This document discusses natural language processing (NLP) toolkits and preprocessing techniques. It introduces popular Python NLP libraries like NLTK, TextBlob, spaCy and gensim. It also covers various text preprocessing methods including tokenization, removing punctuation/characters, stemming, lemmatization, part-of-speech tagging, named entity recognition and more. Code examples demonstrate how to implement these techniques in Python to clean and normalize text data for analysis.
NLP Toolkits andPreprocessing Techniques
• NLP Toolkits
▪ Python libraries for natural language processing
• Text Preprocessing Techniques
▪ Converting text to a meaningful format for analysis
▪ Preprocessing and cleaning text
3.
NLP Toolkits
• NLTK(Natural Language Toolkit)
▪ The most popular NLP library
• TextBlob
▪ Wraps around NLTK and makes it easier to use
• spaCy
▪ Built on Cython, so it’s fast and powerful
• gensim
▪ Great for topic modeling and document similarity
4.
Code: How toInstall NLTK
Command Line
pip install nltk
Jupyter Notebook
import nltk
nltk.download()
# downloads all data & models
# this will take a while
5.
Sample Text Data
HiMr. Smith! I’m going to buy some vegetables (tomatoes and cucumbers) from
the store. Should I pick up some black-eyed peas as well?
Text data is messy.
To analyze this data, we need to preprocess and normalize the text.
6.
Preprocessing Techniques
1. Turntext into a meaningful format for analysis
• Tokenization
2. Clean the data
• Remove: capital letters, punctuation, numbers, stop words
• Stemming
• Parts of speech tagging
• Correct misspellings
• Chunking (named entity recognition, compound term extraction)
7.
Tokenization
Tokenization = splittingraw text into small, indivisible units for
processing
These units can be:
• Words
• Sentences
• N-grams
• Other characters defined by regular expressions
8.
Code: Tokenization (Words)
fromnltk.tokenize import word_tokenize
my_text = "Hi Mr. Smith! I’m going to buy some vegetables (tomatoes and cucumbers)
from the store. Should I pick up some black-eyed peas as well?"
print(word_tokenize(my_text)) # print function requires Python 3
['Hi', 'Mr.', 'Smith', '!', 'I', '’', 'm', ‘going', ‘to', 'buy', 'some',
'vegetables', '(', 'tomatoes', 'and', 'cucumbers', ')', 'from', 'the',
'store', '.', 'Should', 'I', 'pick', 'up', ‘some', 'black-eyed', 'peas', 'as',
'well', '?']
Output:
Input:
Requires python 3
9.
Tokenization: Sentences
Hi Mr.Smith! I’m going to buy some vegetables (tomatoes and cucumbers) from
the store. Should I pick up some black-eyed peas as well?
Tokens can be sentences. How would you split this into sentences? What rules
would you put in place?
It’s a difficult task. This is where tokenizers in Python can help.
10.
Code: Tokenization (Sentences)
fromnltk.tokenize import sent_tokenize
my_text = "Hi Mr. Smith! I’m going to buy some vegetables (tomatoes and cucumbers)
from the store. Should I pick up some black-eyed peas as well?"
print(sent_tokenize(my_text))
['Hi Mr. Smith!',
'I’m going to buy some vegetables (tomatoes and cucumbers) from the store.',
'Should I pick up some black-eyed peas as well?']
Output:
Input:
Requires python 3
11.
Code: Tokenization (N-Grams)
fromnltk.util import ngrams
my_words = word_tokenize(my_text) # This is the list of all words
twograms = list(ngrams(my_words,2)) # This is for two-word combos, but can pick any n
print(twograms)
[('Hi', 'Mr.'), ('Mr.', 'Smith'), ('Smith', '!'), ('!', 'I'), ('I', '’'), ('’',
'm'), ('m', 'going'), ('going', 'to'), ('to', ‘buy'), ('buy', 'some'), ('some',
'vegetables'), ('vegetables', '('), ('(', 'tomatoes'), ('tomatoes', 'and'), ('and',
'cucumbers'), ('cucumbers', ')'), (')', 'from'), ('from', 'the'), ('the', 'store'),
('store', '.'), ('.', 'Should'), ('Should', 'I'), ('I', 'pick'), ('pick', 'up'),
('up', '1/2'), ('1/2', 'lb'), ('lb', 'of'), ('of', 'black-eyed'), ('black-eyed',
'peas'), ('peas', 'as'), ('as', 'well'), ('well', '?')]
Output:
Input:
Requires python 3
12.
Tokenization: Regular Expressions
Let’ssay you want to tokenize by some other type of grouping or pattern.
Regular expressions (regex) allows you to do so.
