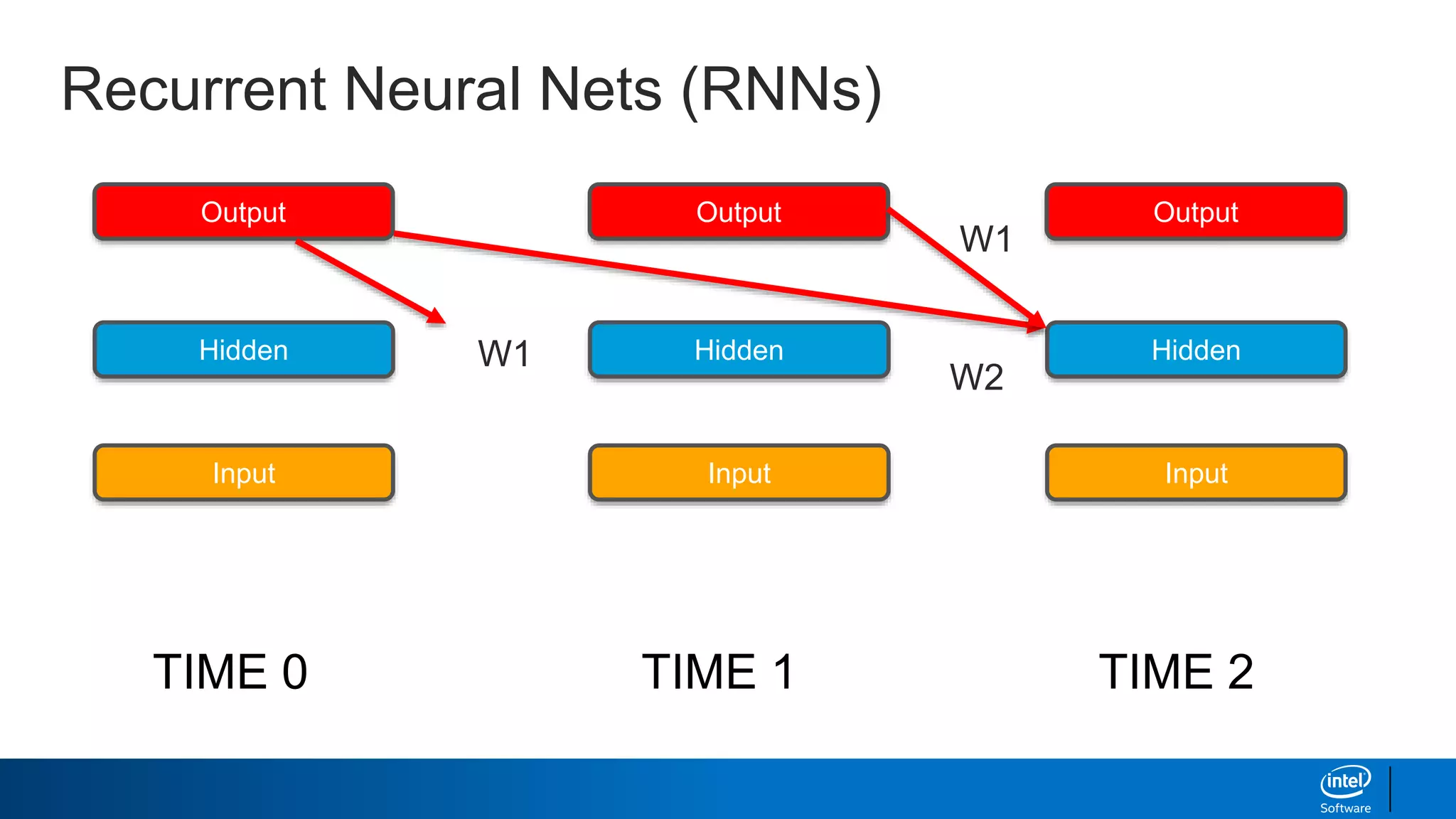
- How RNNs address some limitations by incorporating memory via feedback connections, allowing them to better capture sequential relationships.