Some examples of regular expressions:
• Find white spaces: s+
• Find words starting with capital letters: [A-Z]['w]+
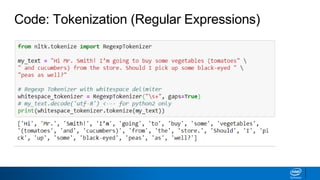
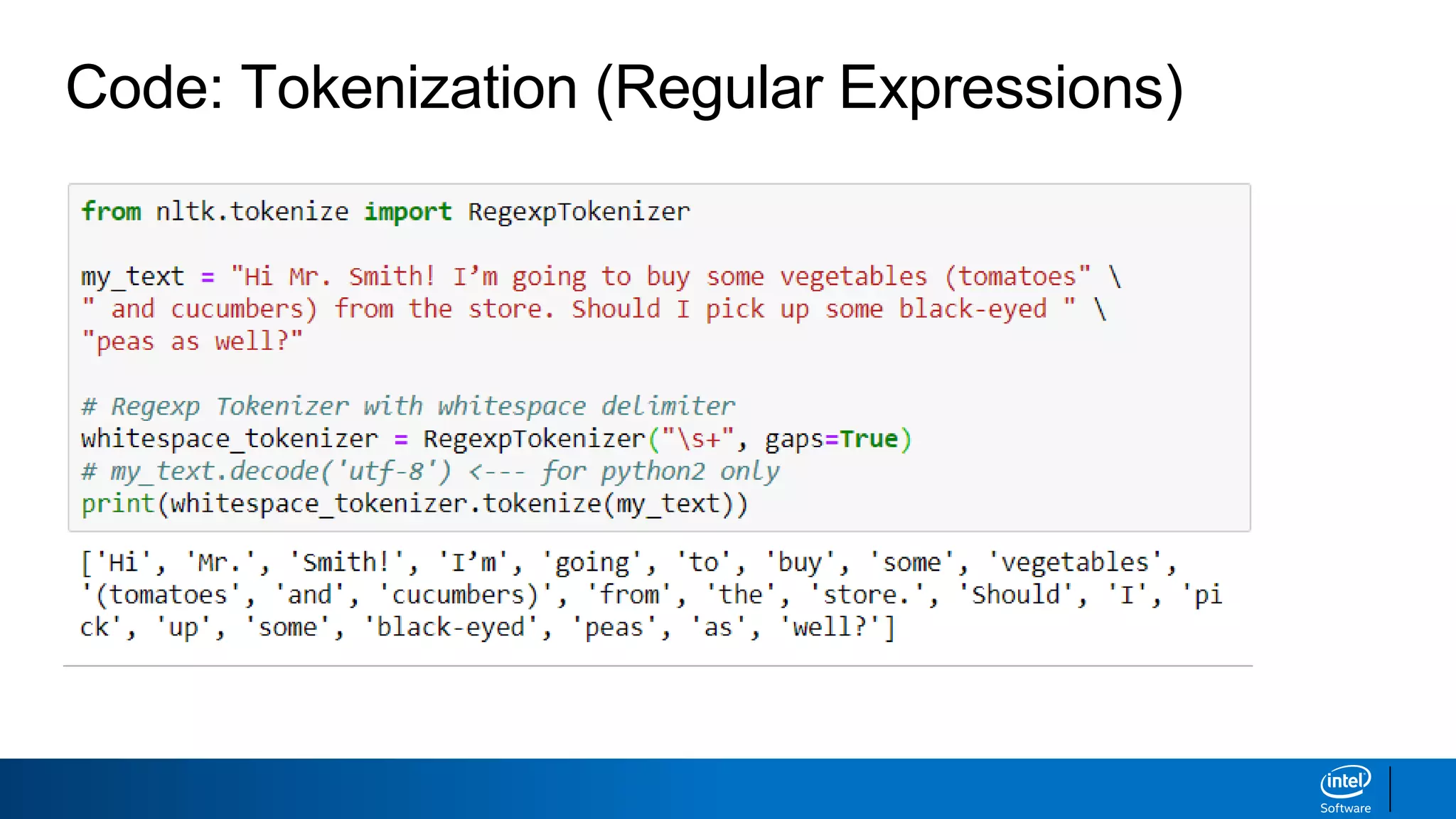
Code: Tokenization (RegularExpressions)
from nltk.tokenize import RegexpTokenizer
# RegexpTokenizer to match only capitalized words
cap_tokenizer = RegexpTokenizer("[A-Z]['w]+")
print(cap_tokenizer.tokenize(my_text))
['Hi', 'Mr', 'Smith', 'Should']
Output:
Input:
15.
Tokenization Summary
Hi Mr.Smith! I’m going to buy some vegetables (tomatoes and cucumbers) from
the store. Should I pick up some black-eyed peas as well?
With tokenization, we were able to break this messy text data down into small
units for us to do analysis
• By sentence, word, n-grams
• By characters and patterns using regular expressions
16.
Preprocessing Checkpoint
What havewe done so far?
• Tokenized text by sentence, word, n-grams and using regex
This is only one step. There is a lot more preprocessing that we can do.
17.
Preprocessing Techniques
1. Turntext into a meaningful format for analysis
• Tokenization
2. Clean the data
• Remove: capital letters, punctuation, numbers, stop words
• Stemming
• Correct misspellings
• Parts of speech tagging
• Chunking (named entity recognition, compound term extraction)
18.
Preprocessing: Remove Characters
HiMr. Smith! I’m going to buy some vegetables (tomatoes and cucumbers) from
the store. Should I pick up 2lbs of black-eyed peas as well?
How can we normalize this text?
• Remove punctuation
• Remove capital letters and make all letters lowercase
• Remove numbers
19.
Code: Remove Punctuation
importre # Regular expression library
import string
# Replace punctuations with a white space
clean_text = re.sub('[%s]' % re.escape(string.punctuation), ' ', my_text)
clean_text
Input:
Output:
'Hi Mr Smith I m going to buy some vegetables tomatoes and cucumbers from
the store Should I pick up 2lbs of black eyed peas as well '
'Hi Mr Smith Im going to buy some vegetables tomatoes and cucumbers from the
store Should I pick up 2lbs of blackeyed peas as well'
Replace with '' instead of ' '
20.
Code: Make AllText Lowercase
clean_text = clean_text.lower()
clean_text
Input:
Output:
'hi mr smith i m going to buy some vegetables tomatoes and cucumbers from
the store should i pick up 2lbs of black eyed peas as well '
21.
Code: Remove Numbers
#Removes all words containing digits
clean_text = re.sub('w*dw*', ' ', clean_text)
clean_text
Input:
Output:
'hi mr smith i m going to buy some vegetables tomatoes and cucumbers from
the store should i pick up of black eyed peas as well '
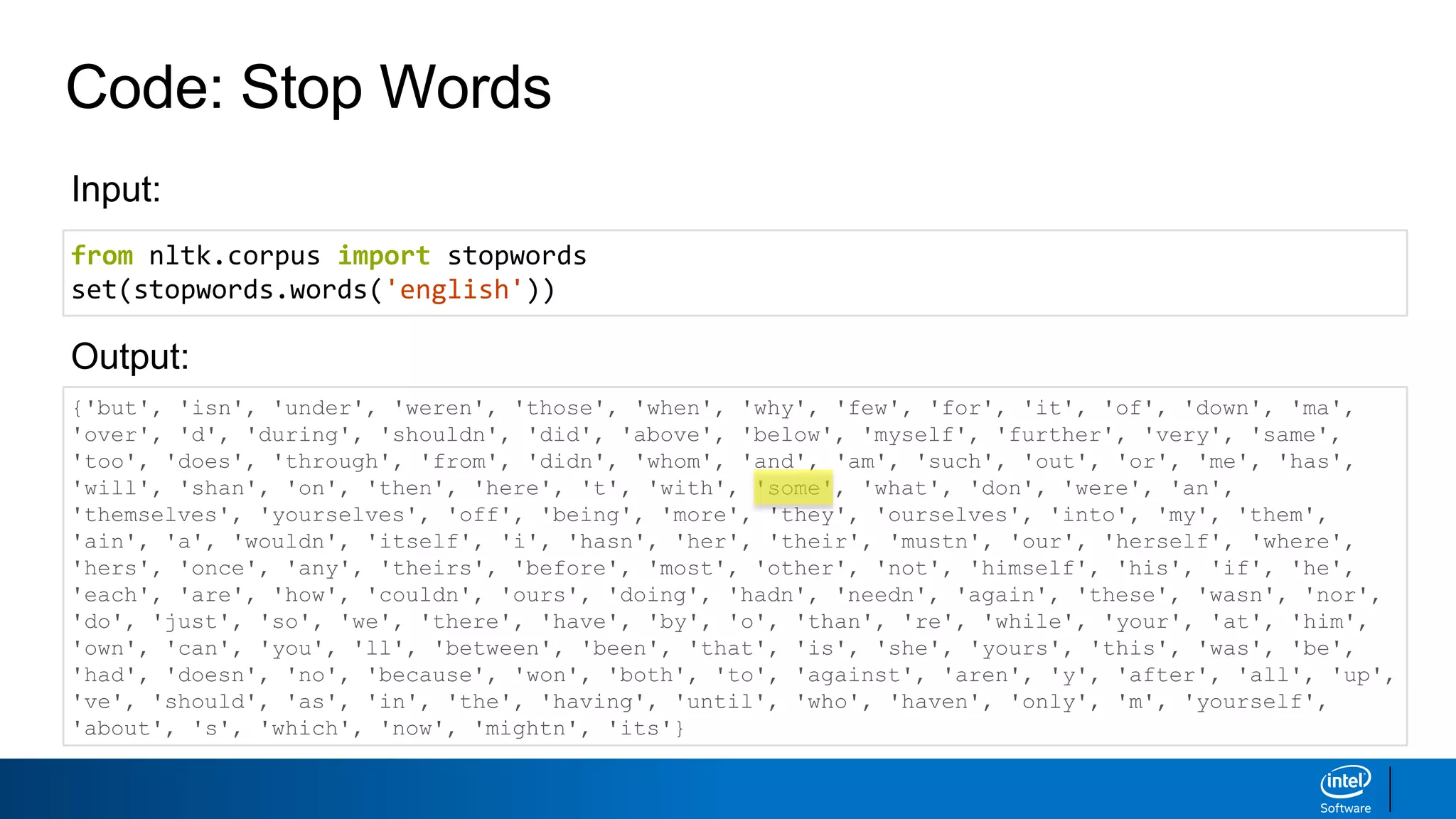
Preprocessing: Stop Words
HiMr. Smith! I’m going to buy some vegetables (tomatoes and cucumbers) from
the store. Should I pick up some black-eyed peas as well?
What is the most frequent term in the text above? Is that information meaningful?
Stop words are words that have very little semantic value.
There are language and context-specific stop word lists online that you can use.
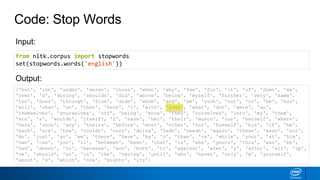
Code: Remove StopWords
my_text = ["Hi Mr. Smith! I’m going to buy some vegetables (tomatoes and cucumbers)
from the store. Should I pick up some black-eyed peas as well?"]
# Incorporate stop words when creating the count vectorizer
cv = CountVectorizer(stop_words='english')
X = cv.fit_transform(my_text)
pd.DataFrame(X.toarray(), columns=cv.get_feature_names())
Input:
Output:
Including stop words
28.
Preprocessing: Stemming
Stemming &Lemmatization = Cut word down to base form
• Stemming: Uses rough heuristics to reduce words to base
• Lemmatization: Uses vocabulary and morphological analysis
• Makes the meaning of run, runs, running, ran all the same
• Cuts down on complexity by reducing the number of unique words
Multiple stemmers available in NLTK
• PorterStemmer, LancasterStemmer, SnowballStemmer
• WordNetLemmatizer
Preprocessing: Parts ofSpeech Tagging
Parts of Speech
• Nouns, verbs, adjectives, etc.
• Parts of speech tagging labels each word as a part of speech
31.
Code: Parts ofSpeech Tagging
from nltk.tag import pos_tag
my_text = "James Smith lives in the United States."
tokens = pos_tag(word_tokenize(my_text))
print(tokens)
Input:
Output:
32.