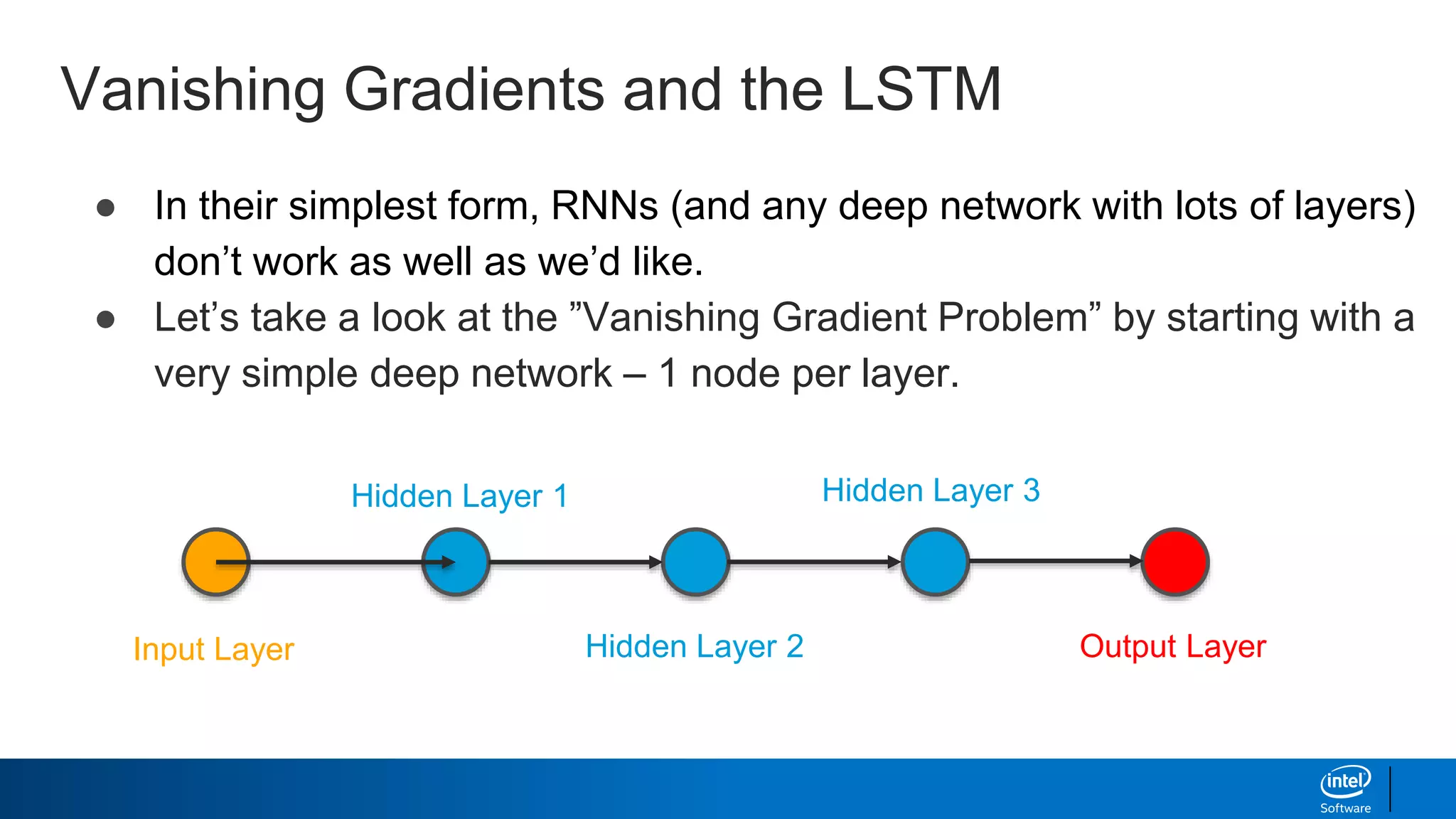
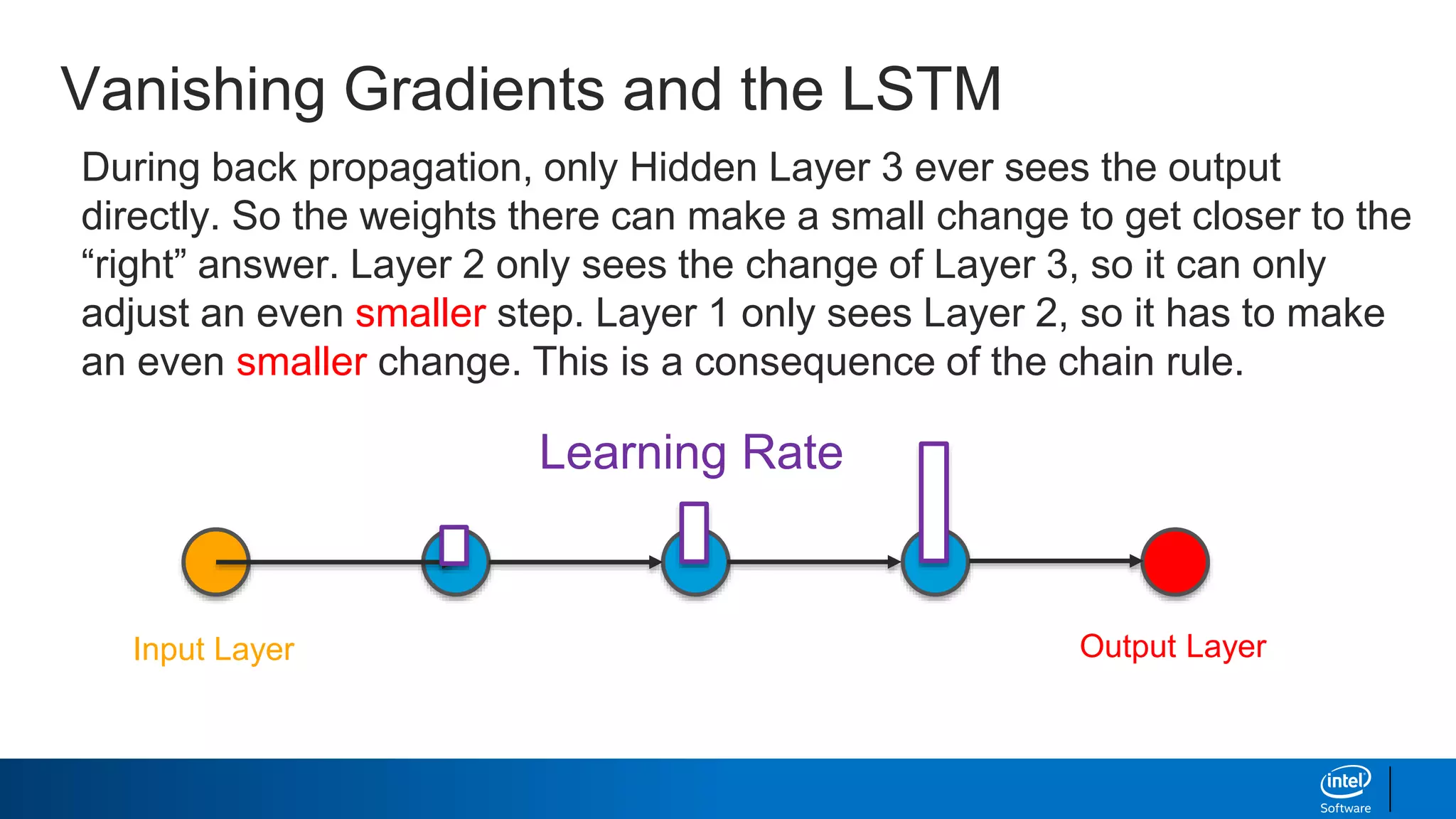
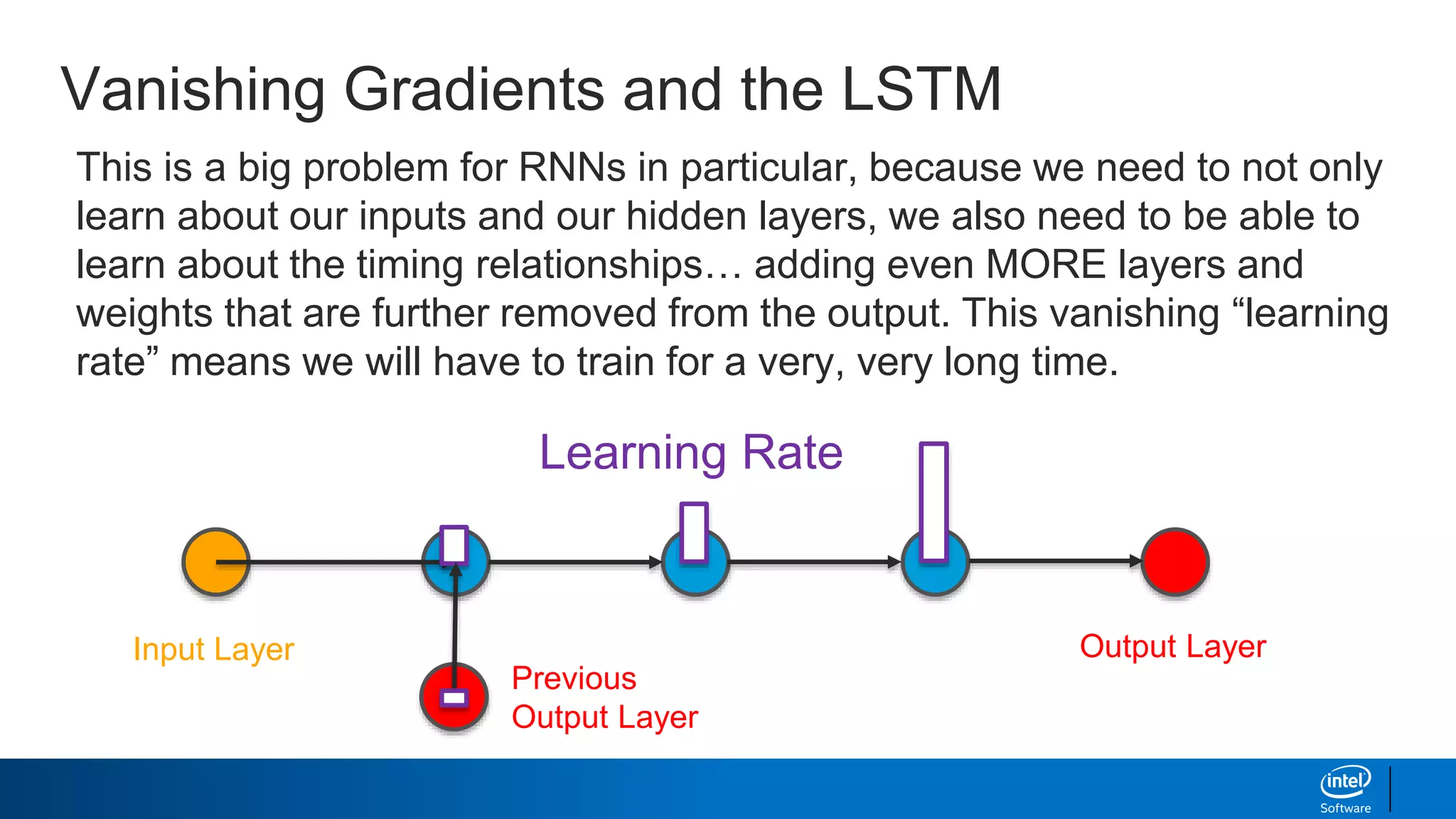
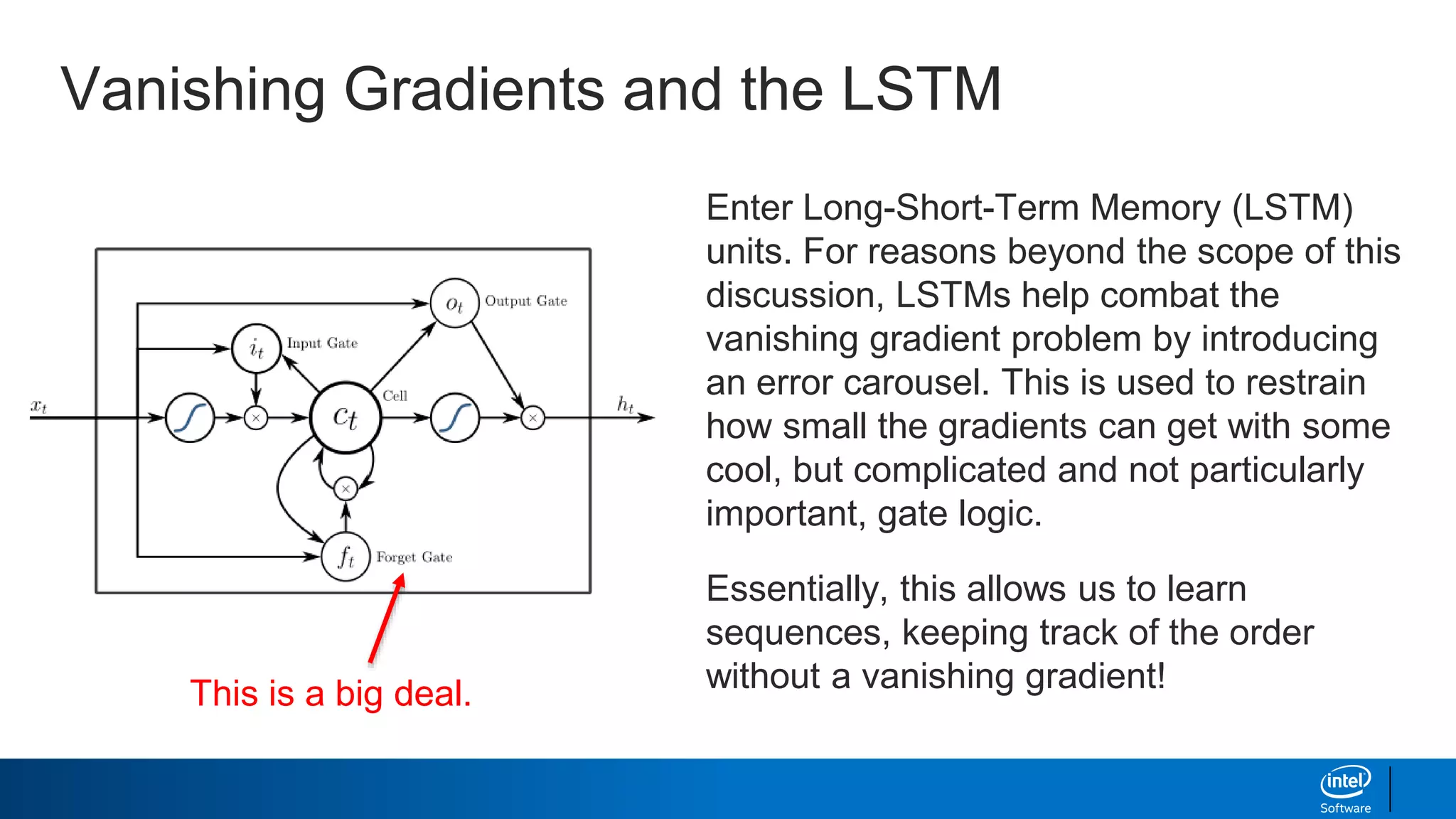
- Long short-term memory (LSTM) networks, which help combat the "vanishing gradient problem" to better learn long-term dependencies in sequences.