Code: Parts ofSpeech Tagging
nltk.help.upenn_tagset()
Input:
Output:
DT: determiner all an another any both del each either every half la many much nary neither no some such that
the them these this those
IN: preposition or conjunction, subordinating astride among uppon whether out inside pro despite on by
throughout below within for towards near behind atop around if like until below next into if beside ...
NNP: noun, proper, singular Motown Venneboerger Czestochwa Ranzer Conchita Trumplane Christos Oceanside
Escobar Kreisler Sawyer Cougar Yvette Ervin ODI Darryl CTCA Shannon A.K.C. Meltex Liverpool ...
NNPS: noun, proper, plural Americans Americas Amharas Amityvilles Amusements Anarcho-Syndicalists Andalusians
Andes Andruses Angels Animals Anthony Antilles Antiques Apache Apaches Apocrypha ...
VBZ: verb, present tense, 3rd person singular bases reconstructs marks mixes displeases seals carps weaves
snatches slumps stretches authorizes smolders pictures emerges stockpiles seduces fizzes uses bolsters slaps
speaks pleads ...
33.
Preprocessing: Named EntityRecognition
Named Entity Recognition (NER) aka Entity Extraction
• Identifies and tags named entities in text (people, places, organizations,
phone numbers, emails, etc.)
• Can be tremendously valuable for further NLP tasks
• For example: “United States” --> “United_States”
34.
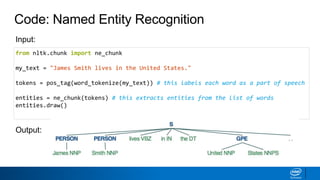
Code: Named EntityRecognition
from nltk.chunk import ne_chunk
my_text = "James Smith lives in the United States."
tokens = pos_tag(word_tokenize(my_text)) # this labels each word as a part of speech
entities = ne_chunk(tokens) # this extracts entities from the list of words
entities.draw()
Input:
Output:
35.
Preprocessing: Compound TermExtraction
Extracting and tagging compound words or phrases in text
• This can be very valuable for special cases
• For example: “black eyed peas“ --> “black_eyed_peas”
• This totally changes the conceptual meaning!
• Named entity recognition groups together words and identifies entities, but
doesn’t capture them all, so you can identify your own compound words
36.
Code: Compound TermExtraction
from nltk.tokenize import MWETokenizer # multi-word expression
my_text = "You all are the greatest students of all time."
mwe_tokenizer = MWETokenizer([('You','all'), ('of', 'all', 'time')])
mwe_tokens = mwe_tokenizer.tokenize(word_tokenize(my_text))
mwe_tokens
Input:
Output:
['You_all', 'are', 'the', 'greatest', 'students', 'of_all_time', '.']
37.
Preprocessing Checkpoint
What havewe done so far?
• Introduced Python’s Natural Language Toolkit
• Converted text into token form
• Further cleaned the data by removing characters, using stop words,
stemming, parts of speech tagging, named entity recognition and compound
words
38.
Preprocessing Review
Given thetext below, what are some preprocessing techniques you could apply?
We’re rushing our patient to the nearest hospital in Bend, Oregon. He has a
traumatic brain injury and requires medical attention within the next 10 minutes!
Tokenization
Sentence
Word
N-Gram
Regex
Remove
Punctuation
Capital Letters
Numbers
Stop Words
Chunking
Named Entity
Recognition
Compound
Term Extraction
More
Stemming
Parts of Speech
Misspellings
Diff Languages
39.
Pandas for DataAnalysis Review
• Pandas is an open-source python library used for data manipulation and
analysis.
• It provides easy-to-use data structures and data analysis tools which can be
used in a wide range of fields.
• We will only discuss some of the NLP-related frequently used Pandas
functions.
40.
Pandas DataFrame
A DataFrameis a two-dimensional array with heterogeneous data.
It basically a table of data much like in Excel or SQL
41.
Creating Pandas DataFrame
importpandas as pd
new_dataframe = pd.DataFrame(
{ “column_name” : [“jack”, “jill”, “john”],
“column_age” : [13, 14, 12],
“column_weight” : [130.4, 123.6, 150.2] }
)
DataFrames can be created manually or from file.
Manually: From csv file:
import pandas as pd
file_dataframe = pd.read_csv(‘file_data.csv’)
Selecting specific column:
42.
Basic Pandas Functionality
importpandas as pd
data = pd.read_csv(‘data.csv’)
Selecting top and bottom rows:
pd.head() Returns the first n rows.
pd.tail() Returns the last n rows.
Selecting columns:
data[‘column_name’] or data.column_name
Selecting by indexer:
data.iloc[0] - first row of data frame
data.iloc[-1] - last row of data frame
data.iloc[:,0] - first column of data frame
data.iloc[:,-1] - last column of data frame
Data.iloc[0,1] – first row, second column of the dataframe
data.iloc[0:4, 3:5] # first 4 rows and 3rd, 4th, 5th columns of data frame
43.
Preprocessing Summary
• Textdata is messy
▪ Preprocessing must be done before doing analysis
▪ Python has some great libraries for NLP, such as NLTK, TextBlob and spaCy
• There are many preprocessing techniques
▪ Tokenization and organizing the data for analysis is necessary
▪ Otherwise, pick and choose the techniques that makes most sense for your
data and your analysis
Editor's Notes
#2 Welcome to Week 2! Today we’ll show you some of the most popular NLP libraries in Python, and also go through a series of preprocessing techniques. Text data is typically quite messy, so a lot of preprocessing has to be done before you can do any analysis.
#3 NLP Toolkits - There are a lot out there, but a few stand out.
Text Preprocessing Techniques - A lot of preprocessing has to be done before doing the fun analysis. We’ll go through the common steps and key terms.
#4 NLTK - Pretty much everyone starts here.
TextBlob - Can use NLTK features by writing very simple code. Highly recommend.
spaCy - This is up and coming. It's marketed as an "industrial-strength" Python NLP library that's geared toward performance.
gensim - We will be going over this later in the course.
#5 After doing nltk.download(), choose to download all in the GUI. This will give you all the tokenizers, chunkers, algorithms and corporas.
The students should run this code now, so everything will be ready in time for when they do the exercises. It takes about 15 minutes.
#6 Brainstorm with the group. What are some ways you can think of to clean up this data for analysis?
#7 Tokenization is the process of dividing our data into the smaller units that we will analyze
Chunking is a general term. It means to extract meaningful units, or chunks, of text from raw text.
#8 For most purposes, we will be splitting our text up into words, but there are many options out there for splitting text up.
A word you might not have seen before is ‘n-gram’, which means a sequence of n items from a text. These ‘items’ might be syllables, letters, words, etc. but usually refer to words. Researchers usually vary the size of their n gram depending on their application.
Example: “Hi my name is Rick” -> [(Hi, my), (my, name), (name, is), (is, Rick)] would be an example of splitting up a piece of text into 2-grams (called bigrams).
We will see how to do this automatically using nltk later in the slides.
#9 As you can see, the nltk’s built in word tokenizer is able to separate out the sentence into tokens for us to analyze.
#10 You might say that capitalization or punctuation are good places to start but as you can see proper nouns (Smith) and titles (Mr.) are two examples of common words that break those rules for tokenization
This is where built-in tokenizers can help
#11 As you can see, developers have been hard at work to make sure that tokenizers are able to accurately pick out sentences from a piece of text.
#12 Why is this useful? Let’s say you didn’t just want to find the most common words, but the most common two-word phrases (like black-eyed peas). N-grams can help with that.
#13 Good website for interpreting regular expressions: https://regex101.com
\s+ /
\s+ matches any whitespace character (equal to [\r\n\t\f\v ])
+ Quantifier — Matches between one and unlimited times, as many times as possible, giving back as needed (greedy)
[A-Z]['\w]+
Match a single character present in the list below [A-Z]
A-Z a single character in the range between A (index 65) and Z (index 90) (case sensitive)
Match a single character present in the list below ['\w]+
+ Quantifier — Matches between one and unlimited times, as many times as possible, giving back as needed (greedy)
' matches the character ' literally (case sensitive)
\w matches any word character (equal to [a-zA-Z0-9_])
#14 As you can see, the possibilities are endless for tokenization, and the regex you learned in last week’s notes will be very useful if you want full control in how you create your tokens.
#15 Another example using capitalized words to split the text.
This example is a little different though, only the capitalized words were returned. Can you guess why that is?
If you guessed that is had something to do with the ‘gaps’ parameter you’d be correct; specifying ‘gaps=True’ tells python that you want to split the text along these patterns to make tokens, otherwise it uses the pattern to find the tokens themselves.
#18 Stanford’s CoreNLP has different language options
#19 Why do we want to remove these things? They impede our analysis of the text. To analyze texts, we want a uniform format that we can read in a consistent way. Therefore, we try to remove some of the ‘artifacts’ that are language-specific and don’t contribute to the meaning of the text.
The major ways to normalize texts are in the removal of punctuation, capital letters, and numbers.
#20 Why are we replacing the string with a whitespace instead of nothing? Which is better?
Note that the ‘black eyed’ peas portion is different - nothing is good here since you want black and eyed to be grouped together
Note that the word ‘I’m’ is different - the whitespace is good here so later ‘I’ can be grouped with other words like ‘I’, ‘me’, etc. when we move into stemming
Later in the presentation, we talk about Compound Word Extraction, and that’s a way you can keep ‘black-eyed peas’ together
#21 Thankfully, strings in python are really easy to send to lowercase, simply use the .lower() function.
#22 Here are regex knowledge comes in handy because we are able to quickly scan for any digits and words containing digits using the expression ‘\w*\d\w*’. Here is the breakdown of what those characters mean:
\d = digits
\w = any word character
* = 0+ of that character
So this removes digits and any words containing digits
Notice that the word ‘2lb’ has been removed.
#23 Lambdas are what as known as “anonymous functions”. They’re meant to be short functions and most of the time they’re single use.
The format of a lambda is described above. It is “ lambda input : output “
#24 Lambdas are cool, but their real power is when you combine them with maps.
A map is a python function that takes a function and an iterable as input and iterates over the iterable and applies the function to every object within the iterable.
For the example above, you can see that the we applied the ‘square_me’ lambda to every number in the list ‘my_numbers’
The output from a map is a map object, so make sure to cast it to list() type if you want to use the data as a list after.
#25 Now, let’s look at an example of these tools applied to NLP.
As you can see, lambdas and maps make it very easy to remove the numbers in a bunch of texts just by creating one lambda.
#26 Stop words don’t contribute to the meaning of the text and so for our purposes will just confuse the algorithm.
For example, the word ‘some’ doesn’t tell us anything meaningful about what’s going on in this text.
On the next slide, there are some of the commonly removed stop words.
#27 The nltk corpus already comes with a list of stopwords that are commonly removed for text analysis but you can also code your own stopwords manually!
#28 This is just an early example of CounterVectorizer. We will discuss how a CounterVectorizer is used further in week three. In simple terms, CounterVectorizer convert a collection of text documents to a matrix of token counts. In the example in the slide, the English stops words will be removed from the resulting tokens.
#29 Lemmatization is closely related to stemming.
The difference is that a stemmer operates on a single word without knowledge of the context, and therefore cannot discriminate between words which have different meanings depending on part of speech.
However, because stemming does not look at this additional context, stemmers run faster and typically are easier to implement.
Depending on your application, the reduced accuracy may not matter.