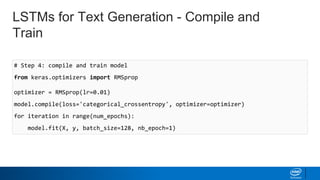
- How LSTMs can be implemented in Python using Keras to generate text character-by-character based on













![“Both the brown fox and the brown dog slept.”
{ (Both, the): [brown] }](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/85/Text-generation-and_advanced_topics-19-320.jpg)
![“Both the brown fox and the brown dog slept.”
{ (Both, the): [brown],
(the, brown): [fox], }](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/85/Text-generation-and_advanced_topics-20-320.jpg)
![“Both the brown fox and the brown dog slept.”
{ (Both, the): [brown],
(the, brown): [fox],
(brown,fox): [and], }](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/85/Text-generation-and_advanced_topics-21-320.jpg)
![“Both the brown fox and the brown dog slept.”
{ (Both, the): [brown],
(the, brown): [fox],
(brown,fox): [and],
(fox, and): [the], }](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/85/Text-generation-and_advanced_topics-22-320.jpg)
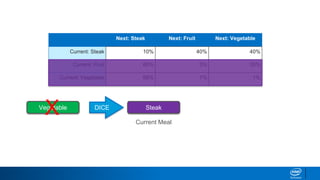
![“Both the brown fox and the brown dog slept.”
{ (Both, the): [brown],
(the, brown): [fox],
(brown,fox): [and],
(fox, and): [the],
(and, the): [brown],}](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/85/Text-generation-and_advanced_topics-23-320.jpg)
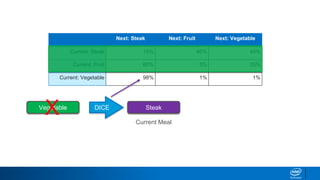
![“Both the brown fox and the brown dog slept.”
{ (Both, the): [brown],
(the, brown): [fox, dog],
(brown,fox): [and],
(fox, and): [the],
(and, the): [brown],}
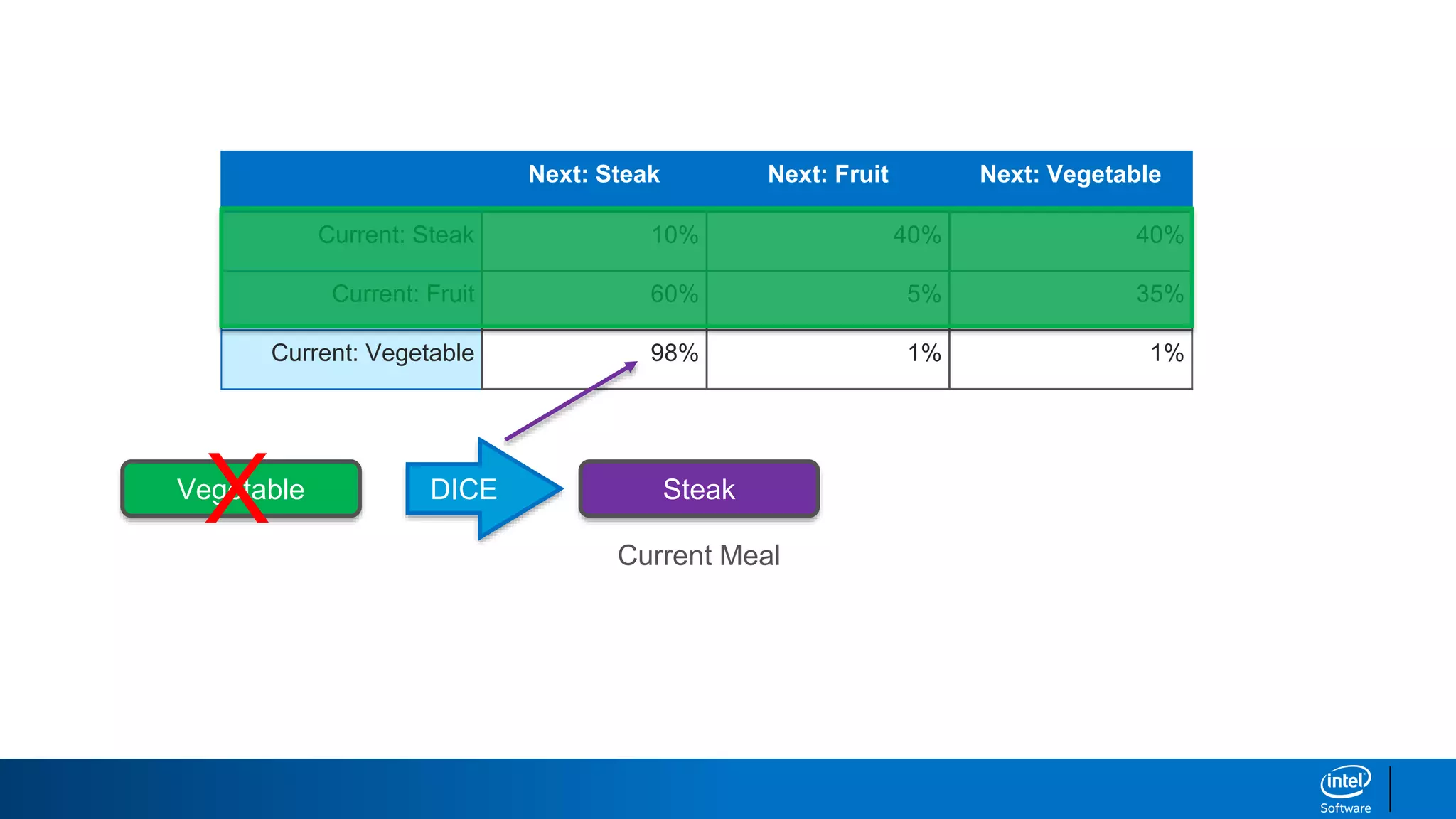
Now if we are in a current state of
“the brown”, both ”fox” and “dog” are
equally likely to occur!
So we have a state dependent chain
of probabilities.
We can use Markov Chains here!](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/85/Text-generation-and_advanced_topics-24-320.jpg)
![{ (Both, the): [brown],
(the, brown): [fox, dog],
(brown,fox): [and],
(fox, and): [the],
(and, the): [brown],
(brown, dog): [slept] }
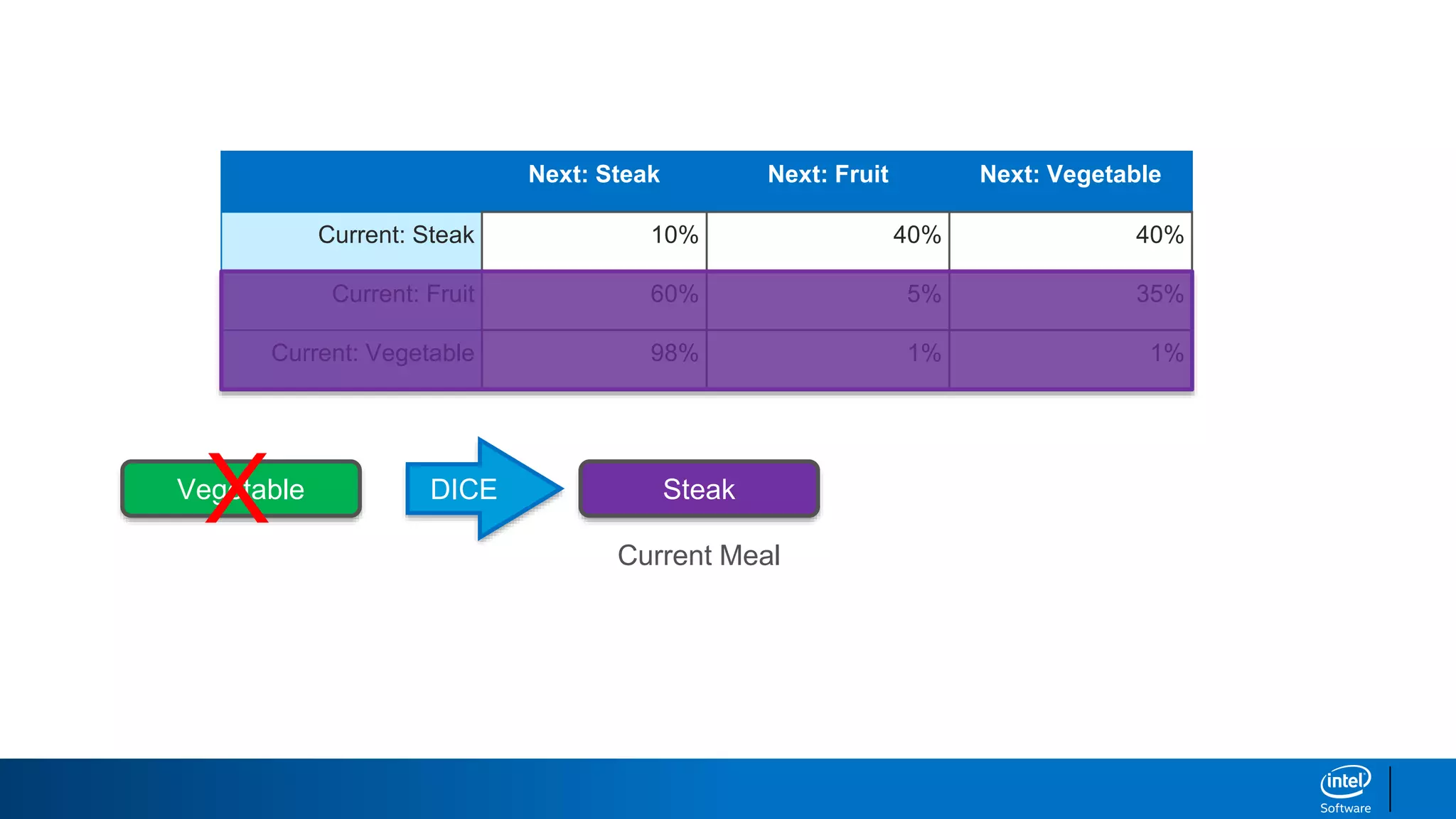
Let’s start with a sentence seed of “and the”
and this dictionary of word relationships and roll
some dice.
”and the “
Text Generation with Markov Chains](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/85/Text-generation-and_advanced_topics-25-320.jpg)
![{ (Both, the): [brown],
(the, brown): [fox, dog],
(brown,fox): [and],
(fox, and): [the],
(and, the): [brown],
(brown, dog): [slept] }
Let’s start with a sentence seed of “and the”
and this dictionary of word relationships and roll
some dice.