#30 As you can see all these different variations of the same word of ‘driving’/’drive’ are reduced to their base form ‘driv’, which is shared by all variations of the word.
An example where lemmatization may provide higher accuracy is:
The stemmed form of leafs is: leaf The stemmed form of leaves is: leav
The lemmatized form of leafs is: leaf The lemmatized form of leaves is: leaf
Source: https://towardsdatascience.com/pre-processing-in-natural-language-machine-learning-898a84b8bd47
#31 Some words change meaning depending on their context in a sentence. For example, the word ‘run’ might be a verb (I like to run in the mornings) or a noun (How did your run go this morning?) depending on how it is used.
Thus part of speech tagging may help gain greater insight into the meaning of a text.
#32 Thankfully, nltk has a built in tagger, so we all we need to do is call this pos_tag from the nltk library.
Some POS tags:
NN - is a noun
NNP – is a proper noun
JJ – is an adjective
IN – is a preposition
VBZ – is a verb, 3rd person sing. present takes
#33 We find the list with all possible POS tags used by the Natural Language Toolkit (nltk) with nltk.help.upenn_tagset() or nltk.help.upenn_tagset('RB’) for information on a specific tag.
#34 Named entity recognition is a case where our preprocessing steps would actually hurt us. If we simply removed punctuations and made everything lowercase, we could accidently convert ‘U.S.’ to ‘us’, which could really change the meaning of a document.
Being able to extract these ‘entities’ (proper nouns) is a valuable tool, that has a lot of applications. For example, if a news site wants to show all the news that pertains to Chicago or U.S.A, it needs to be able to preserve these words.
#35 Again, nltk makes our lives easy by providing a built in ‘ne_chunk’ function that is able to detect what the proper nouns in the sentence are (NNP).
Notice that it is even able to tell the type of proper noun, and labels ‘James Smith’ as ‘PERSON’ and ‘United States’ as ‘GPE’, which stands for geopolitical entity.
#36 Compound term extraction again allows us to better preserve the meaning of our text.
In the example above, having a text with the word ‘black’, ‘eyed’ and ‘peas’ is different than a text that is about ‘black eyed peas’, which is one distinct concept.
#37 This is a way to manually do it in NLTK
Note that this MWE tokenizer is case sensitive. To make it work better, you’d need to make everything lowercase to begin with.







![Code: Tokenization (Words)
from nltk.tokenize import word_tokenize
my_text = "Hi Mr. Smith! I’m going to buy some vegetables (tomatoes and cucumbers)
from the store. Should I pick up some black-eyed peas as well?"
print(word_tokenize(my_text)) # print function requires Python 3
['Hi', 'Mr.', 'Smith', '!', 'I', '’', 'm', ‘going', ‘to', 'buy', 'some',
'vegetables', '(', 'tomatoes', 'and', 'cucumbers', ')', 'from', 'the',
'store', '.', 'Should', 'I', 'pick', 'up', ‘some', 'black-eyed', 'peas', 'as',
'well', '?']
Output:
Input:
Requires python 3](https://image.slidesharecdn.com/nlptoolkitsandpreprocessingtechniques-190218095542/85/Nlp-toolkits-and_preprocessing_techniques-8-320.jpg)

![Code: Tokenization (Sentences)
from nltk.tokenize import sent_tokenize
my_text = "Hi Mr. Smith! I’m going to buy some vegetables (tomatoes and cucumbers)
from the store. Should I pick up some black-eyed peas as well?"
print(sent_tokenize(my_text))
['Hi Mr. Smith!',
'I’m going to buy some vegetables (tomatoes and cucumbers) from the store.',
'Should I pick up some black-eyed peas as well?']
Output:
Input:
Requires python 3](https://image.slidesharecdn.com/nlptoolkitsandpreprocessingtechniques-190218095542/85/Nlp-toolkits-and_preprocessing_techniques-10-320.jpg)
![Code: Tokenization (N-Grams)
from nltk.util import ngrams
my_words = word_tokenize(my_text) # This is the list of all words
twograms = list(ngrams(my_words,2)) # This is for two-word combos, but can pick any n
print(twograms)
[('Hi', 'Mr.'), ('Mr.', 'Smith'), ('Smith', '!'), ('!', 'I'), ('I', '’'), ('’',
'm'), ('m', 'going'), ('going', 'to'), ('to', ‘buy'), ('buy', 'some'), ('some',
'vegetables'), ('vegetables', '('), ('(', 'tomatoes'), ('tomatoes', 'and'), ('and',
'cucumbers'), ('cucumbers', ')'), (')', 'from'), ('from', 'the'), ('the', 'store'),
('store', '.'), ('.', 'Should'), ('Should', 'I'), ('I', 'pick'), ('pick', 'up'),
('up', '1/2'), ('1/2', 'lb'), ('lb', 'of'), ('of', 'black-eyed'), ('black-eyed',
'peas'), ('peas', 'as'), ('as', 'well'), ('well', '?')]
Output:
Input:
Requires python 3](https://image.slidesharecdn.com/nlptoolkitsandpreprocessingtechniques-190218095542/85/Nlp-toolkits-and_preprocessing_techniques-11-320.jpg)
![Tokenization: Regular Expressions
Let’s say you want to tokenize by some other type of grouping or pattern.
Regular expressions (regex) allows you to do so.