”and the brown “
100%
brown
Text Generation with Markov Chains](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/85/Text-generation-and_advanced_topics-26-320.jpg)
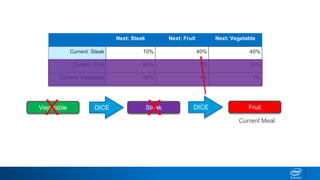
![{ (Both, the): [brown],
(the, brown): [fox, dog],
(brown,fox): [and],
(fox, and): [the],
(and, the): [brown],
(brown, dog): [slept] }
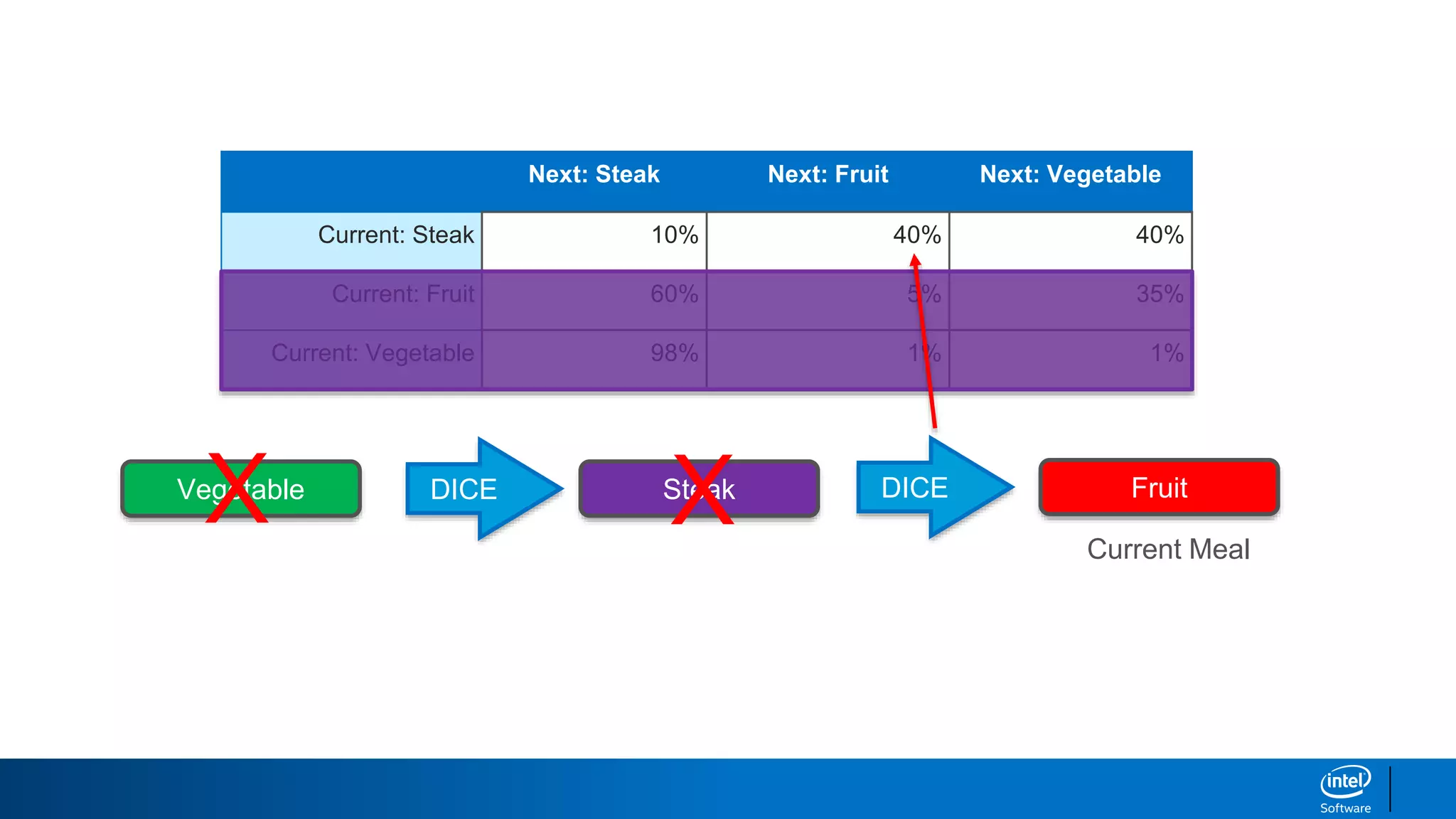
Let’s start with a sentence seed of “and the”
and this dictionary of word relationships and roll
some dice.
”and the brown fox “
50% dog, 50% fox.
ROLL DICE.
Text Generation with Markov Chains](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/85/Text-generation-and_advanced_topics-27-320.jpg)
![{ (Both, the): [brown],
(the, brown): [fox, dog],
(brown,fox): [and],
(fox, and): [the],
(and, the): [brown],
(brown, dog): [slept] }
Text Generation with Markov Chains
Let’s start with a sentence seed of “and the”
and this dictionary of word relationships and roll
some dice.