Some examples of regular expressions:
• Find white spaces: s+
• Find words starting with capital letters: [A-Z]['w]+](https://image.slidesharecdn.com/nlptoolkitsandpreprocessingtechniques-190218095542/85/Nlp-toolkits-and_preprocessing_techniques-12-320.jpg)
![Code: Tokenization (Regular Expressions)
from nltk.tokenize import RegexpTokenizer
# RegexpTokenizer to match only capitalized words
cap_tokenizer = RegexpTokenizer("[A-Z]['w]+")
print(cap_tokenizer.tokenize(my_text))
['Hi', 'Mr', 'Smith', 'Should']
Output:
Input:](https://image.slidesharecdn.com/nlptoolkitsandpreprocessingtechniques-190218095542/85/Nlp-toolkits-and_preprocessing_techniques-14-320.jpg)




![Code: Remove Punctuation
import re # Regular expression library
import string
# Replace punctuations with a white space
clean_text = re.sub('[%s]' % re.escape(string.punctuation), ' ', my_text)
clean_text
Input:
Output:
'Hi Mr Smith I m going to buy some vegetables tomatoes and cucumbers from
the store Should I pick up 2lbs of black eyed peas as well '
'Hi Mr Smith Im going to buy some vegetables tomatoes and cucumbers from the
store Should I pick up 2lbs of blackeyed peas as well'
Replace with '' instead of ' '](https://image.slidesharecdn.com/nlptoolkitsandpreprocessingtechniques-190218095542/85/Nlp-toolkits-and_preprocessing_techniques-19-320.jpg)






![Code: Remove Stop Words
my_text = ["Hi Mr. Smith! I’m going to buy some vegetables (tomatoes and cucumbers)
from the store. Should I pick up some black-eyed peas as well?"]
# Incorporate stop words when creating the count vectorizer
cv = CountVectorizer(stop_words='english')
X = cv.fit_transform(my_text)
pd.DataFrame(X.toarray(), columns=cv.get_feature_names())
Input:
Output:
Including stop words](https://image.slidesharecdn.com/nlptoolkitsandpreprocessingtechniques-190218095542/85/Nlp-toolkits-and_preprocessing_techniques-27-320.jpg)







![Code: Compound Term Extraction
from nltk.tokenize import MWETokenizer # multi-word expression
my_text = "You all are the greatest students of all time."
mwe_tokenizer = MWETokenizer([('You','all'), ('of', 'all', 'time')])
mwe_tokens = mwe_tokenizer.tokenize(word_tokenize(my_text))
mwe_tokens
Input:
Output:
['You_all', 'are', 'the', 'greatest', 'students', 'of_all_time', '.']](https://image.slidesharecdn.com/nlptoolkitsandpreprocessingtechniques-190218095542/85/Nlp-toolkits-and_preprocessing_techniques-36-320.jpg)




![Creating Pandas DataFrame
import pandas as pd
new_dataframe = pd.DataFrame(
{ “column_name” : [“jack”, “jill”, “john”],
“column_age” : [13, 14, 12],
“column_weight” : [130.4, 123.6, 150.2] }
)
DataFrames can be created manually or from file.
Manually: From csv file:
import pandas as pd
file_dataframe = pd.read_csv(‘file_data.csv’)
Selecting specific column:](https://image.slidesharecdn.com/nlptoolkitsandpreprocessingtechniques-190218095542/85/Nlp-toolkits-and_preprocessing_techniques-41-320.jpg)
![Basic Pandas Functionality
import pandas as pd
data = pd.read_csv(‘data.csv’)
Selecting top and bottom rows:
pd.head() Returns the first n rows.
pd.tail() Returns the last n rows.
Selecting columns:
data[‘column_name’] or data.column_name
Selecting by indexer:
data.iloc[0] - first row of data frame
data.iloc[-1] - last row of data frame
data.iloc[:,0] - first column of data frame
data.iloc[:,-1] - last column of data frame
Data.iloc[0,1] – first row, second column of the dataframe
data.iloc[0:4, 3:5] # first 4 rows and 3rd, 4th, 5th columns of data frame](https://image.slidesharecdn.com/nlptoolkitsandpreprocessingtechniques-190218095542/85/Nlp-toolkits-and_preprocessing_techniques-42-320.jpg)









![Code: Tokenization (Words)
from nltk.tokenize import word_tokenize
my_text = "Hi Mr. Smith! I’m going to buy some vegetables (tomatoes and cucumbers)
from the store. Should I pick up some black-eyed peas as well?"
print(word_tokenize(my_text)) # print function requires Python 3
['Hi', 'Mr.', 'Smith', '!', 'I', '’', 'm', ‘going', ‘to', 'buy', 'some',
'vegetables', '(', 'tomatoes', 'and', 'cucumbers', ')', 'from', 'the',
'store', '.', 'Should', 'I', 'pick', 'up', ‘some', 'black-eyed', 'peas', 'as',
'well', '?']
Output:
Input:
Requires python 3](https://image.slidesharecdn.com/nlptoolkitsandpreprocessingtechniques-190218095542/75/Nlp-toolkits-and_preprocessing_techniques-8-2048.jpg)

![Code: Tokenization (Sentences)
from nltk.tokenize import sent_tokenize
my_text = "Hi Mr. Smith! I’m going to buy some vegetables (tomatoes and cucumbers)
from the store. Should I pick up some black-eyed peas as well?"
print(sent_tokenize(my_text))
['Hi Mr. Smith!',
'I’m going to buy some vegetables (tomatoes and cucumbers) from the store.',
'Should I pick up some black-eyed peas as well?']