”and the brown fox and the brown dog slept“
Because of our limited selection of words,
we are now stuck completing the sentence.](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/85/Text-generation-and_advanced_topics-28-320.jpg)



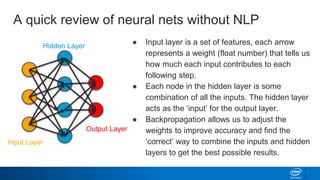

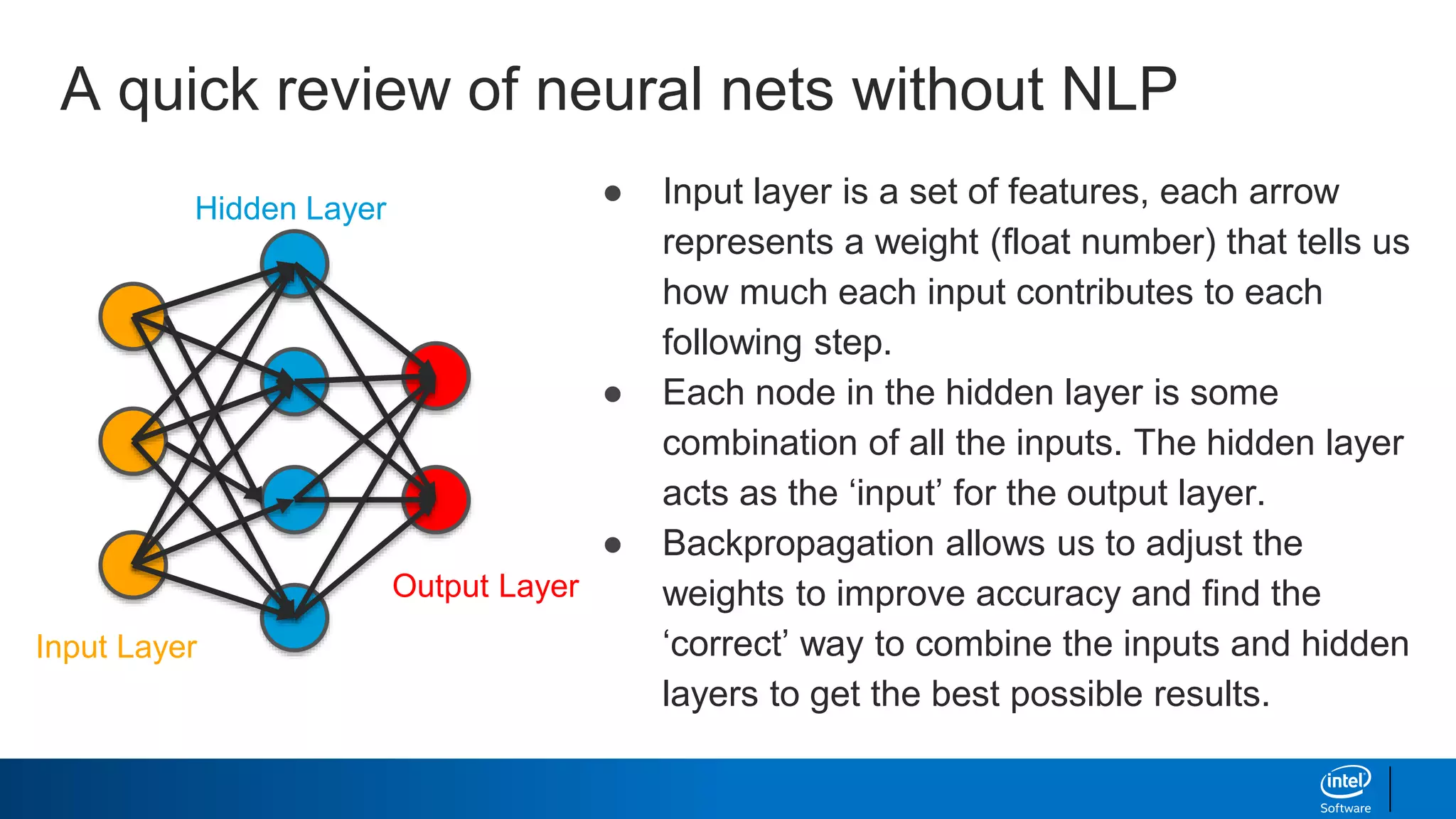
![Hidden Layer
The – [1,0,0,0]
cat – [0,1,0,0]
ran – [0,0,1,0]
Is a legal document?
Veterinary Blog?
Neural Nets with NLP (Traditional)](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/85/Text-generation-and_advanced_topics-34-320.jpg)
![The – [1,0,0,0]
cat – [0,1,0,0]
ran – [0,0,1,0]
Is a legal document?
Veterinary Blog?
Neural Nets with NLP (Traditional)
This doesn’t really have any
concept of “order” built in. It’s just
a bag of words approach. If we
want to switch to text generation,
we’re going to need to get
fancier. Right now, the network
just knows that “the”, “cat”, and
“ran” are all present.](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/85/Text-generation-and_advanced_topics-35-320.jpg)
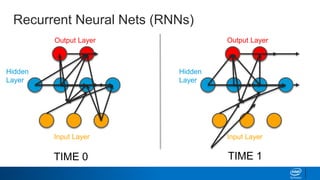
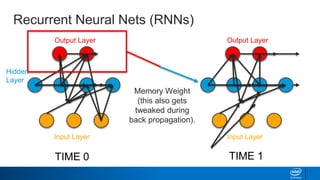
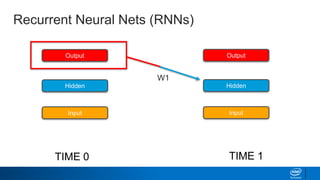
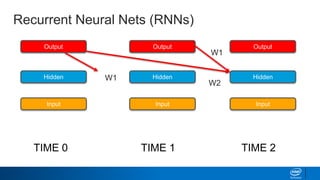

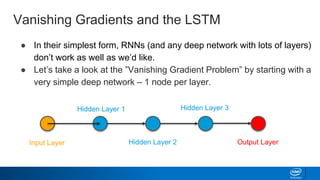
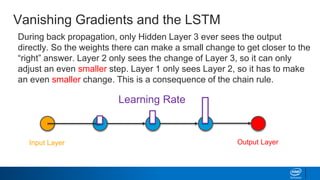
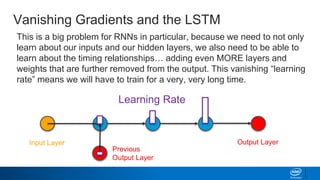
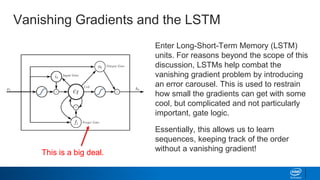

![Keras – Simplifying LSTMs in Python
Why does Keras expect a 2D matrix as input for the LSTM?
It needs a list of lists, ordered by time!
If we were trying to teach it the alphabet, we’d need to send in:
[[’A’], [’B’], [’C’]] as input to get [‘D’] back out. Keras knows that in
this format ‘A’ comes before ’B’. Or more realistically, we’d need to send in
one-hot encoded versions like so:
[[1,0,0,0], [0,1,0,0], [0,0,1,0]] [0,0,0,1]](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/85/Text-generation-and_advanced_topics-46-320.jpg)
![LSTMs for Text Generation
● Using this setup, we can chop our corpus up into character level
sequences. “Hello” could be come [[‘H’],[‘e’],[’l’],[‘l’]] with a
corresponding label of [‘o’]. If we do that for the whole corpus, the
LSTM can learn how to spell and when spaces and line breaks tend to
happen.
● How well could this possible work?](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/85/Text-generation-and_advanced_topics-47-320.jpg)


![LSTMs for Text Generation - Data Prep
Output:
Input:
# Step 1: generate input data
# Inputs: one hot encoded characters: X
print(X[0]) # Sequence of three one hot encoded vectors, of length 59
[[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/85/Text-generation-and_advanced_topics-50-320.jpg)
![LSTMs for Text Generation - Data Prep
Output:
Input:
# Step 2: generate output data
# Inputs: one hot encoded characters: y
print(y[0:3]) # First three “output” vectors we are trying to predict
[[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/85/Text-generation-and_advanced_topics-51-320.jpg)























![“Both the brown fox and the brown dog slept.”
{ (Both, the): [brown] }](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/75/Text-generation-and_advanced_topics-19-2048.jpg)
![“Both the brown fox and the brown dog slept.”
{ (Both, the): [brown],
(the, brown): [fox], }](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/75/Text-generation-and_advanced_topics-20-2048.jpg)
![“Both the brown fox and the brown dog slept.”
{ (Both, the): [brown],
(the, brown): [fox],
(brown,fox): [and], }](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/75/Text-generation-and_advanced_topics-21-2048.jpg)
![“Both the brown fox and the brown dog slept.”
{ (Both, the): [brown],
(the, brown): [fox],
(brown,fox): [and],
(fox, and): [the], }](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/75/Text-generation-and_advanced_topics-22-2048.jpg)
![“Both the brown fox and the brown dog slept.”
{ (Both, the): [brown],
(the, brown): [fox],
(brown,fox): [and],
(fox, and): [the],
(and, the): [brown],}](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/75/Text-generation-and_advanced_topics-23-2048.jpg)
![“Both the brown fox and the brown dog slept.”
{ (Both, the): [brown],
(the, brown): [fox, dog],
(brown,fox): [and],
(fox, and): [the],
(and, the): [brown],}
Now if we are in a current state of
“the brown”, both ”fox” and “dog” are
equally likely to occur!
So we have a state dependent chain
of probabilities.
We can use Markov Chains here!](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/75/Text-generation-and_advanced_topics-24-2048.jpg)
![{ (Both, the): [brown],
(the, brown): [fox, dog],
(brown,fox): [and],
(fox, and): [the],
(and, the): [brown],
(brown, dog): [slept] }
Let’s start with a sentence seed of “and the”
and this dictionary of word relationships and roll
some dice.
”and the “
Text Generation with Markov Chains](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/75/Text-generation-and_advanced_topics-25-2048.jpg)
![{ (Both, the): [brown],
(the, brown): [fox, dog],
(brown,fox): [and],
(fox, and): [the],
(and, the): [brown],
(brown, dog): [slept] }
Let’s start with a sentence seed of “and the”
and this dictionary of word relationships and roll
some dice.
”and the brown “
100%
brown
Text Generation with Markov Chains](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/75/Text-generation-and_advanced_topics-26-2048.jpg)
![{ (Both, the): [brown],
(the, brown): [fox, dog],
(brown,fox): [and],
(fox, and): [the],
(and, the): [brown],
(brown, dog): [slept] }
Let’s start with a sentence seed of “and the”
and this dictionary of word relationships and roll
some dice.
”and the brown fox “
50% dog, 50% fox.
ROLL DICE.
Text Generation with Markov Chains](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/75/Text-generation-and_advanced_topics-27-2048.jpg)
![{ (Both, the): [brown],
(the, brown): [fox, dog],
(brown,fox): [and],
(fox, and): [the],
(and, the): [brown],
(brown, dog): [slept] }
Text Generation with Markov Chains
Let’s start with a sentence seed of “and the”
and this dictionary of word relationships and roll
some dice.
”and the brown fox and the brown dog slept“
Because of our limited selection of words,
we are now stuck completing the sentence.](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/75/Text-generation-and_advanced_topics-28-2048.jpg)




![Hidden Layer
The – [1,0,0,0]
cat – [0,1,0,0]
ran – [0,0,1,0]
Is a legal document?
Veterinary Blog?
Neural Nets with NLP (Traditional)](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/75/Text-generation-and_advanced_topics-34-2048.jpg)
![The – [1,0,0,0]
cat – [0,1,0,0]
ran – [0,0,1,0]
Is a legal document?
Veterinary Blog?
Neural Nets with NLP (Traditional)
This doesn’t really have any
concept of “order” built in. It’s just
a bag of words approach. If we
want to switch to text generation,
we’re going to need to get
fancier. Right now, the network
just knows that “the”, “cat”, and
“ran” are all present.](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/75/Text-generation-and_advanced_topics-35-2048.jpg)


![Keras – Simplifying LSTMs in Python
Why does Keras expect a 2D matrix as input for the LSTM?
It needs a list of lists, ordered by time!
If we were trying to teach it the alphabet, we’d need to send in:
[[’A’], [’B’], [’C’]] as input to get [‘D’] back out. Keras knows that in
this format ‘A’ comes before ’B’. Or more realistically, we’d need to send in
one-hot encoded versions like so:
[[1,0,0,0], [0,1,0,0], [0,0,1,0]] [0,0,0,1]](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/75/Text-generation-and_advanced_topics-46-2048.jpg)
![LSTMs for Text Generation
● Using this setup, we can chop our corpus up into character level
sequences. “Hello” could be come [[‘H’],[‘e’],[’l’],[‘l’]] with a
corresponding label of [‘o’]. If we do that for the whole corpus, the
LSTM can learn how to spell and when spaces and line breaks tend to
happen.
● How well could this possible work?](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/75/Text-generation-and_advanced_topics-47-2048.jpg)


![LSTMs for Text Generation - Data Prep
Output:
Input:
# Step 1: generate input data
# Inputs: one hot encoded characters: X
print(X[0]) # Sequence of three one hot encoded vectors, of length 59
[[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/75/Text-generation-and_advanced_topics-50-2048.jpg)
![LSTMs for Text Generation - Data Prep
Output:
Input:
# Step 2: generate output data
# Inputs: one hot encoded characters: y
print(y[0:3]) # First three “output” vectors we are trying to predict
[[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]](https://image.slidesharecdn.com/textgenerationandadvancedtopics-190218095547/75/Text-generation-and_advanced_topics-51-2048.jpg)