Output:
Input:
Requires python 3](https://image.slidesharecdn.com/nlptoolkitsandpreprocessingtechniques-190218095542/75/Nlp-toolkits-and_preprocessing_techniques-10-2048.jpg)
![Code: Tokenization (N-Grams)
from nltk.util import ngrams
my_words = word_tokenize(my_text) # This is the list of all words
twograms = list(ngrams(my_words,2)) # This is for two-word combos, but can pick any n
print(twograms)
[('Hi', 'Mr.'), ('Mr.', 'Smith'), ('Smith', '!'), ('!', 'I'), ('I', '’'), ('’',
'm'), ('m', 'going'), ('going', 'to'), ('to', ‘buy'), ('buy', 'some'), ('some',
'vegetables'), ('vegetables', '('), ('(', 'tomatoes'), ('tomatoes', 'and'), ('and',
'cucumbers'), ('cucumbers', ')'), (')', 'from'), ('from', 'the'), ('the', 'store'),
('store', '.'), ('.', 'Should'), ('Should', 'I'), ('I', 'pick'), ('pick', 'up'),
('up', '1/2'), ('1/2', 'lb'), ('lb', 'of'), ('of', 'black-eyed'), ('black-eyed',
'peas'), ('peas', 'as'), ('as', 'well'), ('well', '?')]
Output:
Input:
Requires python 3](https://image.slidesharecdn.com/nlptoolkitsandpreprocessingtechniques-190218095542/75/Nlp-toolkits-and_preprocessing_techniques-11-2048.jpg)
![Tokenization: Regular Expressions
Let’s say you want to tokenize by some other type of grouping or pattern.
Regular expressions (regex) allows you to do so.
Some examples of regular expressions:
• Find white spaces: s+
• Find words starting with capital letters: [A-Z]['w]+](https://image.slidesharecdn.com/nlptoolkitsandpreprocessingtechniques-190218095542/75/Nlp-toolkits-and_preprocessing_techniques-12-2048.jpg)
![Code: Tokenization (Regular Expressions)
from nltk.tokenize import RegexpTokenizer
# RegexpTokenizer to match only capitalized words
cap_tokenizer = RegexpTokenizer("[A-Z]['w]+")
print(cap_tokenizer.tokenize(my_text))
['Hi', 'Mr', 'Smith', 'Should']
Output:
Input:](https://image.slidesharecdn.com/nlptoolkitsandpreprocessingtechniques-190218095542/75/Nlp-toolkits-and_preprocessing_techniques-14-2048.jpg)




![Code: Remove Punctuation
import re # Regular expression library
import string
# Replace punctuations with a white space
clean_text = re.sub('[%s]' % re.escape(string.punctuation), ' ', my_text)
clean_text
Input:
Output:
'Hi Mr Smith I m going to buy some vegetables tomatoes and cucumbers from
the store Should I pick up 2lbs of black eyed peas as well '
'Hi Mr Smith Im going to buy some vegetables tomatoes and cucumbers from the
store Should I pick up 2lbs of blackeyed peas as well'
Replace with '' instead of ' '](https://image.slidesharecdn.com/nlptoolkitsandpreprocessingtechniques-190218095542/75/Nlp-toolkits-and_preprocessing_techniques-19-2048.jpg)






![Code: Remove Stop Words
my_text = ["Hi Mr. Smith! I’m going to buy some vegetables (tomatoes and cucumbers)
from the store. Should I pick up some black-eyed peas as well?"]
# Incorporate stop words when creating the count vectorizer
cv = CountVectorizer(stop_words='english')
X = cv.fit_transform(my_text)
pd.DataFrame(X.toarray(), columns=cv.get_feature_names())
Input:
Output:
Including stop words](https://image.slidesharecdn.com/nlptoolkitsandpreprocessingtechniques-190218095542/75/Nlp-toolkits-and_preprocessing_techniques-27-2048.jpg)








![Code: Compound Term Extraction
from nltk.tokenize import MWETokenizer # multi-word expression
my_text = "You all are the greatest students of all time."
mwe_tokenizer = MWETokenizer([('You','all'), ('of', 'all', 'time')])
mwe_tokens = mwe_tokenizer.tokenize(word_tokenize(my_text))
mwe_tokens
Input:
Output:
['You_all', 'are', 'the', 'greatest', 'students', 'of_all_time', '.']](https://image.slidesharecdn.com/nlptoolkitsandpreprocessingtechniques-190218095542/75/Nlp-toolkits-and_preprocessing_techniques-36-2048.jpg)




![Creating Pandas DataFrame
import pandas as pd
new_dataframe = pd.DataFrame(
{ “column_name” : [“jack”, “jill”, “john”],
“column_age” : [13, 14, 12],
“column_weight” : [130.4, 123.6, 150.2] }
)
DataFrames can be created manually or from file.
Manually: From csv file:
import pandas as pd
file_dataframe = pd.read_csv(‘file_data.csv’)
Selecting specific column:](https://image.slidesharecdn.com/nlptoolkitsandpreprocessingtechniques-190218095542/75/Nlp-toolkits-and_preprocessing_techniques-41-2048.jpg)
![Basic Pandas Functionality
import pandas as pd
data = pd.read_csv(‘data.csv’)
Selecting top and bottom rows:
pd.head() Returns the first n rows.
pd.tail() Returns the last n rows.
Selecting columns:
data[‘column_name’] or data.column_name
Selecting by indexer:
data.iloc[0] - first row of data frame
data.iloc[-1] - last row of data frame
data.iloc[:,0] - first column of data frame
data.iloc[:,-1] - last column of data frame
Data.iloc[0,1] – first row, second column of the dataframe
data.iloc[0:4, 3:5] # first 4 rows and 3rd, 4th, 5th columns of data frame](https://image.slidesharecdn.com/nlptoolkitsandpreprocessingtechniques-190218095542/75/Nlp-toolkits-and_preprocessing_techniques-42-2048.jpg)

























































































